How we built vulnerability management

Introduction to the issue
In our practice of working with different types of customers - from large international companies to small firms or even individual entrepreneurs - we see similar problems when trying to systematically work with vulnerabilities.
While the company is relatively small, it is enough to have one or more vulnerability scanners and one specialist who will periodically check the entire infrastructure, closing the most obvious or simple problems to fix.
In practice, when a company grows, the number of devices in the network grows, new information systems are used, including non-standard ones, there is not enough simple approach, because business wants to get answers to the questions:
')
- And with what vulnerabilities from the scanner report (there may be thousands and tens of thousands) need to work and why?
- How much does fixing these vulnerabilities cost?
- But can anyone really use them to launch an attack?
- And what do I risk if I do not fix anything?
- And how to make sure that everything is fixed?
Not every security specialist and system administrator will immediately have a clear answer to all these questions. Also, do not forget that in itself the management of vulnerabilities is a rather complicated process, and there are many factors that influence decision making:
- high risks of falling victim to a massive or targeted attack, if vulnerabilities are not eliminated in time (especially for the external perimeter);
- the high cost of eliminating for many vulnerabilities, especially if there is no ready-made patch or a large number of distributed devices are vulnerable (this is often a stop factor, and as a result, problems persist);
- if different people or even companies are responsible for different types of equipment, they do not always have the necessary qualifications to correctly assess the vulnerabilities found, the elimination process may be extremely time-consuming or not begin at all;
- if specialized equipment or SCADA systems are used, then the probability of missing the necessary patches from the manufacturer or the impossibility of updating the system in principle is high.
Because of all this, the vulnerability management process, implemented haphazardly, does not look effective and understandable in the eyes of the business.
Taking into account the needs of the business and understanding the specifics of working with information security vulnerabilities, we invented a separate service in Acribia.
What did we come up with?
We felt that the management of vulnerabilities should be approached systematically, as with any process. And this is precisely the process, and continuous and iterative, consisting of several stages.
Client connection
We take care of providing, configuring and supporting all the necessary tools. The client is only required to allocate a virtual or physical server (perhaps several if the network is large and distributed). We ourselves will install everything you need and configure it to work correctly.
Inventory and asset profiling
In short, the point is to identify all the devices on the network, divide them into groups of the same type (the level of detail of such a partition may vary depending on the size of the client’s network or the presence of a large number of specific devices), select the groups for which the service is provided, find out persons responsible for selected groups.

It is important not just to carry out this procedure one-time, but to highlight the patterns in order to at any time understand what is happening on the network, find new devices, find old devices that have moved, find new subtypes within groups, and so on. It is important. Inventory occurs constantly with a predetermined frequency. In our practice, we came to the conclusion that without an understanding of the structure of assets, effective management of vulnerabilities is not feasible.
We have been working on the asset profiling algorithm for a long time, each time adding new conditions or altering it altogether. We will not disclose all the technical details and cite the lines of code implementing our algorithm, we give only a general sequence of actions:
- The client provides an IP network plan.
- Using a network scanner, a fingerprint is formed for each device based on open network ports and OS.
- Profiles are combined by device and type (for example, Cisco Catalyst 2960 \ Network equipment).
- When a new device appears, the most similar profile is searched.
- If the accuracy is insufficient, then the type of device is specified at the client.
- A repeated network scan is periodically carried out to update the data and search for new devices and types.
In the absence of an accurate IP network plan (for example, using DHCP or the “human factor”), an online profiling option is possible based on several well-known IP addresses. Next, similar devices are identified within the type, and the profile is upgraded.
This approach allows us to determine the type of device with an accuracy of about 95%, but you always want more. We are open to new ideas, comments and comments. If there is something that we did not consider, we are ready to discuss in the comments.
Scan schedule
When we already have all the necessary information about the client's network, we make a schedule of scanning for vulnerabilities, taking into account the required frequency of checks for each type of device. Periodicity can be any - from 1 day to 1 year. Frequency on the one hand depends on how quickly and how often the client is ready to work with the vulnerabilities of this or that equipment, on the other hand it influences the price of the service.
For example, a plan might look like this:

It is important to note that we strongly recommend checking the outer perimeter of the network daily to minimize the risk of exploiting 1-day (just published) vulnerabilities. The same recommendation applies to public client Web resources.
Actually, scanning
A week before the scheduled start date of scanning groups of devices, we contact the person in charge of the group, inform him about the scan dates and send a full list of devices that we will check. At this stage, you can adjust (if necessary) the scope of the check. This is done in order to minimize the risks of incorrect recognition of devices on the network.
After the scan is completed, the person in charge is also informed. Those. interested parties are ALWAYS aware of what is happening.
We use several different scanners, including separate tools for finding vulnerabilities in web systems. So we get more information for analysis and can find more potential problems.
To optimize costs, we may not scan the entire group of devices of the same type, but restrict ourselves to a representative sample, for example, 30-50% of randomly selected devices from the group or 30-50% of devices from each geographically distributed office. When critical vulnerabilities are found on selected devices, a search is started for specific vulnerabilities already on all devices of the group. So we get the most complete coverage in less time.
It is important to note that there are separate vulnerabilities that are not detected by standard tools. When we start to scan a certain type of device, we check all public vulnerabilities and make sure that our scanners are able to find them. If we understand that the standard tool is not enough, then we look for individual vulnerabilities manually or develop our own tools for testing.
And most importantly, when information about a new dangerous vulnerability appears in the public space, we will not wait for a scheduled scan. All customers who are potentially affected by the vulnerability they have just found will be promptly notified of the problem, and we will perform an unscheduled check.
In general, a detailed description of the vulnerability search technology used by us is somewhat beyond the scope of this article, but you can familiarize yourself with it with the presentation that we did at the SOC-Forum in 2017.
Analysis of scan results
If you have ever run a vulnerability scanner on a corporate network of 100+ hosts, then you probably remember the very feeling that arises when you see a kilometer list of similar entries, from the contents of which, at first glance, little is clear. Without special knowledge it is difficult to adequately assess what is left as it is, and what needs to be corrected, and in what order to act.
We undertake this step, we look at the results, we choose really critical problems that can cause real damage to the client’s business.
We estimate such parameters as:
- availability of a vulnerable device / service for a potential intruder;
- the presence of a public exploit;
- operational complexity;
- potential business risk;
- Is it a false positive?
- difficulty of elimination;
- And so on.
After processing, the “tested and approved” vulnerabilities are published by us in the incident management system (we will talk about it separately), where the client’s staff can see them, ask questions, take them to work or reject them if they take risks.
If necessary, we also assign a consultation with the person responsible for vulnerable devices and tell in detail what is found, what it threatens and what options to minimize the risks are.
After the transfer of the vulnerability to work, the ball goes to the client, and we proceed to scanning the next group of devices.
But the process for the first group does not end there.
Vulnerability Control
In the system for each published vulnerability, you can put the status and deadline for elimination. We track status changes as well as the approaching deadline.
If the vulnerability is closed by the client, we see it and run a scan to make sure that the vulnerability is really no more. Because the scan runs only on one vulnerability, it does not take much time, the result can be obtained in a day for hundreds of thousands of hosts or even in seconds for a small group of devices.
If the vulnerability is really closed, we confirm it. If the vulnerability on all or part of the devices from the group is preserved, then we return for revision.
The cycle of work with each vulnerability ends only when we have confirmed that it is no longer on all vulnerable devices.
The general scheme looks something like this:

In the process of controlling the elimination of vulnerabilities, we can distinguish 2 auxiliary subprocesses: monitoring the timing and working with those responsible for closing the vulnerability on the part of the client.
Timing control
Again, for each vulnerability a deadline should be assigned to eliminate it. This parameter is set by the client independently, i.e. we do not dictate how fast the responsible employees of the client should work, but we monitor the achievement of goals. If the tasks are overdue, the client’s vulnerability management process holder is notified of this. Information about vulnerabilities that are closed on time or overdue is reflected in our periodic reports with the names of, so to speak, “honors” and “losers”. We also consider such an indicator as the average speed of eliminating vulnerabilities. So, the client collects the necessary information for scheduling, loading responsibles, as well as their achievements or omissions.
Work with responsible
Sometimes, for individual vulnerabilities, there is a need to assign several people in charge, transfer all or part of the work on a task to another person, or simply change the person in charge, because the first one failed, went on leave, went on sick leave, etc. All this allows our system to implement.
The picture below shows the scheme of the service in the context of a single vulnerability.
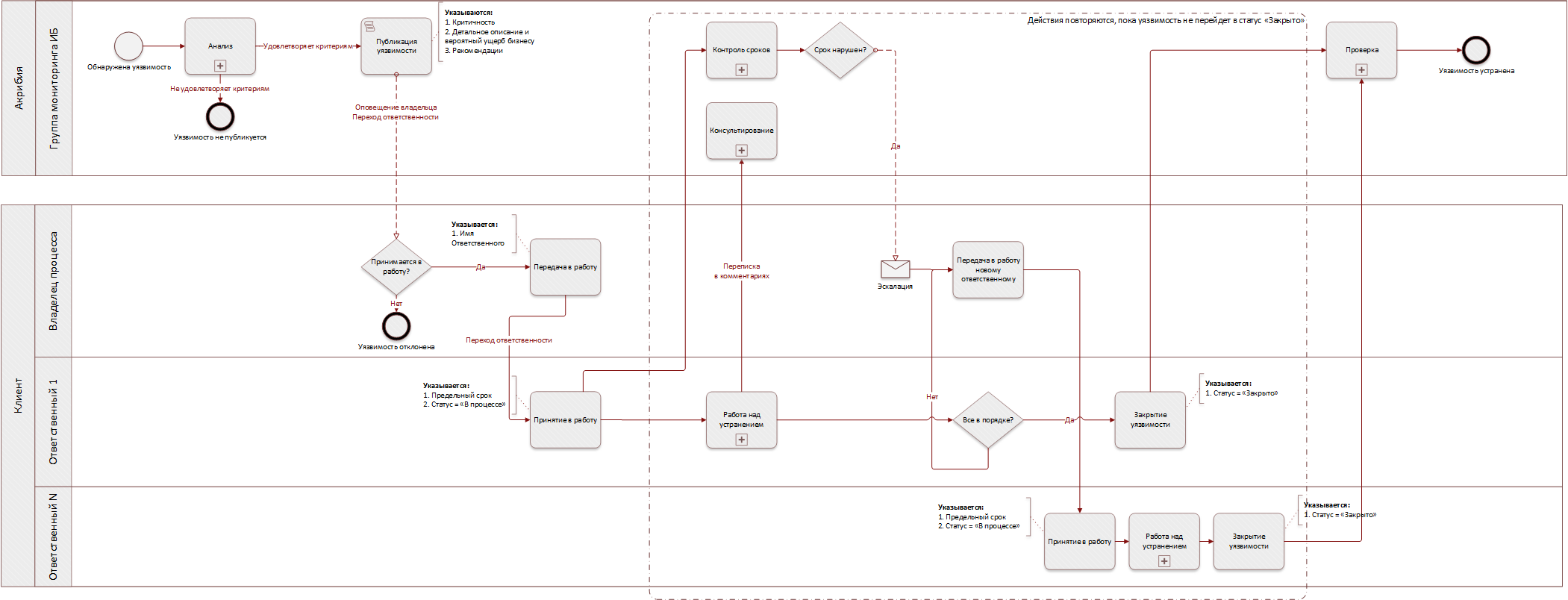
Efficiency
This is how we built the work process and see in our approach a number of advantages and opportunities that will help to work more effectively with vulnerabilities and at the same time solve the problems identified in the first part of the article:
- We undertake not only the task of launching scanners to search for vulnerabilities in the network, but also to analyze the results of their work. We eliminate too much and the output is the final list of vulnerabilities with which you can and should work.
- Making out this list and presenting it to the responsible specialists of the customer, we always write 2 things: a detailed description of the meaning of vulnerability and the negative impact on the business that it carries, and recommendations for eliminating or minimizing risks. Thus, you can always understand what will happen if you do nothing, and you can estimate the time and cost of implementing the recommended activities.
- If there are still doubts or arguments in favor of eliminating a certain vulnerability is not enough, we can additionally check the possibility of exploiting this vulnerability in real conditions or close to real ones. After such a “mini pentest”, it will be seen how possible and difficult the potential attacker will be to attack.
- Finally, when the work on fixing the vulnerability is completed, we always check it. Thus, you can eliminate the risk of errors or omissions.
And the client, in turn, receives in our opinion valuable opportunities and can:
- focus on really important groups of devices and monitor their status more often;
- focus on really dangerous vulnerabilities that can cause real damage;
- monitor the work on each vulnerability, track status changes and deadlines;
- receive individual advice on the closure of vulnerabilities;
- free up the time of your employees, which is necessary for launching and processing the results of scans, as well as for setting up and supporting all the necessary tools;
- Well, and as a bonus for the financial director - to transfer capital expenditures on the purchase of own instruments for scanning into operating rooms for the payment of expert services.
Interesting? In the services section on our website you can see the prices, as well as order testing services on special conditions.
Source: https://habr.com/ru/post/460048/
All Articles