Doing Liquid Resize with your own hands
You've probably already heard about Liquid Resize scaling technology, which takes into account the contents of the image. If you are wondering how it all works and how you can implement all this yourself, then read on (carefully, many pictures).

(UFO flew in and stretched this drawing here)
The article is posted by me at the request of my friend, who can not put it on Habr, because he does not have an account. Thanks to your advantages, the author has an invite, and he is now with us: Kotter .
Seam Carving is an image resizing algorithm that takes into account the contents of the image (as the authors call the Content-Aware Image Resizing Algorithm). It was first demonstrated in 2007 and aroused considerable interest. Probably many Habr's readers have heard about him, since there have already been articles on this topic.
Then the question arises: how does this algorithm take into account the contents of the images? In theory, everything is simple - first, the importance of different parts of the image is calculated, after which only those parts that, according to the algorithm, are not so important, change in size. In practice, to implement this algorithm, we need to solve a number of questions: how to determine how important parts of the image are, how to find and compress less important parts of the image, etc.
')
In this article I tried to answer these, as well as a number of other questions that arise when solving this problem.
Those who now want to see what I finally got, can find examples of images and a demo program with commented source codes at the end of the article.
Before the article itself, I want to stipulate some conventions.
First of all. In the article I often use the term "energy", although I am not sure of the correctness of this term. And I use it because the authors themselves call it the English word "energy". Energy point means its importance in the image. The more energy - the more important point.
Secondly. The article deals only with horizontal resizing. With simultaneous resizing in both directions, the principle remains the same, only we now consider not only vertical chains of pixels, but also horizontal ones.
Thirdly. I have no experience writing under C # /. NET. The choice of program platform / language was determined by the simplicity of the code for understanding and wide audience coverage. Therefore, if I wrote something in the program ineffectively or not “according to dotnetovsky”, then do not pay attention to it. That's not the point of the program.
Fourth. Russian is not my native language, so sorry for any errors.
And the last. The program code is not optimal. I chose simplicity between the simplicity of the code and the optimality of the code, so if you want to use this algorithm somewhere - optimize it for your task. Fortunately, there is room for optimization.
Actually, we finished with the prelude, now we come to the most interesting ...
The whole algorithm consists of the following components:
Now consider each item in more detail.
First of all, we need to decide which parts of the image are important and which are not.
To solve this problem, the authors of the algorithm suggest for each pixel to calculate its "energy" - that is, some kind of conditional indicator (in parrots), which will show whether this pixel is important in this image, or not.
In principle, there are many ways to do this: from the simplest (for example, to count color changes as compared to the neighboring ones) to quite complex ones (for example, to make an analysis of a person’s attention focusing). According to the authors themselves, they tested many energy functions, and one of the simplest functions gave one of the best results. Therefore, we will use this function now. Here she is:

If you, when seeing this formula with derivatives, were afraid that you will need to recall mathematical analysis, then in vain. In fact, it is formulated quite simply: the energy of a pixel is equal to the change in color of neighboring pixels in comparison with a given pixel. That is, the greater the difference in color between a given pixel and its neighbors, the greater its energy.
Now consider the implementation of energy calculations in practice. Let the points of the image are characterized by their intensity. We have the following 3x3 pixel image:

First, we calculate the absolute value of the difference in intensity between the pixel and its neighbors (right and bottom), and then we calculate the energy of this pixel as the arithmetic average of these values.

For the selected pixel: the difference between it and the neighbor to the right is 8, the neighbor to the bottom is 3. The arithmetic average is (8 + 3) / 2 = 5.5. But since it is more convenient and faster to work with integers, and such accuracy is superfluous, then we discard the fractional part. That is, the energy of the selected pixel is equal to 5.
Similarly, we calculate for the remaining pixels. At the same time, the pixels that are extreme on the right and extreme on the bottom will only have a neighbor on the right or on the bottom, so for them the difference value will be the arithmetic average. For the pixel in the right-bottom corner there are no such neighbors at all, so we simply take its energy as 0. Although it is theoretically possible to calculate energy for it, but we will not complicate our life, since in practice it can be neglected.
As a result, we obtain the following matrix of pixel energies:

If, in our case, pixels are characterized not just by intensity, but by intensity values separately for R, G, B, then the pixel energy is equal to the sum of the energies for each of the components.
An example of an energy map for an image:
In this picture, the darker the color on the energy map is, the more energy.
I implemented finding the pixel energies using the following function:
The function works with global variables: energy is an array in which energy is written, and image is an array in which the image is stored.
We already have energy values for each pixel, but now we need to choose those pixels whose energy value is minimal. But if we start to pick up / add arbitrary pixels, then the image itself will simply crawl away and deform beyond recognition. Of course, this result does not suit us. Therefore, you must first select a chain of pixels, and then delete or add them. What is not an arbitrary chain, and the "correct".
The “correct” chain is a set of points, such that exactly 1 pixel is selected in each line of the image, and the pixels in the adjacent lines are “connected” either by sides or corners.
An example of "correct" chains:

Example of "invalid" chains:

Now we know that we need to delete the "correct" chains, then we will not spoil the image much. But which chain then choose? The authors of the algorithm suggest to choose those chains for removal / stretching, the sum of the pixel energies that are included in it is minimal.
This raises a completely natural question: how do we find such a chain?
The first option is to iterate over all the chains, summarize them, and find them with the minimum amount. The option, of course, is interesting, but then for processing even a small image we will have to wait for eternity :) If we have an eternity in store, then we write a brute-force code, start and wait. If you want to see the result in a shorter period of time - then read on.
Here dynamic programming comes to our rescue. I will not go into details, and show what the “dynamism” of programming is (by the way, the term “programming” has nothing to do with writing code), and immediately proceed directly to the algorithm. If someone does not know what “dynamic programming” is and wants to know, he can read about it on Wikipedia or other sources.
First, we will create a new array, which is equal in size to an array with pixel energies. In this array, for each pixel we write the sum of the elements of the minimum chain of pixels that starts at the top edge of the image and ends at this pixel.
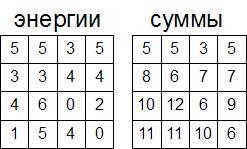
We show the calculation process by example. Suppose we have an array with energy values for each pixel:

We will calculate the elements of this array along the lines - from the first to the last. For the top line, the elements of this array will be equal to the elements of the array, since from each such element it is possible to build only 1 chain (all of unit length):

Now let's calculate the second line. Consider the selected cell. We can build a chain from this cell in three ways, as shown in the figure. Of these three methods, we need to choose the minimal one (since we consider the sums of precisely minimal chains). For the selected cell, this will be a chain with the sum of 3, and add the energy of the cell itself to this chain. Therefore, in this cell we write the number 7 (the sum of 3 and 4). Similarly, we calculate all sums for all elements of the second line:

Let's move to the third line. In principle, the third line is considered to be similar to the second. Consider the selected cell again. From it we can form such chains:
After calculating all the lines in this way, we get the following array as a result:
If we formalize the calculation of this array, we obtain the following formula:
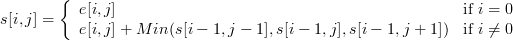
where s is our array of sums, and e is an array of energies.
My implementation of the calculation of the array of sums:
The function works with global variables: energy is an array in which energy is written and sum is an array in which the values of sums are written.
Now, when we already have this array, it is time to think - and why do we need it at all? I will answer - according to this array we can now quickly find a chain with the minimum amount of energies.
First we will find which pixel from the bottom line of the image belongs to this chain: the element that we are looking for will have the smallest value in the array of sums among the elements of the bottom line. Why? Recall that in this array the values of the sum of the elements of the minimum chains are recorded from the top edge to the given pixel. The chains that interest us end in a pixel from the last row. Accordingly, for the entire picture, the minimum chain will be selected as the minimum of all the minimum chains that end in pixels from the bottom line.
For our example, this will be the following element:

We already know on which pixel the minimum chain ends, now we can find a pixel from the last but one line. As it was already written, from the lower pixel we can go only to 3 neighboring pixels on the line above: on the left-from the top, on the top or on the right-from the top. Among these pixels, choose a pixel with the minimum value in the array of sums, and go to it. We continue until we reach the top line. The process is shown in the following figure:

After performing all these operations, we get what we wanted - a set of pixels that we can change with minimal loss for the image.
An example of a minimum chain in the figure:

Software implementation of the chain search algorithm:
We finally found a chain of pixels with which we will work. Now you can remember why we were looking for it at all. Our task is to resize the image. The magnification and reduction of the image are slightly different, so first consider the reduction, and then the increase.
If we need to reduce the width of the image by 1 pixel, then everything is simple: we find a vertical chain, as described above, and simply remove it from the image. I implemented this operation using the following loop:
The i-th element of the cropPixels array contains the number of the pixel column, which we remove from the i-th line. And the cycle itself does the following: all the pixels that are written to the right of those that are deleted, we move one point to the left. As a result of this operation, our pixel chain will be removed from the image.
If we need to reduce the image not by 1 pixel, but by a larger value, then we perform the operation of deleting the chain as many times as necessary (each time we need to look for this chain).
I want to note that the operation of reducing the image by n pixels and the operation of reducing the image by 1 pixel n times are not equivalent. Their difference is that if we reduce by 1 pixel n times, then for each of the intermediate images we look for the pixel energy, and if we immediately reduce it by n, then we take the pixel energy from the original image.
We can already reduce images, now we need to figure out how to increase them.
The first thing that comes to mind is exactly the same as when decreasing, choose chains and “stretch” them. But if we implement it, we get the following result:

As we can see, the program simply took one bar and stretched it, but this is not exactly what we need.
The next thought may be, for example, this: you need to take more than one minimum chain, but as much as you need to complete the drawing to the desired width. Suppose we implemented this algorithm, but what will happen if we increase the figure by 2 times?

As you can see from this picture, we simply selected all the points and stretched them horizontally, but this is also not exactly what we need, since this method does not differ from the usual stretching.
But in principle, the very idea of the latter method is correct, but with a slight change: we need to increase the image in stages, so that at each stage as many “non-important” parts of the image as possible and as few as “important” ones are covered. Then the question arises, how to break the process of increasing into stages? There are a lot of options - from dividing up into stages manually, before writing some kind of heuristic analyzers. But in my program I wrote simply - breaking into stages occurs in such a way that at each stage the image does not increase by more than 50%. Sometimes it gives an acceptable result, sometimes not so much, but, as I have already written, there are a lot of options for implementing partitioning.
If we increase our UFO picture this way, we get the following result:

As you can see, the UFO, man and tree remained unchanged.
All examples of scaling pictures were obtained using a program that I wrote in parallel with this article, implementing the algorithms that are described here.
Source codes and binary programs can be downloaded at the bottom of the article.
A classic example of Content-Aware Resizing:

The following picture clearly expresses the “important” objects and background.
(original) (reduced) (increased)

Drawing starry sky When resizing, the shape of the stars almost does not change.
(original) (reduced) (increased)

And another example of scaling two photos taken by gmm .
(original) (reduced) (increased)

(original) (reduced) (increased)

So, what we got as a result:
Thanks to those who read the article to the end, I hope it was interesting.
Sources (VS 2008)
Binary (.NET)
upd
Useful links on the topic:
(UFO flew in and stretched this drawing here)
The article is posted by me at the request of my friend, who can not put it on Habr, because he does not have an account. Thanks to your advantages, the author has an invite, and he is now with us: Kotter .
Content
- What is Seam Carving?
- A few comments on reading the article
- General scheme of the algorithm
- Point energy calculation
- Finding the chain with the minimum total energy
- Decrease figures
- Enlarging Drawings
- Examples
- Results
What is Seam Carving?
Seam Carving is an image resizing algorithm that takes into account the contents of the image (as the authors call the Content-Aware Image Resizing Algorithm). It was first demonstrated in 2007 and aroused considerable interest. Probably many Habr's readers have heard about him, since there have already been articles on this topic.
Then the question arises: how does this algorithm take into account the contents of the images? In theory, everything is simple - first, the importance of different parts of the image is calculated, after which only those parts that, according to the algorithm, are not so important, change in size. In practice, to implement this algorithm, we need to solve a number of questions: how to determine how important parts of the image are, how to find and compress less important parts of the image, etc.
')
In this article I tried to answer these, as well as a number of other questions that arise when solving this problem.
Those who now want to see what I finally got, can find examples of images and a demo program with commented source codes at the end of the article.
A few comments on reading the article
Before the article itself, I want to stipulate some conventions.
First of all. In the article I often use the term "energy", although I am not sure of the correctness of this term. And I use it because the authors themselves call it the English word "energy". Energy point means its importance in the image. The more energy - the more important point.
Secondly. The article deals only with horizontal resizing. With simultaneous resizing in both directions, the principle remains the same, only we now consider not only vertical chains of pixels, but also horizontal ones.
Thirdly. I have no experience writing under C # /. NET. The choice of program platform / language was determined by the simplicity of the code for understanding and wide audience coverage. Therefore, if I wrote something in the program ineffectively or not “according to dotnetovsky”, then do not pay attention to it. That's not the point of the program.
Fourth. Russian is not my native language, so sorry for any errors.
And the last. The program code is not optimal. I chose simplicity between the simplicity of the code and the optimality of the code, so if you want to use this algorithm somewhere - optimize it for your task. Fortunately, there is room for optimization.
Actually, we finished with the prelude, now we come to the most interesting ...
General scheme of the algorithm
The whole algorithm consists of the following components:
- Finding the energy of each point. At this stage, we need to know which parts of the image are more important and which less important, based on these data, we will subsequently change the image size.
- Finding such a vertical chain of pixels so that the total energy of the pixels that make up this chain is minimal. A pixel chain is such a set of pixels that exactly one pixel is selected in each row, and the neighboring pixels in it are connected by sides or corners. If we find such a chain, we can remove it from the image, while at the same time affecting the content of the image as little as possible.
- When we find a chain with minimal energy, we can only remove it if we need to reduce the image, or stretch it if we need to enlarge the image.
Now consider each item in more detail.
Point energy calculation
First of all, we need to decide which parts of the image are important and which are not.
To solve this problem, the authors of the algorithm suggest for each pixel to calculate its "energy" - that is, some kind of conditional indicator (in parrots), which will show whether this pixel is important in this image, or not.
In principle, there are many ways to do this: from the simplest (for example, to count color changes as compared to the neighboring ones) to quite complex ones (for example, to make an analysis of a person’s attention focusing). According to the authors themselves, they tested many energy functions, and one of the simplest functions gave one of the best results. Therefore, we will use this function now. Here she is:
If you, when seeing this formula with derivatives, were afraid that you will need to recall mathematical analysis, then in vain. In fact, it is formulated quite simply: the energy of a pixel is equal to the change in color of neighboring pixels in comparison with a given pixel. That is, the greater the difference in color between a given pixel and its neighbors, the greater its energy.
Now consider the implementation of energy calculations in practice. Let the points of the image are characterized by their intensity. We have the following 3x3 pixel image:
First, we calculate the absolute value of the difference in intensity between the pixel and its neighbors (right and bottom), and then we calculate the energy of this pixel as the arithmetic average of these values.
For the selected pixel: the difference between it and the neighbor to the right is 8, the neighbor to the bottom is 3. The arithmetic average is (8 + 3) / 2 = 5.5. But since it is more convenient and faster to work with integers, and such accuracy is superfluous, then we discard the fractional part. That is, the energy of the selected pixel is equal to 5.
Similarly, we calculate for the remaining pixels. At the same time, the pixels that are extreme on the right and extreme on the bottom will only have a neighbor on the right or on the bottom, so for them the difference value will be the arithmetic average. For the pixel in the right-bottom corner there are no such neighbors at all, so we simply take its energy as 0. Although it is theoretically possible to calculate energy for it, but we will not complicate our life, since in practice it can be neglected.
As a result, we obtain the following matrix of pixel energies:
If, in our case, pixels are characterized not just by intensity, but by intensity values separately for R, G, B, then the pixel energy is equal to the sum of the energies for each of the components.
An example of an energy map for an image:
In this picture, the darker the color on the energy map is, the more energy.
I implemented finding the pixel energies using the following function:
private void FindEnergy() { for (int i = 0; i < imgHeight; i++) for (int j = 0; j < imgWidth; j++) { energy[i, j] = 0; // R, G, B for (int k = 0; k < 3; k++) { int sum = 0, count = 0; // , sum if (i != imgHeight - 1) { count++; sum += Math.Abs((int)image[i, j, k] - (int)image[i + 1, j, k]); } // , sum if (j != imgWidth - 1) { count++; sum += Math.Abs((int)image[i, j, k] - (int)image[i, j + 1, k]); } // energy k- ( R, G B) if (count != 0) energy[i, j] += sum / count; } } } The function works with global variables: energy is an array in which energy is written, and image is an array in which the image is stored.
Finding the chain with the minimum total energy
We already have energy values for each pixel, but now we need to choose those pixels whose energy value is minimal. But if we start to pick up / add arbitrary pixels, then the image itself will simply crawl away and deform beyond recognition. Of course, this result does not suit us. Therefore, you must first select a chain of pixels, and then delete or add them. What is not an arbitrary chain, and the "correct".
The “correct” chain is a set of points, such that exactly 1 pixel is selected in each line of the image, and the pixels in the adjacent lines are “connected” either by sides or corners.
An example of "correct" chains:
Example of "invalid" chains:
Now we know that we need to delete the "correct" chains, then we will not spoil the image much. But which chain then choose? The authors of the algorithm suggest to choose those chains for removal / stretching, the sum of the pixel energies that are included in it is minimal.
This raises a completely natural question: how do we find such a chain?
The first option is to iterate over all the chains, summarize them, and find them with the minimum amount. The option, of course, is interesting, but then for processing even a small image we will have to wait for eternity :) If we have an eternity in store, then we write a brute-force code, start and wait. If you want to see the result in a shorter period of time - then read on.
Here dynamic programming comes to our rescue. I will not go into details, and show what the “dynamism” of programming is (by the way, the term “programming” has nothing to do with writing code), and immediately proceed directly to the algorithm. If someone does not know what “dynamic programming” is and wants to know, he can read about it on Wikipedia or other sources.
First, we will create a new array, which is equal in size to an array with pixel energies. In this array, for each pixel we write the sum of the elements of the minimum chain of pixels that starts at the top edge of the image and ends at this pixel.
We show the calculation process by example. Suppose we have an array with energy values for each pixel:
We will calculate the elements of this array along the lines - from the first to the last. For the top line, the elements of this array will be equal to the elements of the array, since from each such element it is possible to build only 1 chain (all of unit length):
Now let's calculate the second line. Consider the selected cell. We can build a chain from this cell in three ways, as shown in the figure. Of these three methods, we need to choose the minimal one (since we consider the sums of precisely minimal chains). For the selected cell, this will be a chain with the sum of 3, and add the energy of the cell itself to this chain. Therefore, in this cell we write the number 7 (the sum of 3 and 4). Similarly, we calculate all sums for all elements of the second line:
Let's move to the third line. In principle, the third line is considered to be similar to the second. Consider the selected cell again. From it we can form such chains:
- this cell plus the minimum chain is 8;
- this cell plus the minimum chain is 6;
- this cell plus the minimum chain is 7;
After calculating all the lines in this way, we get the following array as a result:
If we formalize the calculation of this array, we obtain the following formula:
where s is our array of sums, and e is an array of energies.
My implementation of the calculation of the array of sums:
private void FindSum() { // sum energy for (int j = 0; j < imgWidth; j++) sum[0, j] = energy[0, j]; // (i,j) sum // energy[i,j] + MIN ( sum[i-1, j-1], sum[i-1, j], sum[i-1, j+1]) for (int i = 1; i < imgHeight; i++) for (int j = 0; j < imgWidth; j++) { sum[i, j] = sum[i - 1, j]; if (j > 0 && sum[i - 1, j - 1] < sum[i, j]) sum[i, j] = sum[i - 1, j - 1]; if (j < imgWidth - 1 && sum[i - 1, j + 1] < sum[i, j]) sum[i, j] = sum[i - 1, j + 1]; sum[i, j] += energy[i, j]; } } The function works with global variables: energy is an array in which energy is written and sum is an array in which the values of sums are written.
Now, when we already have this array, it is time to think - and why do we need it at all? I will answer - according to this array we can now quickly find a chain with the minimum amount of energies.
First we will find which pixel from the bottom line of the image belongs to this chain: the element that we are looking for will have the smallest value in the array of sums among the elements of the bottom line. Why? Recall that in this array the values of the sum of the elements of the minimum chains are recorded from the top edge to the given pixel. The chains that interest us end in a pixel from the last row. Accordingly, for the entire picture, the minimum chain will be selected as the minimum of all the minimum chains that end in pixels from the bottom line.
For our example, this will be the following element:
We already know on which pixel the minimum chain ends, now we can find a pixel from the last but one line. As it was already written, from the lower pixel we can go only to 3 neighboring pixels on the line above: on the left-from the top, on the top or on the right-from the top. Among these pixels, choose a pixel with the minimum value in the array of sums, and go to it. We continue until we reach the top line. The process is shown in the following figure:
After performing all these operations, we get what we wanted - a set of pixels that we can change with minimal loss for the image.
An example of a minimum chain in the figure:
Software implementation of the chain search algorithm:
private int[] FindShrinkedPixels() { // int last = imgHeight - 1; // int[] res = new int[imgHeight]; // sum, res[last] res[last] = 0; for (int j = 1; j < imgWidth; j++) if (sum[last, j] < sum[last, res[last]]) res[last] = j; // . for (int i = last - 1; i >= 0; i--) { // prev - // (prev-1), prev (prev+1), int prev = res[i + 1]; // , sum, , , res[i] res[i] = prev; if (prev > 0 && sum[i, res[i]] > sum[i, prev - 1]) res[i] = prev - 1; if (prev < imgWidth - 1 && sum[i, res[i]] > sum[i, prev + 1]) res[i] = prev + 1; } return res; } Decrease figures
We finally found a chain of pixels with which we will work. Now you can remember why we were looking for it at all. Our task is to resize the image. The magnification and reduction of the image are slightly different, so first consider the reduction, and then the increase.
If we need to reduce the width of the image by 1 pixel, then everything is simple: we find a vertical chain, as described above, and simply remove it from the image. I implemented this operation using the following loop:
for (int i = 0; i < imgHeight; i++) for (int j = cropPixels[i]; j < imgWidth; j++) { pImage[i, j] = pImage[i, j + 1]; } The i-th element of the cropPixels array contains the number of the pixel column, which we remove from the i-th line. And the cycle itself does the following: all the pixels that are written to the right of those that are deleted, we move one point to the left. As a result of this operation, our pixel chain will be removed from the image.
If we need to reduce the image not by 1 pixel, but by a larger value, then we perform the operation of deleting the chain as many times as necessary (each time we need to look for this chain).
I want to note that the operation of reducing the image by n pixels and the operation of reducing the image by 1 pixel n times are not equivalent. Their difference is that if we reduce by 1 pixel n times, then for each of the intermediate images we look for the pixel energy, and if we immediately reduce it by n, then we take the pixel energy from the original image.
Enlarging Drawings
We can already reduce images, now we need to figure out how to increase them.
The first thing that comes to mind is exactly the same as when decreasing, choose chains and “stretch” them. But if we implement it, we get the following result:
As we can see, the program simply took one bar and stretched it, but this is not exactly what we need.
The next thought may be, for example, this: you need to take more than one minimum chain, but as much as you need to complete the drawing to the desired width. Suppose we implemented this algorithm, but what will happen if we increase the figure by 2 times?
As you can see from this picture, we simply selected all the points and stretched them horizontally, but this is also not exactly what we need, since this method does not differ from the usual stretching.
But in principle, the very idea of the latter method is correct, but with a slight change: we need to increase the image in stages, so that at each stage as many “non-important” parts of the image as possible and as few as “important” ones are covered. Then the question arises, how to break the process of increasing into stages? There are a lot of options - from dividing up into stages manually, before writing some kind of heuristic analyzers. But in my program I wrote simply - breaking into stages occurs in such a way that at each stage the image does not increase by more than 50%. Sometimes it gives an acceptable result, sometimes not so much, but, as I have already written, there are a lot of options for implementing partitioning.
If we increase our UFO picture this way, we get the following result:
As you can see, the UFO, man and tree remained unchanged.
Examples
All examples of scaling pictures were obtained using a program that I wrote in parallel with this article, implementing the algorithms that are described here.
Source codes and binary programs can be downloaded at the bottom of the article.
A classic example of Content-Aware Resizing:
The following picture clearly expresses the “important” objects and background.
Drawing starry sky When resizing, the shape of the stars almost does not change.
And another example of scaling two photos taken by gmm .
Results
So, what we got as a result:
- Knowledge of the principle of operation of such an interesting and useful algorithm as Seam Carving;
- The program in which you can play in the image size changer (of course there are also Photoshop and http://rsizr.com/, but in these cases you do not have the source code);
- Space for imagination on possible improvements of the algorithm (for example, you can attach a face detector to it, I think the results will be better);
- Knowing that Content-Aware Rescale in Photoshop is not a special Photoshop magic, but a simple algorithm that can be understood.
Thanks to those who read the article to the end, I hope it was interesting.
PS
Sources (VS 2008)
Binary (.NET)
upd
Useful links on the topic:
- PDF, in which the authors describe the algorithm (English, ~ 18 MB).
- Improving the way to count energy Sobol operator (eng).
- Dynamic programming on Russian Wikipedia. DP was used in this algorithm, but it has a much larger scope of application, so it is highly recommended to read for those who are not familiar with it.
- At the request of prokoudine , I will mention some free implementations of the algorithm:
- The Liquid Rescale extension for GIMP and ImageMagick , based on the liblqr library,
- SeamCarvingGUI based on CAIR library
Source: https://habr.com/ru/post/48518/
All Articles