Gentoo + drbd + ocfs2
Introduction
Somehow they set a task for me ... they say one server is good ... but I take into account the growth of visitors, it would be nice to increase productivity of return and for this purpose one more server will be purchased ...
another server is good, I thought ... just what to do with it ??
After talking with the programmer and about what he wants ...
Namely, the simultaneous return of content, and something like nfs or balls ...
but then there would be an overhead projector because the data was chased across the network and the disk of one server would be loaded, therefore it was necessary that the data were simultaneously stored on both servers and replicated to each other ...
Having searched Google for something on this topic, I found information on cluster fs, and gfs2 and later discovered ocfs2 were suitable for me, but there was a problem in that the dedicated file storage was usually used and it was already mounted by the nodes ... which was unacceptable for me, and then after asking questions to the people in the conference (gentoo@conference.gentoo.ru because there were people working with clusters and other fun things) I went to drbd
Initial data
1 Fighting server 70 gigov of information, on a regular 1Tb reiserfs section
2 A new server with a 2TB disk, uses lvm to allocate a partition equal to the partition on the first server, + a safe zone from which the site transferred by rsync from the first server will run.
Drbd
What is it?
Going on the off site drbd.org immediately it became clear that this is what I need after looking at this picture.
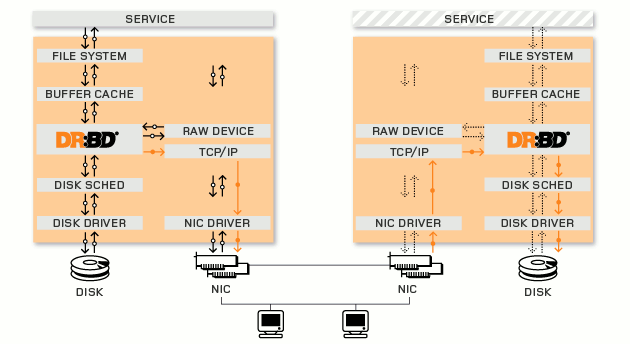
Ie this is essentially a network raid-1
There is replication, but drbd creates only devices and cluster fs is needed on top, otherwise it will work quite strangely.
')
So we put drbd
1. The network between the nodes should work
2. It is desirable to write aliases in / etc / host, for convenience
3. Disk sizes should be the same, but I had significantly more 2TB space on my second computer and only 1TB on the first one, I used lvm to allocate a piece approximately equal to the place on the first server, and use the rest to work the site while working with disks .
approximately equal piece because when creating a drbd device it automatically became equal to the size of the smaller of the two ... that's such a nice bonus ...
4. The kernel must be enabled.
Device Drivers --->
- Connector - unified userspace <-> kernelspace linker
Cryptographic API --->
- Cryptographic algorithm manager
5. We put drbd on both nodes
#emerge drbd
6. Edit the /etc/drbd.conf config
it should look like this
global { usage-count yes; }
common { syncer { rate 100M; } }
resource drbd0 {
protocol C;
startup {
wfc-timeout 20;
degr-wfc-timeout 10;
# become-primary-on both; # Enable this *after* initial testing
}
net {
cram-hmac-alg sha1;
shared-secret "megaSeCrEt";
allow-two-primaries;
ping-timeout 20;
}
on node1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.0.1:7789;
meta-disk internal;
}
on node2 {
device /dev/drbd0;
disk /dev/mapper/vg-home;
address 192.168.0.2:7789;
meta-disk internal;
}
disk {
fencing resource-and-stonith;
no-disk-flushes;
no-md-flushes;
}
handlers {
outdate-peer "/sbin/obliterate"; # We'll get back to this.
}for a more accurate and complete description of man drbd.conf :)
7. On both nodes we enter
# modprobe drbd
# drbdadm create-md drbd0
# drbdadm attach drbd0
# drbdadm connect drbd0
8. Then on the second node (the site is next to it and it will be necessary to upload it to a new section)
#drbdadm - --overwrite-data-of-peer primary drbd0
and restart
# / etc / init.d / drbd restart
restarting is needed so that the service starts up normally and takes the settings from the config, because by default the synchronization speed is quite low ...
9. Synchronization can be observed like this.
#watch cat / proc / drbd
Now it's time to do FS
OCFS2
Why ocfs2?
Because it is in the core.
Why not gfs2?
It is in the kernel, but when you try to use it, when you delete files, it goes into deadlock
(Initially there was an attempt to use it, but after reading the hard way that, yes, she is not ready for production, which is repeatedly mentioned on the developer’s website and not only: (ocfs2 was chosen)
Why not gfs1?
At that time, its support in the 2.6.27 kernel was not + it just did not work ...
1. Do not forget to include in the core
-> File systems
-> OCFS2 file system support (EXPERIMENTAL)
as well as dlm
2. The last ebuilds are looking for in bagzilla
bugs.gentoo.org/show_bug.cgi?id=193249
3. We put
#emerge ocfs2-tools
4. The simplest config, compared to what I had to do on gfs2 (again on both nodes)
/etc/ocfs2/cluster.conf
node:
ip_port = 7777
ip_address = 192.168.0.1
number = 0
name = node1
cluster = ocfs2
node:
ip_port = 7777
ip_address = 192.168.0.2
number = 1
name = node2
cluster = ocfs2
cluster:
node_count = 2
name = ocfs2
5. Create fs on the first node (this step is 10m in the drbd part)
# mkfs.ocfs2 -b 4K -C 32K -N 2 / dev / drbd0 (here you also need to add the name of the cluster and use dlm)
(the exact team got out of my head, but something like this ... as always, complete information man mkfs.ocfs2)
and on the second note it will flood for synchronization ...
Total
After a leisurely format.
mount the partition on the second node
#mount / dev / drbd0 / home / site / www / -t ocfs2
(lyrical digression all webserver logs and so on lie in / home / site / logs for it does not make sense to transfer them to another node, also symlinks in / home / site are made from / home / site / www to some configs which differ on nodes)
and now we are filling the rsync site back ...
after 6 hours of server synchronization, they are ready for combat duty, it remains to be easy to make the server's requests for nodes spreading over the nodes ... but this is another article))
Threat unforgettable
# rc-update add drbd default
# rc-update add ocfs2 default
Zyy possible when formatting and mounting ocfs2 need to restart the service ... unfortunately I do not remember exactly ...
# / etc / init.d / ocfs2 restart
Zyyy possible split-brain sita on how to cope with it there is information on the off site,
Also, drbd's actions are not mentioned here in case of loss of communication with another node, but this is a rather specific thing, so it's better to read about it right in the documentation ...
main links on the basis of which this article was written
www.debian-administration.org/articles/578
oss.oracle.com/projects/ocfs2
www.netup.ru/articles.php?n=13
en.gentoo-wiki.com/wiki/HOWTO_Heartbeat_and_DRBD
www.drbd.org
Source: https://habr.com/ru/post/50143/
All Articles