Top 65 SQL questions from job interviews you should be prepared for in 2019. Part I

Translation of the article was prepared for students of the course "MS SQL Server Developer"
Relational databases are one of the most commonly used databases to this day, and therefore SQL skills for most posts are required. In this article, with SQL questions from interviews, I will introduce you to the most frequently asked questions about SQL (Structured Query Language - Structured Query Language). This article is an ideal guide for exploring all concepts related to SQL, Oracle, MS SQL Server, and the MySQL database.
Our SQL question article is a universal resource with which you can speed up your interview preparation. It consists of a set of 65 of the most common questions that the interviewer can ask during the interview. It usually starts with basic SQL questions and then moves on to more complex ones based on the discussion and your answers. These SQL interview questions will help you get the most value at different levels of understanding.
Let's start!
Interview SQL Questions
Question 1. What is the difference between DELETE and TRUNCATE?
| DELETE | TRUNCATE |
|---|---|
| Used to delete a row in a table. | Used to delete all rows from a table. |
| You can recover data after deletion | You cannot restore data (translation comment: operations are logged differently, but SQL Server has the ability to roll back) transactions) |
| DML team | DDL command |
| Slower than the TRUNCATE statement | Faster |
No. Question 2. What are the subsets of SQL?
- DDL (Data Definition Language) - allows you to perform various operations with the database, such as CREATE (create), ALTER (change) and DROP (delete objects).
- DML (Data Manipulation Language) - allows you to access and manipulate data, for example, insert, update, delete and retrieve data from a database.
- DCL (Data Control Language) - allows you to control access to the database. An example is GRANT (grant rights), REVOKE (revoke rights).
Question 3. What is meant by DBMS? What types of DBMS are there?
Database is a structured data collection. Database Management System (DBMS) - software that interacts with the user, applications and the database itself to collect and analyze data. The DBMS allows the user to interact with the database. The data stored in the database can be modified, retrieved and deleted. They can be of any type, such as strings, numbers, images, etc.
There are two types of DBMS:
- Relational database management system: data is stored in relationships (tables). An example is MySQL.
- Non-relational database management system: there is no concept of relationships, tuples and attributes. An example is Mongo.
Question 4. What is meant by table and field in SQL?
A table is an organized data set in the form of rows and columns. A field is a column in a table. For example:
Table: Student_Information
Field: Stu_Id, Stu_Name, Stu_Marks
Question 5. What are joins in SQL?
The JOIN operator is used to join rows from two or more tables based on a column connected between them. It is used to join two tables or get data from there. There are 4 connection types in SQL, namely:
- Inner Join
- Right Join
- Left Join
- Full Join
Question 6. What is the difference between the CHAR and VARCHAR data types in SQL?
Both Char and Varchar serve as character data types, but varchar is used for variable-length character strings, while Char is used for fixed-length strings. For example, char (10) can only store 10 characters and cannot store a string of any other length, while varchar (10) can store a string of any length up to 10, i.e. e.g. 6, 8, or 2.
Question 7. What is a primary key?

- A primary key is a column or set of columns that uniquely identifies each row in a table.
- Uniquely identifies one row in a table
- Null values not allowed
_Example: In the Student Stu table, the primary key is.
Question 8. What are Constraints?
Constraints are used to indicate restrictions on the data type of a table. They can be specified when creating or modifying a table. Example restrictions:
- NOT NULL
- CHECK
- DEFAULT
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
Question 9. What is the difference between SQL and MySQL?
SQL is the standard Structured Query Language based on English, while MySQL is a database management system. SQL is a relational database language that is used to access and manage data, MySQL is a relational DBMS (database management system), as well as SQL Server, Informix, etc.
Question 10. What is a unique key?
- Uniquely identifies one row in a table.
- Many unique keys are allowed in one table.
- NULL values are allowed ( translation note: depends on the DBMS, in SQL Server, NULL can only be added once in a field with UNIQUE KEY ).
Question 11. What is a foreign key?
- A foreign key maintains referential integrity by providing a link between data in two tables.
- The foreign key in the child table refers to the primary key in the parent table.
- A foreign key constraint prevents actions that break the relationships between the child and parent tables.
Question 12. What is meant by data integrity?
Data integrity determines the accuracy as well as the consistency of the data stored in the database. It also defines integrity constraints to enforce business rules for data when they are entered into an application or database.
Question 13. What is the difference between clustered and nonclustered indexes in SQL?
- Differences between clustered and non-clustered indexes in SQL:
A clustered index is used to easily and quickly retrieve data from a database, while reading from a non-clustered index is relatively slower. - A clustered index changes the way records are stored in the database - it sorts the rows by a column that is set as a clustered index, while in a non-clustered index it does not change the storage method, but creates a separate object inside the table that points to the original table rows when searching.
- One table can have only one clustered index, while it can have many nonclustered ones.
Question 14. Write an SQL query to display the current date.
SQL has a built-in GetDate () function that helps return the current timestamp / date.
Question 15. List the types of connections
There are various types of joins that are used to extract data between tables. Basically, they are divided into four types, namely:
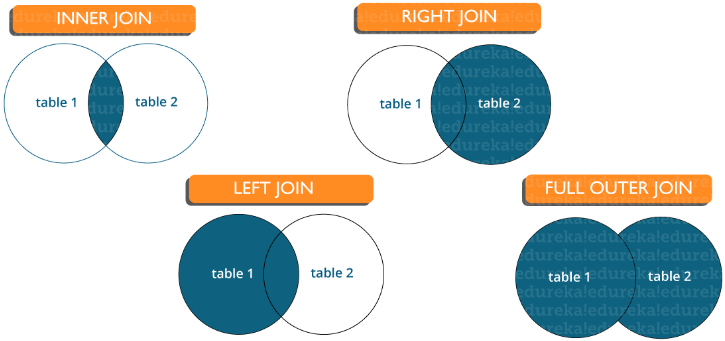
Inner join : In MySQL, the most common type. It is used to return all rows from several tables for which the join condition is fulfilled.
Left Join : in MySQL it is used to return all rows from the left (first) table and only matching rows from the right (second) table for which the join condition is fulfilled.
Right Join : in MySQL it is used to return all rows from the right (second) table and only matching rows from the left (first) table for which the join condition is fulfilled.
Full Join : Returns all records for which there is a match in any of the tables. Therefore, it returns all rows from the left table and all rows from the right table.
Question 16. What do you mean by denormalization?
Denormalization is a technique that is used to convert from higher to lower normal forms. It helps database developers improve the performance of the entire infrastructure by introducing redundancy into the table. It adds redundant data to the table, given the frequent database queries that combine data from different tables into one table.
Question 17. What are entities and relationships?
Entities: a person, place or object in the real world, data about which can be stored in a database. Tables store data that represents one type of entity. For example, a bank database has a customer table for storing customer information. The customer table stores this information as a set of attributes (columns in the table) for each customer.
Relations: relations or relationships between entities that are somehow related to each other. For example, the customer name is associated with the customer account number and contact information, which may be in the same table. There may also be relationships between individual tables (for example, customer to accounts).
Question 18. What is an index?
Indexes relate to a performance tuning method that enables faster retrieval of records from a table. The index creates a separate structure for the indexed field and, therefore, allows faster data retrieval.
Question 19. Describe the different types of indexes.
There are three types of indexes, namely:
- Unique Index: This index prevents the field from having duplicate values if the column is indexed uniquely. If a primary key is defined, a unique index can be applied automatically.
- Clustered Index: This index changes the physical order of the table and searches based on key values. Each table can have only one clustered index.
- Non-Clustered Index: Does not change the physical order of the table and maintains the logical order of the data. Each table can have many non-clustered indexes.
Question 20. What is normalization and what are its advantages?
Normalization is the process of organizing data, the purpose of which is to avoid duplication and redundancy. Some of the benefits:
- Best Database Organization
- More tables with small rows
- Effective Data Access
- Greater flexibility for queries
- Quick information search
- Easier to implement data security
- Allows easy modification
- Reduce redundant and duplicate data
- More compact database
- Ensures data consistency after changes
Question 21. What is the difference between DROP and TRUNCATE?
The DROP command deletes the table itself, and you cannot make Rollback commands, while the TRUNCATE command deletes all rows from the table ( note translation: in SQL Server, Rollback will normally work and roll back DROP ).
Question 22. Explain the different types of normalization.
There are many consecutive levels of normalization. These are the so-called normal forms. Each subsequent normal form includes the previous one. The first three normal forms are usually enough.
- First Normal Form (1NF) - no duplicate groups in rows
- The second normal form (2NF) - each non-key (supporting) column value depends on the entire primary key
- The third normal form (3NF) - each non-key value depends only on the primary key and does not depend on another non-key value of the column
Question 23. What is the ACID property in the database?
ACID means Atomicity, Consistency, Isolation, Durability. It is used to provide reliable processing of data transactions in the database system.
Atomicity. Ensures that the transaction is fully completed or fails, where the transaction represents a single logical data operation. This means that if one part of any transaction fails, the entire transaction fails and the state of the database remains unchanged.
Coherence. Ensures that data must comply with all validation rules. Simply put, you can say that your transaction will never leave your database in an invalid state.
Isolation. The main purpose of isolation is to control the mechanism of parallel data changes.
Durability. Durability implies that if the transaction was confirmed (COMMIT), the changes that occurred within the transaction will be preserved regardless of what might get in their way (for example, power loss, failure or errors of any kind).
Question 24. What do you mean by “trigger” in SQL?
A trigger in SQL is a special type of stored procedure that is designed to be automatically executed when or after data changes. This allows you to execute a code package when an insert, update, or any other query is performed on a specific table.
Question 25. What statements are available in SQL?
Three types of statements are available in SQL, namely:
- Arithmetic Operators
- Logical Operators
- Comparison operators
Question 26. Do NULL values match zero or space?
The value NULL is not at all equal to zero or a space. A NULL value represents a value that is not available, unknown, assigned, or not applicable, while zero is a number and space is a character.
Question 27. What is the difference between a cross join and a natural join?
A cross join creates a cross or Cartesian product of two tables, while a natural join is based on all columns that have the same name and data types in both tables.
Question 28. What is a subquery in SQL?
A subquery is a query inside another query that defines a query to retrieve data or information from a database. In a subquery, the outer query is called the main query, while the inner query is called the subquery. Subqueries are always executed first, and the result of the subquery is passed to the main query. It can be nested in SELECT, UPDATE, or any other query. A subquery can also use any comparison operator, such as>, <, or =.
Question 29. What are the types of subqueries?
There are two types of subqueries, namely: correlated and uncorrelated.
- Correlated subquery: this is a query that selects data from a table with a link to an external query. It is not considered an independent query because it refers to another table or column in the table.
- Uncorrelated subquery: This query is an independent query in which the subquery output is substituted into the main query.
Question 30. List the ways to get the number of records in the table?
To count the number of records in a table, you can use the following commands:SELECT * FROM table1SELECT COUNT(*) FROM table1SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
We will publish another 35 questions with answers in the next part ... Follow the news!
')
Source: https://habr.com/ru/post/461067/
All Articles