Greedy approach and slot machines. Analysis of the tasks of the ML-track of the programming championship

We continue to publish analyzes of the tasks that were proposed at the recent championship. Next in line are tasks taken from the qualification round for machine learning specialists. This is the third track out of four (backend, frontend, ML, analytics). Participants needed to make a model for correcting typos in texts, propose a strategy for playing on slot machines, bring to mind a system of recommendations for content, and compose several more programs.
A. Typos
Condition
| All languages | python2.7 + numpy | python3.5 + numpy | |
| Time limit | 1 s | 5 s | 5 s |
| Memory limit | 64 MB | 256 MB | 256 MB |
| Enter | standard input or input.txt | ||
| Conclusion | standard output or output.txt | ||
- Who composed this nonsense?
- Astrophysicists. They are people too.
- You made 10 mistakes in the word “journalists”.
')
Many users make typing errors, some because of hitting keys, some because of their illiteracy. We want to check if the user could really mean some other word than the one he typed.
More formally, suppose that the following error model takes place: the user begins with a word that he wants to write, and then subsequently makes a number of errors in it. Each mistake is a substitution of some substring of the word for another substring. One error corresponds to replacing only in one position (that is, if the user wants to make a single error by the rule “abc” → “cba”, then from the line “abcabc” he can get either “cbaabc” or “abccba”). After each error, the process repeats. The same rule could be used several times in different steps (for example, in the above example, “cbacba” could be obtained in two steps).
It is required to determine the minimum number of errors a user could make if he had in mind one given word and wrote another.
I / O Formats and Example
The first line contains the word, which, according to our assumption, the user had in mind (it consists of letters of the Latin alphabet in lower case, the length does not exceed 20).
The second line contains the word that he actually wrote (it also consists of letters of the Latin alphabet in lower case, the length does not exceed 20).
The third line contains a single number N (N <50) - the number of replacements that describe various errors.
The next N lines contain possible replacements in the format & lt "correct" letter sequence & gt <space> <"erroneous" letter sequence>. Sequences are no more than 6 characters long.
It is required to print one number - the minimum number of errors that the user could make. If this number exceeds 4 or it is impossible to get another from one word, print -1.
Input format
The first line contains the word, which, according to our assumption, the user had in mind (it consists of letters of the Latin alphabet in lower case, the length does not exceed 20).
The second line contains the word that he actually wrote (it also consists of letters of the Latin alphabet in lower case, the length does not exceed 20).
The third line contains a single number N (N <50) - the number of replacements that describe various errors.
The next N lines contain possible replacements in the format & lt "correct" letter sequence & gt <space> <"erroneous" letter sequence>. Sequences are no more than 6 characters long.
Output format
It is required to print one number - the minimum number of errors that the user could make. If this number exceeds 4 or it is impossible to get another from one word, print -1.
Example
| Enter | Conclusion |
mlax | 4 |
Decision
Let's try to generate from the correct spelling all possible words with no more than 4 errors. In the worst case, there may be O ((L﹒N) 4 ). In the limitations of the problem, this is a rather large number, so you need to figure out how to reduce complexity. Instead, you can use the meet-in-the-middle algorithm: generate words with no more than 2 errors, as well as words from which you can get a user-written word with no more than 2 errors. Note that the size of each of these sets will not exceed 10 6 . If the number of errors made by the user does not exceed 4, then these sets will intersect. Similarly, we can verify that the number of errors does not exceed 3, 2, and 1.
struct FromTo { std::string from; std::string to; }; std::pair<size_t, std::string> applyRule(const std::string& word, const FromTo &fromTo, int pos) { while(true) { int from = word.find(fromTo.from, pos); if (from == std::string::npos) { return {std::string::npos, {}}; } int to = from + fromTo.from.size(); auto cpy = word; for (int i = from; i < to; i++) { cpy[i] = fromTo.to[i - from]; } return {from, std::move(cpy)}; } } void inverseRules(std::vector<FromTo> &rules) { for (auto& rule: rules) { std::swap(rule.from, rule.to); } } int solve(std::string& wordOrig, std::string& wordMissprinted, std::vector<FromTo>& replaces) { std::unordered_map<std::string, int> mapping; std::unordered_map<int, std::string> mappingInverse; mapping.emplace(wordOrig, 0); mappingInverse.emplace(0, wordOrig); mapping.emplace(wordMissprinted, 1); mappingInverse.emplace(1, wordMissprinted); std::unordered_map<int, std::unordered_set<int>> edges; auto buildGraph = [&edges, &mapping, &mappingInverse](int startId, const std::vector<FromTo>& replaces, bool dir) { std::unordered_set<int> mappingLayer0; mappingLayer0 = {startId}; for (int i = 0; i < 2; i++) { std::unordered_set<int> mappingLayer1; for (const auto& v: mappingLayer0) { auto& word = mappingInverse.at(v); for (auto& fromTo: replaces) { size_t from = 0; while (true) { auto [tmp, wordCpy] = applyRule(word, fromTo, from); if (tmp == std::string::npos) { break; } from = tmp + 1; { int w = mapping.size(); mapping.emplace(wordCpy, w); w = mapping.at(wordCpy); mappingInverse.emplace(w, std::move(wordCpy)); if (dir) { edges[v].emplace(w); } else { edges[w].emplace(v); } mappingLayer1.emplace(w); } } } } mappingLayer0 = std::move(mappingLayer1); } }; buildGraph(0, replaces, true); inverseRules(replaces); buildGraph(1, replaces, false); { std::queue<std::pair<int, int>> q; q.emplace(0, 0); std::vector<bool> mask(mapping.size(), false); int level{0}; while (q.size()) { auto [w, level] = q.front(); q.pop(); if (mask[w]) { continue; } mask[w] = true; if (mappingInverse.at(w) == wordMissprinted) { return level; } for (auto& v: edges[w]) { q.emplace(v, level + 1); } } } return -1; } B. Many-armed bandit
Condition
| Time limit | 2 s |
| Memory limit | 64 MB |
| Enter | standard input |
| Conclusion | standard output |
You yourself do not know how it happened, but you found yourself in a hall with slot machines with a whole bag of tokens. Unfortunately, at the box office, they refuse to accept tokens back, and you decided to try your luck. There are many slot machines in the hall that you can play. For one game with a slot machine you use one token. In case of a win, the machine gives you one dollar, in case of a loss - nothing. Each machine has a fixed probability of winning (which you do not know), but it is different for different machines. Having studied the website of the manufacturer of these machines, you found out that the probability of winning for each machine is randomly selected at the manufacturing stage from a beta distribution with certain parameters.
You want to maximize your expected winnings.
I / O Formats and Example
One execution may consist of several tests.
Each test starts with the fact that your program contains two integers in one line, separated by a space: the number N is the number of tokens in your bag, and M is the number of machines in the hall (N ≤ 10 4 , M ≤ min (N, 100) ) The next line contains two real numbers α and β (1 ≤ α, β ≤ 10) - the parameters of the beta distribution of the probability of winning.
The communication protocol with the checking system is this: you make exactly N requests. For each request, print in a separate line the number of the machine you will play (from 1 to M inclusive). As an answer, in a separate line there will be either “0” or “1”, meaning respectively a loss and a win in a game with the requested slot machine.
After the last test, instead of the numbers N and M, there will be two zeros.
The task will be considered completed if your decision is not much worse than the decision of the jury. If your decision is significantly worse than the jury's decision, you will receive the verdict “wrong answer”.
It is guaranteed that if your decision is no worse than the decision of the jury, then the probability of receiving the verdict “incorrect answer” does not exceed 10-6 .
Interaction Example:
Input format
One execution may consist of several tests.
Each test starts with the fact that your program contains two integers in one line, separated by a space: the number N is the number of tokens in your bag, and M is the number of machines in the hall (N ≤ 10 4 , M ≤ min (N, 100) ) The next line contains two real numbers α and β (1 ≤ α, β ≤ 10) - the parameters of the beta distribution of the probability of winning.
The communication protocol with the checking system is this: you make exactly N requests. For each request, print in a separate line the number of the machine you will play (from 1 to M inclusive). As an answer, in a separate line there will be either “0” or “1”, meaning respectively a loss and a win in a game with the requested slot machine.
After the last test, instead of the numbers N and M, there will be two zeros.
Output format
The task will be considered completed if your decision is not much worse than the decision of the jury. If your decision is significantly worse than the jury's decision, you will receive the verdict “wrong answer”.
It is guaranteed that if your decision is no worse than the decision of the jury, then the probability of receiving the verdict “incorrect answer” does not exceed 10-6 .
Notes
Interaction Example:
____________________ stdin stdout ____________________ ____________________ 5 2 2 2 2 1 1 0 1 1 2 1 2 1 Decision
This problem is well known, it could be solved in different ways. The main decision of the jury implemented the Thompson sampling strategy, but since the number of steps was known at the beginning of the program, there are more optimal strategies (for example, UCB1). Moreover, one could even get by with the epsilon-greedy-strategy: with a certain probability ε play a random machine and with a probability (1 - ε) play a machine with the best victory statistics.
class SolverFromStdIn(object): def __init__(self): self.regrets = [0.] self.total_win = [0.] self.moves = [] class ThompsonSampling(SolverFromStdIn): def __init__(self, bandits_total, init_a=1, init_b=1): """ init_a (int): initial value of a in Beta(a, b). init_b (int): initial value of b in Beta(a, b). """ SolverFromStdIn.__init__(self) self.n = bandits_total self.alpha = init_a self.beta = init_b self._as = [init_a] * self.n # [random.betavariate(self.alpha, self.beta) for _ in range(self.n)] self._bs = [init_b] * self.n # [random.betavariate(self.alpha, self.beta) for _ in range(self.n)] self.last_move = -1 random.seed(int(time.time())) def move(self): samples = [random.betavariate(self._as[x], self._bs[x]) for x in range(self.n)] self.last_move = max(range(self.n), key=lambda x: samples[x]) self.moves.append(self.last_move) return self.last_move def set_reward(self, reward): i = self.last_move r = reward self._as[i] += r self._bs[i] += (1 - r) return i, r while True: n, m = map(int, sys.stdin.readline().split()) if n == 0 and m == 0: break alpha, beta = map(float, sys.stdin.readline().split()) solver = ThompsonSampling(m) for _ in range(n): print >> sys.stdout, solver.move() + 1 sys.stdout.flush() reward = int(sys.stdin.readline()) solver.set_reward(reward) C. Alignment of sentences
Condition
| Time limit | 2 s |
| Memory limit | 64 MB |
| Enter | standard input or input.txt |
| Conclusion | standard output or output.txt |
More formally, suppose the following generative model for parallel enclosures is true. At each step, we do one of the following:
1. Stop
With probability p h, hull generation ends.
2. [1-0] Skipping offers
With probability p d we ascribe one sentence to the original text. We do not attribute anything to the translation. The length of the sentence in the original language L ≥ 1 is selected from the discrete distribution:
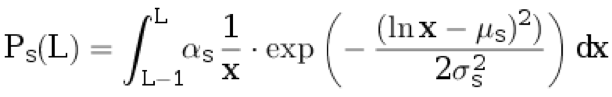 .
.Here μ s , σ s are the distribution parameters, and α s is the normalization coefficient chosen so that
 .
.3. [0-1] Insert proposal
With probability p i we ascribe one sentence to the translation. We do not ascribe anything to the original. The length of a sentence in a translation language L ≥ 1 is selected from a discrete distribution:
 .
.Here μ t , σ t are the distribution parameters, and α t is the normalization coefficient chosen so that
 .
.4. Translation
With probability (1 - p d - p i - p h ) we take the length of the sentence in the original language L s ≥ 1 from the distribution p s (with rounding up). Next, we generate the length of the sentence in the translation language L t ≥ 1 from the conditional discrete distribution:
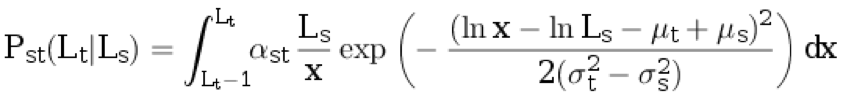 .
.Here, α st is the normalization coefficient, and the remaining parameters are described in the previous paragraphs.
Next is another step:
1. [2-1] With probability p split s, the generated sentence in the original language splits into two non-empty sentences, so that the total number of words increases by exactly one . The probability that a sentence of length L s will fall apart into parts of length L 1 and L 2 (that is, L 1 + L 2 = L s + 1) is proportional to P s (L 1 ) ⋅ P s (L 2 ).
2. [1-2] With probability p split t, the generated sentence in the target language splits into two non-empty sentences, so that the total number of words increases by exactly one. The probability that a sentence of length L t will fall apart into parts of length L1 and L2 (that is, L 1 + L 2 = L t + 1) is proportional to P t (L 1 ) ⋅ P t (L 2 ).
3. 3. [1-1] With the probability (1 - p split s - p split t ), none of the pair of generated sentences will decay.
I / O Formats, Examples, and Notes
The first line of the file contains the distribution parameters: p h , p d , p i , p split s , p split t , μ s , σ s , μ t , σ t . 0.1 ≤ σ s <σ t ≤ 3. 0 ≤ μ s , μ t ≤ 5.
The next line contains the numbers N s and N t - the number of sentences in the case in the original language and in the target language, respectively (1 ≤ N s , N t ≤ 1000).
The next line contains N s integers - the lengths of sentences in the original language. The next line contains N t integers - the lengths of sentences in the target language.
The next line contains two numbers: j and k (1 ≤ j ≤ N s , 1 ≤ k ≤ N t ).
It is required to derive the probability that sentences with indices j and k in the texts, respectively, are parallel (that is, that they are generated at one step of the algorithm and none of them is the result of decay).
Your answer will be accepted if the absolute error does not exceed 10 –4 .
In the first example, the initial sequence of numbers can be obtained in three ways:
• First, with probability p d, add one sentence to the original text, then with probability p i add one sentence to the translation, then with probability p h finish the generation.
The probability of this event is P 1 = p d * P s (4) * p i * P t (20) * p h .
• First, with probability p d, add one sentence to the original text, then with probability p i add one sentence to the translation, then with probability p h finish the generation.
The probability of this event is equal to P 2 = p i * P t (20) * p d * P s (4) * p h .
• With probability (1 - p h - p d - p i ) generate two sentences, then with probability (1 - p split s - p split t ) leave everything as it is (that is, do not split the original or the translation into two sentences ) and after that with probability p h finish the generation.
The probability of this event is
 .
.
As a result, the answer is calculated as .
.
Input format
The first line of the file contains the distribution parameters: p h , p d , p i , p split s , p split t , μ s , σ s , μ t , σ t . 0.1 ≤ σ s <σ t ≤ 3. 0 ≤ μ s , μ t ≤ 5.
The next line contains the numbers N s and N t - the number of sentences in the case in the original language and in the target language, respectively (1 ≤ N s , N t ≤ 1000).
The next line contains N s integers - the lengths of sentences in the original language. The next line contains N t integers - the lengths of sentences in the target language.
The next line contains two numbers: j and k (1 ≤ j ≤ N s , 1 ≤ k ≤ N t ).
Output format
It is required to derive the probability that sentences with indices j and k in the texts, respectively, are parallel (that is, that they are generated at one step of the algorithm and none of them is the result of decay).
Your answer will be accepted if the absolute error does not exceed 10 –4 .
Example 1
| Enter | Conclusion |
0.05 0.08 0.07 0.15 0.1 1 0.3 3 0.5 | 0.975037457809 |
Example 2
| Enter | Conclusion |
0.1 0.2 0.3 0.25 0.3 1 0.3 3 0.5 | 0.247705779810 |
Example 3
| Enter | Conclusion |
0.2 0.2 0.2 0.3 0.3 3 0.3 1 1 | 0.200961101684 |
Notes
In the first example, the initial sequence of numbers can be obtained in three ways:
• First, with probability p d, add one sentence to the original text, then with probability p i add one sentence to the translation, then with probability p h finish the generation.
The probability of this event is P 1 = p d * P s (4) * p i * P t (20) * p h .
• First, with probability p d, add one sentence to the original text, then with probability p i add one sentence to the translation, then with probability p h finish the generation.
The probability of this event is equal to P 2 = p i * P t (20) * p d * P s (4) * p h .
• With probability (1 - p h - p d - p i ) generate two sentences, then with probability (1 - p split s - p split t ) leave everything as it is (that is, do not split the original or the translation into two sentences ) and after that with probability p h finish the generation.
The probability of this event is
.As a result, the answer is calculated as
.Decision
The task is a special case of alignment using hidden Markov models (HMM alignment). The main idea is that you can calculate the probability of generating a specific pair of documents using this model and the forward algorithm : in this case, the state is a pair of document prefixes. Accordingly, the required probability of alignment of a specific pair of parallel sentences can be calculated by the forward-backward algorithm.
Code
#include <iostream> #include <iomanip> #include <cmath> #include <vector> double p_h, p_d, p_i, p_tr, p_ss, p_st, mu_s, sigma_s, mu_t, sigma_t; double lognorm_cdf(double x, double mu, double sigma) { if (x < 1e-9) return 0.0; double res = std::log(x) - mu; res /= std::sqrt(2.0) * sigma; res = 0.5 * (1 + std::erf(res)); return res; } double length_probability(int l, double mu, double sigma) { return lognorm_cdf(l, mu, sigma) - lognorm_cdf(l - 1, mu, sigma); } double translation_probability(int ls, int lt) { double res = length_probability(ls, mu_s, sigma_s); double mu = mu_t - mu_s + std::log(ls); double sigma = std::sqrt(sigma_t * sigma_t - sigma_s * sigma_s); res *= length_probability(lt, mu, sigma); return res; } double split_probability(int l1, int l2, double mu, double sigma) { int l_sum = l1 + l2; double total_prob = 0.0; for (int i = 1; i < l_sum; ++i) { total_prob += length_probability(i, mu, sigma) * length_probability(l_sum - i, mu, sigma); } return length_probability(l1, mu, sigma) * length_probability(l2, mu, sigma) / total_prob; } double log_prob10(int ls) { return std::log(p_d * length_probability(ls, mu_s, sigma_s)); } double log_prob01(int lt) { return std::log(p_i * length_probability(lt, mu_t, sigma_t)); } double log_prob11(int ls, int lt) { return std::log(p_tr * (1 - p_ss - p_st) * translation_probability(ls, lt)); } double log_prob21(int ls1, int ls2, int lt) { return std::log(p_tr * p_ss * split_probability(ls1, ls2, mu_s, sigma_s) * translation_probability(ls1 + ls2 - 1, lt)); } double log_prob12(int ls, int lt1, int lt2) { return std::log(p_tr * p_st * split_probability(lt1, lt2, mu_t, sigma_t) * translation_probability(ls, lt1 + lt2 - 1)); } double logsum(double v1, double v2) { double res = std::max(v1, v2); v1 -= res; v2 -= res; v1 = std::min(v1, v2); if (v1 < -30) { return res; } return res + std::log(std::exp(v1) + 1.0); } double loginc(double* to, double from) { *to = logsum(*to, from); } constexpr double INF = 1e25; int main(void) { using std::cin; using std::cout; cin >> p_h >> p_d >> p_i >> p_ss >> p_st >> mu_s >> sigma_s >> mu_t >> sigma_t; p_tr = 1.0 - p_h - p_d - p_i; int Ns, Nt; cin >> Ns >> Nt; using std::vector; vector<int> ls(Ns), lt(Nt); for (int i = 0; i < Ns; ++i) cin >> ls[i]; for (int i = 0; i < Nt; ++i) cin >> lt[i]; vector< vector< double> > fwd(Ns + 1, vector<double>(Nt + 1, -INF)), bwd = fwd; fwd[0][0] = 0; bwd[Ns][Nt] = 0; for (int i = 0; i <= Ns; ++i) { for (int j = 0; j <= Nt; ++j) { if (i >= 1) { loginc(&fwd[i][j], fwd[i - 1][j] + log_prob10(ls[i - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j] + log_prob10(ls[Ns - i])); } if (j >= 1) { loginc(&fwd[i][j], fwd[i][j - 1] + log_prob01(lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i][Nt - j + 1] + log_prob01(lt[Nt - j])); } if (i >= 1 && j >= 1) { loginc(&fwd[i][j], fwd[i - 1][j - 1] + log_prob11(ls[i - 1], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 1] + log_prob11(ls[Ns - i], lt[Nt - j])); } if (i >= 2 && j >= 1) { loginc(&fwd[i][j], fwd[i - 2][j - 1] + log_prob21(ls[i - 1], ls[i - 2], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 2][Nt - j + 1] + log_prob21(ls[Ns - i], ls[Ns - i + 1], lt[Nt - j])); } if (i >= 1 && j >= 2) { loginc(&fwd[i][j], fwd[i - 1][j - 2] + log_prob12(ls[i - 1], lt[j - 1], lt[j - 2])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 2] + log_prob12(ls[Ns - i], lt[Nt - j], lt[Nt - j + 1])); } } } int j, k; cin >> j >> k; double rlog = fwd[j - 1][k - 1] + bwd[j][k] + log_prob11(ls[j - 1], lt[k - 1]) - bwd[0][0]; cout << std::fixed << std::setprecision(12) << std::exp(rlog) << std::endl; } D. Guideline
Condition
| Time limit | 2 s |
| Memory limit | 64 MB |
| Enter | standard input or input.txt |
| Conclusion | standard output or output.txt |
Let an initial list of recommendations be given a = [a 0 , a 1 , ..., a n - 1 ] of length n> 0. An object with number i has type with number b i ∈ {0, ..., m - 1}. In addition, an object under number i has relevance r (a i ) = 2 −i . Consider the list that is obtained from the initial one by selecting a subset of objects and rearranging them: x = [a i 0 , a i 1 , ..., a i k − 1 ] of length k (0 ≤ k ≤ n). A list is called admissible if no two consecutive objects in it match in type, i.e., b i j ≠ b i j + 1 for all j = 0, ..., k − 2. The relevance of the list is calculated by the formula . You need to find the maximum relevance list among all valid.
I / O Formats and Examples
The first line contains space-separated numbers n and m (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). The next n lines contain the numbers b i for i = 0, ..., n - 1 (0 ≤ b i ≤ m - 1).
Write out, with a space, the numbers of objects in the final list: i 0 , i 1 , ..., i k − 1 .
Input format
The first line contains space-separated numbers n and m (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). The next n lines contain the numbers b i for i = 0, ..., n - 1 (0 ≤ b i ≤ m - 1).
Output format
Write out, with a space, the numbers of objects in the final list: i 0 , i 1 , ..., i k − 1 .
Example 1
| Enter | Conclusion |
1 1 | 0 |
Example 2
| Enter | Conclusion |
2 2 | 0 |
Example 3
| Enter | Conclusion |
10 2 | 0 3 1 4 2 6 5 |
Decision
Using simple mathematical calculations, it can be shown that the problem can be solved by a “greedy” approach, that is, in the optimal list of recommendations, each position has the most relevant object of all that are valid at the same beginning of the list. The implementation of this approach is simple: we take objects in a row and add them to the answer, if possible. When an invalid object is encountered (the type of which coincides with the type of the previous one), we put it aside in a separate queue, from which we insert it into the response as soon as possible. Note that at every moment in time, all objects in this queue will have a matching type. At the end, several objects may remain in the queue, they will no longer be included in the response.
std::vector<int> blend(int n, int m, const std::vector<int>& types) { std::vector<int> result; std::queue<int> repeated; for (int i = 0; i < n; ++i) { if (result.empty() || types[result.back()] != types[i]) { result.push_back(i); if (!repeated.empty() && types[repeated.front()] != types[result.back()]) { result.push_back(repeated.front()); repeated.pop(); } } else { repeated.push(i); } } return result; } D. Clustering character sequences
| All languages | python2.7 + numpy | python3.5 + numpy | |
| Time limit | 1 s | 6 s | 6 s |
| Memory limit | 64 MB | 64 MB | 64 MB |
| Enter | standard input or input.txt | ||
| Conclusion | standard output or output.txt | ||
Consider the following method of generating random strings over the alphabet A:
1. The first character x 1 is a random variable with the distribution P (x 1 = a i ) = q i (it is known that q K = 0).
2. Each next character is generated on the basis of the previous one in accordance with the conditional distribution P (x i = a j || x i - 1 = a l ) = p jl .
3. If x i = S, generation stops and the result is x 1 x 2 ... x i − 1 .
A set of lines generated from a mixture of two described models with different parameters is given. It is necessary for each row to give the index of the chain from which it was generated.
I / O Formats, Example and Notes
The first line contains two numbers 1000 ≤ N ≤ 2000 and 3 ≤ K ≤ 27 - the number of lines and the size of the alphabet, respectively.
The second line contains a line consisting of K − 1 different lowercase letters of the Latin alphabet, indicating the first K − 1 elements of the alphabet.
Each of the following N lines is generated according to the algorithm described in the condition.
N lines, the i-th line contains the cluster number (0/1) for the sequence on the i + 1-th line of the input file. Coincidence with the true answer should be at least 80%.
Note to the test from the condition: in it the first 50 lines are generated from the distribution
P (x i = a | x i − 1 = a) = 0.5, P (x i = S | x i − 1 = a) = 0.5, P (x 1 = a) = 1; second 50 - from distribution
P (x i = b | x i − 1 = b) = 0.5, P (x i = S | x i − 1 = b) = 0.5, P (x 1 = b) = 1.
Input format
The first line contains two numbers 1000 ≤ N ≤ 2000 and 3 ≤ K ≤ 27 - the number of lines and the size of the alphabet, respectively.
The second line contains a line consisting of K − 1 different lowercase letters of the Latin alphabet, indicating the first K − 1 elements of the alphabet.
Each of the following N lines is generated according to the algorithm described in the condition.
Output format
N lines, the i-th line contains the cluster number (0/1) for the sequence on the i + 1-th line of the input file. Coincidence with the true answer should be at least 80%.
Example
| Enter | Conclusion |
100 3 | 0 |
Notes
Note to the test from the condition: in it the first 50 lines are generated from the distribution
P (x i = a | x i − 1 = a) = 0.5, P (x i = S | x i − 1 = a) = 0.5, P (x 1 = a) = 1; second 50 - from distribution
P (x i = b | x i − 1 = b) = 0.5, P (x i = S | x i − 1 = b) = 0.5, P (x 1 = b) = 1.
Decision
The problem is solved using the EM algorithm : it is assumed that the presented sample is generated from a mixture of two Markov chains whose parameters are restored during iterations. A restriction of 80% of the correct answers is made so that the correctness of the solution is not affected by examples that have a high probability in both chains. These examples, therefore, if properly restored, can be assigned to a chain that is incorrect in terms of the generated response.
import random import math EPS = 1e-9 def empty_row(size): return [0] * size def empty_matrix(rows, cols): return [empty_row(cols) for _ in range(rows)] def normalized_row(row): row_sum = sum(row) + EPS return [x / row_sum for x in row] def normalized_matrix(mtx): return [normalized_row(r) for r in mtx] def restore_params(alphabet, string_samples): n_tokens = len(alphabet) n_samples = len(string_samples) samples = [tuple([alphabet.index(token) for token in s] + [n_tokens - 1, n_tokens - 1]) for s in string_samples] probs = [random.random() for _ in range(n_samples)] for _ in range(200): old_probs = [x for x in probs] # probs fixed p0, A = empty_row(n_tokens), empty_matrix(n_tokens, n_tokens) q0, B = empty_row(n_tokens), empty_matrix(n_tokens, n_tokens) for prob, sample in zip(probs, samples): p0[sample[0]] += prob q0[sample[0]] += 1 - prob for t1, t2 in zip(sample[:-1], sample[1:]): A[t1][t2] += prob B[t1][t2] += 1 - prob A, p0 = normalized_matrix(A), normalized_row(p0) B, q0 = normalized_matrix(B), normalized_row(q0) trans_log_diff = [ [math.log(b + EPS) - math.log(a + EPS) for b, a in zip(B_r, A_r)] for B_r, A_r in zip(B, A) ] # A, p0, B, q0 fixed probs = empty_row(n_samples) for i, sample in enumerate(samples): value = math.log(q0[sample[0]] + EPS) - math.log(p0[sample[0]] + EPS) for t1, t2 in zip(sample[:-1], sample[1:]): value += trans_log_diff[t1][t2] probs[i] = 1.0 / (1.0 + math.exp(value)) if max(abs(x - y) for x, y in zip(probs, old_probs)) < 1e-9: break return [int(x > 0.5) for x in probs] def main(): N, K = list(map(int, input().split())) string_samples = [] alphabet = list(input().strip()) + [''] for _ in range(N): string_samples.append(input().rstrip()) result = restore_params(alphabet, string_samples) for r in result: print(r) if __name__ == '__main__': main() Here are the breakdowns of tasks on the backend and frontend .
Source: https://habr.com/ru/post/461273/
All Articles