Auto Test: Ten Lifehacks from Skyeng Team

Hi, I’m Andrey Shalnev, QA Automation Lead in the Skyeng Vimbox project. During the year, the team and I were engaged in optimizing the processes of automatic testing and now we have come close to its final stage. And this is a good reason to exhale, review the backlog and take some intermediate results. For Habra, I decided to make a selection of the ten most useful and at the same time simple things that helped us cope with the task of optimizing autotests. I hope the article will be useful to QA teams in growing companies, where the old testing processes can no longer cope with the load, and the issue of reorganization raises an edge.
How we have autotests arranged now
Vimbox uses Angular for the frontend, so we write tests on the fairly classic stack for this solution - Protractor + Jasmine + JS / Typescript. Over the year, we have significantly redesigned the regression test suite. In its initial form, it was redundant and not very convenient - tests of several hundred lines with a passage time of 5-10 minutes, with this length of a separate test script, it very often does not reach the end due to a false file. Now we divided the tests into shorter and more stable scenarios, we use failFast so that the run time is acceptable (a test that crashes in the middle will not try to complete every next step and wait for it to timeout). In addition, we got rid of redundant checks: we make sure that a particular feature is functional in general, but we do not try to check it in all possible variations.
Auto tests are prioritized. A small set of the highest priorities - User acceptance test (UAT) - runs every hour on the timer on the prod, after the deployment of the main projects and when testing tasks on test stands.
The process at the stands looks like this: the developer transfers the task to testing, QA deploys it to his stand and runs the tests - both UAT and regression. In UAT we have about 150 cases, regression - about 700 tests, it is constantly updated. Most cases that are important and critical, this suite covers about 80% and runs at each iteration.
Ten Lifehacks
Explicitly specify the role of the browser instance . The specificity of Vimbox tests is that in the vast majority of cases two or even more browser instances are used, since the lesson has at least two sides - a teacher and a student. There used to be a problem: a browser instance was indicated by a number, it was understood that everyone understood that
browser1was a teacher, andbrowser2and beyond were students. But this is not always the case, it happened that the student’s browser was the first. In addition, there are tests where the students themselves are different - for example, we need to make sure that you can not accidentally get into someone else's lesson. So that everyone could understand which user is in which browser instance, they began to explicitly indicate the role in its name:teacher.browser,student.browser,wrongStudent.browser, etc. Got more readable test scripts.We use arrow functions:
() =>, notfunction(). Firstly, such a record is shorter. Secondly, a more modern syntax, we try to move away from archaic. Third, arrow functions allow you to avoid problems with thethispointer from JavaScript. The arrow function does not create its lexical scope , so it is possible to refer to something defined outsidethis. Get rid of the classic crutchself=this.We use template strings instead of concatenation with pluses: `Student $ {studentName}`, and not "Student" + studentName . We try to use pattern strings instead of concatenations with pluses.
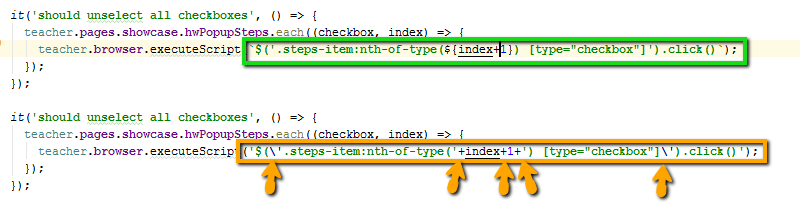
This is a modern syntax, it is more readable, inside the string you can use both types of quotation marks (single and double) and do not escape any of them.
We use TypeScript . Mostly for the sake of more adequate development environment hints and normal code navigation. Now in most cases, instead of a few tips, a direct transition to the method / field is possible. At the same time, switching to TypeScript did not require a lot of refactoring at the same time: for starters, you can simply change the file extensions from .js to .ts, the project remains workable. Then gradually change the syntax of
requiretoImport, navigation is improved.Break large Page Objects into subclasses to make it easier to maintain such objects. Our largest Page Object lesson reached four thousand lines of code, it was hard to leaf through, remember what was started, what was not. Now the longest code is about 1300 lines. It can be said that by doing so we got rid of the antipattern large class. In addition, they removed unnecessary comments and worked on the convenience and comprehensibility of the names of the methods: in most cases, if the method is named in accordance with the convention clear to everyone, a comment explaining its work is simply not needed.
We execute the UAT in parallel in several threads to facilitate the work with the UAT on the prod. The fact is that with us such a test runs once an hour and runs in one thread for 15 minutes. If a file happens in it, it will restart and in the end will work for half an hour. During a deployment, this can be a problem because the queue is delayed. The result of using the parallel is 2-3 minutes on the UAT (or 6 with a restart). The queue moves faster, information about the problem or that the file turned out to be false arrives faster.
We regularly run UAT and regression on test benches . Each of our manual testers has its own server. We used to run regression tests on prod already after the manual tester found a significant part of the bugs - in fact, we just checked for it. Now we run autotests at each iteration of manual testing of the task, which, firstly, facilitates the work of a manual tester (he does not need to pierce what is automatically), and secondly, shorten the feedback cycle. If a developer breaks something, he learns about it half an hour after rolling out the task, and not the next day. Plus, on the test bench, you can do many things that are undesirable on the production: change the version number of the product, delete / add test content, fearlessly edit the database to prepare the test situation, etc.
Delete empty files . We try to maintain consistency between the directory structure in autotests and in Testrail. But at the same time, at some point we ran into a problem - Testrail has a huge number of cases with low priority (only about 9000+ cases), because It is used as a project knowledge base. At the same time, only about a thousand of the most important cases are covered with autotests. If we achieve perfect match, we get a large number of unused files and directories. This complicates the navigation of the project and impairs the understanding of what is actually being tested. As a result, only the necessary folders and files were left, the rest was deleted.
We fix the bugs found . The main task of autotests is not to find bugs, but to quickly make sure that they are not there, so something is rarely detected. Fixation solves two problems: firstly, we see statistics where problems most often remain and which ones, and secondly, we get rid of the feeling that we are doing something wrong. When the tests do not find anything, the question arises: are we doing everything right, maybe our tests are no use? And then there is a tablet showing that when they were able to catch: more than 60 bugs per year. At the same time, the meaning of running tests on both prod and test servers became obvious. Frequent launch on the prod - every hour - helps to catch infrastructure problems (an external service is unavailable, our server went down), the launch before manual testing detects breakdowns introduced by the new code.
Implemented data-qa-id attributes , for example,
[data-qa-id="btn-login"]. Purpose: more stable selectors. We agreed with the development team that when changing the implementation of some elements, if they see thedata-qa-idattribute there, then they understand that this is for autotests, they do not change them and they transfer them accurately. This attribute has a logical name, which in itself is able to tell what the element is responsible for. In addition, we are not dependent on the particular implementation of the element - which regular id hangs on it, which class, tag, differential, link hangs on it. It became calmer: selectors break less often, in some cases additional information can be displayed with this attribute. For example, you need the name of a step in a lesson. If you turn to the name of the step through XPath, the selector can turn out to be long, multi-level and unreadable, and if you work with the html-template in the Angular code, you can display the same name in a short understandable attribute, bypassing the long XPath.
Share your life hacks and thoughts in the comments!
')
Source: https://habr.com/ru/post/461213/
All Articles