Treatment of dead files, download and resume
In this topic you will learn how:
Today stumbled upon the topic " Torrent vs. 64 kbps ”and I saw a problem that I ran into a week ago.
For quite a long time, 10 days (with interruptions), I downloaded a 3.5 GB ISO image at my 100 Kbps. And this very image was damaged when downloading. I tried to search for this case in torrents and use the method described in the above topic - I used to restore files like this before. But the file was not there (and the resource from where I downloaded it only got a couple of weeks ago). In order not to start kicking me for piracy, I will immediately say that I downloaded Visual Studio 2008 Professional SP1 RUS from Dreamspark .
So, I didn’t want to wait another 10 days, just like producing a lot of manual work, as a result of which a script was born, which fulfilled the whole dirty process ...
')
It was necessary to minimize the amount of information that will have to be pumped, and actually somehow identify these damaged pieces. From here, the plan of action obviously follows:
And where to get this “correct” hash? In order not to download everything entirely to yourself, you need some third-party place where you can download a file at a much higher speed. I just had access to the site of virtual hosting, including SSH - just what we need. But ... the space there was not at all 3.5 GB, but only 1.5 GB. As a result, the thought came not to pull the entire file at once, but in pieces.
As a result of all these fabrications, the following code was born (let's call the file md5_verify.php ).
In short, the script downloads the file in parts, comparing the hash of each successive piece, with what we found on our machine. If it does not match - our piece is broken, and the one on the server is good, we postpone it for later download.
To begin with, what we downloaded must be cut into pieces:
The -a parameter indicates the length of the suffix, since it is alphabetic (26 lowercase characters), then 3 will be quite enough for us: 26³ = 17,576, which is clearly more than the number of pieces of 3.5 Gb / 1 Mb ≈ 3584.
When the whole thing is cut, we get files with the names xaaa, xaab, xaac, etc.
Now consider the hash:
This process is also quite long, in the end a file with the contents of the form will be received:
Then we load md5_verify.php and md5sum.txt on the server, and in the same place we create a daddy out, where the pieces that we need to transfer will be added. We are connecting via SSH and typing the php interpreter into our script. Now you can go to sleep, walk or watch House MD
After a few hours, depending on the width of the channel that is provided to you on the site, the script will end, and in the out folder will be all the pieces that you need to download.
Hide them in the archive:
And finally, you just need to transfer the received archive to the daddy from where you can download it, and set your favorite wget, curl or whatever you like there.
Replacing the damaged pieces with what we extracted from the downloaded archive, we can glue the patient back:
You can cut, glue and hash anything you want, but all who inevitably have to use Windows have long gotten all these little wonderful utilities like cat, split and md5sum, standard for Linux, ported to Windows (the GnuWin32 project).
Yes, by the way, at the same time I found a great way to download with a resume, even if the server is not able to give Partial Content: just simply pull the file to your hosting site through the shell, and then download from there like decent people.
Many services, of course, want Referer and / or Cookie, not agreeing to just give up the file. You can get them: you need Firefox and its extension is Live HTTP Headers .
Open the add-on window, click on the site on the link / button "Download", pops up an offer to save the file. We refuse to download the file by clicking "Cancel", and then copy the data we need from the header.
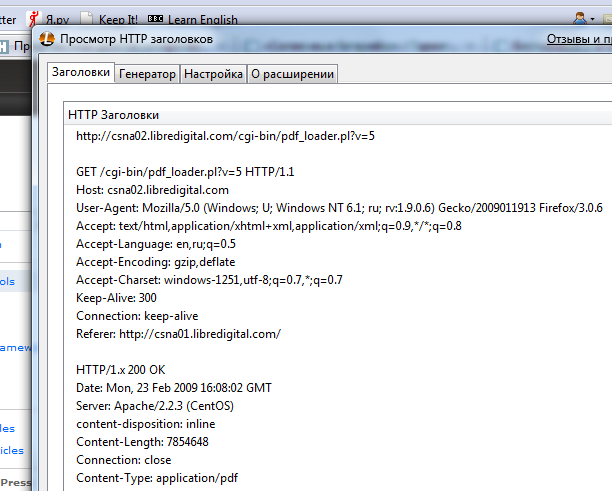
Well, then we shove this data into your favorite rocking chair (on screenshots, this is all done locally, but you obviously need to do this via SSH on a remote server):
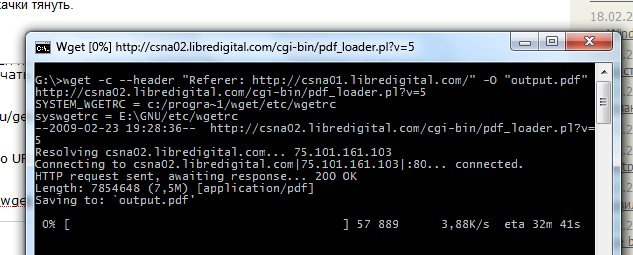
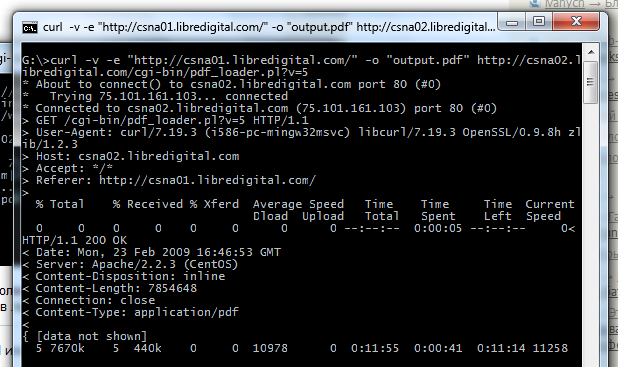
On the screen you can see the use of the -c switch for wget (for curl it is used by -C ), it allows you to download, however, it is given here only for demonstration, because the server from the example just does not allow to download.
However, it makes sense to use wget and curl with resuming directly on your machine: if you leave the same output file name (the -O key), you can download one file in parts at any time and use a new link each time (and with the changed cookie).
This is the third "learn how" of the promises at the beginning of the topic.
PS The whole story ended with the fact that the patient had ≈ 500 damaged parts. It took a couple of hours to write, debug, cut and calculate the hash, several hours to run the script on the server, and about 12 hours to download these parts, which in total took about a day. Nevertheless, it is much less than again to pump parts in a dozen days (and be sure to damage something again).
- recover damaged downloads, even if the file is not in torrents and other sources that contain the hash of its fragments;
- download file with resume, even if it is not supported by the server;
- download, if the server does not provide direct links, giving the file from different addresses (but gives Partial Content).
Today stumbled upon the topic " Torrent vs. 64 kbps ”and I saw a problem that I ran into a week ago.
For quite a long time, 10 days (with interruptions), I downloaded a 3.5 GB ISO image at my 100 Kbps. And this very image was damaged when downloading. I tried to search for this case in torrents and use the method described in the above topic - I used to restore files like this before. But the file was not there (and the resource from where I downloaded it only got a couple of weeks ago). In order not to start kicking me for piracy, I will immediately say that I downloaded Visual Studio 2008 Professional SP1 RUS from Dreamspark .
So, I didn’t want to wait another 10 days, just like producing a lot of manual work, as a result of which a script was born, which fulfilled the whole dirty process ...
')
Idea
It was necessary to minimize the amount of information that will have to be pumped, and actually somehow identify these damaged pieces. From here, the plan of action obviously follows:
- we cut the downloaded file into rather small pieces;
- we consider hash;
- compare with some reference, identifying the "bad";
- Download the necessary pieces and glue.
And where to get this “correct” hash? In order not to download everything entirely to yourself, you need some third-party place where you can download a file at a much higher speed. I just had access to the site of virtual hosting, including SSH - just what we need. But ... the space there was not at all 3.5 GB, but only 1.5 GB. As a result, the thought came not to pull the entire file at once, but in pieces.
Code
As a result of all these fabrications, the following code was born (let's call the file md5_verify.php ).
<?php
$md5sum = 'md5sum.txt' ; //
$tmp = 'chunk.tmp' ; //
$out = 'out/' ; //
$offset = 0 ; // ( )
$chunk = 1048576 ; //
$size = 3760066560 ; //
$host = 'http://all.files.dreamspark.com' ;
$path = '/dl/studentdownload/7/6/3/76329869-10C4-4360-9B09-98C813F8EAFA/ru_visual_studio_2008_professional_edition_dvd_x86_x15-25526.iso' ;
$param = '?LCID=1033&__gda__={timestamp}_{hash}' ;
$cookie = '__sdt__={another-hash-or-guid}' ;
$url = $host . $path . $param ;
//
$sums = file ( $md5sum );
for ( $i = 0 , $l = sizeof ( $sums ); $i < $l && $offset + $i * $chunk < $size ; $i ++)
{
//
$start = $offset + $i * $chunk ;
$end = min ( $size , $offset + ( $i + 1 ) * $chunk ) - 1 ;
//
list( $hash , $file ) = explode ( ' ' , $sums [ $i + intval ( $offset / $chunk )]);
$file = trim ( $file , "*\r\n " );
//
$fp = fopen ( $tmp , "w+" );
// CURL
$options = array
(
CURLOPT_URL => $url ,
CURLOPT_HEADER => false ,
CURLOPT_COOKIE => $cookie ,
CURLOPT_RANGE => $start . '-' . $end , //
CURLOPT_FILE => $fp
);
$ch = curl_init (); // CURL
curl_setopt_array ( $ch , $options ); //
curl_exec ( $ch ); //
curl_close ( $ch ); //
fclose ( $fp ); //
//
$broken = ( $hash != md5_file ( $tmp ));
// ,
print $file . ' [' . $start . '-' . $end . ']: ' . ( $broken ? 'BROKEN' : 'OK' ) . "\n" ;
// , ( )
if ( $broken )
copy ( $tmp , $out . $file );
//
unlink ( $tmp );
}
In short, the script downloads the file in parts, comparing the hash of each successive piece, with what we found on our machine. If it does not match - our piece is broken, and the one on the server is good, we postpone it for later download.
Acting
To begin with, what we downloaded must be cut into pieces:
C:\ISO>mkdir out && cd out && split -a 3 -b 1048576 ..\ru_visual_studio_2008_professional_edition_dvd_x86_x15-25526.isoThe -a parameter indicates the length of the suffix, since it is alphabetic (26 lowercase characters), then 3 will be quite enough for us: 26³ = 17,576, which is clearly more than the number of pieces of 3.5 Gb / 1 Mb ≈ 3584.
When the whole thing is cut, we get files with the names xaaa, xaab, xaac, etc.
Now consider the hash:
C:\ISO\out>md5sum x* > ..\md5sum.txtThis process is also quite long, in the end a file with the contents of the form will be received:
26c379b3718d8a22466aeadd02d734ec *xaaa
2671dc8915abd026010f3d02a5655163 *xaab
6f539fcb0d5336dfd28df48bbe14dd20 *xaac
69f670a2d9f8cf843cdc023b746c3b8c *xaad
…
Then we load md5_verify.php and md5sum.txt on the server, and in the same place we create a daddy out, where the pieces that we need to transfer will be added. We are connecting via SSH and typing the php interpreter into our script. Now you can go to sleep, walk or watch House MD
After a few hours, depending on the width of the channel that is provided to you on the site, the script will end, and in the out folder will be all the pieces that you need to download.
Hide them in the archive:
tar - jcvf "chunks.tar.bz2" ./out/x*And finally, you just need to transfer the received archive to the daddy from where you can download it, and set your favorite wget, curl or whatever you like there.
Replacing the damaged pieces with what we extracted from the downloaded archive, we can glue the patient back:
cat out\x* > fixed.isoYou can cut, glue and hash anything you want, but all who inevitably have to use Windows have long gotten all these little wonderful utilities like cat, split and md5sum, standard for Linux, ported to Windows (the GnuWin32 project).
About resume
Yes, by the way, at the same time I found a great way to download with a resume, even if the server is not able to give Partial Content: just simply pull the file to your hosting site through the shell, and then download from there like decent people.
Many services, of course, want Referer and / or Cookie, not agreeing to just give up the file. You can get them: you need Firefox and its extension is Live HTTP Headers .
Open the add-on window, click on the site on the link / button "Download", pops up an offer to save the file. We refuse to download the file by clicking "Cancel", and then copy the data we need from the header.
Well, then we shove this data into your favorite rocking chair (on screenshots, this is all done locally, but you obviously need to do this via SSH on a remote server):
wget --header "Referer: http://csna01.libredigital.com/" -O "output.pdf" http://csna02.libredigital.com/cgi-bin/pdf_loader.pl?v=5
curl -v -e "http://csna01.libredigital.com/" -o "output.pdf" http://csna02.libredigital.com/cgi-bin/pdf_loader.pl?v=5
On the screen you can see the use of the -c switch for wget (for curl it is used by -C ), it allows you to download, however, it is given here only for demonstration, because the server from the example just does not allow to download.
At last
However, it makes sense to use wget and curl with resuming directly on your machine: if you leave the same output file name (the -O key), you can download one file in parts at any time and use a new link each time (and with the changed cookie).
This is the third "learn how" of the promises at the beginning of the topic.
PS The whole story ended with the fact that the patient had ≈ 500 damaged parts. It took a couple of hours to write, debug, cut and calculate the hash, several hours to run the script on the server, and about 12 hours to download these parts, which in total took about a day. Nevertheless, it is much less than again to pump parts in a dozen days (and be sure to damage something again).
Source: https://habr.com/ru/post/48496/
All Articles