Active Ranking Learning
With this post I am opening a series where my colleagues and I will tell you how ML is used in Mail.ru Search. Today I will explain how ranking is arranged and how we use information about user interactions with our search engine to make the search engine better.
What is meant by ranking task? Imagine that in the training sample there are some set of queries for which the order of documents by relevance is known. For example, you know which document is the most relevant, which is the second most relevant, etc. And you need to restore this order for the entire population. That is, for all requests from the general population, put the most relevant document in the first place, and the most irrelevant in the last.
Let's see how such problems are solved in large search engines.
')
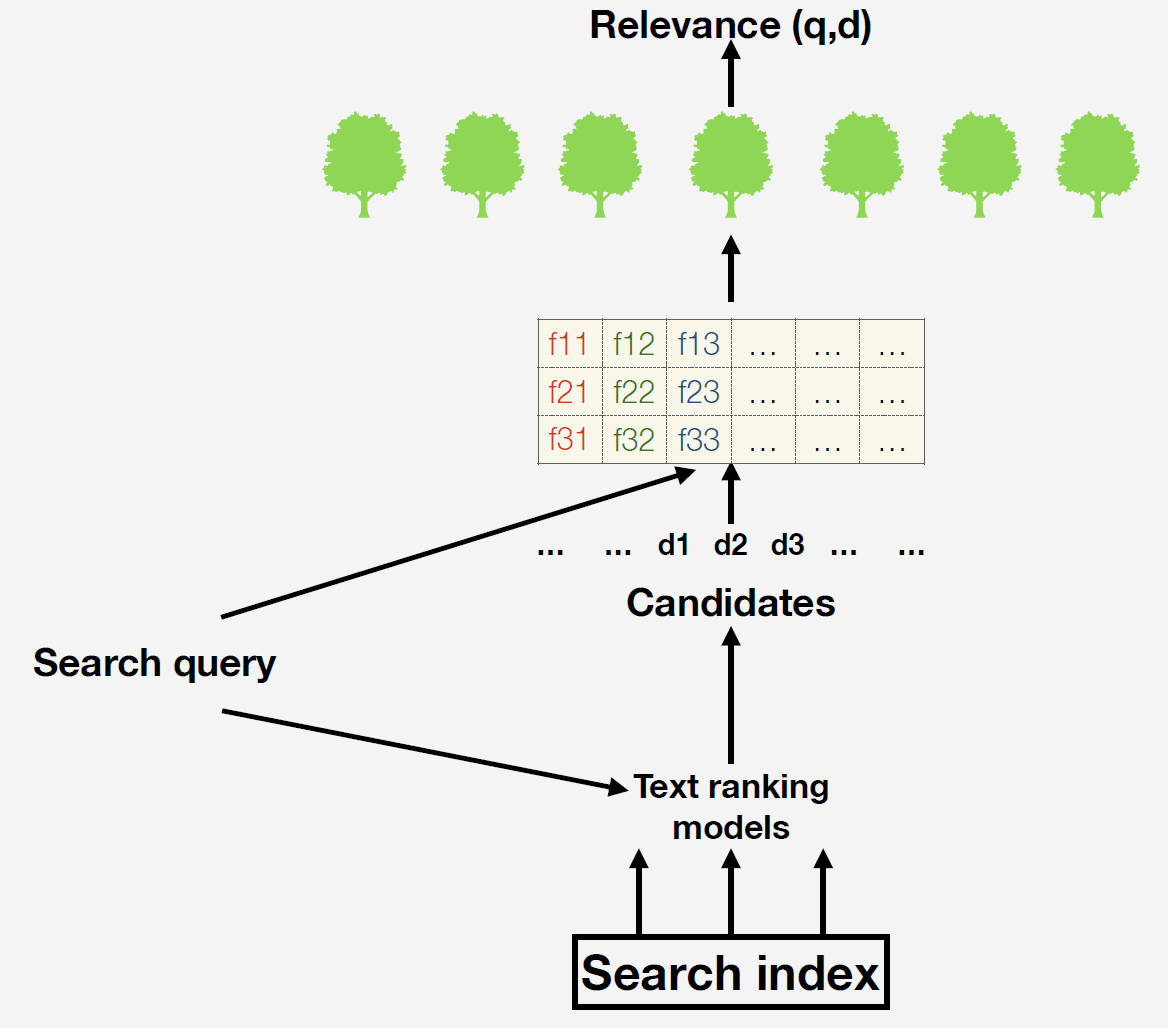
We have a search index - this is a database of many billions of documents. When a request arrives, we first generate a list of candidates for final ranking using simple text models. The easiest option is to pick up documents that, in principle, contain words from the request. Why is this step necessary? The fact is that it is impossible for all available documents to build signs and form forecasting of the final model. After we already calculate the signs. What signs can we take? For example, the number of occurrences of words from a query in a document or the number of clicks on a given document. You can use complex machine-trained factors: we in the Search using neural networks predict the relevance of the document on demand and insert this forecast with a new column in our feature space.
Why are we doing all this? We want to maximize user metrics so that users find relevant results in our results as easily as possible and return to us as often as possible.
Our final model uses an ensemble of decision trees built using gradient boosting. There are two options for building a target metric for training:
There are three approaches to solving the ranking problem:
Which approach is better to use for our target variable? To do this, it is worth discussing an important question: “can clicks be used as a measure of the absolute relevance of a document?”. It is impossible, because they depend on the position of the document in the issue. After receiving the issue, you most likely click on the document that will be higher, because it seems to you that the first documents are more relevant.
How can one test such a hypothesis? We take two documents in the top of the issue and swap them. If clicks were an absolute measure of relevance, then their number would depend only on the document itself, and not on the position. But this is not so. The document above always gets more clicks. Therefore, clicks can never be used as a measure of absolute relevance. Therefore, you can use either pairwise or listwise.
Now we extract the data for the training set. We had this session:

Of the four documents, there was a click on the second and fourth. As a rule, people watch results from top to bottom. You looked at the first document, you did not like it, clicked on the second. Then they returned to the search, looked at the third and clicked on the fourth. Obviously, you liked the second more than the first, and the fourth more than the first and third. These are the pairs we generate for all queries and we use models for training.
Everything seems to be fine, but there is one problem: people only click on documents from the very top of the issue. Therefore, if you make the training sample in this way only, then the distribution in it will be exactly the same as in the test sample. It is necessary to somehow align the distribution. We do this by adding negative examples: these are documents that were at the bottom of the ranking, the user definitely did not see them, but we know that they are bad.

So, we got such a scheme for ranking training: they showed users the results, collected clicks from them, added negative examples to align the distribution, and retrained the ranking model. Thus, we take into account the reaction of users to your current ranking, take errors into account and improve the ranking. We repeat these procedures many times until convergence. It is important to note that we search not only by the web, but also by video, by pictures, and the described scheme works fine in any type of search. As a result, behavioral metrics grow very much. In the second iteration, it is slightly smaller, in the third iteration it is even smaller, and as a result converges to a local optimum.
Let's think about why we converge at a local optimum, and not at a global optimum.
Suppose you are a football fan and in the evening did not have time to watch the match of your favorite team. Wake up in the morning and enter the name of the team in the search bar to find out the result of the match. See the first three documents - these are the official pages about the club, there is no useful information. You will not leaf through the entire issue, will not pick up another request. Perhaps you even click on some irrelevant document. But as a result, get upset, close the SERP and open another search engine.

Although this problem is not only found in the search, it is especially relevant here. Imagine an online store, which is one big tape without the ability to say which category of products you want to see. This is exactly what happens with the search results: after sending the request, you can no longer explain what you really need: information about the football team or the score of the last match.
Imagine that some brutal man went to such a strange online store, consisting of one tape of recommendations, and in his recommendations he sees only typically female goods. Perhaps he even clicks on some dress, because it is worn on a beautiful girl. We will send this click to the training set and decide that the man likes this dress more than sponge. When he comes back into our system, he will already see some dresses. Initially, we did not have products that were valid for the user, so this approach will not allow us to correct this error. We were in a local optimum in which the poor person can no longer tell us that he does not like either sponges or dresses. Often this problem is called the positive feedback problem.
How to make a search engine better? How to get out of a local optimum? New factors need to be added. Suppose we made a very good factor that, upon request with the name of the football team, will raise a relevant document, that is, the results of the last match. What could be the problem here? If you train the model on old data, on offline data, then take the old dataset with clicks and add this attribute there. It may be relevant, but you have not used it in the ranking before, and therefore people did not click on those documents for which this attribute is good. It does not correlate with your target variable, so it simply will not be used by the model.
In such cases, we often use this solution: bypassing the final model, we force our ranking to use this feature. We forcibly show the result of the last match upon request with the name of the team, and if the user clicked on it, then for us this is the information that allows us to understand that the sign is good.
Let's look at an example. Recently we made beautiful pictures for Instagram documents:

It seems that such beautiful pictures should satisfy our users as much as possible. Obviously, we need to make a sign that the document has such a picture. We add to the dataset, retrain the ranking model and see how this feature is used. And then we analyze the change in behavioral metrics. They have improved a bit, but is this the best solution?
No, because for many requests you do not show beautiful pictures. You did not give the user the opportunity to show how he likes them. To solve this problem, we, for some requests that involve showing Instagram documents, forcibly bypassing the model showed beautiful pictures and looked whether they clicked on them. As soon as users appreciated the innovation, they began to retrain the model on datasets, in which users had the opportunity to show the importance of this factor. After this procedure, on a new dataset, the factor began to be used many times more often and significantly increased user metrics.
So, we examined the statement of the ranking problem and discussed the pitfalls that will await you when learning feedback from users. The main thing that you should take out of this article: using feedback as a training target, remember that the user can leave this feedback only where the current model allows him. Such feedback can play a trick on you when trying to build a new machine learning model.
Ranking task
What is meant by ranking task? Imagine that in the training sample there are some set of queries for which the order of documents by relevance is known. For example, you know which document is the most relevant, which is the second most relevant, etc. And you need to restore this order for the entire population. That is, for all requests from the general population, put the most relevant document in the first place, and the most irrelevant in the last.
Let's see how such problems are solved in large search engines.
')
We have a search index - this is a database of many billions of documents. When a request arrives, we first generate a list of candidates for final ranking using simple text models. The easiest option is to pick up documents that, in principle, contain words from the request. Why is this step necessary? The fact is that it is impossible for all available documents to build signs and form forecasting of the final model. After we already calculate the signs. What signs can we take? For example, the number of occurrences of words from a query in a document or the number of clicks on a given document. You can use complex machine-trained factors: we in the Search using neural networks predict the relevance of the document on demand and insert this forecast with a new column in our feature space.
Why are we doing all this? We want to maximize user metrics so that users find relevant results in our results as easily as possible and return to us as often as possible.
Our final model uses an ensemble of decision trees built using gradient boosting. There are two options for building a target metric for training:
- We create a department of assessors - specially trained people to whom we give inquiries and say: "Guys, evaluate how relevant our issuance is." They will respond with numbers that measure relevancy. Why is this approach bad? In this case, we will maximize the model with respect to the opinions of people who are not our users. We will not optimize for the metric that we really want to optimize.
- For this reason, we use the second approach for the target variable: we show users the results, look at which documents they pass to, which ones skip. And then we use this data to train the final model.
How is the ranking problem solved?
There are three approaches to solving the ranking problem:
- Pointwise , it is pointwise. We will consider relevance as an absolute measure and will fine the model for the absolute difference between the predicted relevance and the one we know from the training sample. For example, the assessor gave the document a rating of 3, and we would say 2, so we fine the model by 1.
- Pairwise , pairwise. We will compare documents with each other. For example, in the training sample there are two documents, and we know which one is more relevant for this request. Then we will fine the model if it puts the forecast lower than the less relevant one, that is, the pair is incorrectly arranged.
- Listwise . It is also based on relative relevance, but not inside the pairs: we rank the entire issue by the model and evaluate the result - if the most relevant document is not in the first place, we get a large fine.
Which approach is better to use for our target variable? To do this, it is worth discussing an important question: “can clicks be used as a measure of the absolute relevance of a document?”. It is impossible, because they depend on the position of the document in the issue. After receiving the issue, you most likely click on the document that will be higher, because it seems to you that the first documents are more relevant.
How can one test such a hypothesis? We take two documents in the top of the issue and swap them. If clicks were an absolute measure of relevance, then their number would depend only on the document itself, and not on the position. But this is not so. The document above always gets more clicks. Therefore, clicks can never be used as a measure of absolute relevance. Therefore, you can use either pairwise or listwise.
We collect a dataset
Now we extract the data for the training set. We had this session:
Of the four documents, there was a click on the second and fourth. As a rule, people watch results from top to bottom. You looked at the first document, you did not like it, clicked on the second. Then they returned to the search, looked at the third and clicked on the fourth. Obviously, you liked the second more than the first, and the fourth more than the first and third. These are the pairs we generate for all queries and we use models for training.
Everything seems to be fine, but there is one problem: people only click on documents from the very top of the issue. Therefore, if you make the training sample in this way only, then the distribution in it will be exactly the same as in the test sample. It is necessary to somehow align the distribution. We do this by adding negative examples: these are documents that were at the bottom of the ranking, the user definitely did not see them, but we know that they are bad.
So, we got such a scheme for ranking training: they showed users the results, collected clicks from them, added negative examples to align the distribution, and retrained the ranking model. Thus, we take into account the reaction of users to your current ranking, take errors into account and improve the ranking. We repeat these procedures many times until convergence. It is important to note that we search not only by the web, but also by video, by pictures, and the described scheme works fine in any type of search. As a result, behavioral metrics grow very much. In the second iteration, it is slightly smaller, in the third iteration it is even smaller, and as a result converges to a local optimum.
Let's think about why we converge at a local optimum, and not at a global optimum.
Suppose you are a football fan and in the evening did not have time to watch the match of your favorite team. Wake up in the morning and enter the name of the team in the search bar to find out the result of the match. See the first three documents - these are the official pages about the club, there is no useful information. You will not leaf through the entire issue, will not pick up another request. Perhaps you even click on some irrelevant document. But as a result, get upset, close the SERP and open another search engine.
Although this problem is not only found in the search, it is especially relevant here. Imagine an online store, which is one big tape without the ability to say which category of products you want to see. This is exactly what happens with the search results: after sending the request, you can no longer explain what you really need: information about the football team or the score of the last match.
Imagine that some brutal man went to such a strange online store, consisting of one tape of recommendations, and in his recommendations he sees only typically female goods. Perhaps he even clicks on some dress, because it is worn on a beautiful girl. We will send this click to the training set and decide that the man likes this dress more than sponge. When he comes back into our system, he will already see some dresses. Initially, we did not have products that were valid for the user, so this approach will not allow us to correct this error. We were in a local optimum in which the poor person can no longer tell us that he does not like either sponges or dresses. Often this problem is called the positive feedback problem.
Further improvement
How to make a search engine better? How to get out of a local optimum? New factors need to be added. Suppose we made a very good factor that, upon request with the name of the football team, will raise a relevant document, that is, the results of the last match. What could be the problem here? If you train the model on old data, on offline data, then take the old dataset with clicks and add this attribute there. It may be relevant, but you have not used it in the ranking before, and therefore people did not click on those documents for which this attribute is good. It does not correlate with your target variable, so it simply will not be used by the model.
In such cases, we often use this solution: bypassing the final model, we force our ranking to use this feature. We forcibly show the result of the last match upon request with the name of the team, and if the user clicked on it, then for us this is the information that allows us to understand that the sign is good.
Let's look at an example. Recently we made beautiful pictures for Instagram documents:
It seems that such beautiful pictures should satisfy our users as much as possible. Obviously, we need to make a sign that the document has such a picture. We add to the dataset, retrain the ranking model and see how this feature is used. And then we analyze the change in behavioral metrics. They have improved a bit, but is this the best solution?
No, because for many requests you do not show beautiful pictures. You did not give the user the opportunity to show how he likes them. To solve this problem, we, for some requests that involve showing Instagram documents, forcibly bypassing the model showed beautiful pictures and looked whether they clicked on them. As soon as users appreciated the innovation, they began to retrain the model on datasets, in which users had the opportunity to show the importance of this factor. After this procedure, on a new dataset, the factor began to be used many times more often and significantly increased user metrics.
So, we examined the statement of the ranking problem and discussed the pitfalls that will await you when learning feedback from users. The main thing that you should take out of this article: using feedback as a training target, remember that the user can leave this feedback only where the current model allows him. Such feedback can play a trick on you when trying to build a new machine learning model.
Source: https://habr.com/ru/post/461927/
All Articles