YouTokenToMe: tool for quick tokenization of text from the VKontakte Team
We want to introduce our new tool for text tokenization - YouTokenToMe. It works 7–10 times faster than other popular versions in languages similar in structure to European, and 40–50 times in Asian languages. We tell about YouTokenToMe and share it with you in open source on GitHub. Link at the end of the article!

Today, a significant proportion of tasks for neural network algorithms is text processing. But since neural networks work with numbers, the text needs to be converted before being transferred to the model.
We list the popular solutions that are usually used for this:
')
Each of them has its drawbacks:
Recently, the popular approach is Byte Pair Encoding . Initially, this algorithm was intended for compressing texts, but several years ago it was used to tokenize text in machine translation. Now it is used for a wide range of tasks, including that used in BERT and GPT-2 models.
The most effective implementations of BPE were SentencePiece , developed by Google engineers, and fastBPE , created by a researcher from Facebook AI Research. But we managed to prove that tokenization can be significantly accelerated. We optimized the BPE algorithm and published the source code, and also laid out the finished package in the pip repository.
Below you can compare the results of measuring the speed of our algorithm and other versions. As an example, we took the first 100 MB of data from Wikipedia in Russian, English, Japanese and Chinese.
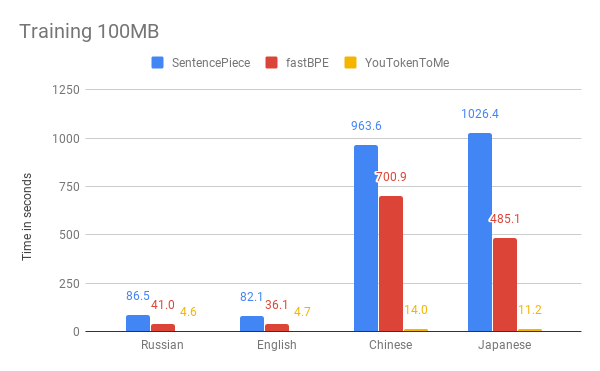

The graphs show that the work time essentially depends on the language. This is due to the fact that in Asian languages the alphabets are larger and the words are not separated by spaces. YouTokenToMe works 7–10 times faster in languages that are similar in structure to European, and 40–50 times - to Asian. The tokenization was accelerated at least twice, and on some tests more than ten times.
We achieved such results thanks to two key ideas:
You can use YouTokenToMe through the interface to work from the command line and directly from Python.
More information can be found in the repository: github.com/vkcom/YouTokenToMe
Today, a significant proportion of tasks for neural network algorithms is text processing. But since neural networks work with numbers, the text needs to be converted before being transferred to the model.
We list the popular solutions that are usually used for this:
')
- splitting into spaces;
- rule-based algorithms: spaCy, NLTK;
- stemming, lemmatization.
Each of them has its drawbacks:
- cannot control the size of the token dictionary. The size of the layer with embeddings in the model directly depends on this;
- information about relatedness of words that differ in suffixes or prefixes is not used, for example: polite - impolite;
- depend on the language.
Recently, the popular approach is Byte Pair Encoding . Initially, this algorithm was intended for compressing texts, but several years ago it was used to tokenize text in machine translation. Now it is used for a wide range of tasks, including that used in BERT and GPT-2 models.
The most effective implementations of BPE were SentencePiece , developed by Google engineers, and fastBPE , created by a researcher from Facebook AI Research. But we managed to prove that tokenization can be significantly accelerated. We optimized the BPE algorithm and published the source code, and also laid out the finished package in the pip repository.
Below you can compare the results of measuring the speed of our algorithm and other versions. As an example, we took the first 100 MB of data from Wikipedia in Russian, English, Japanese and Chinese.
The graphs show that the work time essentially depends on the language. This is due to the fact that in Asian languages the alphabets are larger and the words are not separated by spaces. YouTokenToMe works 7–10 times faster in languages that are similar in structure to European, and 40–50 times - to Asian. The tokenization was accelerated at least twice, and on some tests more than ten times.
We achieved such results thanks to two key ideas:
- The new algorithm has a linear running time depending on the size of the body for training. SentencePiece and fastBPE have less effective asymptotics;
- The new algorithm can effectively use several threads both in the learning process and in the tokenization process - this allows us to get acceleration several times more.
You can use YouTokenToMe through the interface to work from the command line and directly from Python.
More information can be found in the repository: github.com/vkcom/YouTokenToMe
Source: https://habr.com/ru/post/460641/
All Articles