Overview of the free SQLIndexManager tool
As you know, indexes play an important role in the DBMS, providing a quick search of the necessary records. Therefore, it is so important to service them in a timely manner. Quite a lot of material has been written about analysis and optimization, including on the Internet. For example, a recent review of this topic in this publication was made .
There are many both paid and free solutions for this. For example, there is a turnkey solution based on an adaptive index optimization method.
Next, consider the free SQLIndexManager utility, authored by AlanDenton .
The main technical difference between SQLIndexManager and a number of other analogues is made by the author himself here and here .
')
In the same article, we take a look at the project and the possibilities of using this software solution.
Discuss this utility here .
Over time, most of the comments and bugs have been fixed.
So, now let's move on to the SQLIndexManager utility itself.
The application is written in C # .NET Framework 4.5 in Visual Studio 2017 and uses DevExpress for forms:
and looks like this:
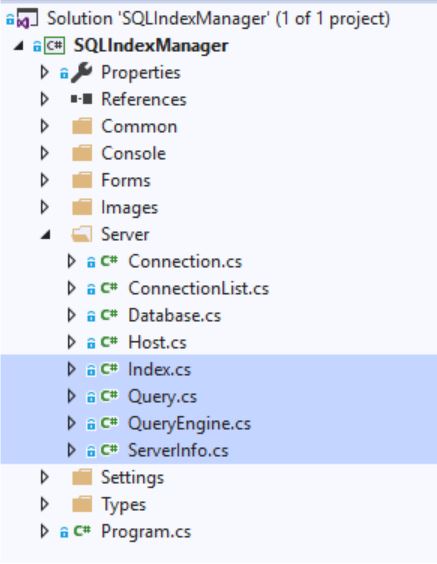
All requests are generated in the following files:
When connecting to the database and sending requests to the DBMS, the application is signed as follows:
When the application starts, a modal window opens to add a connection:
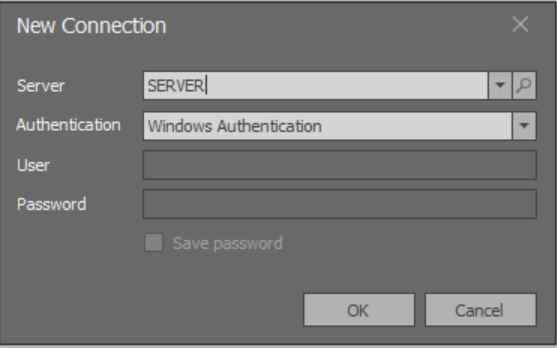
Here loading of the complete list of all instances of MS SQL Server available over local networks does not work yet.
You can also add a connection using the leftmost button on the main menu:
Next, the following DBMS queries will be launched:
After executing the above scripts, a window appears containing brief information about the databases of the selected instance of MS SQL Server:
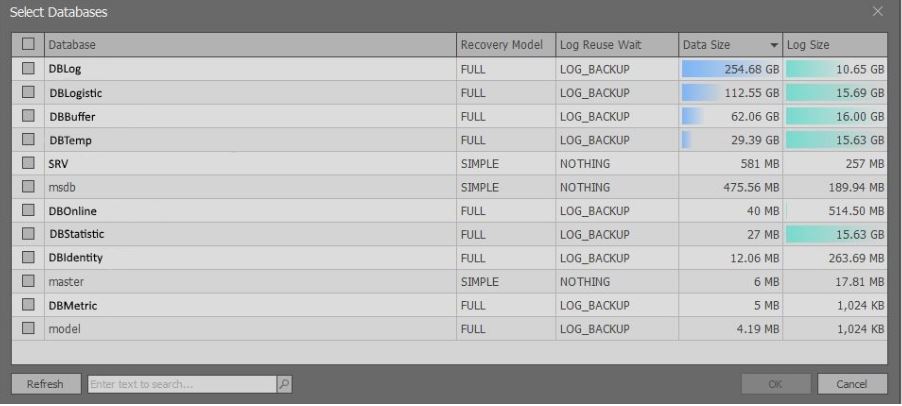
It is worth noting that extended information is displayed based on rights. If there is sysadmin , then you can select data from the sys.master_files view . If there are no such rights, then less data is returned so as not to slow down the request.
Here you need to select the database of interest and click on the “OK” button.
Next, the following script will be executed for each selected database to analyze the status of indexes:
As you can see from the queries themselves, temporary tables are often used. This was done so that there would be no recompilation, and in the case of a large scheme, the plan could be generated parallel when inserting data, since inserting with table variables is possible in only one stream.
After executing the above script, a window with the index table will appear:

Here you can also display other detailed information, such as:
etc.
The columns themselves can be customized:
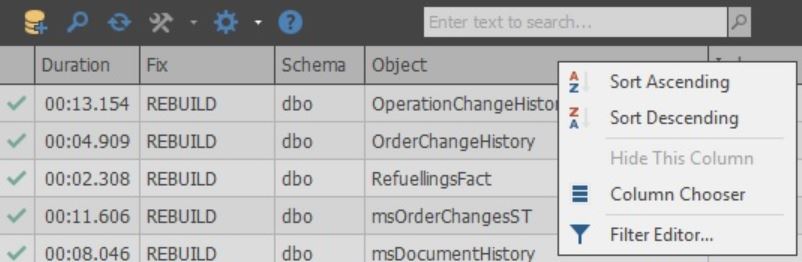
In the cells of the Fix column, you can choose what action will be performed during optimization. Also, when scanning is completed, the default action is selected based on the selected settings:
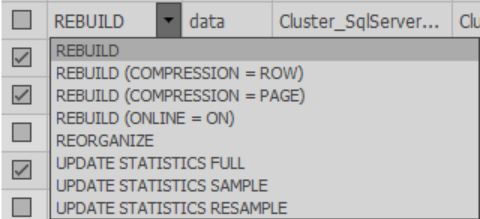
You must select the desired indexes for processing.
Using the main menu, you can save the script (the same button starts the index optimization process itself):
save the table in different formats (the same button allows you to open detailed settings for analysis and optimization of indices):

Also, information can be updated by clicking on the third button on the left in the main menu next to the magnifying glass.
A button with a magnifying glass allows you to select the desired database for consideration.
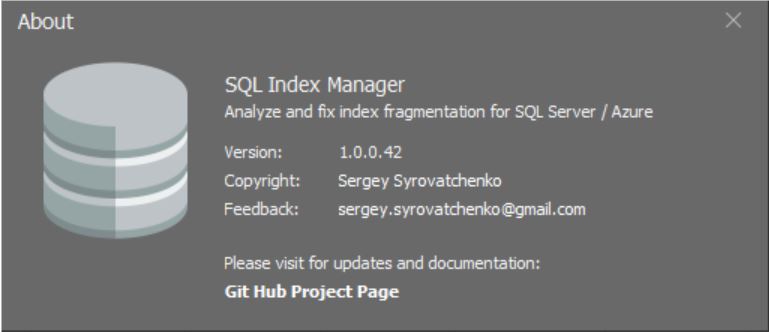
There is currently no complete help system. Therefore, clicking on the “?” Button will simply cause a modal window to appear containing basic information about the software product:
In addition to all of the above, the main menu has a search bar:

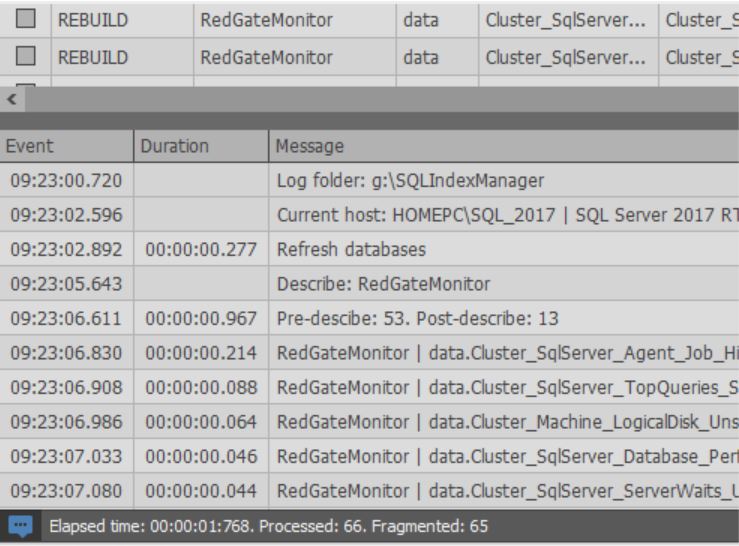
When starting the index optimization process:

Also at the bottom of the window you can see the log of the actions performed:
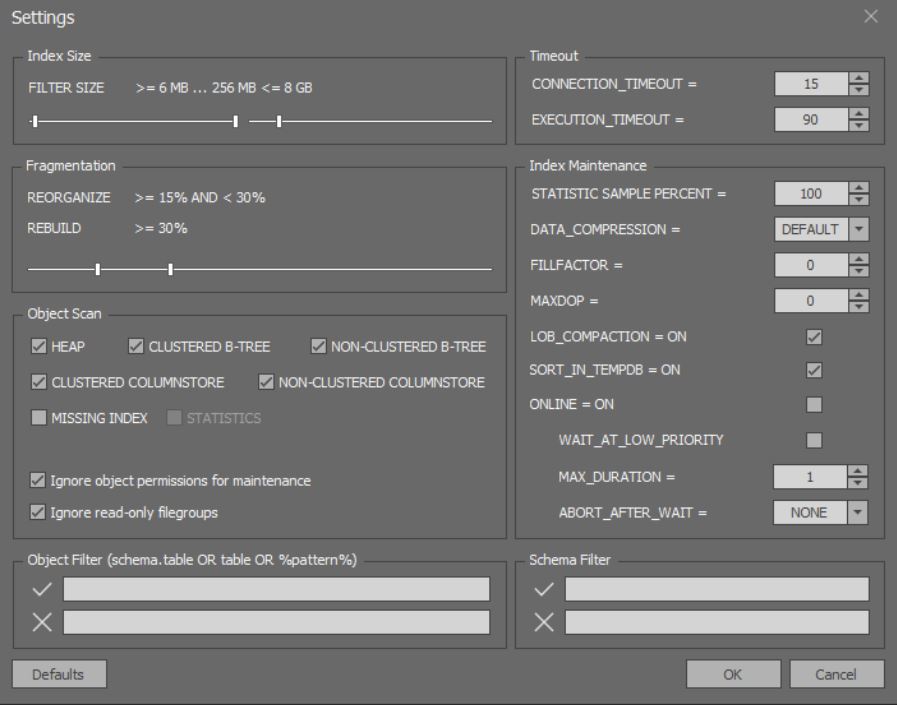
In the window for detailed analysis and optimization of indexes, you can configure more subtle options:
Suggestions for the application:
At the time of writing, article 6 of the wishes is actively being developed and there is already support in the form of a search for complete and similar duplicates:
There are many both paid and free solutions for this. For example, there is a turnkey solution based on an adaptive index optimization method.
Next, consider the free SQLIndexManager utility, authored by AlanDenton .
The main technical difference between SQLIndexManager and a number of other analogues is made by the author himself here and here .
')
In the same article, we take a look at the project and the possibilities of using this software solution.
Discuss this utility here .
Over time, most of the comments and bugs have been fixed.
So, now let's move on to the SQLIndexManager utility itself.
The application is written in C # .NET Framework 4.5 in Visual Studio 2017 and uses DevExpress for forms:
and looks like this:
All requests are generated in the following files:
- Index
- Query
- Queryengine
- ServerInfo
When connecting to the database and sending requests to the DBMS, the application is signed as follows:
ApplicationName=”SQLIndexManager” When the application starts, a modal window opens to add a connection:
Here loading of the complete list of all instances of MS SQL Server available over local networks does not work yet.
You can also add a connection using the leftmost button on the main menu:
Next, the following DBMS queries will be launched:
- Obtaining DBMS Information
SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT) - Getting a list of available databases with their brief properties
SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
After executing the above scripts, a window appears containing brief information about the databases of the selected instance of MS SQL Server:
It is worth noting that extended information is displayed based on rights. If there is sysadmin , then you can select data from the sys.master_files view . If there are no such rights, then less data is returned so as not to slow down the request.
Here you need to select the database of interest and click on the “OK” button.
Next, the following script will be executed for each selected database to analyze the status of indexes:
Index Status Analysis
declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE #AllocationUnits CREATE TABLE #AllocationUnits ( ContainerID BIGINT PRIMARY KEY , ReservedPages BIGINT NOT NULL , UsedPages BIGINT NOT NULL ) INSERT INTO #AllocationUnits (ContainerID, ReservedPages, UsedPages) SELECT [container_id] , SUM([total_pages]) , SUM([used_pages]) FROM sys.allocation_units WITH(NOLOCK) GROUP BY [container_id] HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize IF OBJECT_ID('tempdb.dbo.#ExcludeList') IS NOT NULL DROP TABLE #ExcludeList CREATE TABLE #ExcludeList (ID INT PRIMARY KEY) INSERT INTO #ExcludeList SELECT [object_id] FROM sys.objects WITH(NOLOCK) WHERE [type] IN ('V', 'U') AND ( [is_ms_shipped] = 1 ) IF OBJECT_ID('tempdb.dbo.#Partitions') IS NOT NULL DROP TABLE #Partitions SELECT [object_id] , [index_id] , [partition_id] , [partition_number] , [rows] , [data_compression] INTO #Partitions FROM sys.partitions WITH(NOLOCK) WHERE [object_id] > 255 AND [rows] > 0 AND [object_id] NOT IN (SELECT * FROM #ExcludeList) IF OBJECT_ID('tempdb.dbo.#Indexes') IS NOT NULL DROP TABLE #Indexes CREATE TABLE #Indexes ( ObjectID INT NOT NULL , IndexID INT NOT NULL , IndexName SYSNAME NULL , PagesCount BIGINT NOT NULL , UnusedPagesCount BIGINT NOT NULL , PartitionNumber INT NOT NULL , RowsCount BIGINT NOT NULL , IndexType TINYINT NOT NULL , IsAllowPageLocks BIT NOT NULL , DataSpaceID INT NOT NULL , DataCompression TINYINT NOT NULL , IsUnique BIT NOT NULL , IsPK BIT NOT NULL , FillFactorValue INT NOT NULL , IsFiltered BIT NOT NULL , PRIMARY KEY (ObjectID, IndexID, PartitionNumber) ) INSERT INTO #Indexes SELECT ObjectID = i.[object_id] , IndexID = i.index_id , IndexName = i.[name] , PagesCount = a.ReservedPages , UnusedPagesCount = CASE WHEN ABS(a.ReservedPages - a.UsedPages) > 32 THEN a.ReservedPages - a.UsedPages ELSE 0 END , PartitionNumber = p.[partition_number] , RowsCount = ISNULL(p.[rows], 0) , IndexType = i.[type] , IsAllowPageLocks = i.[allow_page_locks] , DataSpaceID = i.[data_space_id] , DataCompression = p.[data_compression] , IsUnique = i.[is_unique] , IsPK = i.[is_primary_key] , FillFactorValue = i.[fill_factor] , IsFiltered = i.[has_filter] FROM #AllocationUnits a JOIN #Partitions p ON a.ContainerID = p.[partition_id] JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id] AND p.[index_id] = i.[index_id] WHERE i.[type] IN (0, 1, 2, 5, 6) AND i.[object_id] > 255 DECLARE @files TABLE (ID INT PRIMARY KEY) INSERT INTO @files SELECT DISTINCT [data_space_id] FROM sys.database_files WITH(NOLOCK) WHERE [state] != 0 AND [type] = 0 IF @@ROWCOUNT > 0 BEGIN DELETE FROM i FROM #Indexes i LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id] AND i.PartitionNumber = dds.[destination_id] WHERE ISNULL(dds.[data_space_id], i.DataSpaceID) IN (SELECT * FROM @files) END DECLARE @DBID INT , @DBNAME SYSNAME SET @DBNAME = DB_NAME() SELECT @DBID = [database_id] FROM sys.databases WITH(NOLOCK) WHERE [name] = @DBNAME IF OBJECT_ID('tempdb.dbo.#Fragmentation') IS NOT NULL DROP TABLE #Fragmentation CREATE TABLE #Fragmentation ( ObjectID INT NOT NULL , IndexID INT NOT NULL , PartitionNumber INT NOT NULL , Fragmentation FLOAT NOT NULL , PRIMARY KEY (ObjectID, IndexID, PartitionNumber) ) INSERT INTO #Fragmentation (ObjectID, IndexID, PartitionNumber, Fragmentation) SELECT i.ObjectID , i.IndexID , i.PartitionNumber , r.[avg_fragmentation_in_percent] FROM #Indexes i CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r WHERE i.PagesCount <= @PreDescribeSize AND r.[index_level] = 0 AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA' AND i.IndexType IN (0, 1, 2) IF OBJECT_ID('tempdb.dbo.#Columns') IS NOT NULL DROP TABLE #Columns CREATE TABLE #Columns ( ObjectID INT NOT NULL , ColumnID INT NOT NULL , ColumnName SYSNAME NULL , SystemTypeID TINYINT NULL , IsSparse BIT , IsColumnSet BIT , MaxLen INT , PRIMARY KEY (ObjectID, ColumnID) ) INSERT INTO #Columns SELECT ObjectID = [object_id] , ColumnID = [column_id] , ColumnName = [name] , SystemTypeID = [system_type_id] , IsSparse = [is_sparse] , IsColumnSet = [is_column_set] , MaxLen = [max_length] FROM sys.columns WITH(NOLOCK) WHERE [object_id] IN (SELECT DISTINCT i.ObjectID FROM #Indexes i) IF OBJECT_ID('tempdb.dbo.#IndexColumns') IS NOT NULL DROP TABLE #IndexColumns CREATE TABLE #IndexColumns ( ObjectID INT NOT NULL , IndexID INT NOT NULL , OrderID INT NOT NULL , ColumnID INT NOT NULL , IsIncluded BIT NOT NULL , PRIMARY KEY (ObjectID, IndexID, ColumnID) ) INSERT INTO #IndexColumns SELECT ObjectID = [object_id] , IndexID = [index_id] , OrderID = CASE WHEN [is_included_column] = 0 THEN [key_ordinal] ELSE [index_column_id] END , ColumnID = [column_id] , IsIncluded = ISNULL([is_included_column], 0) FROM sys.index_columns ic WITH(NOLOCK) WHERE EXISTS( SELECT * FROM #Indexes i WHERE i.ObjectID = ic.[object_id] AND i.IndexID = ic.[index_id] AND i.IndexType IN (1, 2) ) IF OBJECT_ID('tempdb.dbo.#Lob') IS NOT NULL DROP TABLE #Lob CREATE TABLE #Lob ( ObjectID INT NOT NULL , IndexID INT NOT NULL , IsLobLegacy BIT , IsLob BIT , PRIMARY KEY (ObjectID, IndexID) ) INSERT INTO #Lob (ObjectID, IndexID, IsLobLegacy, IsLob) SELECT c.ObjectID , IndexID = ISNULL(i.IndexID, 1) , IsLobLegacy = MAX(CASE WHEN c.SystemTypeID IN (34, 35, 99) THEN 1 END) , IsLob = 0 FROM #Columns c LEFT JOIN #IndexColumns i ON c.ObjectID = i.ObjectID AND c.ColumnID = i.ColumnID WHERE c.SystemTypeID IN (34, 35, 99) GROUP BY c.ObjectID , i.IndexID IF OBJECT_ID('tempdb.dbo.#Sparse') IS NOT NULL DROP TABLE #Sparse CREATE TABLE #Sparse (ObjectID INT PRIMARY KEY) INSERT INTO #Sparse SELECT DISTINCT ObjectID FROM #Columns WHERE IsSparse = 1 OR IsColumnSet = 1 IF OBJECT_ID('tempdb.dbo.#AggColumns') IS NOT NULL DROP TABLE #AggColumns CREATE TABLE #AggColumns ( ObjectID INT NOT NULL , IndexID INT NOT NULL , IndexColumns NVARCHAR(MAX) , IncludedColumns NVARCHAR(MAX) , PRIMARY KEY (ObjectID, IndexID) ) INSERT INTO #AggColumns SELECT t.ObjectID , t.IndexID , IndexColumns = STUFF(( SELECT ', [' + c.ColumnName + ']' FROM #IndexColumns i JOIN #Columns c ON i.ObjectID = c.ObjectID AND i.ColumnID = c.ColumnID WHERE i.ObjectID = t.ObjectID AND i.IndexID = t.IndexID AND i.IsIncluded = 0 ORDER BY i.OrderID FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '') , IncludedColumns = STUFF(( SELECT ', [' + c.ColumnName + ']' FROM #IndexColumns i JOIN #Columns c ON i.ObjectID = c.ObjectID AND i.ColumnID = c.ColumnID WHERE i.ObjectID = t.ObjectID AND i.IndexID = t.IndexID AND i.IsIncluded = 1 ORDER BY i.OrderID FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '') FROM ( SELECT DISTINCT ObjectID, IndexID FROM #Indexes WHERE IndexType IN (1, 2) ) t SELECT i.ObjectID , i.IndexID , i.IndexName , ObjectName = o.[name] , SchemaName = s.[name] , i.PagesCount , i.UnusedPagesCount , i.PartitionNumber , i.RowsCount , i.IndexType , i.IsAllowPageLocks , u.TotalWrites , u.TotalReads , u.TotalSeeks , u.TotalScans , u.TotalLookups , u.LastUsage , i.DataCompression , f.Fragmentation , IndexStats = STATS_DATE(i.ObjectID, i.IndexID) , IsLobLegacy = ISNULL(lob.IsLobLegacy, 0) , IsLob = ISNULL(lob.IsLob, 0) , IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT) , IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT) , FileGroupName = fg.[name] , i.IsUnique , i.IsPK , i.FillFactorValue , i.IsFiltered , a.IndexColumns , a.IncludedColumns FROM #Indexes i JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id] LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID AND a.IndexID = i.IndexID LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID AND f.IndexID = i.IndexID AND f.PartitionNumber = i.PartitionNumber LEFT JOIN ( SELECT ObjectID = [object_id] , IndexID = [index_id] , TotalWrites = NULLIF([user_updates], 0) , TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0) , TotalSeeks = NULLIF([user_seeks], 0) , TotalScans = NULLIF([user_scans], 0) , TotalLookups = NULLIF([user_lookups], 0) , LastUsage = ( SELECT MAX(dt) FROM ( VALUES ([last_user_seek]) , ([last_user_scan]) , ([last_user_lookup]) , ([last_user_update]) ) t(dt) ) FROM sys.dm_db_index_usage_stats WITH(NOLOCK) WHERE [database_id] = @DBID ) u ON i.ObjectID = u.ObjectID AND i.IndexID = u.IndexID LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID AND lob.IndexID = i.IndexID LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id] AND i.PartitionNumber = dds.[destination_id] JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id] WHERE o.[type] IN ('V', 'U') AND ( f.Fragmentation >= @Fragmentation OR i.PagesCount > @PreDescribeSize OR i.IndexType IN (5, 6) ) As you can see from the queries themselves, temporary tables are often used. This was done so that there would be no recompilation, and in the case of a large scheme, the plan could be generated parallel when inserting data, since inserting with table variables is possible in only one stream.
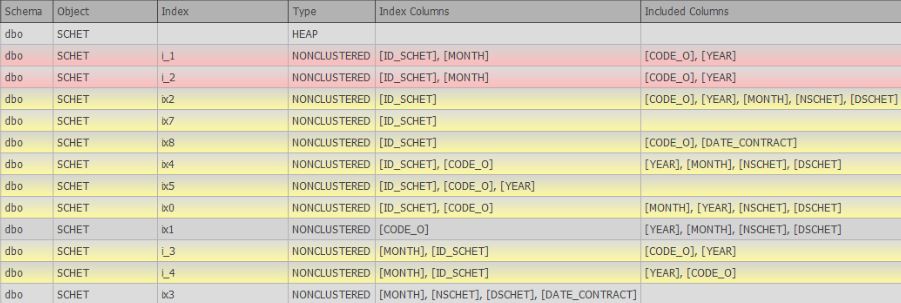
After executing the above script, a window with the index table will appear:
Here you can also display other detailed information, such as:
- database
- number of sections
- date and time of last call
- compression
- filegroup
etc.
The columns themselves can be customized:
In the cells of the Fix column, you can choose what action will be performed during optimization. Also, when scanning is completed, the default action is selected based on the selected settings:
You must select the desired indexes for processing.
Using the main menu, you can save the script (the same button starts the index optimization process itself):
save the table in different formats (the same button allows you to open detailed settings for analysis and optimization of indices):
Also, information can be updated by clicking on the third button on the left in the main menu next to the magnifying glass.
A button with a magnifying glass allows you to select the desired database for consideration.
There is currently no complete help system. Therefore, clicking on the “?” Button will simply cause a modal window to appear containing basic information about the software product:
In addition to all of the above, the main menu has a search bar:
When starting the index optimization process:
Also at the bottom of the window you can see the log of the actions performed:
In the window for detailed analysis and optimization of indexes, you can configure more subtle options:
Suggestions for the application:
- make it possible to selectively update statistics not only for indexes, but also in different ways (fully update or partially)
- make it possible not only to select the database, but also different servers (this is very convenient when there are many instances of MS SQL Server)
- for greater flexibility in use, it is proposed to wrap commands in libraries, and output them to PowerShell commands, as is done, for example, here:
- dbatools.io/commands
- make it possible to save and change personal settings both for the entire application and, if necessary, for each instance of MS SQL Server and each database
- from clauses 2 and 4 it follows the desire to make groups on databases and groups on instances of MS SQL Server, for which the settings are the same
- search for duplicate indexes (full and incomplete, which either differ slightly or differ only in the included columns)
- Since SQLIndexManager is used only for MS SQL Server DBMS, you need to reflect this in the name, for example, as follows: SQLIndexManager for MS SQL Server
- Remove all parts of the application from the GUI into separate modules and rewrite them to .NET Core 2.1
At the time of writing, article 6 of the wishes is actively being developed and there is already support in the form of a search for complete and similar duplicates:
Sources
Source: https://habr.com/ru/post/461277/
All Articles