Mysterious adversary: fuzzy borrowing
Illegal Borrowing is a multi-headed hydra, an enemy who is constantly changing his face. Our best private investigators are ready to cling to any crime committed by this enemy. However, the enemy does not sleep, he is cunning and treacherous: obviously substituting in one thing, he incredibly skillfully sweeps traces in others. Sometimes he manages to catch red-handed with the help of our most nimble employee - Suffix Massiv . Sometimes the enemy hesitates, and the meticulous, but unhurried Search for Paraphrase manages to calculate its location. But evil is insidious, and we constantly need new forces to fight it .
Today we will talk about our new special-purpose detective named Fuzzy Search , as well as his first encounter with fuzzy borrowings.
With you detective agency Antiplagiarism , get ready for the Mysterious Opponent Case

Image Source: pxhere.com
Scene
When checking the area (document), the Anti-Plagiarism checks if there are any calls about a possible crime in the area. The eyewitnesses who will signal us about the crime are the Shingles Index .
"A shingle is a piece of text a few words in size." Each such piece is hashed, and documents that have shingles with the same hashes as in the document being checked are searched in the index.
An eyewitness, seeing a coincidence in the hash of two shingles, calls us with a message about the crime. Unfortunately, the shingles index cannot be punished for a false call, it is immune to sanctions, which is why there are a lot of calls. The agency determines the documents with the largest accumulation of such calls - the scene of a potential crime.
First clue
Now you're a detective, son.
From now on you are forbidden to believe in coincidences.
© “The Dark Knight: Revival of the Legend” (“The Dark Knight Rises”, dir. K. Nolan, 2012).
')
Detective Fuzzy Search arrived at the crime scene. Large enough criminals do not go unnoticed, because the larger the scale of the crime, the more likely it is to leave a clue. For Fuzzy Search, such leads are short matches of a fixed length. It seems that our detective is missing a large share of skillfully sweeping traces of criminals, but only 5% of attackers do not leave such a clue. It is important not to lose the criminals, so the detective quickly scans the area using a special technique for detecting matches.
A detective’s diary on the working method. First stage
We use two features of the task:
- We are interested in clear duplicates of a fixed length.
- In a good document, the same shingle is not duplicated too many times.
The second condition is necessary to limit the number of clear duplicates found. Indeed, a single that occurs 1000 times in the document and in the source will give 1,000,000 pairs of matches. Such frequently repeated shingles can only be seen in uncleaned documents with crawl attempts.
A document cleared of crawls is presented as a sequence of words. We bring the words to a normal word form, then hash them. We get a sequence of integers (on the gif - a sequence of letters). All shingles of this sequence are hashed and entered into the hash table with the value of the position of the beginning of the substring. Then, for each shingle in the candidate document, matches are found in the hash table. This creates clear duplicates of a fixed length. Tests show triple acceleration when using the new method in comparison with the suffix array.
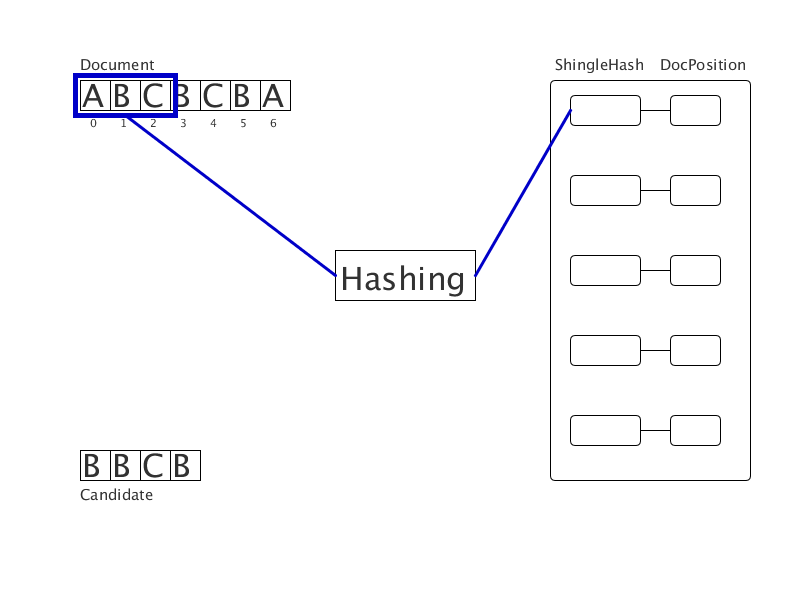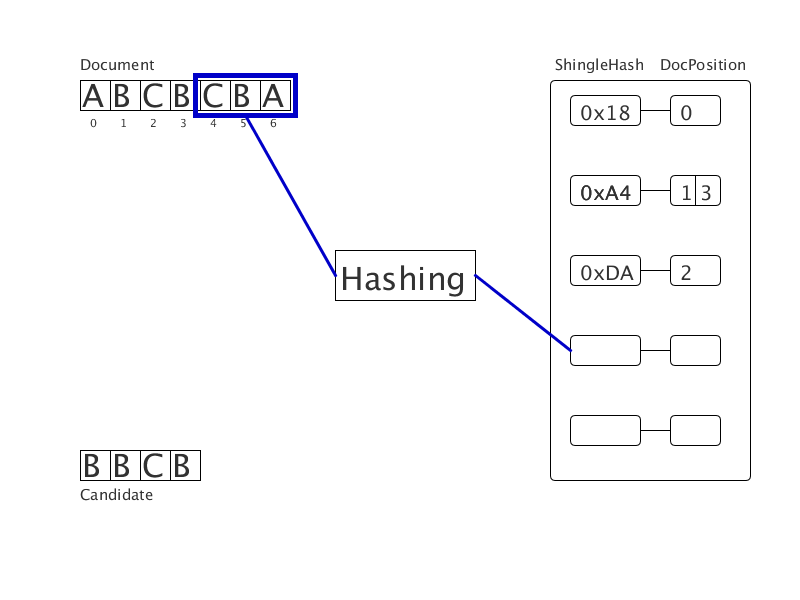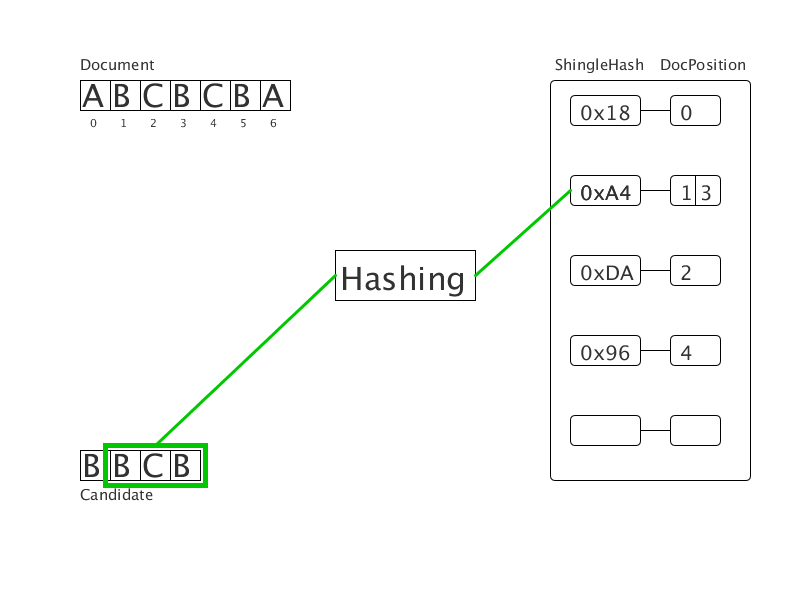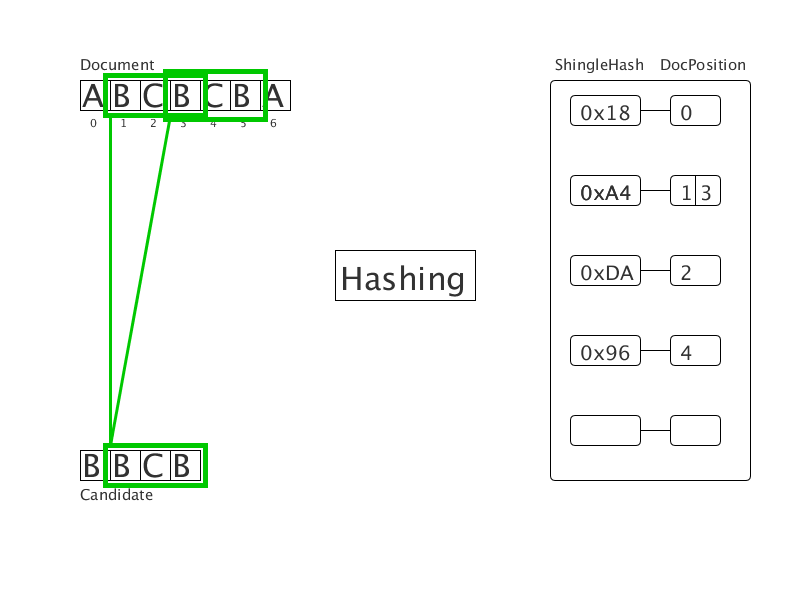
We calculate the criminal
- Are there any other points that you would advise me to pay attention to?
“The dog’s strange behavior on the night of the crime.”
- Dogs? But she did not behave in any way!
“That's strange,” said Holmes.
© Arthur Conan-Doyle, “Silver” (from the series “Notes on Sherlock Holmes”)
So, Fuzzy Search found several clues by which to identify criminals. Our hero uses his deductive abilities to the fullest, so that bit by bit, he will gradually restore the image of the criminal by the found clues. The detective is gradually expanding the picture of what is happening, supplementing it with new details, discovering more and more evidence until this picture finally becomes complete. Our detective is sometimes brought in, and he has to be lowered from heaven to earth and convinced that we need the identity of the criminal, and not the biography of his cousin. Fuzzy Search grumbles, but humbly narrows the picture to the desired scale.
A detective’s diary on the working method Second phase

Image Source: pixabay.com
The second stage distributes duplicates left and right across the document. Distribution comes from the “centers” - clear duplicates found. To compare the suffixes, we use the Levenshtein distance - the minimum number of deletions / replacements / insertions of words necessary to bring one line to another. The distance can be calculated dynamically for duplicate suffixes using the Wagner-Fisher algorithm , based on the recursive determination of the Levenshtein distance. However, this algorithm is quadratic in complexity and does not allow controlling the proportion of errors. Another problem is the exact definition of the boundaries of duplicates. To address these issues, we use several straightforward, but nonetheless effective procedures.
At this step, it is proposed first to sequentially fill in the Levenshtein Distance Matrix for fuzzy duplicate suffixes (then, similarly, for prefixes). Since we check suffixes for “similarity”, we are only interested in values near the diagonal of this matrix (Levenshtein distance is greater than or equal to the difference in the lengths of the lines). This allows for linear complexity. Having set the maximum allowable Levenshtein distance, we will fill in the table until we meet a column with values greater than the permissible ones. Such a column indicates that our fuzzy duplicate has recently ended and the words almost completely ceased to coincide. Having saved the previous optimal one for each filled cell, we descend from the cell with a minimum penalty in the critical column until we find several matches, after which the error began to increase sharply. These will be the boundaries of the found fuzzy duplicate.
Additionally, so that errors do not accumulate, a procedure is introduced that resets the number of errors, starting propagation again if we stumbled upon an “island” from successive coincidences.
Gang of criminals
- Tomorrow we plan to get together with classmates!
- In one big classmate?
- What?
© Bashorg
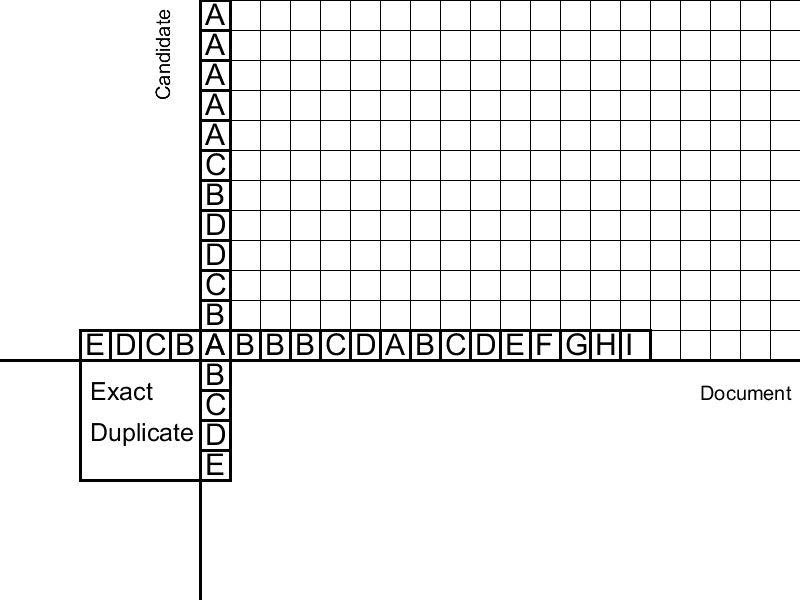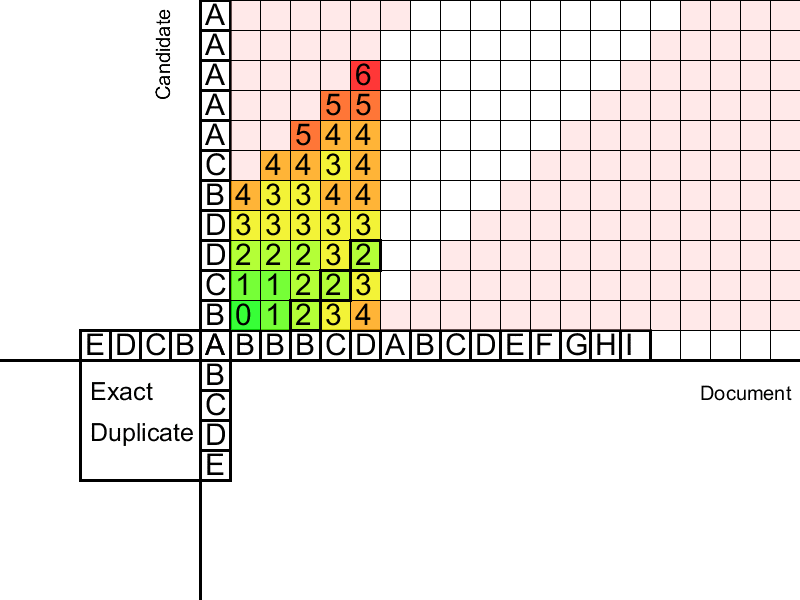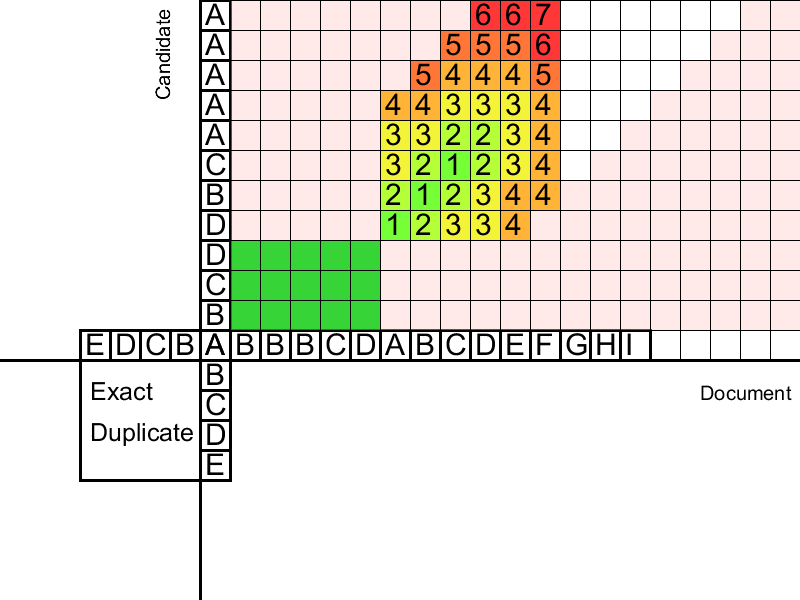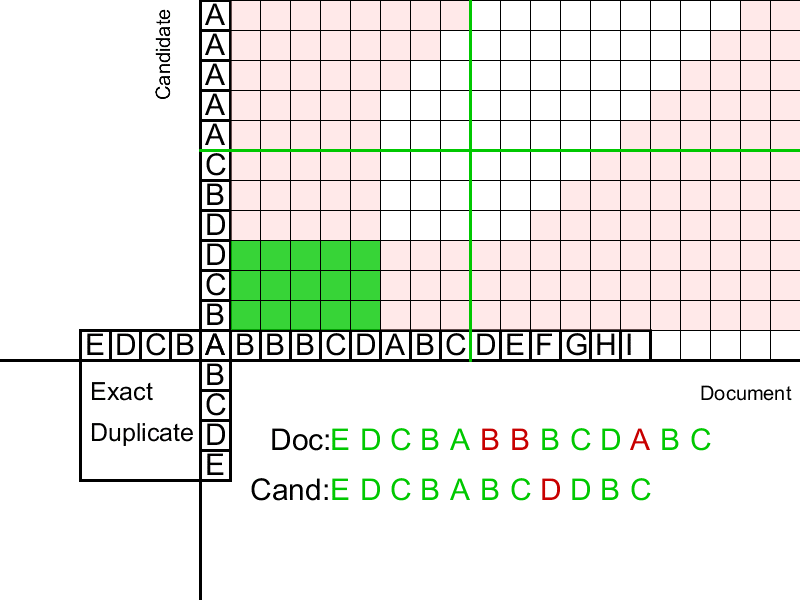
The fuzzy Search has remained a simple task: to unite the criminals caught in the same place into gangs, to justify the innocent suspects and to collect the results together.

Image Source: pixabay.com
Gluing duplicates immediately solves 3 problems. Firstly, the second stage of “distribution of duplicates” absorbs modifications of words and phrases, but not whole sentences. If you increase the "spreading ability" of the algorithm, then it will begin to spread over coincidences found at too great a distance, and the boundaries of duplicates will be determined worse. So we lose the Precision so important to us, which a clear search had.
Secondly, the second stage does not recognize the permutation of two duplicates. I would like the permutation of the two sentences in some places to form a phrase close to the original, but for a line of unique characters, the permutation of the prefix and suffix in some places leads to the line that is as far as possible from the original (in the Levenshtein metric). It turns out that the second stage, when rearranging the sentences, finds two duplicates located next to each other that you want to combine into one.
And the third reason is Granularity, or Granularity. Granularity is a metric that determines the average number of duplicates found in one true loan that we found. In other words, granularity shows how well we find the entire borrowing instead of the few parts covering it. The formal definition of granularity, as well as the determination of micro-averaged accuracy and completeness, can be found in the article “An evaluation framework for plagiarism detection” .
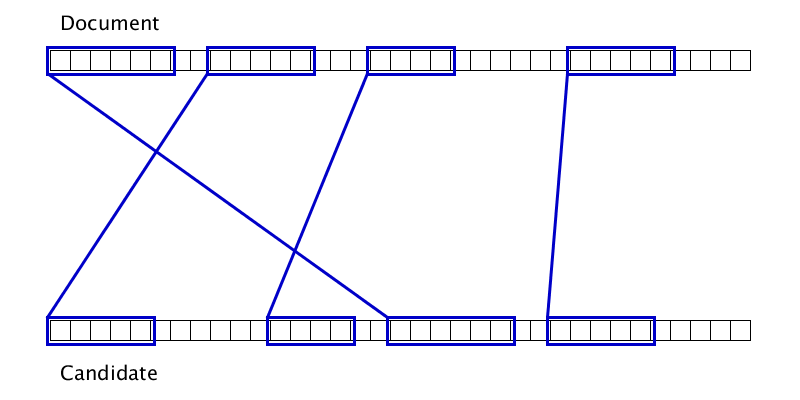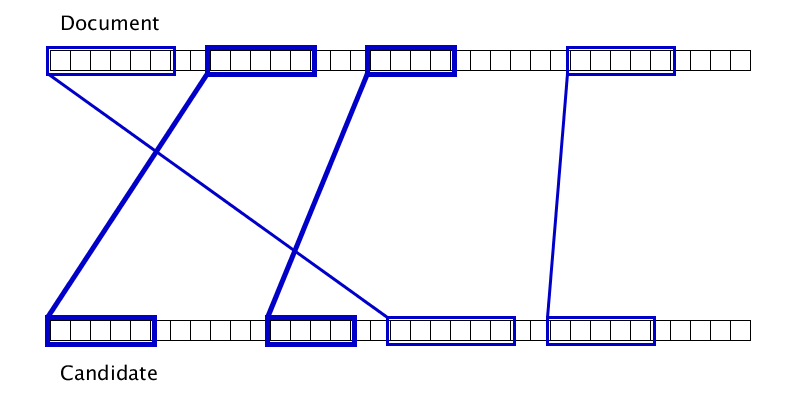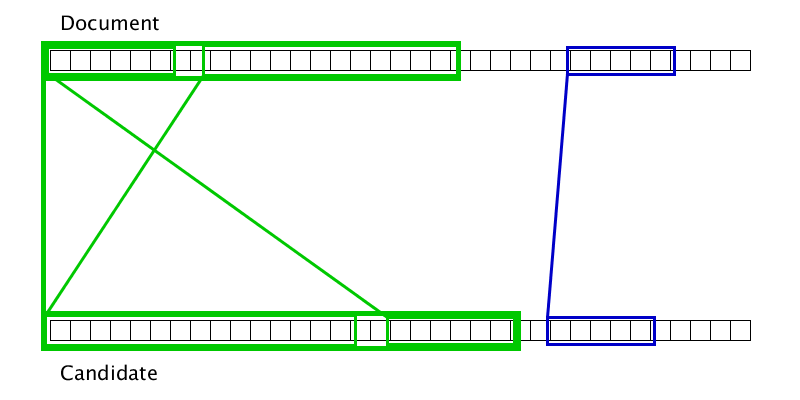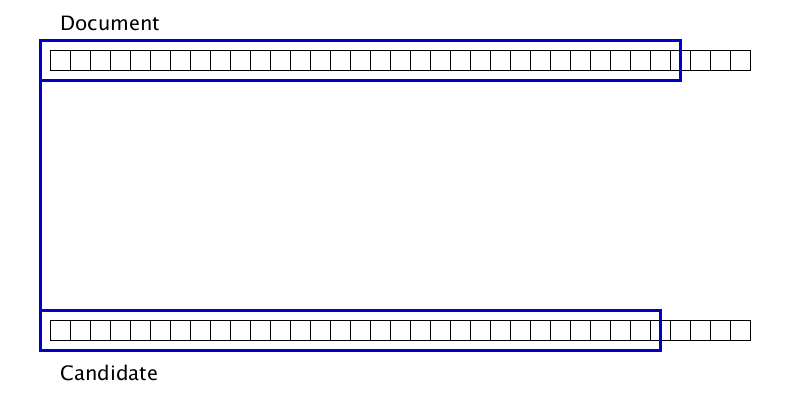
Gifka shows that sometimes two duplicates can be glued only after one of them adheres to the third duplicate. Accordingly, just one pass from left to right on the document does not work to complete gluing.
The list of duplicates at the input is sorted by the left border in the document.
We are trying to glue the current duplicate with several of the closest candidates in front of it.
If it turns out, try to glue it again, if not, go to the next duplicate.
Since the number of duplicates is no more than the length of the document, and each double-check reduces the number of duplicates by 1 and is performed in constant time, the complexity of this algorithm is O (n).
A set of several parameters is used as a rule for gluing duplicates, but if we forget about microoptimization of quality, then we will glue those duplicates for which the maximum of the distances in the document and source is quite small.
The gluing locality provides O (1) duplicates, to which the current duplicate can be glued.
Beginner Training
The detective needed to adapt to the features of our town, adapt to the area, walk along the inconspicuous streets and get to know better its inhabitants. For this, a beginner takes a special training course in which he studies similar situations at a training ground. The detective in practice studies the clues, deduction and the construction of social ties for the most effective capture of criminals.
The parametric model needed to be optimized. To determine the optimal model parameters, the PlagEvalRus sample was used .
The sample is divided into 4 collections:
- Generated_Copypast (4250 pairs) - verbatim generated borrowings
- Generated_Paraphrased (4250 pairs) - weakly and medium-modified borrowings generated by the machine using the noise of the original passages (arbitrary replacements / deletions / inserts)
- Manually_Paraphrased (713 pairs) Hand-written texts with various types of borrowings, mostly weak and medium-modified borrowings (replaced by no more than 30% of the words in the duplicate)
- Manually_Paraphrased 2 (198 pairs) Hand-written texts with medium and highly modified (more than 30% words) borrowings
- DEL - Delete individual words (up to 20%) from the original sentence.
- ADD - Add single words (up to 20%) to the original sentence.
- LPR - Change of forms (change in the number, case, form and tense of a verb, etc.) of individual words (up to 30%) of the original sentence.
- SHF - Changing the order of words or parts of a sentence (turns, parts of a simple sentence as part of a complex) without significant changes “inside” the rearranged parts.
- CCT - Glue two or more sentences of the source text into one sentence.
- SEP / SSP - Splitting the initial complex sentence into two or more independent sentences (possibly with a change in the order of their sequence in the text).
- SYN - Replacing individual words or individual terms with synonyms (for example, “salt” - “sodium chloride”), replacing abbreviations with their full decipherments and vice versa, revealing the initials of your full name and vice versa, replacing your first name with initials, etc.
- HPR - Strong processing of the original sentence, which is a combination of many (3-5 or more) types of text modification above. The same type assumes a strong change in the source text by periphrase using idiomatic expressions, complex synonymous constructions, permutation of words or parts of a complex sentence, etc. tricks that together make it difficult to determine the correspondence between the original source and the altered text.
The search for the optimal model parameters was carried out using the multi-start descent method. Maximized measure with (emphasis on accuracy). Here are the most significant optimal parameters.
| Model parameter | Description | Manually_Paraphrased (stricter model) | Manually_Paraphrased 2 (less strict model) |
|---|---|---|---|
| MinExactCiteLength | Clear duplicate length for stage 1 | five | 3 |
| MinSymbolCiteLength | The minimum length of the final quote in characters | 70 | 95 |
| Limit | Maximum allowable Levenshtein distance | five | ten |
| MinExpandLength | Amount of coincidence to nullify the distribution penalty | 2 | 2 |
| Glue distance | Spacing in words for gluing duplicates | eleven | 29th |
| MinWordLength | The minimum length of the final quote in words | ten | eleven |
Case Open Statistics
The trial period of our Fuzzy Search has come to an end. Let's compare its productivity with that of another detective, Suffix Array. Training course Fuzzy Search took place on the program Manually_Paraphrased.

In the field, the newcomer showed a significant superiority in the proportion of cases solved. The speed of his work also can not but rejoice. Our agency lacked such a valuable employee.
Comparing the quality of the model with the suffix array, we notice a significant improvement in granularity, as well as better detection of medium and highly modified borrowings.
| Manually_Paraphrased | Manually_Paraphrased 2 | |
|---|---|---|
| Quality |
|
|
Testing on documents up to 10 7 words in size, we verify the linearity of both algorithms. On the i5-4460 processor, the program processes a pair of "document source" a million words long in less than a second.

Having generated texts with a large number of borrowings, we are convinced that the fuzzy search (blue line) is not slower than the suffix array (red line). Conversely, a suffix array suffers on large documents from too many duplicates. We compared performance with a minimum duplicate length of 5 words. But for sufficient borrowing coverage, we use a clear search with a minimum duplicate length of 3 words, which on giant documents leads to a significant drop in productivity (orange line). It is worth noting that ordinary documents contain less borrowing, and in practice this effect is much less pronounced. But such an experiment allows us to understand the expansion of the applicability of the models with a new fuzzy search.
Examples:
| Original | Borrowing |
|---|---|
| "For combining fascinating stories with an analysis of human nature" in 2014, he received a well-deserved award - US National Medal in the Arts | In 2014, awarded the United States National Medal of Arts with the wording “For combining fascinating stories with an analysis of human nature” |
| the culture of totalitarianism where all dissent was suppressed. To build socialism, the following tasks were set: literacy, the creation of a system of higher education institutions, training | The culture of totalitarianism is taking shape. Any dissent was suppressed. To achieve the main goal of building socialism, the following tasks were posed: 1. The cultural revolution, including the elimination of illiteracy, the creation of a giant system of universities; Research institutes, libraries, theaters, training |
It can be seen that the algorithm, despite the small computational complexity, copes with the detection of replacements / deletions / insertions, and the third step allows you to detect borrowings with the permutation of sentences and their parts.
Epilogue
Fuzzy Search works in a team with our other tools: Quick Search for Candidate Documents, Extraction of Document Formatting, Large-scale Catching of Bypass Attempts. This command allows you to quickly find potential plagiarism. Fuzzy Search has taken root in this team and performs its search functions more qualitatively, and, importantly, faster than the Suffix Array did. Our agency will cope even better with its tasks, and unscrupulous authors will encounter new problems when using non-original text .
Create with your own mind!
Source: https://habr.com/ru/post/461903/
All Articles