Experience modeling from the team Computer Vision Mail.ru

My name is Edward Tiantov, I lead the Computer Vision team at Mail.ru Group. For several years of existence, our team has solved dozens of computer vision tasks, and today I will tell you about what techniques we use to successfully create machine learning models that work on a wide range of tasks. I will share tricks that can speed up the acquisition of a model at all stages: problem statement, data preparation, training, and deployment to production.
Computer Vision in Mail.ru
To begin with, what is Computer Vision in Mail.ru, and what projects we are doing. We provide solutions to our products, such as Mail, Cloud Mail.ru (photo and video storage application), Vision (B2B solutions based on computer vision) and others. I will give a few examples.
The cloud (this is our first and main client) stores 60 billion photos. We develop various features based on machine learning for their clever processing, for example, face recognition and sight ( there is a separate post about it ). All photos of the user are run through the recognition model, which allows you to organize the search and grouping by people, tags, visited cities and countries, and so on.
')
For the Post we did OCR - text recognition from the image. I will tell you about it in more detail today.
For B2B products, we do recognition and counting of people in queues. For example, there is a queue at the ski lift, and you want to count how many people are in it. To begin with, to test the technology and play around, we deployed a prototype in the canteen in the office. There are several ticket offices and, accordingly, several queues, and we, using several cameras (one for each of the queues), use the model to calculate how many people are in the queues and how many minutes each stand in. Thus, we can better balance the queues in the dining room.

Formulation of the problem
Let's start with the critical part of any task - its setting. Virtually any ML development takes at least a month (this is, at best, when you know what to do), and in most cases several months. If it is wrong or inaccurate to set a task, then at the end of the work there is a great chance to hear something from the product manager in the spirit: “Everything is wrong. This is no good. I wanted another. To avoid this, you need to take some steps. What is special about ML-based products? Unlike the task of developing a site, a task in machine learning cannot be formalized by text alone. Moreover, as a rule, for an unprepared person, it seems that everything is obvious and just needs to be done “beautifully”. And what small details are there, the task director, perhaps, does not even know, never thought about them and would not think until he saw the final product and said: “What have you done?”
Problems
Let's understand by example what problems there may be. Suppose you face the task of recognizing faces. You get it, rejoice and call your mom: “Hooray, an interesting task!” But can you just break loose and start doing? If you do this, then at the end you can expect surprises:
- There are different nationalities. For example, there were no Asians or anyone else in Dataset. Your model, respectively, does not know how to recognize them at all, but the product turned out to be necessary. Or vice versa, you spent the extra three months on revision, and only Europoids will be in the product, and this was not necessary.
- There are children. For such childless fathers like me, all children are the same person. I am absolutely in solidarity with the model, when she sends all children to one cluster - it’s really not clear how most children are different! ;) But people who have children have a completely different opinion. Usually they are also your leaders. Or there are still funny recognition errors when the child’s head is successfully compared to the elbow or the head of a bald man (true story).
- What to do with the drawn characters is generally incomprehensible. Need to recognize them or not?
Such aspects of the task are very important to determine at the beginning. Therefore, it is necessary to work and communicate with the manager from the very beginning “on data”. You can not take oral explanations. We must look at the data. It is desirable from the same distribution on which the model will work.
Ideally, in the course of this discussion, some test dataset will be obtained, where you can finally launch the model and check whether it works as the manager wanted. It is desirable to give part of the test dataset to the manager himself so that you do not have any access to him. Because you can easily retrain to this test set, you are an ML developer!
Setting a task in ML is a permanent job between a product manager and an ML specialist. Even if at first you set the task well, then as the model develops, new problems will appear, new features that you will learn about your data. All this needs to be constantly discussed with the manager. Good leaders always broadcast their ML-teams, that we must take responsibility for ourselves and help the manager to set tasks.
Why is that? Machine learning is a fairly new area. Managers have no (or little) experience in handling such tasks. How often do people learn to solve new problems? On the mistakes. If you do not want your favorite project to become a mistake, then you need to get involved and take responsibility for yourself, to teach the product manager to set the task correctly, to develop checklists and policies; All this helps a lot. Every time I pull myself down (or someone from my colleagues pulls me down) when a new interesting task arrives, and we run to do it. Everything that I have told you now, I myself forget. Therefore, it is important to have some kind of checklist to check yourself.
Data
Data is super important in ML. For deep learning, the more data you feed the models, the better. The blue graph shows that usually deep learning models improve dramatically when adding data.

And the "old" (classical) algorithms from some point can no longer improve.
Usually in ML datasets are dirty. They were marked by people who always lie (s). Assessors are often inattentive and make a lot of mistakes. We use this technique: we take the data that we have, train the model on them, and then use this model to clear the data and repeat the cycle again.
Let's take a closer look at the same face recognition. Let's say we downloaded VKontakte user avatars. For example, we have a user profile with 4 avatars. We detect faces that are on all 4 images, and run through the face recognition model. So we get the embeddingings of persons with the help of which they can be “glued together” by similar faces into groups (clustering). Then we choose the largest cluster, assuming that the user's avatars basically contain exactly his face. Accordingly, all other faces (which are noise), we can thus clean out. After this, we can repeat the cycle: train the model on the cleaned data and use it to clear the data. You can repeat several times.
Almost always, we use CLink algorithms for such clustering. This is a hierarchical clustering algorithm, in which it is very convenient to set a threshold value for “gluing together” similar objects (this is exactly what is required for cleaning). CLink generates spherical clusters. This is important, as we often learn the metric space of these embeddings. The algorithm has complexity O (n 2 ), which, in principle, is approx.
Sometimes the data is so hard to get or mark up that nothing remains but to start generating it. Generative approach allows you to produce a huge amount of data. But for this you need to program something. The simplest example is OCR, text recognition in images. The markup of the text for this task is wildly expensive and noisy: you need to select each line and each word, sign the text, and so on. Even a hundred pages of text assessors (people involved in markup) will mark extremely long, and for training you need much more. Obviously, you can somehow generate the text and somehow “move” it so that the model learns from it.
We deduced for ourselves that the best and most convenient tool for this task is a combination of PIL, OpenCV and Numpy. They have everything to work with the text. You can in any way complicate the image with the text so that the network does not retrain for simple examples.

Sometimes we need some real world objects. For example, goods on store shelves. One of these pictures is automatically generated. Do you think left or right?

In fact, both are generated. If you do not look closely at small details, then you will not notice differences from reality. We do this with Blender (similar to 3dmax).
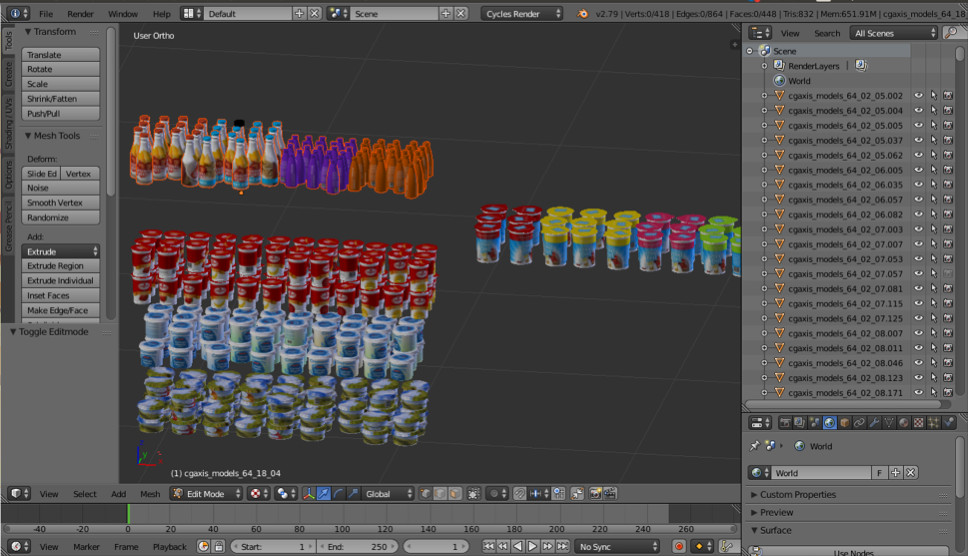
The main important advantage is that it is open source. It has an excellent Python API, which allows you to place objects directly in the code, configure and randomize the process, and eventually get a variety of datasets.
Ray tracing is used for rendering. This is a rather expensive procedure, but it gives the result with excellent quality. The most important question: where to get models for objects? As a rule, they need to buy. But if you are a poor student and want to experiment with something, there are always torrents. It is clear that for the production you need to buy or order from someone drawn models.
On this about the data all. Let's move on to learning.
Metric learning
The goal of Metric learning is to train the network in such a way that it translates similar objects into similar regions in the metric embedding space. Let me give you an example again with landmarks, which is unusual in that it is essentially a classification task, but into tens of thousands of classes. It would seem, why is metric learning, which, as a rule, is relevant in tasks like face recognition? Let's try to figure it out.
If you use standard Loss for teaching classification tasks, for example, Softmax, then classes in the metric space will be well separated, but in the embedding space, points of different classes can be close to each other ...

This creates potential errors during generalization, since a slight difference in the source data may change the classification result. We would really like the points to be more compact. For this purpose, various techniques of metric learning are used. For example, Center loss, the idea of which is extremely simple: we simply tighten the points to the learning center of each class, which, as a result, become more compact.
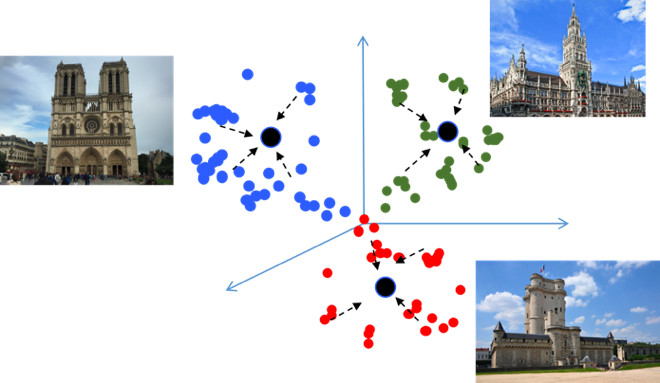
Center loss is programmed literally in 10 lines in Python, it works very quickly, and most importantly, it improves the quality of classification, since compactness leads to better generalizing ability.
Angular softmax
We tried many different methods of metric learning, and concluded that Angular Softmax leads to the best results. Among the research community, he is also considered a state of the art.
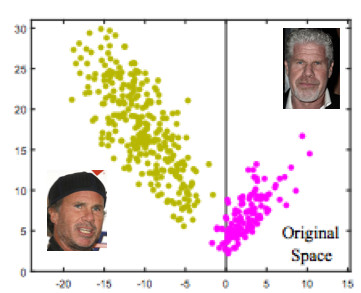
Let's take it through the example of face recognition. Here we have two people. If we use the standard Softmax, then a dividing plane will be drawn between them - based on two weights vectors. If you make the embeddings 1, then the points will lie on the circle, i.e. on the sphere in the n-dimensional case (picture on the right).

Then you can see that the angle between them is already responsible for the division of classes, and it can be optimized. But this is not enough. If we just move on to the optimization of the angle, then the task in fact will not change, because we simply reformulated it in other terms. Our goal, I remind you, is to make clusters more compact.
It is necessary to somehow require a greater angle between the classes - to complicate the task of the neural network. For example, in such a way that she thinks that the angle between the points of one class is larger than it actually is, so that she tries to squeeze them more and more. This is achieved by introducing the parameter m, which controls the difference between the cosines of the corners.
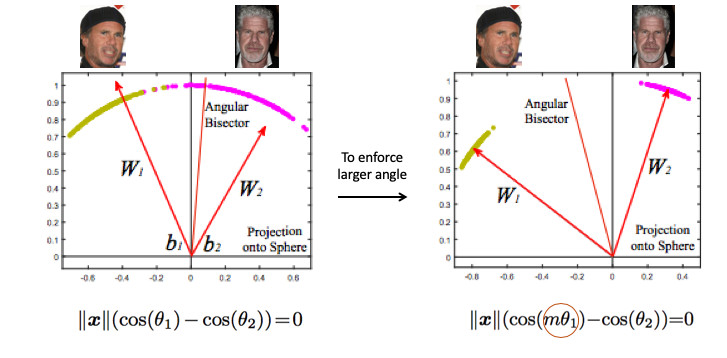
There are several options for Angular Softmax. All of them are played in order to multiply this angle by m or add, or multiply and add. State-of-the-art - ArcFace.
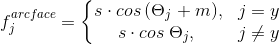
In fact, this one is quite simply integrated into the pipeline classification.
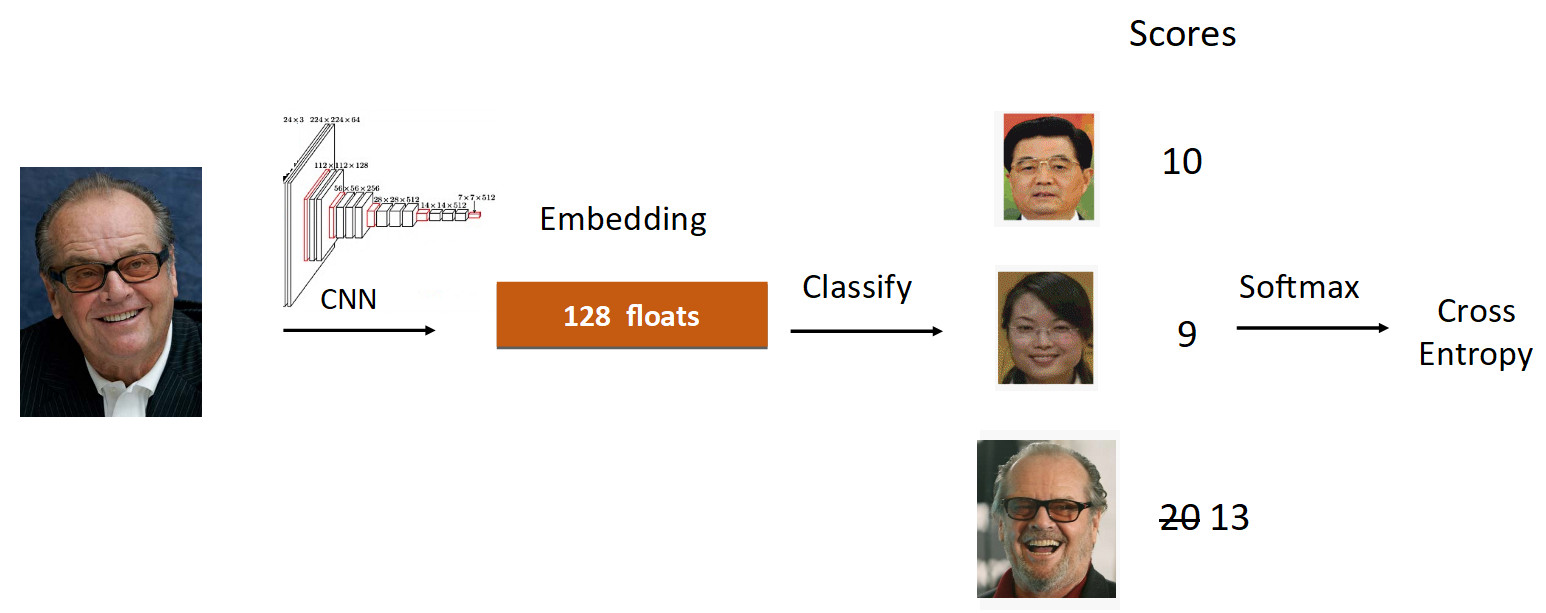
Let's look at the example of Jack Nicholson. We run his photo through the grid in the process of learning. We get an embedding, we run through the linear layer for classification and we get at the exit the speed, which reflects the degree of belonging to the class. In this case, the picture of Nicholson is probably 20, the largest. Further, according to the formula from ArcFace, we reduce the speed from 20 to 13 (done only for the groundtruth class), complicating the task for the neural network. Then we do everything as usual: Softmax + Cross Entropy.
In total, the usual linear layer is replaced by the ArcFace layer, which is written not in 10, but in 20 lines, but it gives excellent results and a minimum of overhead to implement. As a result, ArcFace on most tasks is better than all other methods. It fits perfectly into classification tasks and improves quality.
Transfer learning
The second thing I wanted to tell you about is Transfer learning - using a pre-trained network on a similar task for additional training on a new task. Thus, there is a transfer of knowledge from one task to another.
We did our search for images. The essence of the task is to output semantically similar to the image from the database.

It is logical to take a network that has already studied on a large number of images - on ImageNet or OpenImages, in which there are millions of pictures, and to test on our data.
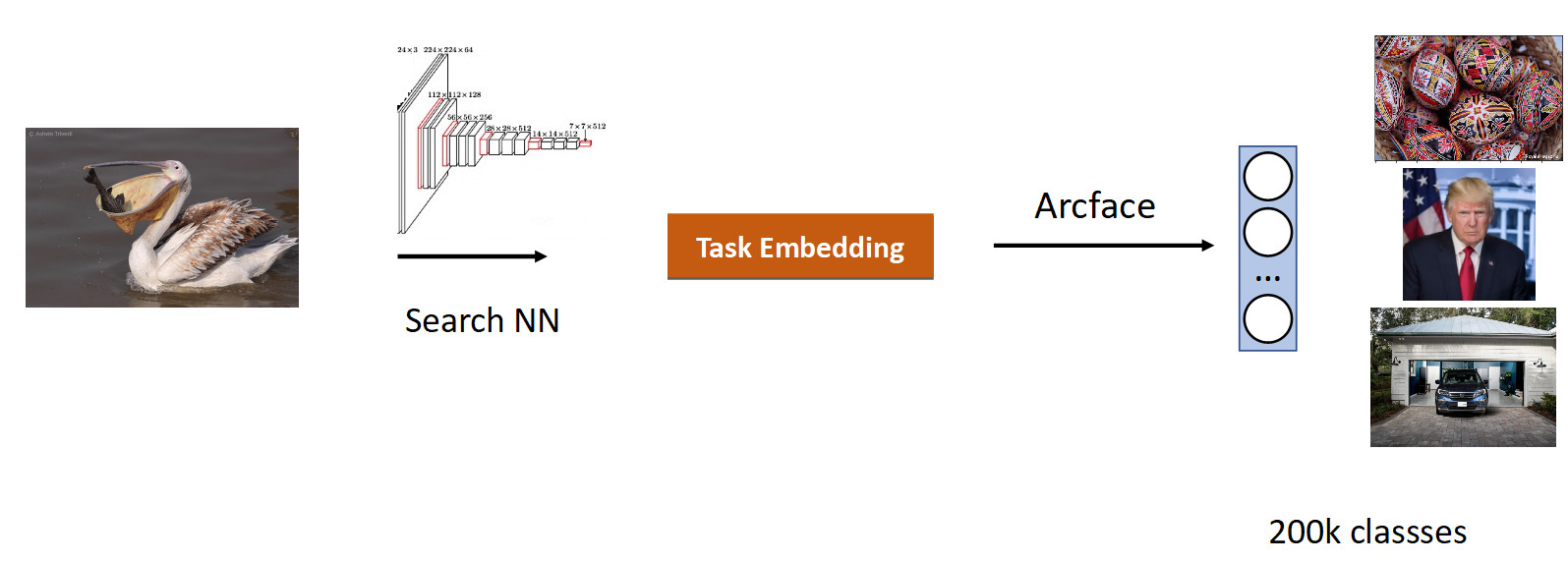
We collected data for this task based on the similarity of pictures and user clicks and got 200k classes. After training with ArFace we got the following result.

In the picture above, we see that for the requested pelican, sparrows were also extradited. Those. embedding turned out to be semantically correct - it is a bird, but racially incorrect. The most annoying thing is that the original model with which we trained, knew these classes and perfectly distinguished them. Here we see the effect that is peculiar to all neural networks, called catastrophic forgetting. That is, the network for additional training forgets the previous task, sometimes even completely. This is exactly what prevents in this task to achieve better quality.
Knowledge distillation
This is treated with the help of a technique called knowledge distillation, when one network teaches another and “transfers its knowledge to it”. What it looks like (full pipeline learning in the picture below).
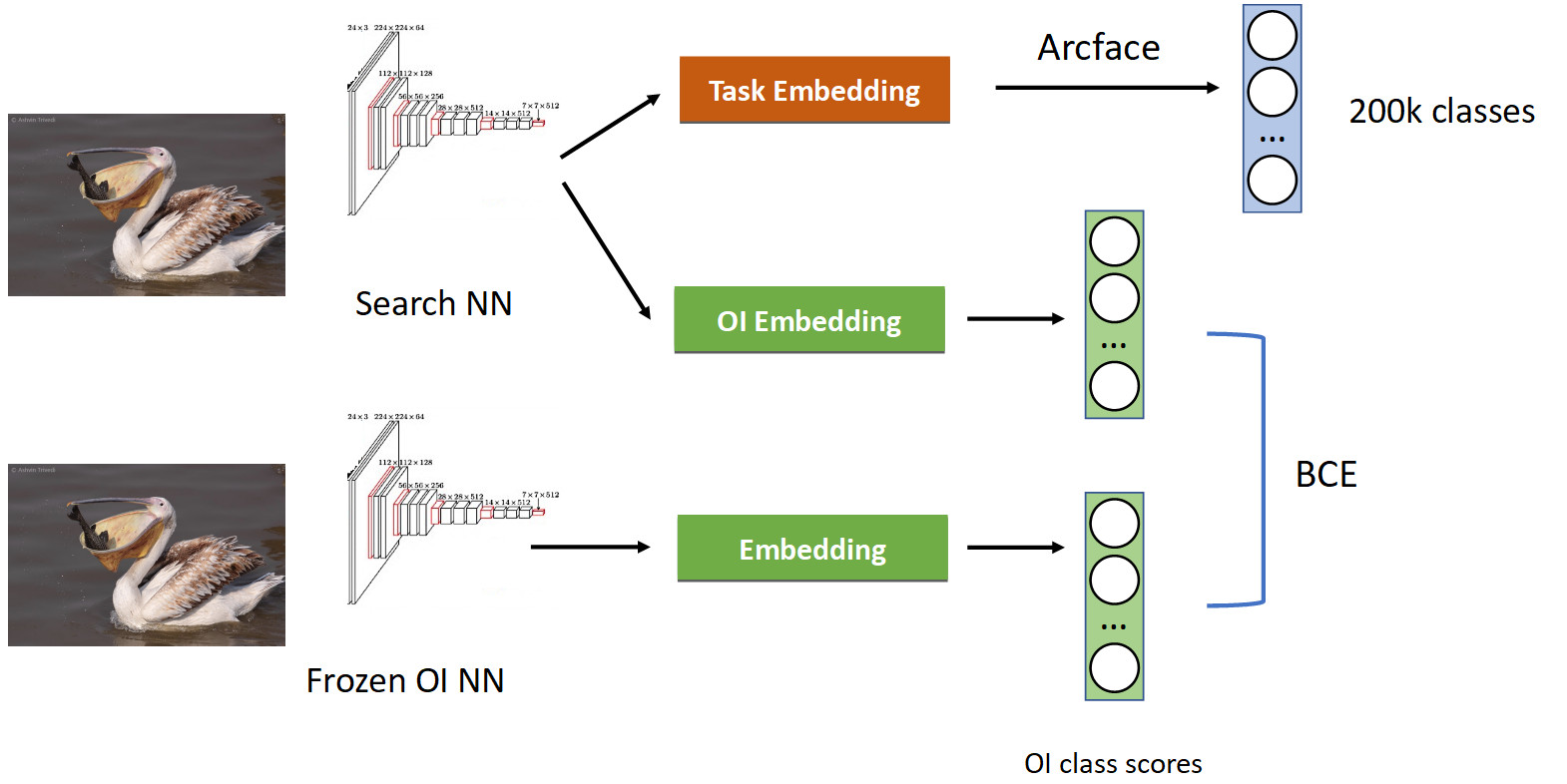
We already have a familiar pipeline classification with Arcface. Recall that we have a network with which we have strained. We froze it and simply calculate its embeddings in all the photographs in which we teach our network, and we get skies of OpenImages classes: pelicans, sparrows, cars, people, etc. ... OpenImages, which gives similar speeds. With the help of BCE, we force the network to issue a similar distribution of these speeds. Thus, on the one hand, we are learning a new task (at the top of the picture), but also making the network not forget its roots (at the bottom) - remember those classes that it used to know. If you correctly balance the gradients in the conditional 50/50 ratio, then this will allow you to leave all the pelicans in the top and throw out all the sparrows from there.

When we applied it, we got a whole percentage in the mAP. This is quite a lot.
| Model | mAP |
|---|---|
| Arcface | 92.8 |
| + Knowledge distil | 93.8 (+1%) |
So if your network forgets the previous task, then treat with the help of knowledge distillation - it works great.
Extra heads
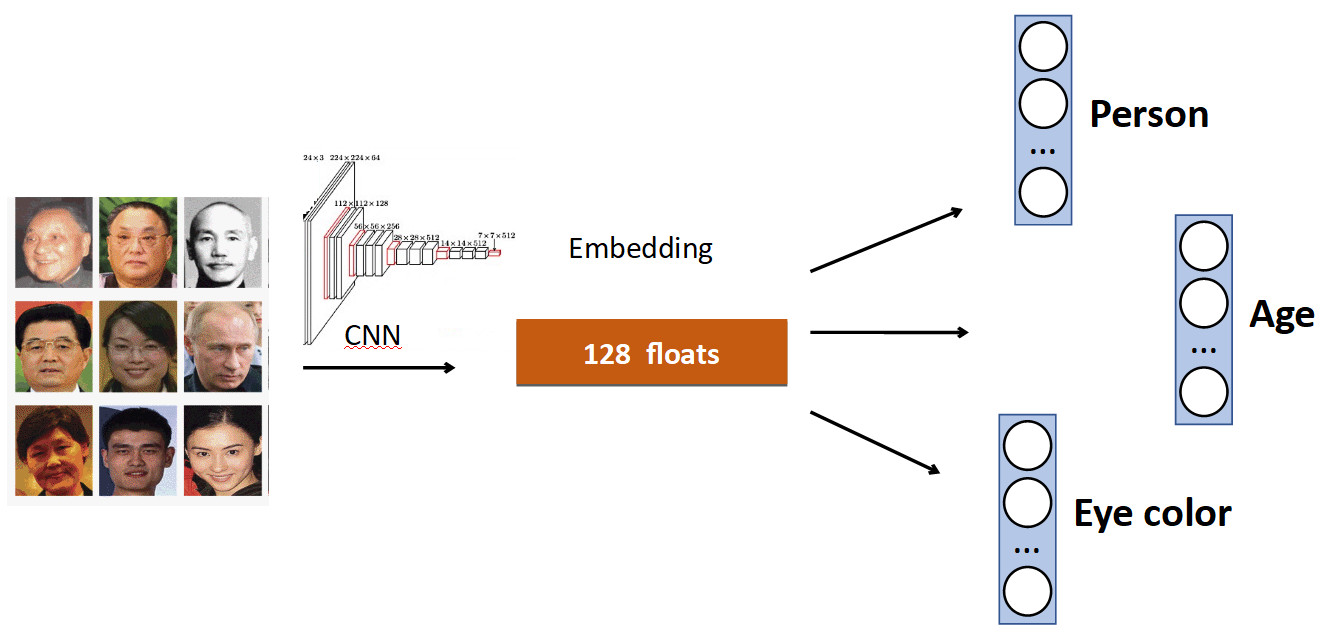
The basic idea is very simple. Again on the example of Face Recognition. We have a set of persons in dataset. But also often in datasets there are other facial characteristics. For example, how old, what color of eyes, etc. All this can be added as another add. signal: teach individual heads to predict this data. Thus, our network receives a more diverse signal, and may, as a result, it is better to learn the basic task.
Another example: queue detection.

Often in datasets with people besides the body there is a separate marking of the position of the head, which, obviously, can be used. Therefore, we added to the network to the prediction of a person's bounding box and a prediction of the bounding box of the head, and received an increase of 0.5% to accuracy (mAP), which is decent. And most importantly - free of charge in terms of performance, because on production, the extra head is turned off.

OCR
A more complex and interesting case is the OCR already mentioned above. Standard pipeline such.
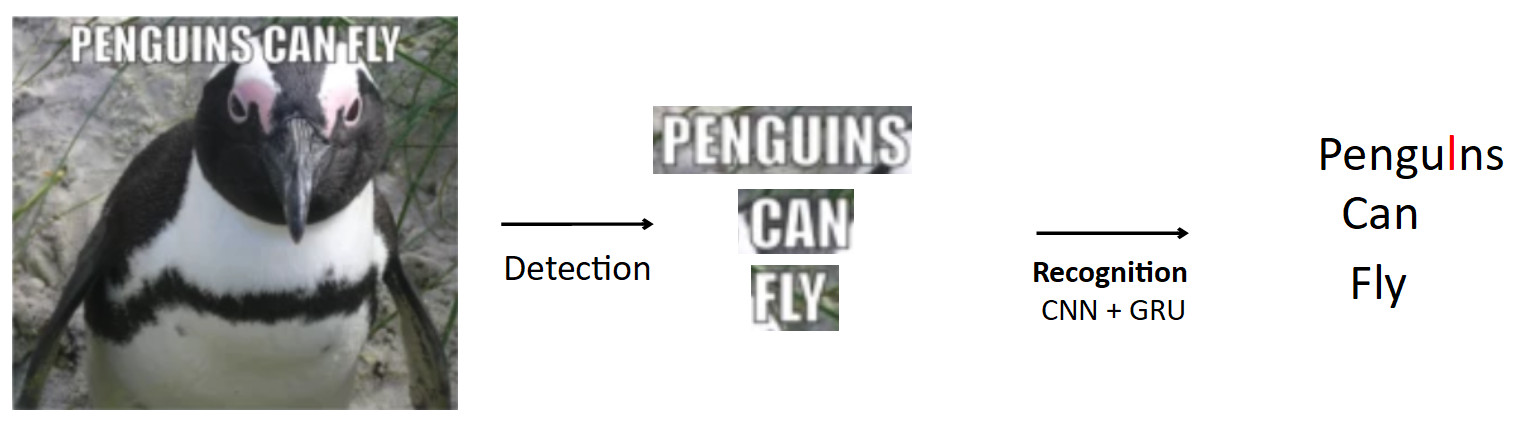
Suppose there is a poster with a penguin, it is written text. Using the detection model, we highlight this text. Then we feed this text to the input of the recognition model, which displays the recognized text. Suppose our network is mistaken, and instead of “i” in the word penguins predicts “l”. This is actually a very common problem in OCR when the network confuses similar characters. The question is how to avoid it - do pengulns translate to penguins? When a person looks at this example, it is obvious to him that this is a mistake, because he has knowledge of the structure of the language. Therefore, one should embed knowledge of the distribution of characters and words in the language into the model.
We used a piece called BPE (byte-pair encoding) for this. This is a compression algorithm, which was generally invented back in the 90s not for machine learning, but now it is very popular and is used in deep learning. The meaning of the algorithm is that frequently encountered subsequences in the text are replaced with new characters. Suppose we have the string “aaabdaaabac” and we want to get BPE for it. We find that a pair of “aa” symbols is the most frequent in our word. We replace it with a new symbol “Z”, we get the string “ZabdZabac”. We repeat the iteration: we see that ab is the most frequent subsequence, we replace it with “Y”, we get the string “ZYdZYac”. Now “ZY” is the most frequent subsequence, we replace it with “X”, we get “XdXac”. Thus, we encode some statistical dependencies in the distribution of the text. If we meet a word in which there are very “strange” (rare for the learning corpus) subsequences, then this word is suspicious.
aaabdaaabac
ZabdZabac Z=aa
ZY d ZY ac Y=ab
X d X ac X=ZYHow it all fits into recognition.
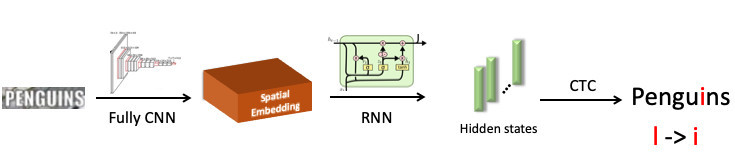
We singled out the word “penguin”, sent it to a convolutional neural network, which produced spatial embedding (a vector of fixed length, for example, 512). Spatial symbol information is encoded in this vector. Next, we use a recurrent network (UPD: in fact, we already use the Transformer model), it gives some hidden states (green bars), in each of which the probability distribution is wired - which model does the symbol represent at a specific position. Next, using CTC-Loss, we spin up these states and get our prediction for the whole word, but with an error: L is in place i.
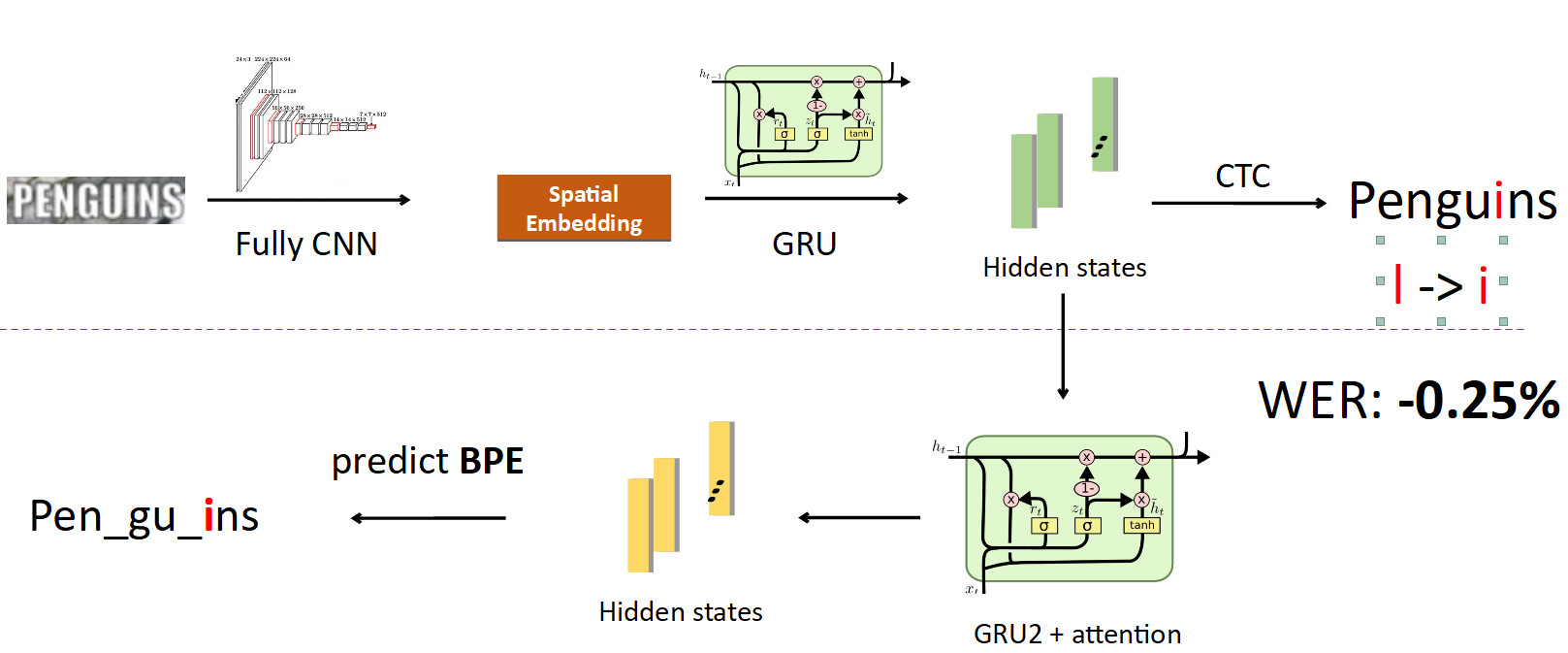
Now integrate BPE into pipeline. We want to move away from the prediction of individual characters to words, so we branch off from the states in which information about characters is sewn up, and set another recurrent network on them; she predicts BPE. In the case of the error described above, 3 BPE is obtained: “peng”, “ul”, “ns”. This is significantly different from the correct sequence for the word penguins, i.e. “pen”, “gu”, “ins”. If you look at it from the point of view of learning the model, then when character-wise prediction the network was mistaken only in one letter of eight (error 12.5%); and in terms of BPE, she was 100% wrong in predicting all 3 BPEs incorrectly. This is a much larger signal to the network that something went wrong, and we need to correct our behavior. When we implemented this, we were able to correct errors of this kind and reduced the Word Error Rate by 0.25% - that is a lot. This additional head is removed during inflection by fulfilling its role during training.
FP16
The last thing I wanted to say about training is FP16. So historically, the networks were trained on the GPU in single precision, that is, FP32. But this is redundant, especially for the inference, where there is enough half-precision (FP16) without loss of quality. However, when learning it is not.
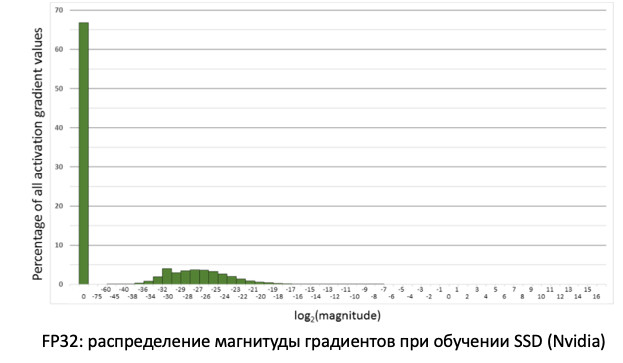
If we look at the distribution of gradients, information that updates our weights when spreading errors, we will see that there is a huge peak at zero. And in general, a lot of values are close to zero. If we simply transfer all the weights to FP16, then it turns out that we will cut off the left side near zero (from the red line).
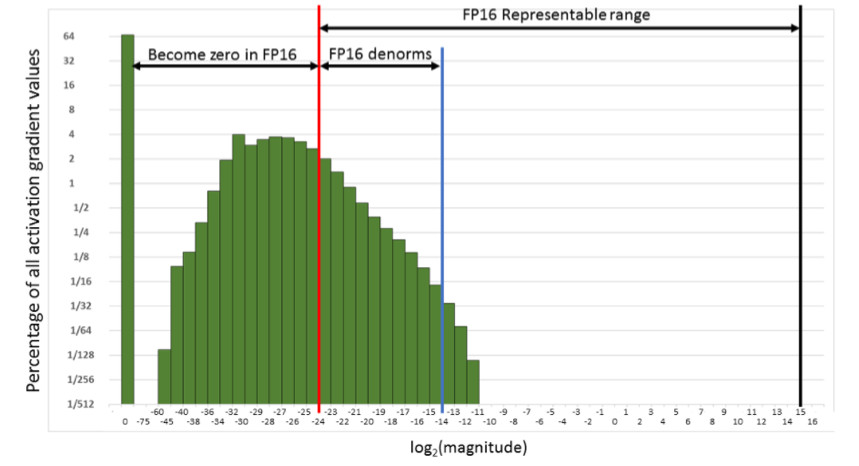
That is, we will reset a very large number of gradients. And the right side, in the working range FP16, is not used at all. As a result, if you train in the forehead on FP16, then the process will most likely diverge (the gray graph in the picture below).
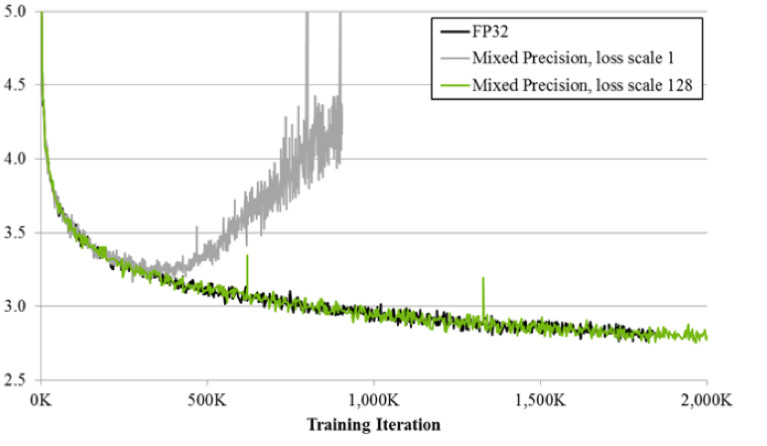
If you train using the technique of mixed precision, the result is almost identical to FP32. Mixed precision does two things.
First, we simply multiply the loss by a constant, for example, 128. Thus, we scale all the gradients, and move their values from zero to the side of the working FP16 range. Second, we store the master version of the FP32 weights, which is used only for updating, and only FP16 is used in the forward and backward pass calculation operations of the networks.
We use Pytorch for training networks. NVIDIA made a special build for it with the so-called APEX, which implements the logic described above. He has two modes. The first is Automatic mixed precision. By the code below you can see how easy it is to use it.

Literally two lines are added to the learning code that wrap loss and the initialization procedure for the model and optimizers. What does AMP do? He monkey patch all functions. What exactly is going on? For example, he sees that there is a convolution function, and it receives a profit from FP16. Then he replaces it with his own, which first makes a cast to FP16, and then performs a convolution operation. So AMP does for all the functions that can be used on the network. For some it does not, because there will be no acceleration. For most tasks, this method is suitable.
The second option: FP16 optimizer for fans of complete control. It is suitable if you want to set which layers will be in FP16, and which in FP32. But there are a number of limitations and difficulties. He does not start with a half-kick (at least we had to sweat to start it). Also FP_optimizer works only with Adam, and only with Adam, which is in APEX (yes, they have their own Adam in the repository, which has a completely different interface than the payload).
We conducted a comparison when training on Tesla T4 cards.
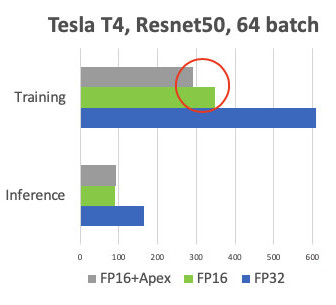
At the Inference, we have the expected acceleration twice. When learning, we see that the Apex framework gives 20% acceleration, relatively simply FP16. As a result, we get training, which is twice as fast and consumes 2 times less memory, and the quality of training does not suffer at all. Freebie.
Inference
Because we use PyTorch, then there is an acute question, how to deploy it into production.

There are 3 options for how to do it (and all of them we used (s).
- ONNX -> Caffe2
- ONNX -> TensorRT
- And more recently, Pytorch C ++
Let's take each one out.
ONNX and Caffe2
1.5 years ago appeared onnx. This is a special framework for converting models between different frameworks. And Caffe2 is a framework adjacent to Pytorch, both are developing on Facebook. Historically, Pytorch has evolved much faster than Caffe2. Caffe2 lags behind Pytorch’s features, so not every model you have trained in Pytorch can be converted to Caffe2. Often it is necessary to retrain with other layers. For example, in Caffe2 there is no such standard operation as upsampling with the nearest neighbor interpolation. As a result, we came to the conclusion that a special docker image was introduced for each model, in which we nail versions of frameworks with nails in order to avoid discrepancies with their future updates, so that when any of the versions are updated again, we do not waste time on their compatibility . All this is not very convenient and lengthens the deployment process.
Tensor RT
There is also Tensor RT, a NVIDIA framework that optimizes the network architecture for speeding up the inference. We made our measurements (on the Tesla T4 map).
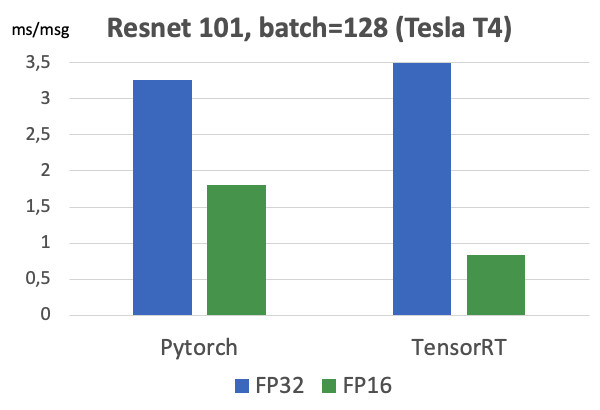
If you look at the graphs, you can see that the transition from FP32 to FP16 gives 2x acceleration on Pytorch, while TensorRT gives you already 4x. Very significant difference. We tested this on the Tesla T4, which has tensor cores, which very well utilize the FP16 calculations, which is obviously excellent used in TensorRT. Therefore, if there is a highly loaded model that runs on dozens of video cards, then there are all the motivators to try Tensor RT.
However, when working with TensorRT, there is even more pain than in Caffe2: there are even less supported layers. Unfortunately, every time we use this framework, we have to suffer a bit to convert the model. But for high-loaded models have to do it. ;) I note that on maps without tensor kernels such a massive increase is not observed.
Pytorch C ++
And the last - Pytorch C ++. Half a year ago, the developers of Pytorch realized all the pain of the people who use their framework, and released the TorchScript tutorial , which allows tracing and serializing the Python model into a static graph without unnecessary gestures (JIT). She came out in December 2018, we immediately began to use it, immediately caught several performance bugs and waited a few months for fixing from Chintala . But now it is a fairly stable technology, and we actively use it for all models. The only thing missing documentation, which is actively supplemented. Of course, you can always look at the * .h-files, but for people who do not know the pluses, this is hard. But then there really is an identical work with Python. In C ++, the code runs on -jit on the minimal Python interpreter, which practically guarantees C ++ identity with Python.
findings
- Task setting is super important. It is necessary to communicate with product managers on the data. Before you start to do the task, it is desirable to have a ready-made testset, on which we measure the final metrics before the implementation stage.
- We clean the data using clustering. We get the model on the original data, clean the data using clustering CLink and repeat the process until convergence.
- Metric learning: even classification helps. State-of-the-art - ArcFace, which is easy to integrate into the learning process.
- If you do transfer learning from a pre-trained network, then, so that the network does not forget the old task, use knowledge distillation.
- It is also useful to use several net heads that will utilize different signals from the data to improve the main task.
- For FP16, you must use the Apex assembly from NVIDIA, Pytorch.
- And inference it is convenient to use Pytorch C ++.
Source: https://habr.com/ru/post/460307/
All Articles