Stop the line or upgrade your pipeline, yo
If your releases are lightning fast, automated and reliable, you can skip this article.
Previously, our release process was manual, slow, and buggy.
We missed the sprint after the sprint, because we did not have time to do and put the features to the next Sprint Review. We hated our releases. Often they lasted for three or four days.
In this article, we describe the practice of Stop the Line, which helped us focus on eliminating display pipeline problems. In just three months, we managed to increase the speed of deployment by 10 times. Today, our deployment is fully automated, and the release of the monolith takes only 4-5 hours.
')
I remember how we came up with Stop the Line. At a general retrospective, we discussed long releases that prevented us from achieving the goals of the sprint. One of our developers suggested:
We decided that if the release lasts more than 48 hours, then we turn on the flasher and stop all teams working on the monolith business features. All teams working on the monolith should stop the development and focus on pushing the current release to prod or eliminate the reasons for the delayed release. When the release is stuck, it makes no sense to make new features, because they still come out soon. At this time, it is forbidden to write new code, even in separate branches.
We also entered “Stop the Line Board” on a simple flipchart. On it we write tasks that either help to push the current release, or help to avoid the reasons for its delay.
Of course, Stop The Line is not an easy decision, but this practice is an important step towards uninterrupted delivery and genuine DevOps.
There is a golden rule in Extreme Programming (XP): if something hurts, do it as often as possible. Our releases have always been a pain. We spent several days to deploy the test environment, restore the database, run the tests (usually several times), figure out why they fell, fix the bugs, and finally release.
The sprint lasts 2 weeks, and the release rolls for three days. In order to be released before Sprint Review on Friday, you need to start the release on Monday in a good way. This means that we are working on a sprint goal only 50% of the time. And if we could release every day, then the productive period of work would increase to 80-90%.
Our average release usually took two to three days. At first, six teams worked on the code in the common dev branch (and with the growth of the company, the number of teams increased to nine). Just before the release, we branched the release branch. While this branch is being tested and regressed, the teams continue development in the general dev branch. Before the release branch reaches the sales, the teams will write quite a lot of code.
The more changes in the increment, the greater the chance that changes made by different teams will affect each other, which means that the more carefully the increment must be tested, and the longer its release will take. This is a self-reinforcing cycle (see Fig. 2). The more changes in the release (“horse” release), the longer the regression time. The longer the regression time, the more time between releases and the more changes the team makes before the next release. We called it "horses give birth to horses." The following CLD diagram (Causal Loop Diagram) illustrates this dependency:
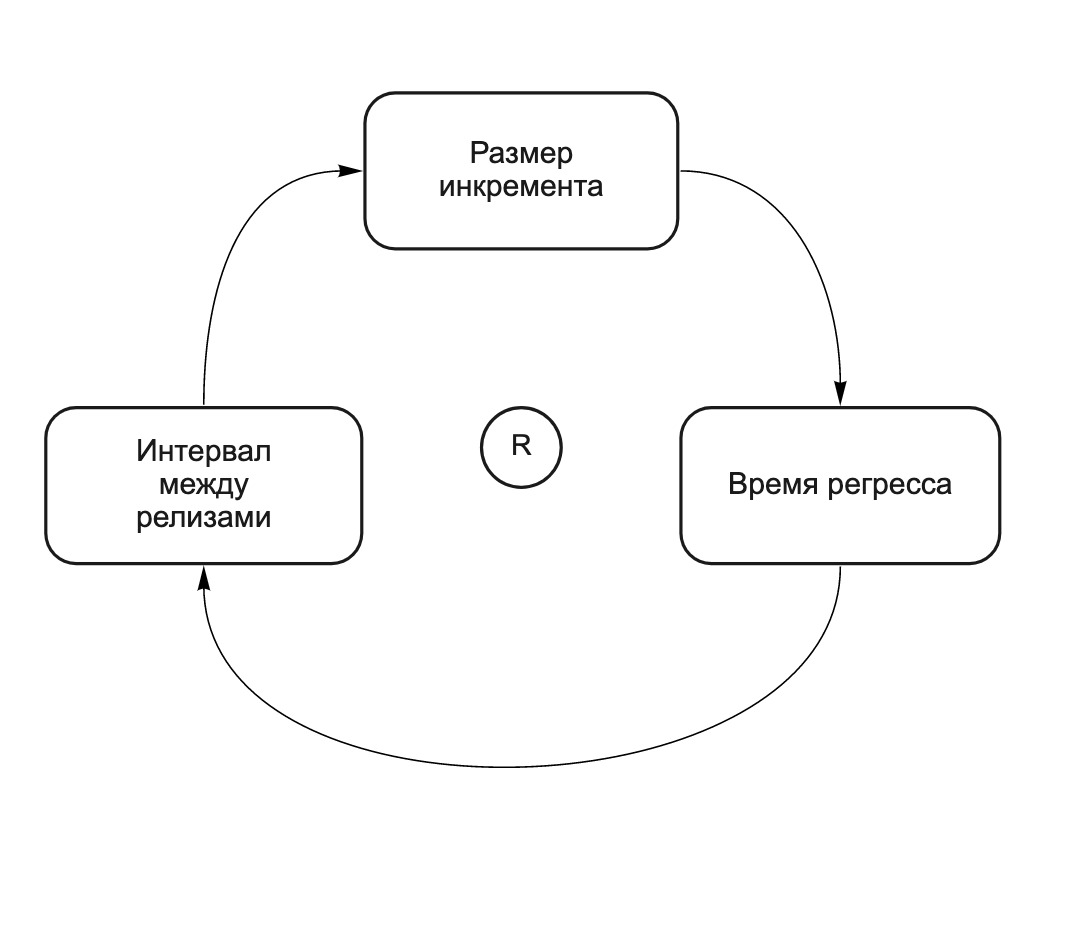
Fig. 2. CLD chart: long releases lead to even longer releases
At first we decided to get rid of manual regression testing, but the path to this was a long and difficult one. Two years ago, Dodo IS manual regression lasted a whole week. Then we had a whole team of manual testers who checked the same features in 10 countries week after week. Such work is not to be envied.
In June 2017, we formed the QA team. The main goal of the team was to automate the regression of the most important business operations: order taking and production of products. As soon as we had enough tests to start us to trust them, we completely abandoned manual testing. But this happened only 1.5 years after we started automating the regression. After that, we dismissed the QA team, and members of the QA team joined the development teams.
However, UI tests have significant drawbacks. Since they depend on real data in the database, this data must be configured. One test can spoil data for another test. The test may fall, not only because some logic is broken, but also because of a slow network or outdated data in the cache. We had to spend a lot of effort to get rid of the flashing tests and make them reliable and reproducible.
We created a community of like-minded people #IReleaseEveryDay and brainstormed how to speed up the deployment pipeline. The first actions were:
Thanks to the above solutions, we have reduced the average release time, but it was still annoyingly long. It's time for system changes.
We introduced the rule that if the release lasts more than 48 hours, then we turn on the flasher and stop all teams working on the monolith's business features. All teams working on the monolith should stop development and focus on rolling out the current release before selling or eliminating the reasons for the delayed release.
During Stop the line, an orange flasher is turned on in the office. Anyone who comes to the third floor, where the developers of Dodo IS work, sees this visual signal. We decided not to drive our developers crazy with the sound of a siren and left only annoying blinking lights. So conceived. How can we feel comfortable when release is in trouble?

Fig. 3. Flashing light Stop the Line
At first, Stop the Line liked all the teams, because it was fun. Everyone was happy as children and laid out photos of our flashers. But when it burns 3-4 days in a row, it becomes not funny. One day, one of the teams broke the rules and flooded the code into the dev branch during Stop the Line to save their sprint goal. It is easiest to break the rule if it prevents you from working. This is a quick and dirty way to make a business feature by ignoring a system problem.
As a Scrum Master, I could not tolerate violations of the rules, so I raised this issue in general retrospective. We had a difficult conversation. Most teams agreed that the rules apply to everyone. We agreed that each team must abide by the rules, even if it does not agree with them. And at the same time how to change the rules without waiting for the next retrospective.
Initially, developers didn’t focus on solving system problems with deployment pipelint. When the release got stuck, instead of helping to eliminate the causes of the delay, they preferred to develop microservices that were not covered by the Stop the Line rule. Microservices are good, but the problems of the monolith will not solve themselves. In order to solve these problems, we introduced the Back The Line backlog.
Some solutions were quick fixes that hid problems rather than solved them. For example, many tests were repaired by increasing timeouts or adding relays. One such test was performed for 21 minutes. The test searched for the most recently created employee in the table without an index. Instead of correcting the logic of the request, the programmer added 3 retry. As a result, the slow test became even slower. When Stop The Line appeared the owner team, which focused on the problems of tests, over the next three sprints, they were able to speed up our tests by 2-3 times.
Previously, only one team had problems with the release - the one that supported the release. The teams tried to get rid of this unpleasant duty as quickly as possible, instead of investing in long-term improvements. For example, if the tests on the test environment have fallen, they can be restarted locally and if the tests pass, continue the release. With the introduction of Stop The Line, teams have time to stabilize tests. We rewrote the test data preparation code, replaced some UI tests with API tests, removed unnecessary timeouts. Now almost all tests pass quickly and on any environment.
Previously, teams did not engage in technical debt systematically. Now we have the backlog of technical improvements that we analyze during Stop the Line. For example, we rewrote tests on .Net Core, which allowed us to run them in Docker. Running tests in Docker allowed us to use the Selenium Grid to parallelize tests and further reduce their execution time.
Previously, teams relied on the QA team for testing and the infrastructure team for deployment. Now there is no one to count on except themselves. The teams themselves test and release the code in Production. This is genuine, not fake DevOps.
In the general sprint retrospective, we are reviewing the experiments. For several subsequent retrospectives, we made many changes to the Stop the Line rules, for example:
In fact, the practice of Stop the Line converts a self-amplifying cycle (Fig. 2) into two balancing cycles (Fig. 4). Stop the Line helps us focus on improving the deployment pipeline when it becomes too slow. In total for 4 sprints we:
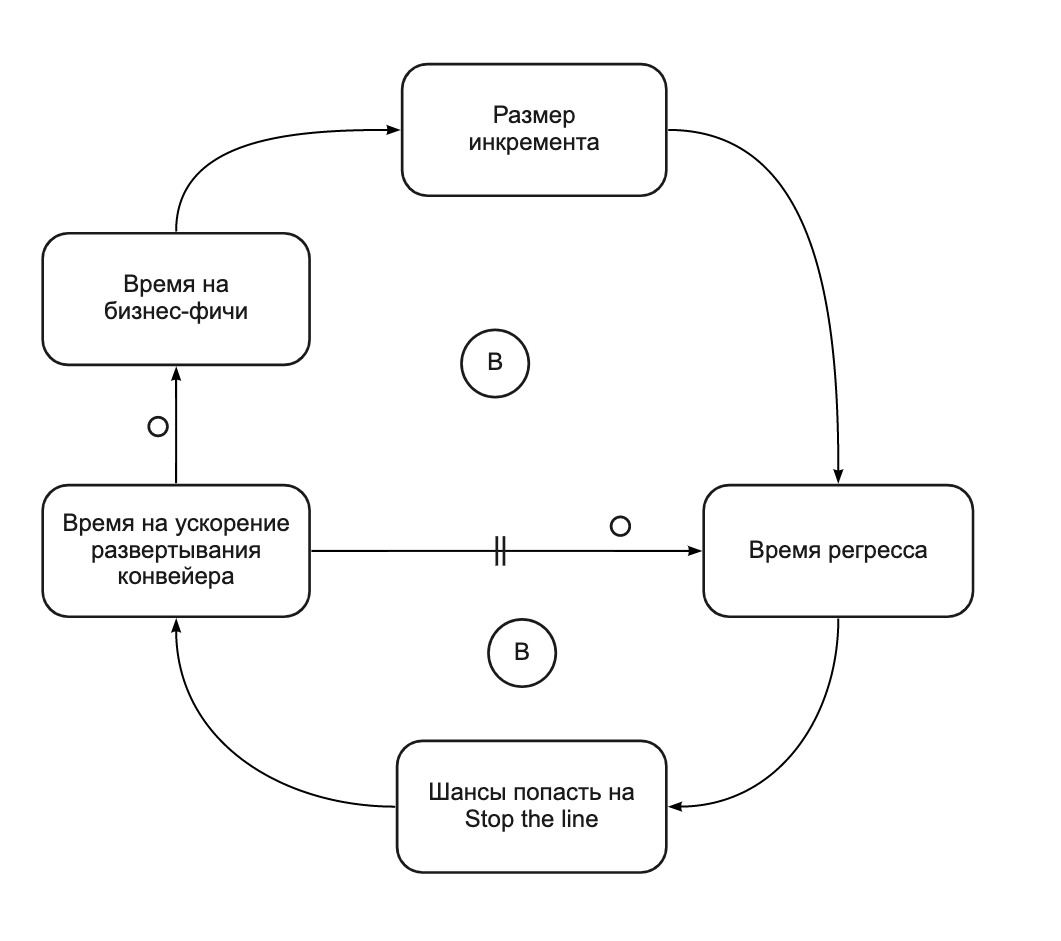
Fig. 4. CLD chart: Stop the Line balances release time
Stop The Line is a vivid example of a strong solution invented by the development teams themselves. Scrum Master can not just take and bring teams a brilliant new practice. The practice will only work if the teams themselves invented it. This requires favorable conditions: an atmosphere of trust and a culture of experimentation.
Necessarily need the trust and support from the business, which is possible only with full transparency. Feedback, such as regular general retrospective with all team members, helps to come up with, introduce and change new practices.
Over time, the practice of Stop the Line should kill itself. The more often we stop the line, the more we invest in the deployment pipeline, the more stable and fast the release becomes, the fewer reasons for stopping. In the end, the line will never stop unless we decide to lower the threshold, for example, from 48 to 24 hours. But thanks to this practice, we have greatly improved the release procedure. The teams gained experience not only in development, but also in fast delivery of value to the prod. This is authentic DevOps.
What's next? I dont know. Perhaps we will soon give up this practice. The teams will decide. But it is obvious that we will continue to move towards Continuous Delivery and DevOps. One day my dream of releasing a monolith several times a day will surely come true.
Previously, our release process was manual, slow, and buggy.
We missed the sprint after the sprint, because we did not have time to do and put the features to the next Sprint Review. We hated our releases. Often they lasted for three or four days.
In this article, we describe the practice of Stop the Line, which helped us focus on eliminating display pipeline problems. In just three months, we managed to increase the speed of deployment by 10 times. Today, our deployment is fully automated, and the release of the monolith takes only 4-5 hours.
')
Stop the Line. Practice, invented by the team
I remember how we came up with Stop the Line. At a general retrospective, we discussed long releases that prevented us from achieving the goals of the sprint. One of our developers suggested:
- [Sergey] Let's limit the amount of release. This will help us test, fix bugs and deploy faster.
- [Dima] Can we introduce a limit on the work in progress (WIP limit)? For example, as soon as we have done 10 tasks, we stop development.
- [Developers] But the tasks may be different in size. This does not solve the problem of large releases.
- [I] Let's introduce a limit based on the duration of the release, not on the number of tasks. We will stop development if release takes too much time.
We decided that if the release lasts more than 48 hours, then we turn on the flasher and stop all teams working on the monolith business features. All teams working on the monolith should stop the development and focus on pushing the current release to prod or eliminate the reasons for the delayed release. When the release is stuck, it makes no sense to make new features, because they still come out soon. At this time, it is forbidden to write new code, even in separate branches.
We also entered “Stop the Line Board” on a simple flipchart. On it we write tasks that either help to push the current release, or help to avoid the reasons for its delay.
Of course, Stop The Line is not an easy decision, but this practice is an important step towards uninterrupted delivery and genuine DevOps.
Dodo IS history (technical preamble)
Dodo IS is written mainly on the .Net framework with UI on React / Redux, some places on jQuery and inlays of Angular. Still there are applications for iOS and Android on Swift and Kotlin.
The architecture of Dodo IS is a mixture of an inherited monolith and about 20 microservices. We develop new business features in individual microservices that are deployed either at each commit (continuous deployment) or upon request when the business needs it, even though every five minutes (continuous delivery).
But we still have a huge part of our business logic, implemented in a monolithic architecture. The monolith is the hardest to deploy. It takes time to build the entire system (the build artifact weighs about 1 GB), run unit and integration tests and perform a manual regression before each release. The release itself is also slow. Each country will deploy its own copy of the monolith, so we must deploy 12 copies for 12 countries.
Continuous Integration (CI) is a practice that helps developers keep the code running at all times, growing the product in small steps, integrating at least daily in one branch with the support of the CI build with a lot of autotests.
When several teams work on a single product and practice CI, the number of changes in a common branch grows rapidly. The more changes you accumulate, the more this change will contain hidden defects and potential problems. This is why teams prefer to deploy changes frequently, which leads to the practice of Continuous Delivery (CD) as the next logical step after CI.
Practice CD allows you to deploy code in the prod at any time. This practice is based on the deployment pipeline - a set of automatic or manual steps that check the product increment on the way to the product.
Our pipeline deployment looks like this:
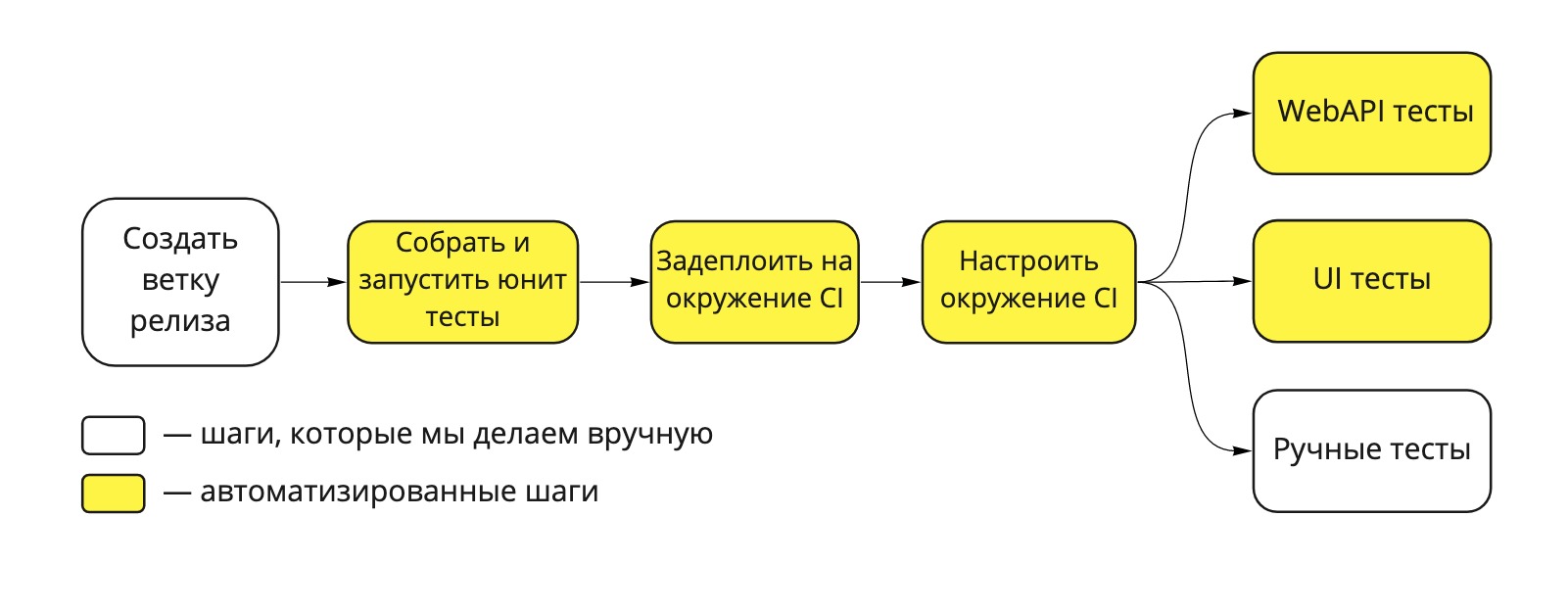
Fig. 1. Dodo IS Deployment Pipeline
The architecture of Dodo IS is a mixture of an inherited monolith and about 20 microservices. We develop new business features in individual microservices that are deployed either at each commit (continuous deployment) or upon request when the business needs it, even though every five minutes (continuous delivery).
But we still have a huge part of our business logic, implemented in a monolithic architecture. The monolith is the hardest to deploy. It takes time to build the entire system (the build artifact weighs about 1 GB), run unit and integration tests and perform a manual regression before each release. The release itself is also slow. Each country will deploy its own copy of the monolith, so we must deploy 12 copies for 12 countries.
Continuous Integration (CI) is a practice that helps developers keep the code running at all times, growing the product in small steps, integrating at least daily in one branch with the support of the CI build with a lot of autotests.
When several teams work on a single product and practice CI, the number of changes in a common branch grows rapidly. The more changes you accumulate, the more this change will contain hidden defects and potential problems. This is why teams prefer to deploy changes frequently, which leads to the practice of Continuous Delivery (CD) as the next logical step after CI.
Practice CD allows you to deploy code in the prod at any time. This practice is based on the deployment pipeline - a set of automatic or manual steps that check the product increment on the way to the product.
Our pipeline deployment looks like this:
Fig. 1. Dodo IS Deployment Pipeline
Let's release quickly: from problem to adapted practice. Stop the line
The pain of slow releases. Why are they so long? Analysis
There is a golden rule in Extreme Programming (XP): if something hurts, do it as often as possible. Our releases have always been a pain. We spent several days to deploy the test environment, restore the database, run the tests (usually several times), figure out why they fell, fix the bugs, and finally release.
The sprint lasts 2 weeks, and the release rolls for three days. In order to be released before Sprint Review on Friday, you need to start the release on Monday in a good way. This means that we are working on a sprint goal only 50% of the time. And if we could release every day, then the productive period of work would increase to 80-90%.
Our average release usually took two to three days. At first, six teams worked on the code in the common dev branch (and with the growth of the company, the number of teams increased to nine). Just before the release, we branched the release branch. While this branch is being tested and regressed, the teams continue development in the general dev branch. Before the release branch reaches the sales, the teams will write quite a lot of code.
The more changes in the increment, the greater the chance that changes made by different teams will affect each other, which means that the more carefully the increment must be tested, and the longer its release will take. This is a self-reinforcing cycle (see Fig. 2). The more changes in the release (“horse” release), the longer the regression time. The longer the regression time, the more time between releases and the more changes the team makes before the next release. We called it "horses give birth to horses." The following CLD diagram (Causal Loop Diagram) illustrates this dependency:
Fig. 2. CLD chart: long releases lead to even longer releases
Automate Recourse with the QA Command
Steps that make up the release
- Set up the environment. Restoring the database with the sale (675 GB), encrypt personal data and clean the RabbitMQ queues. Data encryption is a very time-consuming operation and takes about 1 hour.
- Run automatic tests. Some UI tests are unstable, so we have to run them several times until we pass. Correcting flashing tests requires a lot of attention and discipline.
- Manual acceptance tests. Some teams prefer to do final acceptance before the code goes to the prod. This may take several hours. If they find bugs, we give the teams two hours to fix them, otherwise they should roll back their changes.
- Depla on the prod. Since we have separate copies of Dodo IS for each country, the deployment process takes some time. After the completion of the deployment in the first country, we look for some time at the logs, look for errors, and then continue with the deployment in the other countries. The whole process usually takes about two hours, but sometimes it can take more, especially if you have to roll back the release.
At first we decided to get rid of manual regression testing, but the path to this was a long and difficult one. Two years ago, Dodo IS manual regression lasted a whole week. Then we had a whole team of manual testers who checked the same features in 10 countries week after week. Such work is not to be envied.
In June 2017, we formed the QA team. The main goal of the team was to automate the regression of the most important business operations: order taking and production of products. As soon as we had enough tests to start us to trust them, we completely abandoned manual testing. But this happened only 1.5 years after we started automating the regression. After that, we dismissed the QA team, and members of the QA team joined the development teams.
However, UI tests have significant drawbacks. Since they depend on real data in the database, this data must be configured. One test can spoil data for another test. The test may fall, not only because some logic is broken, but also because of a slow network or outdated data in the cache. We had to spend a lot of effort to get rid of the flashing tests and make them reliable and reproducible.
One step to Stop the line. #IReleaseEveryDay Initiative
We created a community of like-minded people #IReleaseEveryDay and brainstormed how to speed up the deployment pipeline. The first actions were:
- we significantly reduced the UI test suite by discarding repetitive and unnecessary tests. This reduced the testing time by several tens of minutes;
- We have significantly reduced the time to set up the environment due to the preliminary database recovery and data encryption. For example, now we create a backup of the database at night, and as soon as the release begins, we switch the test environment to the backup database in a few seconds.
Thanks to the above solutions, we have reduced the average release time, but it was still annoyingly long. It's time for system changes.
What if....
We introduced the rule that if the release lasts more than 48 hours, then we turn on the flasher and stop all teams working on the monolith's business features. All teams working on the monolith should stop development and focus on rolling out the current release before selling or eliminating the reasons for the delayed release.
When the release is stuck, it makes no sense to make new features, because they still come out soon. At this time, it is forbidden to write new code, even in separate branches. This principle is described in Martin Fowler's “Continuous Delivery” article: “In case of problems with display, your team should prioritize the solution of these problems above working on new features.”
Entourage flasher
During Stop the line, an orange flasher is turned on in the office. Anyone who comes to the third floor, where the developers of Dodo IS work, sees this visual signal. We decided not to drive our developers crazy with the sound of a siren and left only annoying blinking lights. So conceived. How can we feel comfortable when release is in trouble?
Fig. 3. Flashing light Stop the Line
Resistance teams and small sabotage
At first, Stop the Line liked all the teams, because it was fun. Everyone was happy as children and laid out photos of our flashers. But when it burns 3-4 days in a row, it becomes not funny. One day, one of the teams broke the rules and flooded the code into the dev branch during Stop the Line to save their sprint goal. It is easiest to break the rule if it prevents you from working. This is a quick and dirty way to make a business feature by ignoring a system problem.
As a Scrum Master, I could not tolerate violations of the rules, so I raised this issue in general retrospective. We had a difficult conversation. Most teams agreed that the rules apply to everyone. We agreed that each team must abide by the rules, even if it does not agree with them. And at the same time how to change the rules without waiting for the next retrospective.
What didn't work out as planned?
Initially, developers didn’t focus on solving system problems with deployment pipelint. When the release got stuck, instead of helping to eliminate the causes of the delay, they preferred to develop microservices that were not covered by the Stop the Line rule. Microservices are good, but the problems of the monolith will not solve themselves. In order to solve these problems, we introduced the Back The Line backlog.
Some solutions were quick fixes that hid problems rather than solved them. For example, many tests were repaired by increasing timeouts or adding relays. One such test was performed for 21 minutes. The test searched for the most recently created employee in the table without an index. Instead of correcting the logic of the request, the programmer added 3 retry. As a result, the slow test became even slower. When Stop The Line appeared the owner team, which focused on the problems of tests, over the next three sprints, they were able to speed up our tests by 2-3 times.
How did the behavior of the teams change after practicing Stop the Line?
Previously, only one team had problems with the release - the one that supported the release. The teams tried to get rid of this unpleasant duty as quickly as possible, instead of investing in long-term improvements. For example, if the tests on the test environment have fallen, they can be restarted locally and if the tests pass, continue the release. With the introduction of Stop The Line, teams have time to stabilize tests. We rewrote the test data preparation code, replaced some UI tests with API tests, removed unnecessary timeouts. Now almost all tests pass quickly and on any environment.
Previously, teams did not engage in technical debt systematically. Now we have the backlog of technical improvements that we analyze during Stop the Line. For example, we rewrote tests on .Net Core, which allowed us to run them in Docker. Running tests in Docker allowed us to use the Selenium Grid to parallelize tests and further reduce their execution time.
Previously, teams relied on the QA team for testing and the infrastructure team for deployment. Now there is no one to count on except themselves. The teams themselves test and release the code in Production. This is genuine, not fake DevOps.
Evolution of the Stop the line method
In the general sprint retrospective, we are reviewing the experiments. For several subsequent retrospectives, we made many changes to the Stop the Line rules, for example:
- Release channel All information about the current release is in a separate Slack channel. The channel has all the commands whose changes were included in the release. In this channel releaseman asks for help.
- Release log. The release manager logs his actions. This helps to find the reasons for the delayed release and to detect patterns.
- The rule of five minutes. Within five minutes after the announcement of the Stop the Line team representatives gather around the flasher.
- Baclog Stop the Line. On the wall there is a flip chart with Stop The Line backlog - a list of tasks that teams can perform during a line stop.
- Ignore the last Friday sprint. It is unfair to compare two releases, for example, the one that started on Monday and the other that started on Friday. The first team can spend two full days to support the release, and during the second release there will be many activities on Friday (Sprint Review, Team Retrospective, General Retrospective) and next Monday (General and Team Sprint Planning), so Friday’s team has less time for release support. Friday's release will be more likely to stop than on Monday. Therefore, we decided to exclude the last Friday sprint from the equation.
- The elimination of technical debt. After a couple of months, the teams decided that during the shutdown they could work on technical debt, and not just accelerate the deployment pipeline.
- Owner Stop the Line. One of the developers volunteered to become the owner of Stop The Line. He is deeply immersed in the causes of delayed releases and manages the Stop the Line backlog. When the line stops, the owner can involve any commands to work on the Stop the Line backlog elements.
- Post mortem. The owner of the Stop the Line postmortem after each stop.
Cost of loss
Due to Stop the Line, we didn’t fulfill several sprint goals. Business representatives were not too pleased with our progress and asked many questions at the Sprint Review. Observing the principle of transparency, we told what Stop the Line is and why we should wait a few more sprints. At each Sprint Review, we showed teams and stakeholders how much money we lost due to Stop the Line. The cost is calculated as the total salary of development teams during downtime.
• November - 2 106 000 p.
• December - 503 504 p.
• January - 1,219,767 p.
• February - 2,002,278 p.
• March - 0 p.
• April - 0 p.
• May - 361,138 p.
Such transparency creates healthy pressure and motivates teams to immediately solve problems of the deployment pipeline. Watching these figures, our teams understand that nothing is given for free, and each Stop the Line gets us a lot of money.
results
In fact, the practice of Stop the Line converts a self-amplifying cycle (Fig. 2) into two balancing cycles (Fig. 4). Stop the Line helps us focus on improving the deployment pipeline when it becomes too slow. In total for 4 sprints we:
- Stabilized 12 stable releases
- Reduced assembly time by 30%
- Stabilized UI and API tests. Now they are held on all environments and even locally.
- Get rid of the flashing tests
- Began to trust our tests
Fig. 4. CLD chart: Stop the Line balances release time
Findings from the Scrum Masters
Stop The Line is a vivid example of a strong solution invented by the development teams themselves. Scrum Master can not just take and bring teams a brilliant new practice. The practice will only work if the teams themselves invented it. This requires favorable conditions: an atmosphere of trust and a culture of experimentation.
Necessarily need the trust and support from the business, which is possible only with full transparency. Feedback, such as regular general retrospective with all team members, helps to come up with, introduce and change new practices.
Over time, the practice of Stop the Line should kill itself. The more often we stop the line, the more we invest in the deployment pipeline, the more stable and fast the release becomes, the fewer reasons for stopping. In the end, the line will never stop unless we decide to lower the threshold, for example, from 48 to 24 hours. But thanks to this practice, we have greatly improved the release procedure. The teams gained experience not only in development, but also in fast delivery of value to the prod. This is authentic DevOps.
What's next? I dont know. Perhaps we will soon give up this practice. The teams will decide. But it is obvious that we will continue to move towards Continuous Delivery and DevOps. One day my dream of releasing a monolith several times a day will surely come true.
Source: https://habr.com/ru/post/460191/
All Articles