Openstack Load Balancing
In large cloud systems, the issue of automatic balancing or balancing the load on computing resources is especially acute. Tionics also took care of this issue (the developer and operator of cloud services, we are part of the Rostelecom group of companies).
And, since our main development platform is Openstack, and we, like all people, are lazy, it was decided to choose some kind of ready-made module that is already part of the platform. Our choice fell on Watcher, which we decided to use for our needs.

First, let's deal with terms and definitions.
A goal is a human-readable, observable, and measurable end result that must be achieved. To achieve each goal, there are one or more strategies. A strategy is an implementation of an algorithm that is able to find a solution for a given purpose.
An Action is an elementary task that changes the current state of a target managed resource of an OpenStack cluster, such as: migrating a virtual machine (migration), changing the power state of a node (change_node_power_state), changing the state of a nova service (change_nova_service_state), changing a flavor (resize) , registration of NOP messages (nop), lack of action for a certain length of time - pause (sleep), disk transfer (volume_migrate).
')
Action Plan (Action Plan) - a specific stream of actions carried out in a specific order to achieve a specific Goal. The action plan also contains estimated global performance with a set of performance indicators. An action plan is generated by Watcher upon a successful audit, as a result of which the strategy used finds a solution to achieve the goal. An action plan consists of a list of sequential actions.
Audit is a request for cluster optimization. Optimization is performed in order to achieve one goal in a given cluster. For each successful audit, Watcher generates an Action Plan.
Audit Scope is a set of resources within which an audit is performed (availability zone (s), node aggregators, individual computing nodes or storage nodes, etc.). An audit scope is defined in each template. If the audit scope is not specified, the entire cluster is audited.
Audit Template - A saved set of settings for starting an audit. Templates are needed in order to run audits with the same settings multiple times. The template must necessarily contain the purpose of the audit, if strategies are not indicated, then the most suitable of existing strategies are selected.
A Cluster is a collection of physical machines that provide computing, storage, and network resources and are managed by the same OpenStack control node.
The Cluster Data Model (CDM) is a logical representation of the current state and topology of cluster-managed resources.
Efficiency Indicator (Efficacy Indicator) - an indicator that indicates how the solution created using this strategy is implemented. Performance indicators are specific to a particular goal and are commonly used to calculate the global effectiveness of a final action plan.
The Efficacy Specification is a set of specific features associated with each Goal, which defines various performance indicators that the strategy ensuring the achievement of the corresponding goal should provide in its decision. Indeed, each solution proposed by the strategy will be checked for compliance with specifications before calculating its global effectiveness.
A “scoring engine” is an executable file that has clearly defined input data, clearly defined output data and performs a purely mathematical task. Thus, the calculation does not depend on the environment in which it is performed - it will give the same result anywhere.
The Watcher Planner is part of the Watcher decision engine. This module accepts the set of actions generated by the strategy and creates a workflow plan that defines how to plan these various actions in time and for each action, what are the prerequisites.
Dummy goal - a reserve goal that is used for testing purposes.
Related strategies: Dummy Strategy, Dummy Strategy using sample Scoring Engines and Dummy strategy with resize. Dummy strategy is a dummy strategy used for integration testing through Tempest. This strategy does not provide any useful optimization; its sole purpose is to use the Tempest tests.
Dummy strategy using sample Scoring Engines - the strategy is similar to the previous one, it differs only in the use of the “rating engine” sample, which conducts calculations using machine learning methods.
Dummy strategy with resize - the strategy is similar to the previous one, it differs only in the use of changing the flavor (migration and resize).
Not used in production.
Saving Energy - minimize energy consumption. Strategy for this goal Saving Energy Strategy together with the strategy VM Workload Consolidation Strategy (Server Consolidation) is able to perform the functions of dynamic power management (DPM), which save energy by dynamically consolidating workloads even during periods of low resource load: virtual machines are transferred to fewer nodes , and unnecessary nodes are disconnected. After consolidation, the strategy offers a decision on turning on / off the nodes in accordance with the given parameters: “min_free_hosts_num” - the number of free included nodes that are waiting for load, and “free_used_percent” - the percentage of free included nodes to the number of nodes occupied by the machines. For the strategy to work, Ironic must be turned on and configured to work with power on / off on the nodes.
There must be at least two nodes in the cloud. The method used is changing the power state of the node (change_node_power_state). Strategy does not require collection of metrics.
Server Consolidation - minimize the number of compute nodes (consolidation). It has two strategies: Basic Offline Server Consolidation and VM Workload Consolidation Strategy.
The Basic Offline Server Consolidation strategy minimizes the total number of servers used and minimizes the number of migrations.
The basic strategy requires the following metrics:
Strategy parameters: migration_attempts - the number of combinations to search for potential shutdown candidates (default, 0, no restrictions), period - time interval in seconds to obtain static aggregation from the metric data source (700 by default).
Methods used: migration, nova service state change (change_nova_service_state).
The VM Workload Consolidation Strategy is based on the first-fit heuristic algorithm, which focuses on the measured CPU load and tries to minimize nodes that have too much or too little load, taking into account resource capacity limitations. This strategy provides a solution that leads to a more efficient use of cluster resources using the following four steps:
The strategy requires the following metrics:
The following metrics are optional, but improve strategy accuracy if available:
Strategy parameters: period - the time interval in seconds to obtain static aggregation from the metric data source (3600 by default).
Uses the same methods as the previous strategy. More details here .
Workload Balancing - balance workload between compute nodes. The goal has three strategies: Workload Balance Migration Strategy, Workload stabilization, Storage Capacity Balance Strategy.
Workload Balance Migration Strategy launches virtual machine migrations based on the workload of host virtual machines. The decision to transfer is made whenever the% of CPU or RAM utilization of the node exceeds the specified threshold. At the same time, the moved virtual machine should bring the node closer to the average workload of all nodes.
Strategy Options:
The method used is migration.
Workload stabilization - a strategy aimed at stabilizing the workload using live migration. The strategy is based on the standard deviation algorithm and determines if there is congestion in the cluster and responds to it by triggering a machine migration to stabilize the cluster.
Storage Capacity Balance Strategy (a strategy implemented since Queens) - the strategy transfers disks depending on the load of Cinder pools. The transfer decision is made whenever the pool utilization exceeds the specified threshold. A roaming disk should bring the pool closer to the average load of all Cinder pools.
Strategy Options:
The method used is disk migration (volume_migrate).
Noisy Neighbor - identify and migrate a “noisy neighbor” - a low-priority virtual machine that adversely affects the performance of a high-priority virtual machine from an IPC perspective, overuse of the Last Level Cache. Own strategy: Noisy Neighbor (the strategy parameter used is cache_threshold (the default value is 35), migration starts when the performance drops to the specified value. For the strategy to work, the included LLC (Last Level Cache) metrics, the latest Intel server with CMT support , and also collection of the following metrics:
Cluster data model (default): Nova cluster data model collector. The applied method is migration.
Work with this goal through the Dashboard is not fully implemented in Queens.
Thermal Optimization - optimize temperature conditions. The outlet temperature (exhaust air) is one of the important thermal telemetry systems for measuring the state of the server’s thermal / workload. For the purpose, there is one strategy - Outlet temperature based strategy, which makes decisions on transferring workloads to nodes with favorable temperature conditions (the lowest temperature at the exit) when the temperature at the output of the original hosts reaches a custom threshold.
For the strategy to work, you need a server with Intel Power Node Manager 3.0 or later installed and configured, as well as collecting the following metrics:
Strategy Options:
The method used is migration.
Airflow Optimization - optimize the ventilation mode. Own strategy - Uniform Airflow using live migration. The strategy starts the migration of the virtual machine whenever the air flow from the server fan exceeds the specified threshold.
To work, the strategy requires:
For the strategy to work, a server with installed and configured Intel Power Node Manager 3.0 or later is required.
Limitations: The concept is not intended for production.
It is proposed to use this algorithm with continuous audits, since only one virtual machine is planned to be migrated per iteration.
Live migrations are possible.
Strategy Options:
The method used is migration.
Hardware Maintenance - hardware maintenance. A strategy related to this goal is Zone migration. The strategy is a tool for efficient automatic and minimal migration of virtual machines and disks in case of hardware maintenance. The strategy builds an action plan in accordance with the weights: a set of actions that has more weight will be planned ahead of the others. There are two configuration options: action weights (action_weights) and parallelization.
Limitations: it is necessary to adjust the weights of actions and parallelization.
Strategy Options:
Elements of an array of compute nodes:
Elements of the array of storage nodes:
Elements of priority objects:
Used methods - migration of virtual machines, migration of disks.
Unclassified is a supporting goal used to facilitate the strategy development process. It does not contain specifications and can be used whenever the strategy is not yet connected with an existing goal. This goal can also be used as a transitional phase. A related strategy is Actuator.
The Watcher Decision Engine has an “external goal” plugin interface that allows you to integrate an external goal that can be achieved using strategy.
Before creating a new goal, you should make sure that none of the existing goals meets your needs.
To create a new target, you must: extend the target class, implement the get_name () class method to return a unique identifier for the new target that you want to create. This unique identifier must match the name of the entry point that you declare later.
Next, you need to implement the class method get_display_name () to return the translated display name of the target you want to create (do not use the variable to return the translated string so that it can be automatically collected by the translation tool.).
Implement the get_translatable_display_name () class method to return the translation key (actually the English display name) of your new target. The return value must match the string translated into get_display_name ().
Implement its get_efficacy_specification () method to return the performance specification for your purpose. The get_efficacy_specification () method returns the Unclassified () instance provided by Watcher. This performance specification is useful in the process of developing your goal because it meets the empty specification.
→ More details here
Architecture Watcher (more info here ).
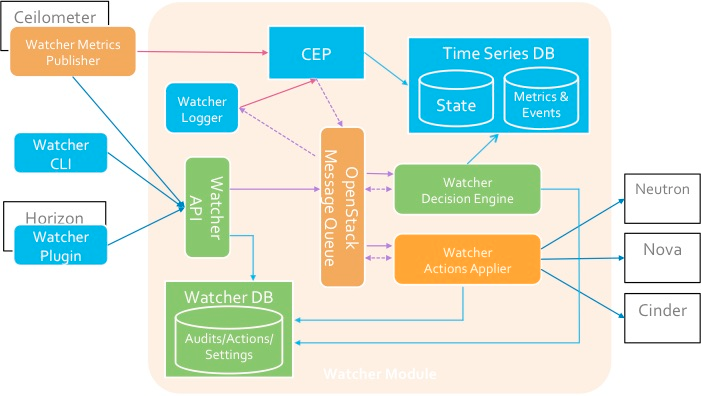
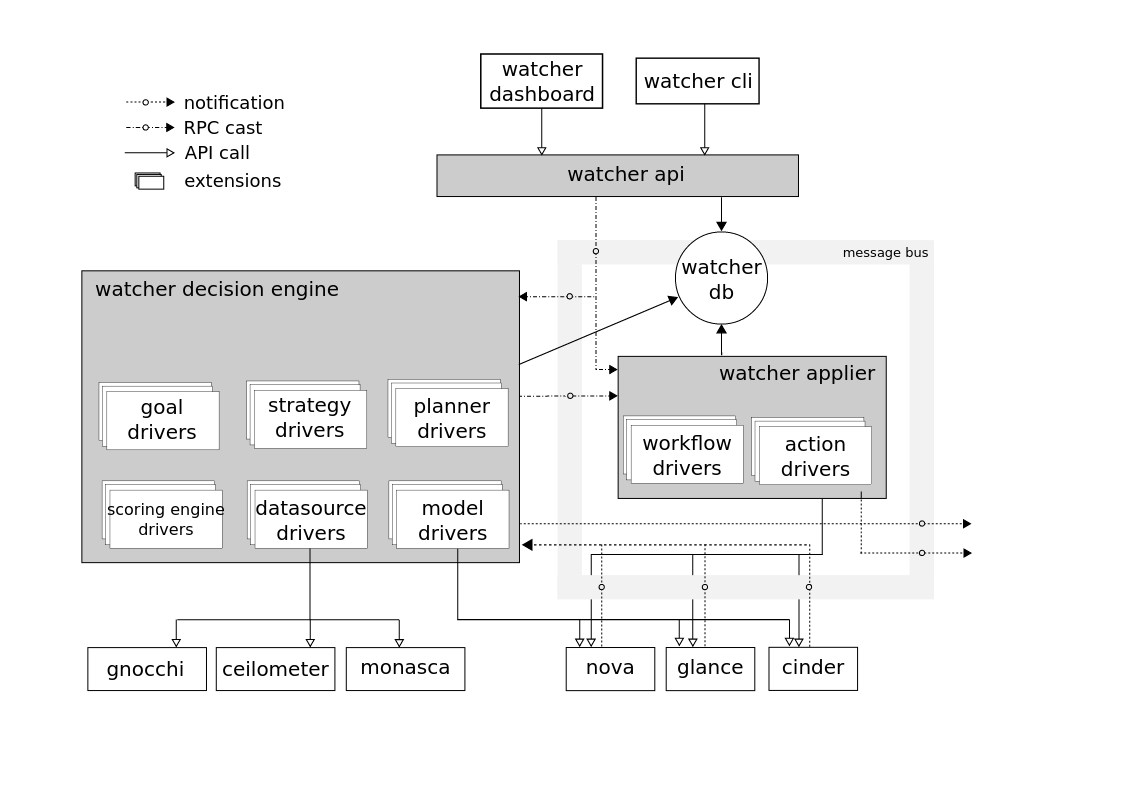
Watcher API - a component that implements the REST API provided by Watcher. Interaction mechanisms: CLI, Horizon plugin, Python SDK.
Watcher DB - Watcher database.
Watcher Applier - a component that implements the action plan created by the component Watcher Decision Engine.
The Watcher Decision Engine is a component responsible for calculating a set of potential optimization actions to fulfill an audit goal. If a strategy is not specified, the component independently selects the most suitable one.
Watcher Metrics Publisher is a component that collects and calculates some metrics or events and publishes them at the CEP endpoint. Feature functionality may also be provided by Ceilometer publisher.
Complex Event Processing (CEP) Engine - an integrated event processing engine. For performance reasons, there may be several CEP Engine instances running at the same time, each of which handles a specific type of metric / event. In the Watcher system, CEP launches two types of actions: - write the corresponding events / metrics to the time series database; - send relevant events to the Watcher Decision Engine component when this event can affect the result of the current optimization strategy, since the Openstack cluster is not a static system.
The interaction of the components is carried out according to the AMQP protocol.
→ Configuring Watcher

The following audit completion errors are also encountered. Traceback in decision-engine.log logs (cluster state is not defined).
→ Discussion of the error here
The result of our two-month research was the unambiguous conclusion that in order to get a full-fledged, working load balancing system, we will have to work closely on finalizing the tools for the Openstack platform.
Watcher has proved itself to be a serious and rapidly developing product with enormous potential, for the full use of which a lot of serious work will be required.
But more about that in the next articles of the cycle.
And, since our main development platform is Openstack, and we, like all people, are lazy, it was decided to choose some kind of ready-made module that is already part of the platform. Our choice fell on Watcher, which we decided to use for our needs.
First, let's deal with terms and definitions.
Terms and Definitions
A goal is a human-readable, observable, and measurable end result that must be achieved. To achieve each goal, there are one or more strategies. A strategy is an implementation of an algorithm that is able to find a solution for a given purpose.
An Action is an elementary task that changes the current state of a target managed resource of an OpenStack cluster, such as: migrating a virtual machine (migration), changing the power state of a node (change_node_power_state), changing the state of a nova service (change_nova_service_state), changing a flavor (resize) , registration of NOP messages (nop), lack of action for a certain length of time - pause (sleep), disk transfer (volume_migrate).
')
Action Plan (Action Plan) - a specific stream of actions carried out in a specific order to achieve a specific Goal. The action plan also contains estimated global performance with a set of performance indicators. An action plan is generated by Watcher upon a successful audit, as a result of which the strategy used finds a solution to achieve the goal. An action plan consists of a list of sequential actions.
Audit is a request for cluster optimization. Optimization is performed in order to achieve one goal in a given cluster. For each successful audit, Watcher generates an Action Plan.
Audit Scope is a set of resources within which an audit is performed (availability zone (s), node aggregators, individual computing nodes or storage nodes, etc.). An audit scope is defined in each template. If the audit scope is not specified, the entire cluster is audited.
Audit Template - A saved set of settings for starting an audit. Templates are needed in order to run audits with the same settings multiple times. The template must necessarily contain the purpose of the audit, if strategies are not indicated, then the most suitable of existing strategies are selected.
A Cluster is a collection of physical machines that provide computing, storage, and network resources and are managed by the same OpenStack control node.
The Cluster Data Model (CDM) is a logical representation of the current state and topology of cluster-managed resources.
Efficiency Indicator (Efficacy Indicator) - an indicator that indicates how the solution created using this strategy is implemented. Performance indicators are specific to a particular goal and are commonly used to calculate the global effectiveness of a final action plan.
The Efficacy Specification is a set of specific features associated with each Goal, which defines various performance indicators that the strategy ensuring the achievement of the corresponding goal should provide in its decision. Indeed, each solution proposed by the strategy will be checked for compliance with specifications before calculating its global effectiveness.
A “scoring engine” is an executable file that has clearly defined input data, clearly defined output data and performs a purely mathematical task. Thus, the calculation does not depend on the environment in which it is performed - it will give the same result anywhere.
The Watcher Planner is part of the Watcher decision engine. This module accepts the set of actions generated by the strategy and creates a workflow plan that defines how to plan these various actions in time and for each action, what are the prerequisites.
Watcher Goals and Strategies
| purpose | Strategies |
| Dummy goal | Dummy strategy |
| Dummy Strategy using sample Scoring Engines | |
| Dummy strategy with resize | |
| Saving energy | Saving energy strategy |
| Server consolidation | Basic Offline Server Consolidation |
| VM Workload Consolidation Strategy | |
| Workload balancing | Workload Balance Migration Strategy |
| Storage Capacity Balance Strategy | |
| Workload stabilization | |
| Noisy neighbor | Noisy neighbor |
| Thermal optimization | Outlet temperature based strategy |
| Airflow optimization | Uniform airflow migration strategy |
| Hardware maintenance | Zone migration |
| Unclassified | Actuator |
Dummy goal - a reserve goal that is used for testing purposes.
Related strategies: Dummy Strategy, Dummy Strategy using sample Scoring Engines and Dummy strategy with resize. Dummy strategy is a dummy strategy used for integration testing through Tempest. This strategy does not provide any useful optimization; its sole purpose is to use the Tempest tests.
Dummy strategy using sample Scoring Engines - the strategy is similar to the previous one, it differs only in the use of the “rating engine” sample, which conducts calculations using machine learning methods.
Dummy strategy with resize - the strategy is similar to the previous one, it differs only in the use of changing the flavor (migration and resize).
Not used in production.
Saving Energy - minimize energy consumption. Strategy for this goal Saving Energy Strategy together with the strategy VM Workload Consolidation Strategy (Server Consolidation) is able to perform the functions of dynamic power management (DPM), which save energy by dynamically consolidating workloads even during periods of low resource load: virtual machines are transferred to fewer nodes , and unnecessary nodes are disconnected. After consolidation, the strategy offers a decision on turning on / off the nodes in accordance with the given parameters: “min_free_hosts_num” - the number of free included nodes that are waiting for load, and “free_used_percent” - the percentage of free included nodes to the number of nodes occupied by the machines. For the strategy to work, Ironic must be turned on and configured to work with power on / off on the nodes.
Strategy Options
| parameter | type of | default | description |
| free_used_percent | Number | 10.0 | ratio of the number of free computing nodes to the number of computing nodes with virtual machines |
| min_free_hosts_num | Int | one | minimum number of free computing nodes |
There must be at least two nodes in the cloud. The method used is changing the power state of the node (change_node_power_state). Strategy does not require collection of metrics.
Server Consolidation - minimize the number of compute nodes (consolidation). It has two strategies: Basic Offline Server Consolidation and VM Workload Consolidation Strategy.
The Basic Offline Server Consolidation strategy minimizes the total number of servers used and minimizes the number of migrations.
The basic strategy requires the following metrics:
| metrics | service | plugins | comment |
| compute.node.cpu.percent | ceilometer | none | |
| cpu_util | ceilometer | none |
Strategy parameters: migration_attempts - the number of combinations to search for potential shutdown candidates (default, 0, no restrictions), period - time interval in seconds to obtain static aggregation from the metric data source (700 by default).
Methods used: migration, nova service state change (change_nova_service_state).
The VM Workload Consolidation Strategy is based on the first-fit heuristic algorithm, which focuses on the measured CPU load and tries to minimize nodes that have too much or too little load, taking into account resource capacity limitations. This strategy provides a solution that leads to a more efficient use of cluster resources using the following four steps:
- Unloading phase - processing of overspended resources;
- Consolidation phase - processing of underutilized resources;
- Solution optimization - reducing the number of migrations;
- Disabling unused compute nodes.
The strategy requires the following metrics:
| metrics | service | plugins | comment |
| memory | ceilometer | none | |
| disk.root.size | ceilometer | none |
The following metrics are optional, but improve strategy accuracy if available:
| metrics | service | plugins | comment |
| memory.resident | ceilometer | none | |
| cpu_util | ceilometer | none |
Strategy parameters: period - the time interval in seconds to obtain static aggregation from the metric data source (3600 by default).
Uses the same methods as the previous strategy. More details here .
Workload Balancing - balance workload between compute nodes. The goal has three strategies: Workload Balance Migration Strategy, Workload stabilization, Storage Capacity Balance Strategy.
Workload Balance Migration Strategy launches virtual machine migrations based on the workload of host virtual machines. The decision to transfer is made whenever the% of CPU or RAM utilization of the node exceeds the specified threshold. At the same time, the moved virtual machine should bring the node closer to the average workload of all nodes.
Requirements
- Use of physical processors;
- At least two physical computing nodes;
- The installed and configured Ceilometer component is the ceilometer-agent-compute, which works on each computing node, and the Ceilometer API, as well as collecting the following metrics:
| metrics | service | plugins | comment |
| cpu_util | ceilometer | none | |
| memory.resident | ceilometer | none |
Strategy Options:
| parameter | type of | default | description |
| metrics | String | 'cpu_util' | The metrics that underlie: 'cpu_util', 'memory.resident'. |
| threshold | Number | 25.0 | Workload threshold for migration. |
| period | Number | 300 | The cumulative time period of the Ceilometer. |
The method used is migration.
Workload stabilization - a strategy aimed at stabilizing the workload using live migration. The strategy is based on the standard deviation algorithm and determines if there is congestion in the cluster and responds to it by triggering a machine migration to stabilize the cluster.
Requirements
- Use of physical processors;
- At least two physical computing nodes;
- The installed and configured Ceilometer component is the ceilometer-agent-compute, which works on each computing node, and the Ceilometer API, as well as collecting the following metrics:
| metrics | service | plugins | comment |
| cpu_util | ceilometer | none | |
| memory.resident | ceilometer | none |
Storage Capacity Balance Strategy (a strategy implemented since Queens) - the strategy transfers disks depending on the load of Cinder pools. The transfer decision is made whenever the pool utilization exceeds the specified threshold. A roaming disk should bring the pool closer to the average load of all Cinder pools.
Requirements and Limitations
- At least two Cinder pools;
- Ability to migrate disks.
- Cluster data model collector.
Strategy Options:
| parameter | type of | default | description |
| volume_threshold | Number | 80.0 | Threshold value of disks for volume balancing. |
The method used is disk migration (volume_migrate).
Noisy Neighbor - identify and migrate a “noisy neighbor” - a low-priority virtual machine that adversely affects the performance of a high-priority virtual machine from an IPC perspective, overuse of the Last Level Cache. Own strategy: Noisy Neighbor (the strategy parameter used is cache_threshold (the default value is 35), migration starts when the performance drops to the specified value. For the strategy to work, the included LLC (Last Level Cache) metrics, the latest Intel server with CMT support , and also collection of the following metrics:
| metrics | service | plugins | comment |
| cpu_l3_cache | ceilometer | none | Intel CMT required. |
Cluster data model (default): Nova cluster data model collector. The applied method is migration.
Work with this goal through the Dashboard is not fully implemented in Queens.
Thermal Optimization - optimize temperature conditions. The outlet temperature (exhaust air) is one of the important thermal telemetry systems for measuring the state of the server’s thermal / workload. For the purpose, there is one strategy - Outlet temperature based strategy, which makes decisions on transferring workloads to nodes with favorable temperature conditions (the lowest temperature at the exit) when the temperature at the output of the original hosts reaches a custom threshold.
For the strategy to work, you need a server with Intel Power Node Manager 3.0 or later installed and configured, as well as collecting the following metrics:
| metrics | service | plugins | comment |
| hardware.ipmi.node.outlet_temperature | ceilometer | IPMI |
Strategy Options:
| parameter | type of | default | description |
| threshold | Number | 35.0 | Temperature threshold for migration. |
| period | Number | thirty | The time interval in seconds to obtain statistical aggregation from a metric data source. |
The method used is migration.
Airflow Optimization - optimize the ventilation mode. Own strategy - Uniform Airflow using live migration. The strategy starts the migration of the virtual machine whenever the air flow from the server fan exceeds the specified threshold.
To work, the strategy requires:
- Hardware: computing nodes <with support for NodeManager 3.0;
- At least two compute nodes;
- The ceilometer-agent-compute and Ceilometer API components installed and configured on each computing node can successfully report metrics such as air flow, system power, and inlet temperature:
| metrics | service | plugins | comment |
| hardware.ipmi.node.airflow | ceilometer | IPMI | |
| hardware.ipmi.node.temperature | ceilometer | IPMI | |
| hardware.ipmi.node.power | ceilometer | IPMI |
For the strategy to work, a server with installed and configured Intel Power Node Manager 3.0 or later is required.
Limitations: The concept is not intended for production.
It is proposed to use this algorithm with continuous audits, since only one virtual machine is planned to be migrated per iteration.
Live migrations are possible.
Strategy Options:
| parameter | type of | default | description |
| threshold_airflow | Number | 400.0 | Airflow threshold for migration Unit is 0.1CFM |
| threshold_inlet_t | Number | 28.0 | Inlet temperature threshold for migration decision |
| threshold_power | Number | 350.0 | System power threshold for migration decision |
| period | Number | thirty | The time interval in seconds to obtain statistical aggregation from a metric data source. |
The method used is migration.
Hardware Maintenance - hardware maintenance. A strategy related to this goal is Zone migration. The strategy is a tool for efficient automatic and minimal migration of virtual machines and disks in case of hardware maintenance. The strategy builds an action plan in accordance with the weights: a set of actions that has more weight will be planned ahead of the others. There are two configuration options: action weights (action_weights) and parallelization.
Limitations: it is necessary to adjust the weights of actions and parallelization.
Strategy Options:
| parameter | type of | default | description |
| compute_nodes | array | None | Computing nodes for migration. |
| storage_pools | array | None | Storage nodes for migration. |
| parallel_total | integer | 6 | The total number of actions to be performed in parallel. |
| parallel_per_node | integer | 2 | The number of actions performed in parallel for each computing node. |
| parallel_per_pool | integer | 2 | The number of actions performed in parallel for each storage pool. |
| priority | object | None | Priority list for virtual machines and disks. |
| with_attached_volume | boolean | False | False - virtual machines will be migrated after all drives are migrated. True - virtual machines will be migrated after the migration of all mapped drives. |
Elements of an array of compute nodes:
| parameter | type of | default | description |
| src_node | string | None | Computing node from which virtual machines are migrated (required). |
| dst_node | string | None | Compute the node to which virtual machines migrate. |
Elements of the array of storage nodes:
| parameter | type of | default | description |
| src_pool | string | None | Storage pool from which disks are migrated (required). |
| dst_pool | string | None | Storage pool to which disks are migrated. |
| src_type | string | None | Original disk type (required). |
| dst_type | string | None | Final drive type (required). |
Elements of priority objects:
| parameter | type of | default | description |
| project | array | None | The names of the projects. |
| compute_node | array | None | Names of compute nodes. |
| storage_pool | array | None | The names of the storage pools. |
| compute | enum | None | Virtual machine parameters [“vcpu_num”, “mem_size”, “disk_size”, “created_at”]. |
| storage | enum | None | Disk options [“size”, “created_at”]. |
Used methods - migration of virtual machines, migration of disks.
Unclassified is a supporting goal used to facilitate the strategy development process. It does not contain specifications and can be used whenever the strategy is not yet connected with an existing goal. This goal can also be used as a transitional phase. A related strategy is Actuator.
Create a new goal
The Watcher Decision Engine has an “external goal” plugin interface that allows you to integrate an external goal that can be achieved using strategy.
Before creating a new goal, you should make sure that none of the existing goals meets your needs.
Create a new plugin
To create a new target, you must: extend the target class, implement the get_name () class method to return a unique identifier for the new target that you want to create. This unique identifier must match the name of the entry point that you declare later.
Next, you need to implement the class method get_display_name () to return the translated display name of the target you want to create (do not use the variable to return the translated string so that it can be automatically collected by the translation tool.).
Implement the get_translatable_display_name () class method to return the translation key (actually the English display name) of your new target. The return value must match the string translated into get_display_name ().
Implement its get_efficacy_specification () method to return the performance specification for your purpose. The get_efficacy_specification () method returns the Unclassified () instance provided by Watcher. This performance specification is useful in the process of developing your goal because it meets the empty specification.
→ More details here
Architecture Watcher (more info here ).
Components
Watcher API - a component that implements the REST API provided by Watcher. Interaction mechanisms: CLI, Horizon plugin, Python SDK.
Watcher DB - Watcher database.
Watcher Applier - a component that implements the action plan created by the component Watcher Decision Engine.
The Watcher Decision Engine is a component responsible for calculating a set of potential optimization actions to fulfill an audit goal. If a strategy is not specified, the component independently selects the most suitable one.
Watcher Metrics Publisher is a component that collects and calculates some metrics or events and publishes them at the CEP endpoint. Feature functionality may also be provided by Ceilometer publisher.
Complex Event Processing (CEP) Engine - an integrated event processing engine. For performance reasons, there may be several CEP Engine instances running at the same time, each of which handles a specific type of metric / event. In the Watcher system, CEP launches two types of actions: - write the corresponding events / metrics to the time series database; - send relevant events to the Watcher Decision Engine component when this event can affect the result of the current optimization strategy, since the Openstack cluster is not a static system.
The interaction of the components is carried out according to the AMQP protocol.
→ Configuring Watcher
Scheme of interaction with Watcher
Watcher Test Results
- On the Optimization - Action plans 500 page, an error (both on a clean Queens, and on a stand with Tionics modules) appears only after the audit is started and an action plan is generated, an empty one opens normally.
- On the Action details tab of the error, it is not possible to get the goal and audit strategy (both on pure Queens and on the stand with Tionics modules).
- Audits for the purpose of Dummy (test) are created and run normally, action plans are generated.
- No audits are created for the Unclassified target, because the target is not functional and is intended for intermediate configuration when creating new strategies.
- Workload Balancing audits (Storage Capacity balance strategy) are created successfully, but no action plan is generated. No optimization of storage pools.
- Workload Balancing audits (Workload Balance Migration Strategy) are created successfully, but no action plan is generated.
- Audits for the Workload Balancing goal (Workload Stabilization Strategy) fail.
- Noisy Neighbor audits are created successfully, but no action plan is generated.
- Audits for the purpose of Hardware maintenance are created successfully, the action plan is not generated in full (performance indicators are generated, but the list of actions is not generated).
- Edits in the nova.conf configs (in the default section compute_monitors = cpu.virt_driver) on the compute and control nodes do not fix errors.
- Audits for Server Consolidation (Basic Strategy) also fail.
- Audits for Server Consolidation (VM workload consolidation strategy) fail. In the logs, an error occurred in obtaining the initial data. A discussion of the error, in particular, is here .
We tried to specify Watcher in the config file (it did not help - as a result of an error on all Optimization pages, returning to the original contents of the config file does not correct the situation):
[watcher_strategies.basic]
datasource = ceilometer, gnocchi - Audits for Saving Energy fail. Judging by the logs, the problem is still in the absence of Ironic, it will not work without baremetal service.
- Thermal Optimization Audits fail. The traceback is the same as for Server Consolidation (VM workload consolidation strategy) (source data error)
- Audits for Airflow Optimization fail.
The following audit completion errors are also encountered. Traceback in decision-engine.log logs (cluster state is not defined).
→ Discussion of the error here
Conclusion
The result of our two-month research was the unambiguous conclusion that in order to get a full-fledged, working load balancing system, we will have to work closely on finalizing the tools for the Openstack platform.
Watcher has proved itself to be a serious and rapidly developing product with enormous potential, for the full use of which a lot of serious work will be required.
But more about that in the next articles of the cycle.
Source: https://habr.com/ru/post/461483/
All Articles