AERODISK Engine: Disaster. Part 2. Metroklaster

Hello, readers Habra! In the last article, we talked about a simple means of disaster recovery in AERODISK ENGINE storage systems - about replication. In this article, we will dive into a more complex and interesting topic - a metro cluster, that is, a means of automated disaster protection for two data centers, which allows data centers to work in active-active mode. Let's tell, show, break and repair.
As usual, at the beginning of the theory
A metrocluster is a cluster separated into several sites within a city or district. The word "cluster" clearly hints at us that the complex is automated, that is, the switching of cluster nodes in the event of failures occurs automatically.
This is where the main difference between the metrocluster and ordinary replication lies. Automation of operations. That is, in the event of certain incidents (data center failure, channel breaks, etc.), the storage system will independently perform the necessary actions in order to preserve the availability of data. When using conventional replicas, these actions are performed in whole or in part manually by the administrator.
What is it for?
The main goal pursued by customers using various implementations of the metro cluster is to minimize the RTO (Recovery Time Objective). That is, minimize the time it takes to recover IT services after a failure. If you use regular replication, then the recovery time will always be longer than the recovery time at the metro cluster. Why? Very simple. The administrator must be at the workplace and switch the replication hands, and the metrocluster does it automatically.
If you do not have a dedicated administrator on duty who does not sleep, does not eat, does not smoke, and does not get sick, and looks at the storage system state 24 hours a day, then there is no way to guarantee that the administrator will be available for manual switching during a failure.
Accordingly, the RTO in the absence of a metro cluster or 99th level immortal admin The duty service of administrators will be equal to the sum of the switching time of all systems and the maximum time interval through which the administrator is guaranteed to start working with storage systems and adjacent systems.
Thus, we come to the obvious conclusion that the metrocluster should be used if the requirement for an RTO is minutes, not hours or days. - to services within minutes, and even seconds.
How it works?
At the lower level, the metrocluster uses the synchronous data replication mechanism that we described in the previous article (see link ). Since replication is synchronous, the requirements for it are relevant, or rather:
- fiber as physics, 10 Gigabit Ethernet (or higher);
- distance between data centers is no more than 40 kilometers;
- the delay of the optics channel between data centers (between storage systems) up to 5 milliseconds (optimally 2).
All these requirements are advisory in nature, that is, the metrocluster will work even if these requirements are not met, but it should be understood that the consequences of non-observance of these requirements are equal to slowing down the operation of both storage systems in the metrocluster.
So, to transfer data between storage systems, a synchronous replica is used, and how replicas are automatically switched and most importantly, how to avoid split-brain? For this, at the level above, an additional entity is used - the arbiter.
How does the referee work and what is his task?
The arbitrator is a small virtual machine, or a hardware cluster that needs to be run on a third platform (for example, in the office) and provide access to ICMP and SSH storage. After the launch, the arbiter should be set to IP, and then from the storage system, specify its address, plus the addresses of the remote controllers that participate in the metrocluster. After that, the arbitrator is ready to work.
The arbitrator performs continuous monitoring of all storage systems in the metrocluster and, in case of unavailability of this or that storage system, after confirming the inaccessibility from another cluster member (one of the live storage systems), decides to start the procedure for switching replication rules and mapping.
A very important point. The arbitrator should always be located on the site, different from those on which the storage systems are located, that is, neither in data center-e 1, where is storage system 1, or in data center-e 2, where storage system 2 is installed.
Why? Because only this way the arbiter with the help of one of the surviving storage systems can unambiguously and accurately determine the fall of any of the two sites where the storage systems are installed. Any other ways of placing an arbiter may result in a split-brain.
Now dive into the details of the work of the arbitrator
Several services are running on the arbiter, which are constantly polled by all storage controllers. If the result of the survey differs from the previous one (available / unavailable), then it is recorded in a small database, which also works on the arbitrator.
Consider the logic of the arbitrator in more detail.
Step 1. Determination of unavailability. The event signaling the failure of the storage system is the lack of ping from both controllers of the same storage system for 5 seconds.
Step 2. Launching the switching procedure. After the arbitrator realized that one of the storage systems was unavailable, he sends a request for a “live” storage system in order to verify that the “dead” storage system has indeed died.
After receiving such a command from the arbitrator, the second (live) storage system additionally checks the availability of the fallen first storage system and, if not, sends confirmation to the arbitrator of his guess. Storage is indeed unavailable.
After receiving such confirmation, the arbiter starts the remote procedure for switching replication and raising the mapping on those replicas that were active (primary) on the fallen storage system, and sends the command to the second storage system to make these replicas from secondary to primary and raise the mapping. Well, the second storage system, respectively, performs these procedures, after which it provides access to the lost LUNs from themselves.
Why do I need additional verification? For the quorum. That is, most of the total odd (3) number of cluster members must confirm the fall of one of the cluster nodes. Only then will this decision be exactly the right one. This is necessary in order to avoid erroneous switching and, accordingly, split-brain.
Step 2 takes about 5 to 10 seconds, so taking into account the time required to determine unavailability (5 seconds), within 10 to 15 seconds after the accident, LUNs with a fallen storage system will be automatically available for working with a live storage system.
It is clear that in order to avoid breaking the connection with the hosts, you also need to take care of the correct timeout setting on the hosts. The recommended timeout is at least 30 seconds. This will not allow the host to break the connection to the storage system during a load transfer during an accident and will be able to guarantee that there will be no I / O interruption.
Wait a second, it turns out, if everything is so good with the metrocluster, why do we need regular replication?
In fact, it's not that simple.
Consider the pros and cons of the metro cluster
So, we realized that the obvious advantages of a metrocluster compared to conventional replication are:
- Full automation, providing minimal recovery time in the event of a disaster;
- And that's all :-).
And now, attention, cons:
- The cost of the solution. Although the metrocluster in the Aerodisk systems does not require additional licensing (the same license is used as for the replica), the cost of the solution will still be even higher than with the use of synchronous replication. You will need to implement all the requirements for a synchronous replica, plus the requirements for the metrocluster associated with additional switching and an additional platform (see planning a metrocluster);
- The complexity of the solution. The metrocluster is much more complex than a regular replica, and requires much more attention and effort to plan, configure and document.
Eventually. Metrocluster is definitely a very high-tech and good solution when you really need to provide an RTO in seconds or minutes. But if there is no such task, and the RTO at the clock is OK for the business, then there is no point in shooting a cannon at the sparrows. Enough conventional worker-peasant replication, since the metrocluster will cause additional costs and complicate the IT infrastructure.
Metro cluster planning
This section does not claim to be a comprehensive design guide for the metrocluster, but only shows the main directions that should be worked out if you decide to build such a system. Therefore, with the actual implementation of the metrocluster, be sure to engage the storage vendor (that is, us) and other related systems for consultation.
Sites
As stated above, a minimum of three sites are required for a metrocluster. Two data centers, where the storage and related systems will work, as well as the third platform, where the arbitrator will work.
The recommended distance between data centers is no more than 40 kilometers. A longer distance with a high probability will cause additional delays, which are extremely undesirable in the case of a metro cluster. Recall delays should be up to 5 milliseconds, although it is desirable to keep within 2.
Delays are recommended to be checked also in the planning process. Any more or less adult provider that provides fiber between data centers, can organize quality checking fairly quickly.
As for the delays before the arbitrator (that is, between the third platform and the first two), the recommended threshold for delays is up to 200 milliseconds, that is, the usual corporate VPN connection over the Internet will do.
Switching and network
Unlike the replication scheme, where it is sufficient to connect storage systems from different sites to each other, a circuit with a metro cluster requires connecting hosts with both storage systems at different sites. To make it clearer, what is the difference, both schemes are listed below.
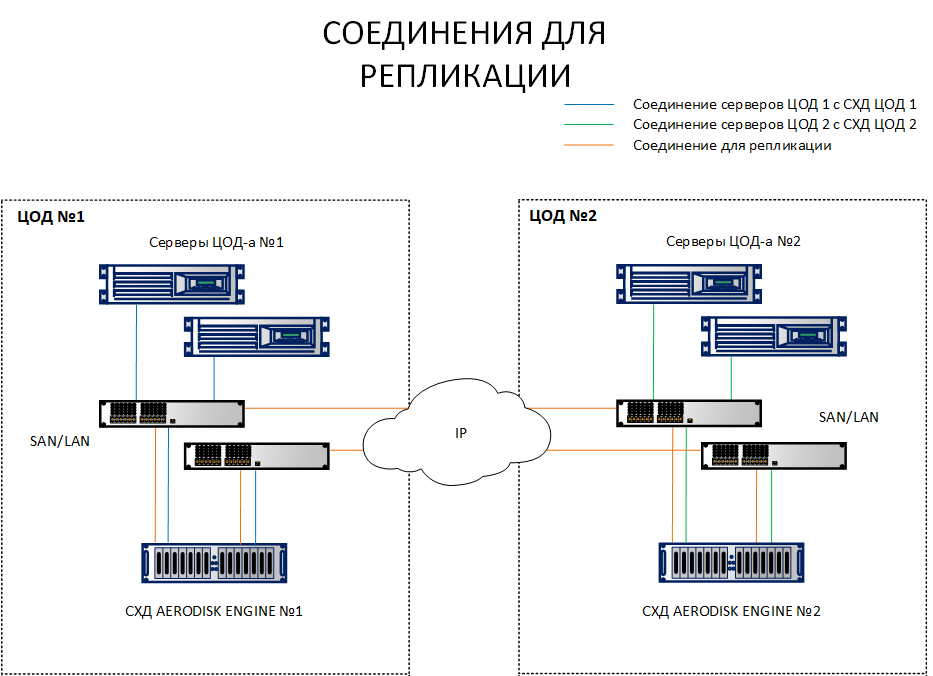

As can be seen from the diagram, we have site 1 hosts looking at both storage system 1 and storage system 2. Also, on the contrary, site 2 hosts look at storage system 2 and storage system 1. That is, each host sees both storage systems. This is a prerequisite for the operation of the metro cluster.
Of course, there is no need for each host to pull an optical cord into another data center, no ports and laces are enough. All these connections must be made via Ethernet 10G + or FibreChannel 8G + switches (FC only for connecting hosts and storage for IO, the replication channel is currently only available over IP (Ethernet 10G +).
Now a few words about the network topology. The important point is the correct configuration of subnets. You must immediately define several subnets for the following types of traffic:
- Subnet for replication, which will synchronize data between storage systems. There may be several of them, in this case it does not matter, it all depends on the current (already implemented) network topology. If there are two, then obviously the routing between them must be configured;
- Storage subnets through which hosts will access storage resources (if it is iSCSI). There should be one such subnet in each data center;
- Management subnets, that is, three routed subnets on three sites from which the storage is managed, and the arbiter is located there.
We do not consider subnets for access to host resources here, since they are highly dependent on tasks.
Separating different traffic on different subnets is extremely important (it is especially important to separate the replica from I / O), because if you mix all the traffic into one “thick” subnet, then this traffic will be impossible to manage, and in the conditions of two data centers, this can cause different options for network collisions. In this issue, we will not dive much into this article, since the planning of a network stretched between data centers can be read on the resources of network equipment manufacturers, where it is described in great detail.
Referee configuration
The arbitrator must provide access to all ICMP and SSH storage control interfaces. You should also consider the resiliency of the arbitrator. There is a nuance.
The resiliency of the arbitrator is very desirable, but not required. And what will happen if the referee crashes in time?
- The work of the metrocluster in the normal mode will not change, because arbtir doesn’t affect the metrocluster operation in the normal mode absolutely no way (its task is to switch the load between data centers in time)
- Moreover, if for one reason or another the arbiter falls and “sleeps” the accident in the data center, then there will be no switching, because there will be no one to give the necessary switching commands and organize a quorum. In this case, the metrocluster will turn into a regular scheme with replication, which will have to be switched by hand during a catastrophe, which will affect the RTO.
What follows from this? If you really need to ensure a minimum RTO, you need to ensure the resiliency of the arbitrator. There are two options for this:
- Run the virtual machine with the arbiter on the fault-tolerant hypervisor, since all adult hypervisors support fault tolerance;
- If on the third site (in the conditional office)
too lazy to put a normal clusterIf there is no existing hypervisor cluster, we have provided for the hardware version of the arbiter, which is made in a 2U box, in which two regular x-86 servers operate and which can survive a local failure.
We strongly recommend to ensure the resiliency of the arbitrator, despite the fact that in normal mode the metro cluster is not needed. But as the theory and practice shows, if we build a truly reliable disaster-resistant infrastructure, then it is better to be safe. It is better to protect yourself and business from the “law of meanness”, that is, from the failure of both the arbitrator and one of the sites where the storage system is located.
Solution architecture
Given the requirements above, we get the following overall solution architecture.

LUNs should be evenly distributed across two sites to avoid severe overload. At the same time, when sizing in both data centers, not only double volume (which is necessary for storing data on two storage systems simultaneously), but also double performance in IOPS and MB / s should be used to prevent degradation of applications in the event of failure of one data center. ov
Separately, we note that with a proper approach to sizing (that is, provided that we have provided proper upper boundaries for IOPS and MB / s, as well as the necessary CPU and RAM resources), if one of the storage systems in the metro cluster fails, temporary work on a single storage system.
This is due to the fact that in the working conditions of two sites at the same time, running synchronous replication “eats” half of the write performance, since each transaction must be written to two storage systems (similar to RAID-1/10). So, if one of the storage systems fails, the replication effect temporarily (until the failed storage system rises) disappears, and we get a two-fold increase in performance per record. After the LUNs of the failed storage system are restarted on the working storage system, this two-fold increase disappears due to the load from the LUNs of the other storage system, and we return to the same level of performance that we had before the “drop” but only within the same site.
With the help of competent sizing, you can provide the conditions under which the users will not feel the failure of the entire storage system at all. But once again, this requires very careful sizing, for which, by the way, you can contact us for free :-).
Metro cluster setting
Setting up a metrocluster is very similar to setting up normal replication, which we described in a previous article . Therefore, we focus only on the differences. In the lab, we set up a bench based on the architecture above only in the minimal version: two storage systems connected via 10G Ethernet to each other, two 10G switches and one host, which looks through the switches at both storage ports of 10G. The arbitrator works in a virtual machine.

When configuring virtual IP (VIP) for a replica, select the VIP type for the metro cluster.

Created two replication links for two LUNs and distributed them across two storage systems: LUN TEST Primary on SHD1 (METRO link), LUN TEST2 Primary for SHD2 (METRO link 2).

For them, we configured two identical targets (in our case, iSCSI, but FC is supported, the configuration logic is the same).
SHD1:

SHD2:

For replication connections, mappings were made on each storage system.
SHD1:

SHD2:

Set up multipath and presented to the host.


We configure the arbitrator
You don’t need to do anything special with the arbiter himself, you just need to turn it on at the third site, assign it an IP and configure access to it via ICMP and SSH. The configuration itself is performed from the storage systems themselves. In this case, it is sufficient to configure the arbiter once on any of the storage controllers in the metro cluster, these settings will be distributed to all controllers automatically.
In the Remote Replication >> Metrocluster (on any controller) section >> the Configure button.
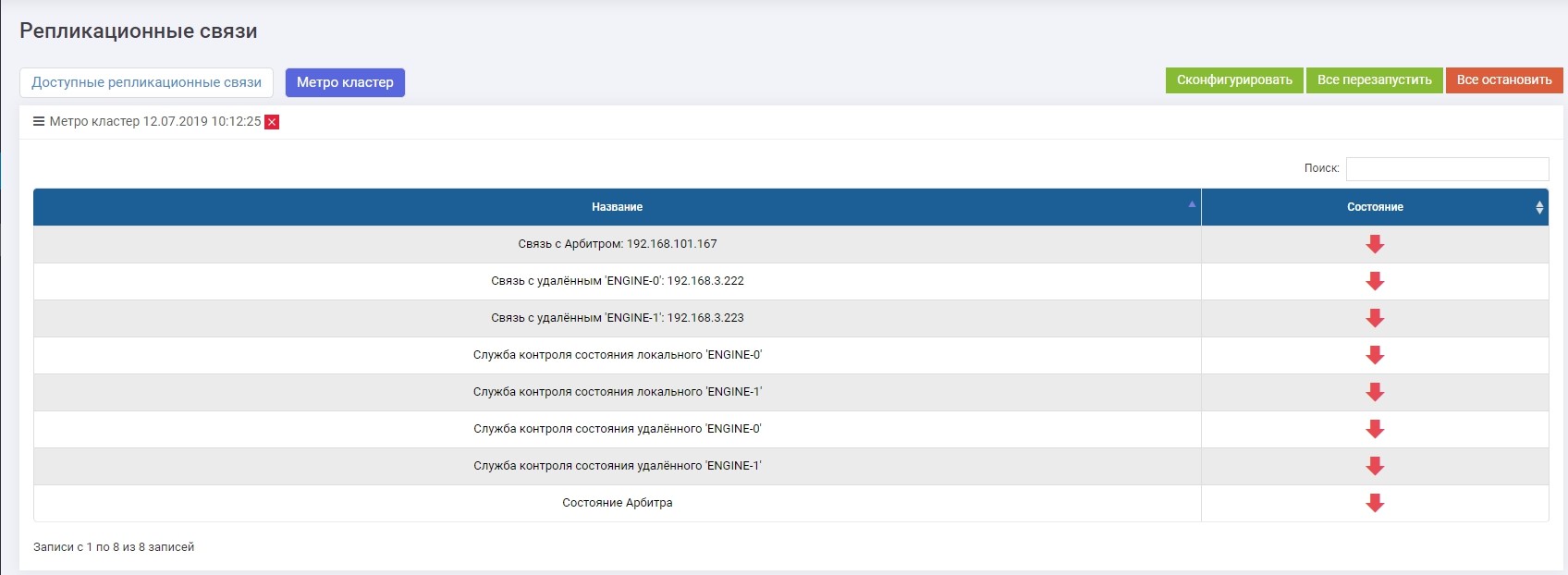
Enter the IP arbiter, as well as the control interfaces of the two controllers of the remote storage system.

After that, you need to turn on all services (the "Restart All" button). In the case of reconfiguration in the future, the service must be restarted for the settings to take effect.

We check that all services are running.

This completes the metro cluster setup.
Crush test
Crash test in our case will be quite simple and fast, since the replication functionality (switching, consistency, etc.) was considered in the previous article . Therefore, to test the reliability of the metrocluster, it is enough for us to test the automation of accident detection, switching, and the absence of recording loss (input / output stopping).
To do this, we emulate a complete failure of one of the storage systems, physically turning off both its controllers, running previously copying a large file to the LUN, which must be activated on the other storage system.

We disconnect one SHD. On the second storage system we see alerts and messages in the logs that the connection with the neighboring system has disappeared. If you have configured SMTP or SNMP monitoring alerts, then the corresponding alerts will be sent to the admin.

Exactly 10 seconds later (seen in both screenshots) the METRO replication link (the one that was Primary on the fallen storage) automatically became Primary on the working storage. By activating the existing mapping, LUN TEST remained available to the host, the recording slipped a bit (within the promised 10 percent), but was not interrupted.


Test completed successfully.
Summarize
The current implementation of the metrocluster in the AERODISK Engine N-Series storage systems fully solves the problems where it is necessary to eliminate or minimize the downtime of IT services and ensure their work 24/7/365 with minimal labor costs.
We can say, of course, that all of this theory, ideal laboratory conditions, and so on ... BUT we have a number of implemented projects in which we implemented disaster recovery functionality, and the systems work perfectly. One of our fairly well-known customers, where just two storage systems are used in a disaster-tolerant configuration, has already agreed to publish information about the project, so in the next part we will talk about combat deployment.
Thank you, we are waiting for a productive discussion.
')
Source: https://habr.com/ru/post/460305/
All Articles