How pod priorities at Kubernetes caused downtime at Grafana Labs
Note perev. : We present to your attention technical details about the reasons for the recent outage in the cloud service, served by the creators of Grafana. This is a classic example of how a new and seemingly extremely useful feature designed to improve the quality of infrastructure ... can do much harm if one does not foresee the numerous nuances of its application in the realities of production. It is wonderful when such materials appear that allow you to learn not only from your mistakes. Details are in the translation of this text from the vice president of product from Grafana Labs.

On Friday, July 19, the Hosted Prometheus service at Grafana Cloud stopped working for about 30 minutes. I apologize to all the customers who suffered from the failure. Our task is to provide the necessary tools for monitoring, and we understand that their inaccessibility complicates your life. We take this incident very seriously. This note explains what happened, how we reacted to it, and what we are doing so that this does not happen again.
')
The Grafana Cloud Hosted Prometheus service is based on Cortex , a CNCF project to create a horizontally scalable, highly accessible, multi-tenant Prometheus service. The Cortex architecture consists of a set of separate microservices, each of which performs its function: replication, storage, requests, etc. Cortex is being actively developed, it is constantly having new opportunities and improving productivity. We regularly deploy new Cortex releases to clusters so that customers can take advantage of these opportunities - fortunately, Cortex can update without downtime.
For smooth updates, Ingester Cortex's service requires an additional Ingester replica during the update process. ( Note : Ingester is the core component of Cortex. Its task is to collect a constant stream of samples, group them into chunks of Prometheus and store them in a database like DynamoDB, BigTable or Cassandra.) This allows older Ingesters. forward current data to new Ingesters. It is worth noting that Ingesters are demanding on resources. For their work it is necessary to have 4 cores and 15 GB of memory per pod, i.e. 25% of the processor power and memory of the base machine in the case of our Kubernetes clusters. In general, we usually have much more unused resources in the cluster than 4 cores and 15 GB of memory, so we can easily run these additional Ingesters during updates.
However, it often happens that during normal operation none of the machines has these 25% of unclaimed resources. Yes, we do not strive: CPU and memory are always useful for other processes. To solve this problem, we decided to use Kubernetes Pod Priorities . The idea is to give Ingesters a higher priority than other (stateless) microservices. When we need to run an additional (N + 1) Ingester, we temporarily force out other, smaller pods. These pods are transferred to free resources on other machines, leaving a sufficiently large “hole” for launching an additional Ingester.
On Thursday, July 18, we launched four new priority levels in our clusters: critical , high , medium and low . They were tested on an internal cluster without client traffic for about one week. By default, pods without a given priority received a medium priority; a high priority class was set for Ingesters. Critical was reserved for monitoring (Prometheus, Alertmanager, node-exporter, kube-state-metrics, etc.). Our config is open, and see PR here .
On Friday, July 19, one of the engineers launched a new dedicated Cortex cluster for a large client. The config for this cluster did not include new pod priorities, so all new pods were assigned the default priority - medium .
The Kubernetes cluster did not have enough resources for the new Cortex cluster, and the existing Cortex production cluster was not updated (Ingesters were left without a high priority). Since the Ingesters of the new cluster defaulted to medium priority, and the existing pods in production worked without priority at all, the Ingesters of the new cluster drove Ingesters out of the existing Cortex production cluster.
ReplicaSet for the preempted Ingester in the production cluster detected the preempted pod and created a new one to maintain the specified number of copies. The new pod was set to medium priority by default, and the next "old" Ingester in production lost resources. The result was an avalanche-like process that led to crowding out all pods from Ingester for Cortex production clusters.
Ingesters keep stateful and store data for the previous 12 hours. This allows us to compress them more efficiently before writing to long-term storage. To do this, Cortex shards series data using a Distributed Hash Table (DHT), and replicates each series to three Ingesters using Dynamo-style quorum consistency. Cortex does not write data to Ingesters, which are disabled. Thus, when a large number of Ingesters leave DHT, Cortex cannot provide sufficient replication of the records, and they “fall”.
New Prometheus notifications based on the " error-budget-based " (details appear in a future article) began to sound an alarm 4 minutes after the start of the shutdown. Over the next five minutes, we performed diagnostics and expanded the underlying Kubernetes cluster to accommodate both new and existing production clusters.
Five minutes later, the old Ingesters successfully recorded their data, and the new ones started up, and the Cortex clusters became available again.
It took another 10 minutes to diagnose and fix out-of-memory (OOM) errors from reverse authentication proxies located in front of Cortex. OOM errors were caused by a tenfold increase in QPS (as we believe, due to excessively aggressive requests from Prometheus client servers).
The total downtime was 26 minutes. No data was lost. Ingesters successfully uploaded all in-memory data to long-term storage. During a shutdown, the Prometheus client servers buffered the entries using the new WAL-based remote_write API (authored by Callum Styan from Grafana Labs) and repeated failed entries after the failure.
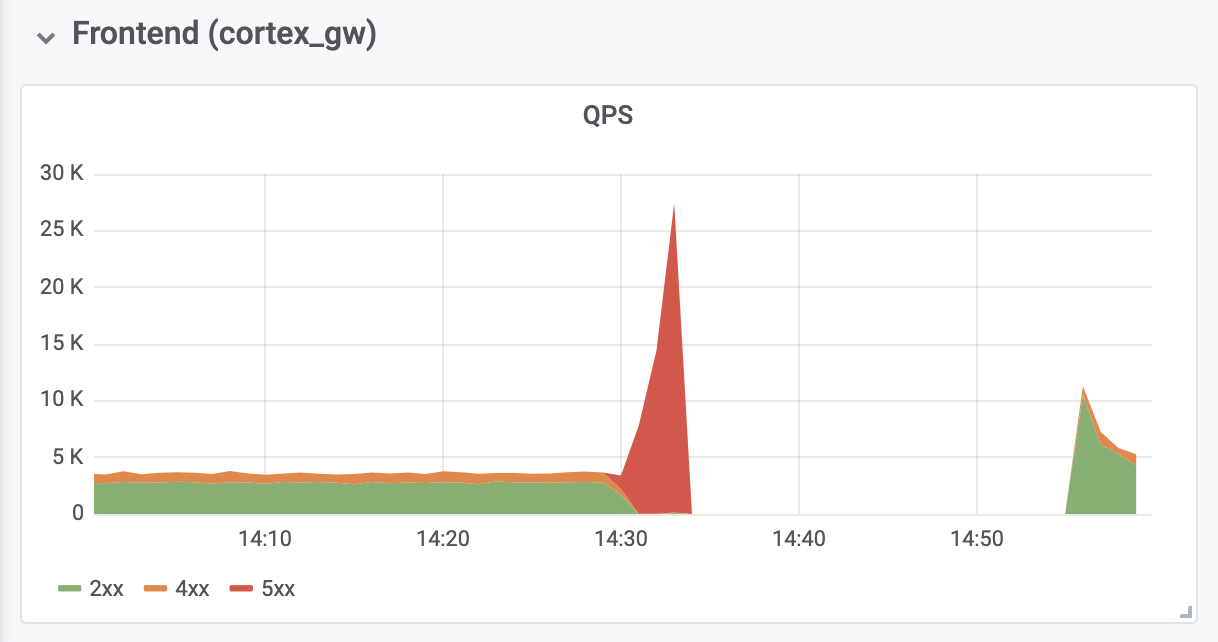
Production Cluster Write Operations
It is important to learn from this incident and take the necessary steps to avoid a recurrence.
Looking back, we must admit that we should not set the default medium priority, until all Ingesters in production received a high priority. In addition, they should have taken care of their high priority in advance. Now everything is fixed. We hope that our experience will help other organizations considering the use of pod priorities in Kubernetes.
We will add an additional level of control over the deployment of any additional objects whose configurations are global for the cluster. Henceforth, such changes will be evaluated by more people. In addition, the modification that led to the failure was considered too insignificant for a separate project document - it was discussed only in the GitHub issue. From now on, all such configuration changes will be accompanied by the corresponding project documentation.
Finally, we automate the resizing of the reverse authentication proxy to prevent OOM during congestion, which we have witnessed, and analyze the default Prometheus settings related to rollback and scaling to prevent similar problems in the future.
The experienced failure also had some positive consequences: after receiving the necessary resources, Cortex automatically recovered without any additional intervention. We also gained valuable experience with Grafana Loki , our new log aggregation system, which helped to ensure that all Ingesters behaved properly during and after the crash.
Read also in our blog:
On Friday, July 19, the Hosted Prometheus service at Grafana Cloud stopped working for about 30 minutes. I apologize to all the customers who suffered from the failure. Our task is to provide the necessary tools for monitoring, and we understand that their inaccessibility complicates your life. We take this incident very seriously. This note explains what happened, how we reacted to it, and what we are doing so that this does not happen again.
')
Background
The Grafana Cloud Hosted Prometheus service is based on Cortex , a CNCF project to create a horizontally scalable, highly accessible, multi-tenant Prometheus service. The Cortex architecture consists of a set of separate microservices, each of which performs its function: replication, storage, requests, etc. Cortex is being actively developed, it is constantly having new opportunities and improving productivity. We regularly deploy new Cortex releases to clusters so that customers can take advantage of these opportunities - fortunately, Cortex can update without downtime.
For smooth updates, Ingester Cortex's service requires an additional Ingester replica during the update process. ( Note : Ingester is the core component of Cortex. Its task is to collect a constant stream of samples, group them into chunks of Prometheus and store them in a database like DynamoDB, BigTable or Cassandra.) This allows older Ingesters. forward current data to new Ingesters. It is worth noting that Ingesters are demanding on resources. For their work it is necessary to have 4 cores and 15 GB of memory per pod, i.e. 25% of the processor power and memory of the base machine in the case of our Kubernetes clusters. In general, we usually have much more unused resources in the cluster than 4 cores and 15 GB of memory, so we can easily run these additional Ingesters during updates.
However, it often happens that during normal operation none of the machines has these 25% of unclaimed resources. Yes, we do not strive: CPU and memory are always useful for other processes. To solve this problem, we decided to use Kubernetes Pod Priorities . The idea is to give Ingesters a higher priority than other (stateless) microservices. When we need to run an additional (N + 1) Ingester, we temporarily force out other, smaller pods. These pods are transferred to free resources on other machines, leaving a sufficiently large “hole” for launching an additional Ingester.
On Thursday, July 18, we launched four new priority levels in our clusters: critical , high , medium and low . They were tested on an internal cluster without client traffic for about one week. By default, pods without a given priority received a medium priority; a high priority class was set for Ingesters. Critical was reserved for monitoring (Prometheus, Alertmanager, node-exporter, kube-state-metrics, etc.). Our config is open, and see PR here .
Crash
On Friday, July 19, one of the engineers launched a new dedicated Cortex cluster for a large client. The config for this cluster did not include new pod priorities, so all new pods were assigned the default priority - medium .
The Kubernetes cluster did not have enough resources for the new Cortex cluster, and the existing Cortex production cluster was not updated (Ingesters were left without a high priority). Since the Ingesters of the new cluster defaulted to medium priority, and the existing pods in production worked without priority at all, the Ingesters of the new cluster drove Ingesters out of the existing Cortex production cluster.
ReplicaSet for the preempted Ingester in the production cluster detected the preempted pod and created a new one to maintain the specified number of copies. The new pod was set to medium priority by default, and the next "old" Ingester in production lost resources. The result was an avalanche-like process that led to crowding out all pods from Ingester for Cortex production clusters.
Ingesters keep stateful and store data for the previous 12 hours. This allows us to compress them more efficiently before writing to long-term storage. To do this, Cortex shards series data using a Distributed Hash Table (DHT), and replicates each series to three Ingesters using Dynamo-style quorum consistency. Cortex does not write data to Ingesters, which are disabled. Thus, when a large number of Ingesters leave DHT, Cortex cannot provide sufficient replication of the records, and they “fall”.
Detection and elimination
New Prometheus notifications based on the " error-budget-based " (details appear in a future article) began to sound an alarm 4 minutes after the start of the shutdown. Over the next five minutes, we performed diagnostics and expanded the underlying Kubernetes cluster to accommodate both new and existing production clusters.
Five minutes later, the old Ingesters successfully recorded their data, and the new ones started up, and the Cortex clusters became available again.
It took another 10 minutes to diagnose and fix out-of-memory (OOM) errors from reverse authentication proxies located in front of Cortex. OOM errors were caused by a tenfold increase in QPS (as we believe, due to excessively aggressive requests from Prometheus client servers).
Effects
The total downtime was 26 minutes. No data was lost. Ingesters successfully uploaded all in-memory data to long-term storage. During a shutdown, the Prometheus client servers buffered the entries using the new WAL-based remote_write API (authored by Callum Styan from Grafana Labs) and repeated failed entries after the failure.
Production Cluster Write Operations
findings
It is important to learn from this incident and take the necessary steps to avoid a recurrence.
Looking back, we must admit that we should not set the default medium priority, until all Ingesters in production received a high priority. In addition, they should have taken care of their high priority in advance. Now everything is fixed. We hope that our experience will help other organizations considering the use of pod priorities in Kubernetes.
We will add an additional level of control over the deployment of any additional objects whose configurations are global for the cluster. Henceforth, such changes will be evaluated by more people. In addition, the modification that led to the failure was considered too insignificant for a separate project document - it was discussed only in the GitHub issue. From now on, all such configuration changes will be accompanied by the corresponding project documentation.
Finally, we automate the resizing of the reverse authentication proxy to prevent OOM during congestion, which we have witnessed, and analyze the default Prometheus settings related to rollback and scaling to prevent similar problems in the future.
The experienced failure also had some positive consequences: after receiving the necessary resources, Cortex automatically recovered without any additional intervention. We also gained valuable experience with Grafana Loki , our new log aggregation system, which helped to ensure that all Ingesters behaved properly during and after the crash.
PS from the translator
Read also in our blog:
Source: https://habr.com/ru/post/461807/
All Articles