Common components by different teams. Yandex Report
Creating and maintaining common components is a process in which many teams must be engaged. The head of the shared components service of Yandex Vladimir Grinenko tadatuta explained how their development outgrew the dedicated Lego team, how we made a mono-repository based on GitHub using Lerna and set up Canary releases with the implementation of services directly in CI, what was needed and what still to be.
“Glad to welcome you all.” My name is Vladimir, I do common things in Yandex interfaces. I want to talk about them. Probably, if you do not use our services very deeply, you may have a question: what are we all typesetting? What is there to typeset?
')


There is a list of answers in the search results, sometimes there is a column on the right. Each of you will probably cope in a day. If you remember that there are different browsers and so on, then we add another day to fix bugs, and then everyone will cope with it.
Someone will recall that there is still such an interface. Taking into account all the little things you can give it another week and go for it. And Dima just told us that there are so many of us that we need our own school. And all these people are constantly making up pages. Every day they come to work and typeset, imagine? Clearly there is something else.

In fact, the services in Yandex, indeed, are more. And there’s even a little more than on this slide. Behind each such link is a bunch of different interfaces with great variability. They are for different devices, in different languages. They work sometimes even in cars and other various strange things.

Yandex today is not only the web, not only different goods with warehouses, delivery and all that. Cars yellow ride. And not only what you can eat, and not only pieces of iron. And not only all sorts of automatic intelligences. But all of the above is united by the fact that for each item interfaces are needed. Often - very rich. Yandex is hundreds of different huge services. We are constantly creating something new every day. We have thousands of employees, including hundreds of front-end developers and interface developers. These people work in different offices, live in different time zones, new guys constantly come to work.
At the same time, we, as far as we have enough strength, try to make it monotonous, uniform for users.

This is the search for documents on the Internet. But if we switch to issuing pictures, the header matches, despite the fact that this is a separate repository, which is engaged in a completely separate team, possibly even on other technologies. It would seem that there is complicated? Well, they made up a hat twice, it seems a simple matter. Each button in the cap also has its own separate rich inner world. Some popups appear here, something can also be pushed there. All this is translated into different languages, works on different platforms. And here we go from the pictures, for example, to video, and this is again a new service, another team. Again another repository. But still the same hat, although there are differences. And all this must be left uniform.
What is it worth, switching like this on the slides, to make sure that nothing has gone anywhere on the pixel? We try to prevent this from happening.

To show the scale a little more, I took a screenshot of the repository, which stores only the front-end code for new browsers - only the output from documents, without pictures and videos. There are tens of thousands of commits and almost 400 contributors. This is only in layout, only one project. Here is a list of blue links that you are used to seeing.
Sergey Berezhnoy, my leader, loves this story very much, since since we have gathered so much in the company, I want our interaction to work together as if in JavaScript: one plus one is more than two.
And we are trying to get everything we can from the interaction. The first thing that comes to mind in such conditions is reuse. Here, for example, a video snippet on a service in the search results for a video. This is some kind of picture with a signature and some other different elements.
If you look further, here is the usual issuance of documents. But here, too, there is exactly the same snippet.

Or, let’s say, there is a separate Yandex.Anter service, which slightly less than completely consists of similar snippets.

Or, let's say, the video snippet in the notifier, which is on different pages of the portal.
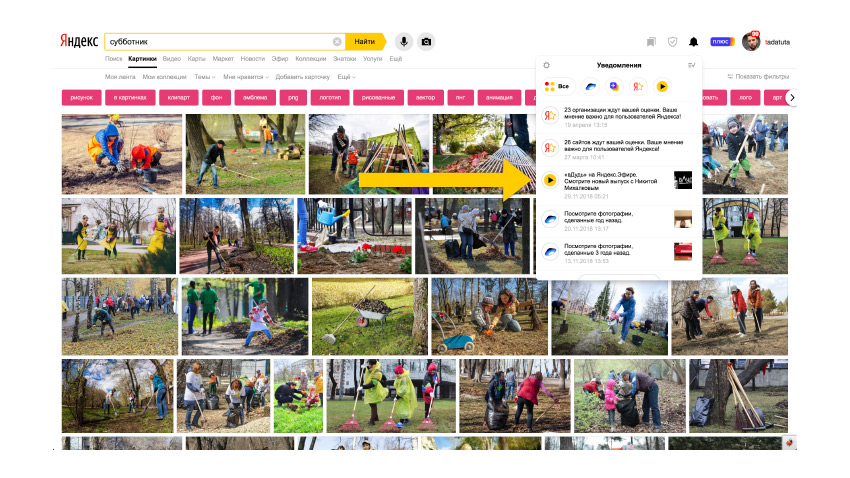
Or a video snippet when you add it to your Favorites, and then watch it in your Collections.

Seem to be? Obviously, it seems. So what? If we really let the services easily integrate our finished components into other portal services, then obviously this service, due to the fact that users will be able to interact with their data on different sites, will get more users. It's great. Users will also benefit from this. They will see the same things equally. They will behave as usual. That is, one does not have to guess again and again what the designer had in mind here and how to interact with it.
And finally, the company will get obvious savings from this. Moreover, it just seems - what is there to make up the video thumbnail and some kind of signature / In fact, in order to get it just like that, you need to conduct a lot of different experiments, test different hypotheses, choose sizes, colors, indents. Add some elements, perhaps later to remove, because they did not fly. And what happened, what really works, is the result of a very long process. And if every time in every new place to do it again, this is a huge amount of effort.
Now imagine. Let's say we got something that works well. Everywhere, everywhere they’ve implemented it, and then they conducted a new experiment and realized what could be improved. And again, we have to repeat this whole implementation chain. Expensive.

Ok, it seems obvious to reuse well. But now we have to solve a number of new issues. You need to understand where to store such new code. On the one hand, it seems to be logical. Here we have the video snippet, the video team makes it, they have a repository with their project. Probably should be put there. But how then to distribute it to other repositories of all other guys? And if other guys want to bring something of their own to this snippet? Again not clear.
It is necessary to version it somehow. You can’t change anything, and so, voila, everyone suddenly rolls out. Something needs to be tested. Moreover, we, for example, tested this on the service of the video itself. But what if, when integrated into another service, something breaks? Again not clear.
In the end, it is necessary to somehow somehow ensure fast enough delivery to different services, because it will be strange if we have somewhere the previous version, somewhere new. The user seems to click on the same thing, and there is a different behavior. And we need to somehow provide the opportunity for developers of different teams to make changes to such common code. We need to somehow teach them how to use it all. We have a long way to make reusing interfaces convenient.

We started in time immemorial, back in SVN, and it was lamp-like and convenient: a daddy with HTML, just like in Bootstrap. You copy it to yourself. Next to daddy with styles, some kind of JS there, who then knew how to simply show / hide something. And that’s all.

Somehow the list of components looked like this. The b-domeg, which was responsible for authorization, is highlighted here. Perhaps you still remember, on Yandex, there really was such a form for login and password, with a roof. We called the "house", although she hinted at the mail envelope, because they usually entered the mail.
Then we came up with a whole methodology to be able to support common interfaces.

The library itself inside the company acquired its own website with a search and any taxonomy.

The repository now looks like this. You see, also almost 10 thousand commits and more than 100 contributors.

But this is the folder of the very b-house in the new reincarnation. Now she looks like this. There are already more folders within your own than half a screen.

And so the site looks today.

As a result, the shared library is used in more than 360 repositories inside Yandex. And there are different implementations, a debugged release cycle, etc. It would seem that, here, we got a common library, let's now use it everywhere, and everything is great. The problem of introducing common stuff anywhere solved. Not really.

Trying to solve the reuse problem at the stage when you already have ready-made code is too late. This means that from the moment the designer drew the layout of the services, distributed them to the services, and, in particular, to the team that deals with common components, some time has passed. Most likely, by this time it will turn out so that on each separate service, or at least on several of them, this same interface element was also made up. They made up somehow in their own way.
And even if then a common solution appears in the shared library, it still turns out that you will now have to re-re-implement everything that you managed to complete on each service. And this is again a problem. It is very difficult to justify. Here is the team. She has her own goals, everything is already working well. And we say these - look, finally we have a common little thing, take it. But the team is like this - we have enough work already. Why do we need it? Moreover, suddenly something will not suit us there? We do not want.
The second big problem is, in fact, the dissemination of information about what these cool new components are. Just because there are so many developers, they are busy with their daily tasks. And they have the opportunity to sit and study what is happening there in the area of common, no matter what it means, in fact, either.
And the biggest problem is that it is fundamentally impossible to solve the problems common to all-all services with a single dedicated team. That is, when we have a team that deals with video, and it makes its own snippet with video, it is clear that we will agree with them and do this snippet in some kind of centralized library. But there are thousands of such examples on different services. And here certainly no hands are enough. Therefore, the only solution is that everyone should deal with general components all the time.

And you need to start, strangely enough, not with interface developers, but with designers. They understand that too. We have several simultaneous attempts inside so that this process converges. Designers make design systems. I really hope that sooner or later it will be possible to reduce them into a single common system that takes into account all the needs.

Now there are several of them. Surprisingly, the tasks there are exactly the same: to speed up the development process, to solve the problem of consistency, not to reinvent the wheel and not duplicate the work done.

And one way to solve the problem of communicating information is to allow developers to get acquainted with other teams, including one that deals with common interface components. We solve it on this side by the fact that we have a bootcamp, which, when a developer appears on Yandex, first of all allows him to go to different teams for eight weeks, see how it works, and then make a choice where it will work . But during this time, his horizons will expand significantly. He will be guided where that is.
We talked about common things. Let's now see how it all looks closer to the development process. Let's say we have a common library called Lego. And we want to implement some new feature in it or make some kind of revision. We fixed the code and released the version.
We need to publish this version in npm, and then go to the repository of some project where the library is used, and implement this version. Most likely, this will fix some number in package.json, restart the assembly. Perhaps even regenerate package-lock, create a pull request, see how the tests pass. And what will we see?
Most likely, we will see that a bug has occurred. Because it is very difficult to predict all the ways to use the component on different services. And if that happened, then what is our way out? So we realized that did not fit together. We continue to redo it. We return to the repository with a shared library, fix the bug, release the new version, send it to npm, deploy, run the tests, and what is it? Most likely, a bug will happen again.
And this is still good when we implement it in one service, and right there everything broke right away. It was much sadder when we did all this, implemented it in ten different services. Nothing broke there. We have already gone to brew a smoothie, or whatever is needed. At this time, the version is being introduced in the 11th project, or in the 25th. And there is a bug. We return along the whole chain, make a patch and implement it in all previous 20 services. Moreover, this patch may explode in one of the previous ones. Well and so on. Fun.
The only way out, it seems, is that you just need to write a lot of code very quickly. Then, sooner or later, if we run very, very fast, most likely, we will manage to manage to roll out to production a version in which there is no bug yet. But then a new feature will appear, and nothing will save us.
Okay. In fact, the scheme may be something like the following. Automation will help us. It is about this, in general, the whole story, in fact. We came up with the idea that a repository with a common library can be built according to the mono-repository scheme. You probably came across, now there are a lot of such projects, especially infrastructure ones. All sorts of Babel, and similar things, live like mono-repositories when there are many different npm packages inside. They may be somehow connected with each other. And they are managed, for example, through Lerna, so that it’s convenient to publish all this, given the dependencies.
Exactly according to this scheme, it is possible to organize a project, where everything common is stored, for the whole company. There may be a library, which is a separate team. And, including, there may be packages that each individual service develops, but which he wants to share with others.

Then the circuit looks like this. The beginning is no different. One way or another, we need to make changes to the common code. And then, with the help of automation, in one fell swoop we want to run tests not only next to this code, but immediately in all those projects where this common code is embedded. And see their aggregated result.
Then, even if a bug happened there, we still haven’t managed to release any version, haven’t published it in any npm, we haven’t implemented it specifically with our hands, we haven’t done all these extra efforts. We saw a bug, immediately fixed it locally, ran the general tests again, and that’s all in production.
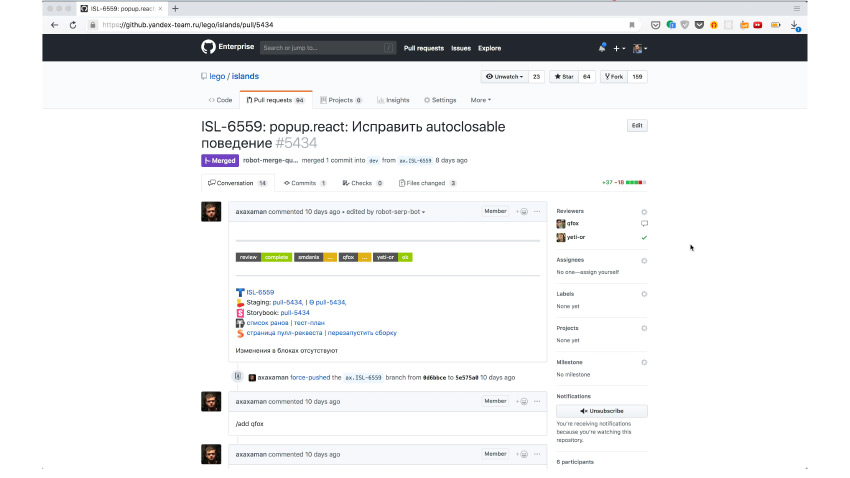
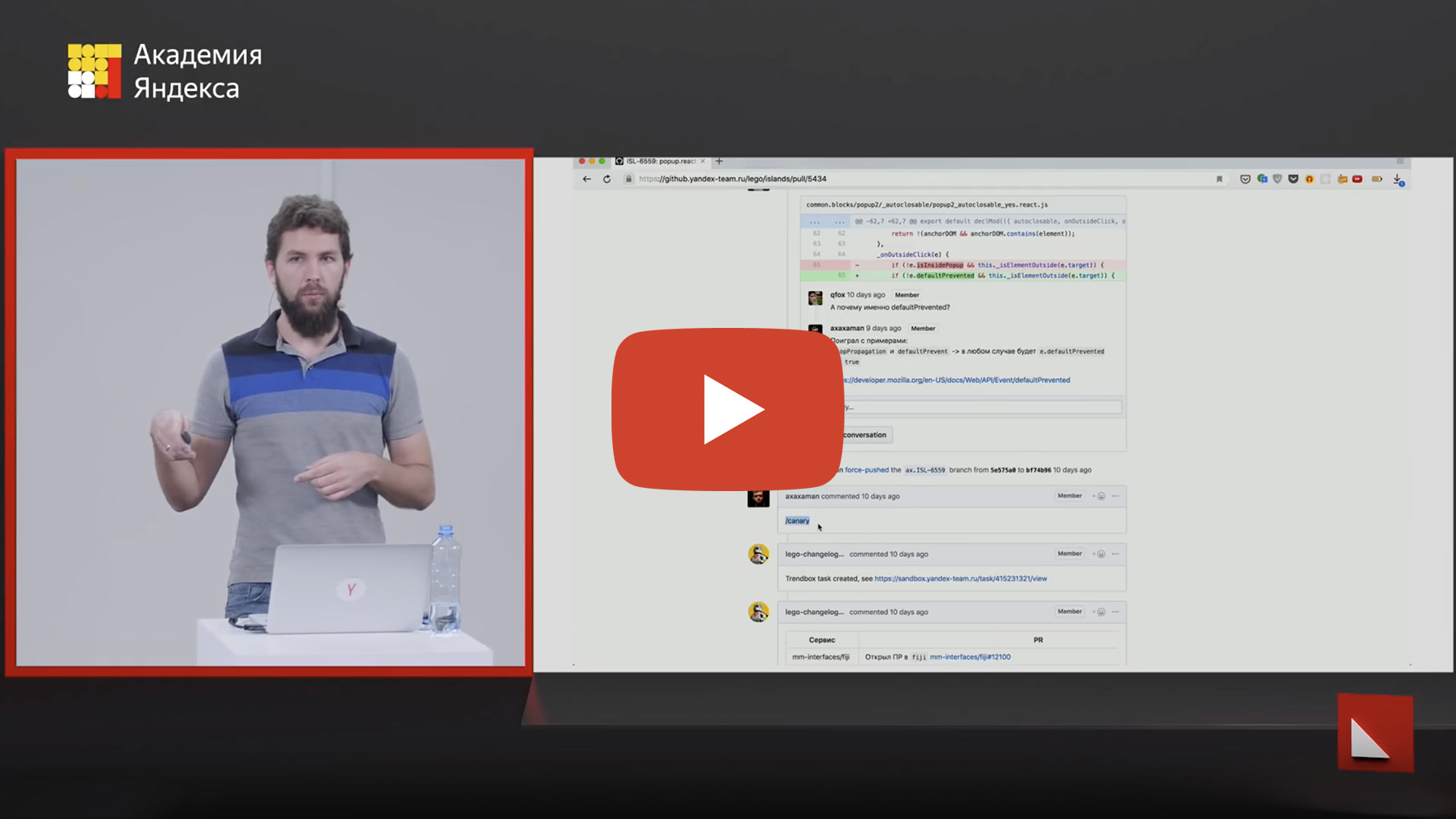
What does it look like in practice? Here is a pull request with a fix. It can be seen here that the automation called for the necessary reviewers there to check that everything was fine in the code. Indeed, the reviewers came and agreed that everything was fine. And at this moment, the developer simply writes a special / canary command, right in the pull request.
A robot comes and says - okay, I created a task for the next miracle to happen. The miracle is that a canary version with these changes has now been released and it has been automatically implemented in all repositories where this component is used. Autotests were launched there, as in this repository. Here you can see that a whole bunch of checks have been launched.
Behind each test there can be hundreds of different tests. But it is important that in addition to the local tests that we were able to write to the component separately, we also launched tests for each project where it was implemented. Integration tests have already been launched there: we check that this component works normally in the environment in which it is conceived on the service. This already really guarantees us that we have not forgotten anything, we have not broken anything to anyone. If everything is fine here, then we really can safely release a version. And if something is bad here, we’ll fix it here.
It seems like this should help us. If your company has something similar, you see that there are parts that you could potentially reuse, but for now you have to re-arrange them because there is no automation, I recommend that you come to a similar solution.

What did we get? The general monorepository in which linters are rebuilt. That is, everyone writes code the same way, it has all kinds of tests. Any team can come, put their component and test it with JS unit-tests, cover it with screenshots, etc. Everything will already be out of the box. The clever code review that I already mentioned. Thanks to rich internal tools, it is really smart here.
Is the developer on vacation now? Calling him into a pull request is pointless; the system will take this into account. Is the developer sick? The system will also take this into account. If both conditions are not fulfilled and the developer seems to be free, he will receive a notification in one of his messengers of his choice. And he is like this: no, now I'm busy with something urgent or at a meeting. He can come there and just write the / busy command. The system will automatically understand that you need to assign the next one from the list.
The next step is to publish the same canary version. That is, with any code change, we need to release a service package that we can check on different services. Next, we need to run tests when deployed to all of these services. And when it all came together - launch the releases.
If a change affects some static that must be loaded from the CDN, you need to automatically publish it separately. This also works out of the box. , , , , . , , , changelog - .
, , , , . , , .
, . . , , : , ? . , . . , .
“Glad to welcome you all.” My name is Vladimir, I do common things in Yandex interfaces. I want to talk about them. Probably, if you do not use our services very deeply, you may have a question: what are we all typesetting? What is there to typeset?
')
There is a list of answers in the search results, sometimes there is a column on the right. Each of you will probably cope in a day. If you remember that there are different browsers and so on, then we add another day to fix bugs, and then everyone will cope with it.
Someone will recall that there is still such an interface. Taking into account all the little things you can give it another week and go for it. And Dima just told us that there are so many of us that we need our own school. And all these people are constantly making up pages. Every day they come to work and typeset, imagine? Clearly there is something else.
In fact, the services in Yandex, indeed, are more. And there’s even a little more than on this slide. Behind each such link is a bunch of different interfaces with great variability. They are for different devices, in different languages. They work sometimes even in cars and other various strange things.
Yandex today is not only the web, not only different goods with warehouses, delivery and all that. Cars yellow ride. And not only what you can eat, and not only pieces of iron. And not only all sorts of automatic intelligences. But all of the above is united by the fact that for each item interfaces are needed. Often - very rich. Yandex is hundreds of different huge services. We are constantly creating something new every day. We have thousands of employees, including hundreds of front-end developers and interface developers. These people work in different offices, live in different time zones, new guys constantly come to work.
At the same time, we, as far as we have enough strength, try to make it monotonous, uniform for users.
This is the search for documents on the Internet. But if we switch to issuing pictures, the header matches, despite the fact that this is a separate repository, which is engaged in a completely separate team, possibly even on other technologies. It would seem that there is complicated? Well, they made up a hat twice, it seems a simple matter. Each button in the cap also has its own separate rich inner world. Some popups appear here, something can also be pushed there. All this is translated into different languages, works on different platforms. And here we go from the pictures, for example, to video, and this is again a new service, another team. Again another repository. But still the same hat, although there are differences. And all this must be left uniform.
What is it worth, switching like this on the slides, to make sure that nothing has gone anywhere on the pixel? We try to prevent this from happening.
To show the scale a little more, I took a screenshot of the repository, which stores only the front-end code for new browsers - only the output from documents, without pictures and videos. There are tens of thousands of commits and almost 400 contributors. This is only in layout, only one project. Here is a list of blue links that you are used to seeing.
Sergey Berezhnoy, my leader, loves this story very much, since since we have gathered so much in the company, I want our interaction to work together as if in JavaScript: one plus one is more than two.
And we are trying to get everything we can from the interaction. The first thing that comes to mind in such conditions is reuse. Here, for example, a video snippet on a service in the search results for a video. This is some kind of picture with a signature and some other different elements.
If you look further, here is the usual issuance of documents. But here, too, there is exactly the same snippet.
Or, let’s say, there is a separate Yandex.Anter service, which slightly less than completely consists of similar snippets.
Or, let's say, the video snippet in the notifier, which is on different pages of the portal.
Or a video snippet when you add it to your Favorites, and then watch it in your Collections.
Seem to be? Obviously, it seems. So what? If we really let the services easily integrate our finished components into other portal services, then obviously this service, due to the fact that users will be able to interact with their data on different sites, will get more users. It's great. Users will also benefit from this. They will see the same things equally. They will behave as usual. That is, one does not have to guess again and again what the designer had in mind here and how to interact with it.
And finally, the company will get obvious savings from this. Moreover, it just seems - what is there to make up the video thumbnail and some kind of signature / In fact, in order to get it just like that, you need to conduct a lot of different experiments, test different hypotheses, choose sizes, colors, indents. Add some elements, perhaps later to remove, because they did not fly. And what happened, what really works, is the result of a very long process. And if every time in every new place to do it again, this is a huge amount of effort.
Now imagine. Let's say we got something that works well. Everywhere, everywhere they’ve implemented it, and then they conducted a new experiment and realized what could be improved. And again, we have to repeat this whole implementation chain. Expensive.
Ok, it seems obvious to reuse well. But now we have to solve a number of new issues. You need to understand where to store such new code. On the one hand, it seems to be logical. Here we have the video snippet, the video team makes it, they have a repository with their project. Probably should be put there. But how then to distribute it to other repositories of all other guys? And if other guys want to bring something of their own to this snippet? Again not clear.
It is necessary to version it somehow. You can’t change anything, and so, voila, everyone suddenly rolls out. Something needs to be tested. Moreover, we, for example, tested this on the service of the video itself. But what if, when integrated into another service, something breaks? Again not clear.
In the end, it is necessary to somehow somehow ensure fast enough delivery to different services, because it will be strange if we have somewhere the previous version, somewhere new. The user seems to click on the same thing, and there is a different behavior. And we need to somehow provide the opportunity for developers of different teams to make changes to such common code. We need to somehow teach them how to use it all. We have a long way to make reusing interfaces convenient.
We started in time immemorial, back in SVN, and it was lamp-like and convenient: a daddy with HTML, just like in Bootstrap. You copy it to yourself. Next to daddy with styles, some kind of JS there, who then knew how to simply show / hide something. And that’s all.
Somehow the list of components looked like this. The b-domeg, which was responsible for authorization, is highlighted here. Perhaps you still remember, on Yandex, there really was such a form for login and password, with a roof. We called the "house", although she hinted at the mail envelope, because they usually entered the mail.
Then we came up with a whole methodology to be able to support common interfaces.
The library itself inside the company acquired its own website with a search and any taxonomy.
The repository now looks like this. You see, also almost 10 thousand commits and more than 100 contributors.
But this is the folder of the very b-house in the new reincarnation. Now she looks like this. There are already more folders within your own than half a screen.
And so the site looks today.
As a result, the shared library is used in more than 360 repositories inside Yandex. And there are different implementations, a debugged release cycle, etc. It would seem that, here, we got a common library, let's now use it everywhere, and everything is great. The problem of introducing common stuff anywhere solved. Not really.
Trying to solve the reuse problem at the stage when you already have ready-made code is too late. This means that from the moment the designer drew the layout of the services, distributed them to the services, and, in particular, to the team that deals with common components, some time has passed. Most likely, by this time it will turn out so that on each separate service, or at least on several of them, this same interface element was also made up. They made up somehow in their own way.
And even if then a common solution appears in the shared library, it still turns out that you will now have to re-re-implement everything that you managed to complete on each service. And this is again a problem. It is very difficult to justify. Here is the team. She has her own goals, everything is already working well. And we say these - look, finally we have a common little thing, take it. But the team is like this - we have enough work already. Why do we need it? Moreover, suddenly something will not suit us there? We do not want.
The second big problem is, in fact, the dissemination of information about what these cool new components are. Just because there are so many developers, they are busy with their daily tasks. And they have the opportunity to sit and study what is happening there in the area of common, no matter what it means, in fact, either.
And the biggest problem is that it is fundamentally impossible to solve the problems common to all-all services with a single dedicated team. That is, when we have a team that deals with video, and it makes its own snippet with video, it is clear that we will agree with them and do this snippet in some kind of centralized library. But there are thousands of such examples on different services. And here certainly no hands are enough. Therefore, the only solution is that everyone should deal with general components all the time.
And you need to start, strangely enough, not with interface developers, but with designers. They understand that too. We have several simultaneous attempts inside so that this process converges. Designers make design systems. I really hope that sooner or later it will be possible to reduce them into a single common system that takes into account all the needs.
Now there are several of them. Surprisingly, the tasks there are exactly the same: to speed up the development process, to solve the problem of consistency, not to reinvent the wheel and not duplicate the work done.
And one way to solve the problem of communicating information is to allow developers to get acquainted with other teams, including one that deals with common interface components. We solve it on this side by the fact that we have a bootcamp, which, when a developer appears on Yandex, first of all allows him to go to different teams for eight weeks, see how it works, and then make a choice where it will work . But during this time, his horizons will expand significantly. He will be guided where that is.
We talked about common things. Let's now see how it all looks closer to the development process. Let's say we have a common library called Lego. And we want to implement some new feature in it or make some kind of revision. We fixed the code and released the version.
We need to publish this version in npm, and then go to the repository of some project where the library is used, and implement this version. Most likely, this will fix some number in package.json, restart the assembly. Perhaps even regenerate package-lock, create a pull request, see how the tests pass. And what will we see?
Most likely, we will see that a bug has occurred. Because it is very difficult to predict all the ways to use the component on different services. And if that happened, then what is our way out? So we realized that did not fit together. We continue to redo it. We return to the repository with a shared library, fix the bug, release the new version, send it to npm, deploy, run the tests, and what is it? Most likely, a bug will happen again.
And this is still good when we implement it in one service, and right there everything broke right away. It was much sadder when we did all this, implemented it in ten different services. Nothing broke there. We have already gone to brew a smoothie, or whatever is needed. At this time, the version is being introduced in the 11th project, or in the 25th. And there is a bug. We return along the whole chain, make a patch and implement it in all previous 20 services. Moreover, this patch may explode in one of the previous ones. Well and so on. Fun.
The only way out, it seems, is that you just need to write a lot of code very quickly. Then, sooner or later, if we run very, very fast, most likely, we will manage to manage to roll out to production a version in which there is no bug yet. But then a new feature will appear, and nothing will save us.
Okay. In fact, the scheme may be something like the following. Automation will help us. It is about this, in general, the whole story, in fact. We came up with the idea that a repository with a common library can be built according to the mono-repository scheme. You probably came across, now there are a lot of such projects, especially infrastructure ones. All sorts of Babel, and similar things, live like mono-repositories when there are many different npm packages inside. They may be somehow connected with each other. And they are managed, for example, through Lerna, so that it’s convenient to publish all this, given the dependencies.
Exactly according to this scheme, it is possible to organize a project, where everything common is stored, for the whole company. There may be a library, which is a separate team. And, including, there may be packages that each individual service develops, but which he wants to share with others.
Then the circuit looks like this. The beginning is no different. One way or another, we need to make changes to the common code. And then, with the help of automation, in one fell swoop we want to run tests not only next to this code, but immediately in all those projects where this common code is embedded. And see their aggregated result.
Then, even if a bug happened there, we still haven’t managed to release any version, haven’t published it in any npm, we haven’t implemented it specifically with our hands, we haven’t done all these extra efforts. We saw a bug, immediately fixed it locally, ran the general tests again, and that’s all in production.
What does it look like in practice? Here is a pull request with a fix. It can be seen here that the automation called for the necessary reviewers there to check that everything was fine in the code. Indeed, the reviewers came and agreed that everything was fine. And at this moment, the developer simply writes a special / canary command, right in the pull request.
A robot comes and says - okay, I created a task for the next miracle to happen. The miracle is that a canary version with these changes has now been released and it has been automatically implemented in all repositories where this component is used. Autotests were launched there, as in this repository. Here you can see that a whole bunch of checks have been launched.
Behind each test there can be hundreds of different tests. But it is important that in addition to the local tests that we were able to write to the component separately, we also launched tests for each project where it was implemented. Integration tests have already been launched there: we check that this component works normally in the environment in which it is conceived on the service. This already really guarantees us that we have not forgotten anything, we have not broken anything to anyone. If everything is fine here, then we really can safely release a version. And if something is bad here, we’ll fix it here.
It seems like this should help us. If your company has something similar, you see that there are parts that you could potentially reuse, but for now you have to re-arrange them because there is no automation, I recommend that you come to a similar solution.
What did we get? The general monorepository in which linters are rebuilt. That is, everyone writes code the same way, it has all kinds of tests. Any team can come, put their component and test it with JS unit-tests, cover it with screenshots, etc. Everything will already be out of the box. The clever code review that I already mentioned. Thanks to rich internal tools, it is really smart here.
Is the developer on vacation now? Calling him into a pull request is pointless; the system will take this into account. Is the developer sick? The system will also take this into account. If both conditions are not fulfilled and the developer seems to be free, he will receive a notification in one of his messengers of his choice. And he is like this: no, now I'm busy with something urgent or at a meeting. He can come there and just write the / busy command. The system will automatically understand that you need to assign the next one from the list.
The next step is to publish the same canary version. That is, with any code change, we need to release a service package that we can check on different services. Next, we need to run tests when deployed to all of these services. And when it all came together - launch the releases.
If a change affects some static that must be loaded from the CDN, you need to automatically publish it separately. This also works out of the box. , , , , . , , , changelog - .
, , , , . , , .
, . . , , : , ? . , . . , .
Source: https://habr.com/ru/post/460811/
All Articles