Kubernetes Dailymotion Adventure: Building Infrastructure in the Clouds + on-premises

Note perev. : Dailymotion is one of the largest video hosting services in the world and therefore a notable Kubernetes user. In this article, system architect David Donchez shares the results of creating a production platform for the company based on K8s, which began with a cloud installation in GKE and ended as a hybrid solution, which allowed to achieve better reaction time and save on infrastructure costs.
In deciding to rebuild the core Dailymotion API three years ago, we wanted to develop a more efficient way to host applications and facilitate the development and production processes . For this purpose, we decided to use the container orchestration platform and naturally chose Kubernetes.
')
Why is it worth creating your own Kubernetes-based platform?
Production level API in no time using Google Cloud
Summer of 2016
Three years ago, right after Vivendi bought Dailymotion, our engineering teams focused on one global goal: to create a completely new Dailymotion product.
Based on the analysis of containers, orchestration solutions and our past experience, we made sure that Kubernetes is the right choice. Some developers already had an idea of the basic concepts and knew how to use it, which was a huge advantage for infrastructure transformation.
In terms of infrastructure, a powerful and flexible system was needed to host new types of cloud-native applications. We chose to stay in the cloud at the beginning of our journey in order to calmly build the most reliable local platform. They decided to deploy their applications using the Google Kubernetes Engine, although they knew that sooner or later we would switch to our own data centers and apply a hybrid strategy.
Why choose GKE?
We made this choice mainly for technical reasons. In addition, it was necessary to quickly provide the infrastructure that meets the needs of the company’s business. We had some application requirements, such as geographic distribution, scalability, and fault tolerance.
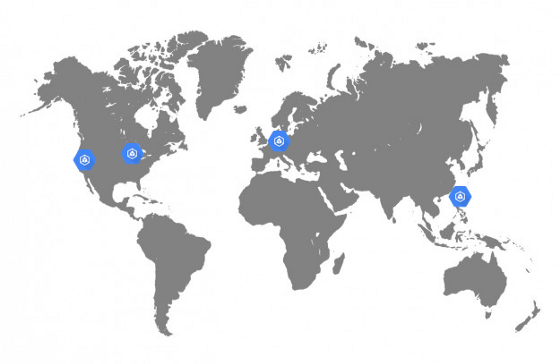
GKE clusters in Dailymotion
Since Dailymotion is a video platform available all over the world, we really wanted to improve the quality of service by reducing latency . Previously, our API was only available in Paris, which was not optimal. I wanted to be able to host applications not only in Europe, but also in Asia and the United States.
This delay sensitivity meant that we had to seriously work on the network architecture of the platform. While most cloud services forced them to create their own network in each region and then connect them through a VPN or a certain managed service, Google Cloud made it possible to create a fully routable unified network covering all regions of Google. This is a big plus in terms of operation and system efficiency.
In addition, network services and load balancers from Google Cloud do an excellent job. They simply allow you to use arbitrary public IP addresses from each region, and the wonderful BGP protocol takes care of the rest (i.e., redirects users to the nearest cluster). Obviously, in the event of a failure, traffic will automatically go to another region without any human intervention.
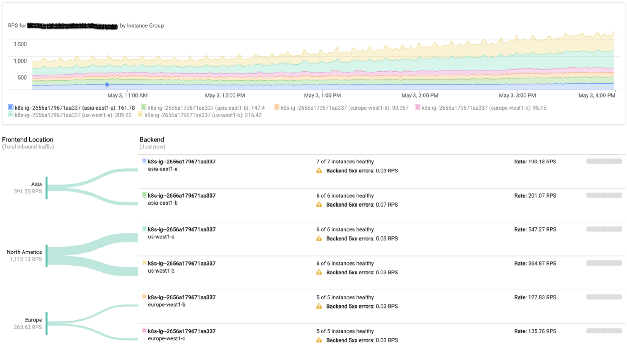
Google load balancing monitoring
Our platform also actively uses graphics processors. Google Cloud makes it extremely efficient to use them directly in Kubernetes clusters.
At that time, the infrastructure team focused mainly on the old stack deployed on physical servers. That is why the use of a managed service (including Kubernetes master components) met our requirements and allowed us to train teams on working with local clusters.
As a result, we were able to start accepting production traffic on the Google Cloud infrastructure just 6 months after the start of work.
However, despite a number of advantages, working with a cloud provider is associated with certain costs, which can increase depending on the load. That is why we carefully analyzed each used managed service, hoping to implement them on-premises in the future. In fact, the introduction of local clusters began at the end of 2016 and at the same time a hybrid strategy was initiated.
Launching the Dailymotion Local Container Orchestration Platform
Fall 2016
In conditions when the whole stack was ready for production, and work on the API continued , there was time to concentrate on regional clusters.
At that time, users watched more than 3 billion videos every month. Of course, we have been operating our own branched Content Delivery Network for several years now. We wanted to take advantage of this circumstance and deploy Kubernetes clusters in existing data centers.
The infrastructure of Dailymotion totaled more than 2.5 thousand servers in six data centers. All are configured using Saltstack. We began to prepare all the necessary recipes for creating master and worker nodes, as well as an etcd cluster.

Network part
Our network is fully routable. Each server announces its IP on the network using Exabgp. We compared several network plug-ins and Calico was the only one satisfying all the needs (due to the approach used at the L3 level). It fits perfectly into the existing network infrastructure model.
Since I wanted to use all the available infrastructure elements, first of all I had to deal with our home-grown network utility (used on all servers): use it to announce IP address ranges on a network with Kubernetes nodes. We allowed Calico to assign IP addresses to pods, but did not use it and still do not use it for BGP sessions on network equipment. In fact, Exabgp handles routing, which announces the subnets used by Calico. This allows us to reach out to any pod from the internal network (and in particular from load balancers).
How we manage ingress traffic
To redirect incoming requests to the desired service, it was decided to use Ingress Controller due to its integration with Kubernetes ingress resources.
Three years ago, nginx-ingress-controller was the most mature controller: Nginx was used for a long time and was known for its stability and performance.
In our system, we decided to place the controllers on dedicated 10-gigabit blade servers. Each controller was connected to the kube-apiserver endpoint of the corresponding cluster. Exabgp was also used on these servers to announce public or private IP addresses. The topology of our network allows us to use BGP from these controllers to route all traffic directly to pods without using a service like NodePort. This approach helps to avoid horizontal traffic between nodes and improves efficiency.
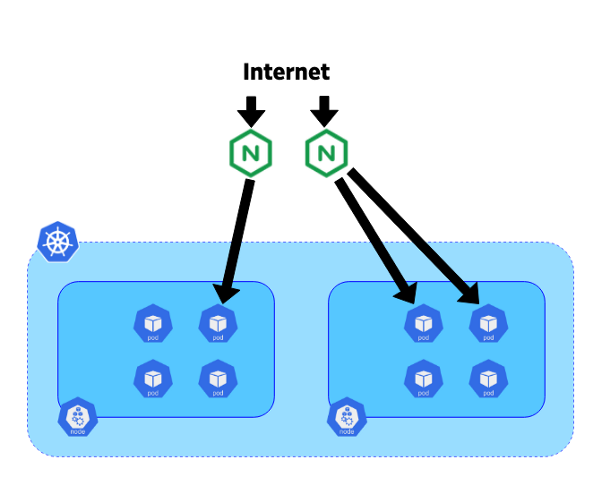
Movement of traffic from the Internet to pods
Now that you’ve figured out our hybrid platform, you can delve into the process of traffic migration.
Migrating traffic from Google Cloud to Dailymotion infrastructure
Fall 2018
After almost two years of creating, testing and configuring, we finally got a full Kubernetes stack, ready to receive some of the traffic.

The current routing strategy is quite simple, but quite satisfies the needs. In addition to public IP (in Google Cloud and Dailymotion), AWS Route 53 is used to set policies and redirect users to the cluster of our choice.
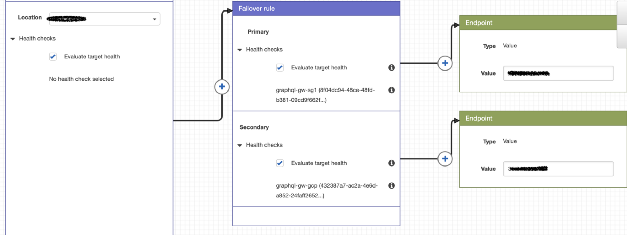
Example Routing Policy Using Route 53
With Google Cloud, it’s easy, because we use a single IP for all clusters, and the user is redirected to the nearest GKE cluster. The technology is different for our clusters because their IPs are different.
During the migration, we sought to redirect regional requests to the respective clusters and evaluated the advantages of this approach.
Since our GKE clusters are configured to automatically scale using Custom Metrics, they increase / decrease capacity depending on incoming traffic.
In normal mode, all regional traffic is directed to the local cluster, and GKE serves as a reserve in case of problems (health-checks are carried out by Route 53).
...
In the future, we want to fully automate routing policies to get an autonomous hybrid strategy that constantly improves user accessibility. As for the pluses: the cost of the cloud was significantly reduced and even managed to reduce the response time of the API. We trust the resulting cloud platform and are ready to redirect more traffic to it if necessary.
PS from the translator
You might also be interested in another recent Dailymotion publication about Kubernetes. It is dedicated to deploying Helm applications to many Kubernetes clusters and was published about a month ago.
Read also in our blog:
- " Switching Tinder to Kubernetes ."
- “ Kubernetes success stories in production. Part 10: Reddit ";
- “ Kubernetes success stories in production. Part 9: CERN and 210 K8s clusters ”;
- “ Kubernetes success stories in production. Part 8: Huawei ";
- “ Kubernetes success stories in production. Part 7: BlackRock ";
- “ Kubernetes success stories in production. Part 6: BlaBlaCar ";
- “ Kubernetes success stories in production. Part 5: Monzo Digital Bank ";
- “ Kubernetes success stories in production. Part 4: SoundCloud (authors Prometheus) ";
- “ Kubernetes success stories in production. Part 3: GitHub ";
- “ Kubernetes success stories in production. Part 2: Concur and SAP ";
- “ Kubernetes success stories in production. Part 1: 4,200 hearths and TessMaster on eBay . ”
Source: https://habr.com/ru/post/460877/
All Articles