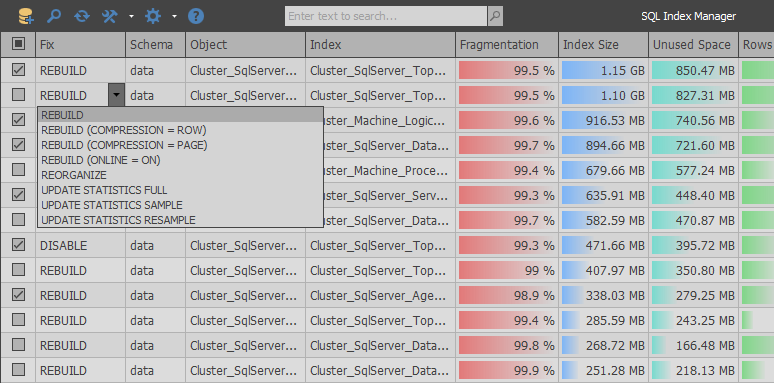
SQL Index Manager is a free tool for defragmenting and maintaining indexes.
For many years, working as a SQL Server DBA and doing server administration and performance optimization. In general, I wanted in my free time to do something useful for the Universe and colleagues in the workshop. So the result was a small open source index maintenance for SQL Server and Azure.
Sometimes people when working on their priorities may resemble a finger-type battery - a motivational charge lasts only one flash, and then everything. And until recently, I was no exception to this life observation. Often I was visited by ideas to create something of my own, but priorities changed and nothing came to the end.
')
My work in Devart, a Kharkov company that created software for developing and administering SQL Server, MySQL and Oracle databases, had a strong influence on my motivation and professional development.
Before coming to them, I had little idea about the specifics of creating my own product, but already in the process I gained a lot of knowledge about the internal structure of SQL Server. For more than a year, having been engaged in optimizing requests for metadata in their product lines, I gradually began to understand which functionality is more in demand in the market.
At a certain stage, the idea arose of making a new niche product, but due to circumstances, this idea did not take off. At that time, for a new project, there simply wasn’t enough free resources inside the company without affecting the core business.
Already when I was working at a new place and trying to do a project on my own, I had to constantly make some compromises. The original idea to make a large and stuffed with features product quickly came to naught and gradually transformed into a different direction - to break the planned functionality into separate mini-tools and implement them independently from each other.
As a result, SQL Index Manager was born, a free index maintenance tool for SQL Server and Azure. The main idea was to base commercial alternatives from RedGate and Devart companies and try to improve their functionality. Provide both beginners and advanced users the ability to conveniently analyze and maintain indexes.
In words, everything always sounds simple ... this one looked looked at a couple of motivating vidosikov, got up in the small stands and started making a cool product. But in practice, not everything is so rosy, since there are many pitfalls when working with the sys.dm_db_index_physical_stats system table function and in combination the only place where you can get up-to-date information about index fragmentation.
From the first days of development, there was a great opportunity to pave one's dreary way among the standard schemes and copy the already debugged logic of the competing applications, while adding a little ad-libbing. But after analyzing the requests for metadata, I wanted to do something more optimized, which, due to the bureaucracy of large companies, would never have appeared in their products.
When analyzing the RedGate SQL Index Manager (1.1.9.1378 - $ 155), you can see that the application uses a very simple approach: with one query, we get a list of user tables and views, and after the second query, we return a list of all indexes within the selected database.
Next, in the loop for each section of the index, a request is sent to determine its size and level of fragmentation. At the end of the scan, indexes that weigh less than the entry threshold are dropped on the client.
When analyzing the logic of this application, you can find many shortcomings. For example, if you find fault with trifles, before sending a request, no checks are made on whether the current section contains lines to exclude empty sections from scanning.
But the most acute problem is manifested in another aspect: the number of requests to the server will be approximately equal to the total number of rows from sys.partitions. Given the fact that real databases can contain tens of thousands of sections, this nuance can lead to a huge number of similar requests to the server. In a situation if the database is remote, then the scan time will be even longer due to the increased network delays in the execution of each, even the simplest query.
Unlike RedGate, a similar product developed by Devart - dbForge Index Manager for SQL Server (1.10.38 - $ 99) receives information in one large query and then displays everything on the client:
The main problem with the veil of similar queries in a competing product was eliminated, but the drawbacks of this implementation are that no additional parameters are passed to the sys.dm_db_index_physical_stats function, which can limit the scanning of obviously unnecessary indexes. In fact, this leads to obtaining information on all indices in the system and unnecessary disk loads at the scanning stage.
It is important to note that the data obtained from sys.dm_db_index_physical_stats is not permanently cached in the buffer pool, therefore minimizing physical reads when obtaining information about index fragmentation was one of the priority tasks during development.
After several experiments, it turned out to combine both approaches, dividing the scan into two parts. First, the size of the sections is determined by one large query, filtering in advance those that are not included in the filtering range:
Next, we get only those sections that contain data to avoid unnecessary reads from empty indexes.
Depending on the settings, only the types of indexes that the user wants to analyze are obtained (work with heaps, cluster / non-clustered indexes and columnistors is supported).
After this, a little magic begins: for all small indices we determine the level of fragmentation by repeatedly calling the function sys.dm_db_index_physical_stats with full indication of all parameters.
Next, we return all possible information to the client, filtering out the extra data:
After that, point queries determine the level of fragmentation for large indices.
Due to this approach, when generating queries, it turned out to solve problems with scanning performance that were encountered in competitors' applications. This could be completed, but in the process of development, new ideas gradually emerged that made it possible to expand the scope of application of their product.
Initially, support for working with WAIT_AT_LOW_PRIORITY was implemented, then it became possible to use DATA_COMPRESSION and FILL_FACTOR for rebuild indexes.

The application has slightly overgrown with previously unplanned functionality like servicing columns:
Or the ability to create nonclustered indexes based on information from dm_db_missing_index:
After six months of the active development phase, I am glad that the plans do not end there, because I want to further develop this product. The next step is to add functionality for finding duplicate or unused indexes, as well as implement full support for maintaining statistics within SQL Server.
Based on the fact that there are a lot of paid solutions on the market now, I want to believe that due to free positioning, more optimized metadata descraib and the availability of various useful trifles for someone, this product will definitely become useful in everyday tasks.
The current version of the application can be downloaded on GitHub . Sources are in the same place.
Idea
Sometimes people when working on their priorities may resemble a finger-type battery - a motivational charge lasts only one flash, and then everything. And until recently, I was no exception to this life observation. Often I was visited by ideas to create something of my own, but priorities changed and nothing came to the end.
')
My work in Devart, a Kharkov company that created software for developing and administering SQL Server, MySQL and Oracle databases, had a strong influence on my motivation and professional development.
Before coming to them, I had little idea about the specifics of creating my own product, but already in the process I gained a lot of knowledge about the internal structure of SQL Server. For more than a year, having been engaged in optimizing requests for metadata in their product lines, I gradually began to understand which functionality is more in demand in the market.
At a certain stage, the idea arose of making a new niche product, but due to circumstances, this idea did not take off. At that time, for a new project, there simply wasn’t enough free resources inside the company without affecting the core business.
Already when I was working at a new place and trying to do a project on my own, I had to constantly make some compromises. The original idea to make a large and stuffed with features product quickly came to naught and gradually transformed into a different direction - to break the planned functionality into separate mini-tools and implement them independently from each other.
As a result, SQL Index Manager was born, a free index maintenance tool for SQL Server and Azure. The main idea was to base commercial alternatives from RedGate and Devart companies and try to improve their functionality. Provide both beginners and advanced users the ability to conveniently analyze and maintain indexes.
Implementation
In words, everything always sounds simple ... this one looked looked at a couple of motivating vidosikov, got up in the small stands and started making a cool product. But in practice, not everything is so rosy, since there are many pitfalls when working with the sys.dm_db_index_physical_stats system table function and in combination the only place where you can get up-to-date information about index fragmentation.
From the first days of development, there was a great opportunity to pave one's dreary way among the standard schemes and copy the already debugged logic of the competing applications, while adding a little ad-libbing. But after analyzing the requests for metadata, I wanted to do something more optimized, which, due to the bureaucracy of large companies, would never have appeared in their products.
When analyzing the RedGate SQL Index Manager (1.1.9.1378 - $ 155), you can see that the application uses a very simple approach: with one query, we get a list of user tables and views, and after the second query, we return a list of all indexes within the selected database.
SELECT objects.name AS tableOrViewName , objects.object_id AS tableOrViewId , schemas.name AS schemaName , CAST(ISNULL(lobs.NumLobs, 0) AS BIT) AS ContainsLobs , o.is_memory_optimized FROM sys.objects AS objects JOIN sys.schemas AS schemas ON schemas.schema_id = objects.schema_id LEFT JOIN ( SELECT object_id , COUNT(*) AS NumLobs FROM sys.columns WITH (NOLOCK) WHERE system_type_id IN (34, 35, 99) OR max_length = -1 GROUP BY object_id ) AS lobs ON objects.object_id = lobs.object_id LEFT JOIN sys.tables AS o ON o.object_id = objects.object_id WHERE objects.type = 'U' OR objects.type = 'V' SELECT i.object_id AS tableOrViewId , i.name AS indexName , i.index_id AS indexId , i.allow_page_locks AS allowPageLocks , p.partition_number AS partitionNumber , CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex FROM sys.indexes AS i JOIN sys.partitions AS p ON p.index_id = i.index_id AND p.object_id = i.object_id JOIN ( SELECT COUNT(*) AS numPartitions , object_id , index_id FROM sys.partitions GROUP BY object_id , index_id ) AS c ON c.index_id = i.index_id AND c.object_id = i.object_id WHERE i.index_id > 0 -- ignore heaps AND i.is_disabled = 0 AND i.is_hypothetical = 0 Next, in the loop for each section of the index, a request is sent to determine its size and level of fragmentation. At the end of the scan, indexes that weigh less than the entry threshold are dropped on the client.
EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 1, @partitionNr = 1 EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 2, @partitionNr = 1 EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 3, @partitionNr = 1 When analyzing the logic of this application, you can find many shortcomings. For example, if you find fault with trifles, before sending a request, no checks are made on whether the current section contains lines to exclude empty sections from scanning.
But the most acute problem is manifested in another aspect: the number of requests to the server will be approximately equal to the total number of rows from sys.partitions. Given the fact that real databases can contain tens of thousands of sections, this nuance can lead to a huge number of similar requests to the server. In a situation if the database is remote, then the scan time will be even longer due to the increased network delays in the execution of each, even the simplest query.
Unlike RedGate, a similar product developed by Devart - dbForge Index Manager for SQL Server (1.10.38 - $ 99) receives information in one large query and then displays everything on the client:
SELECT SCHEMA_NAME(o.[schema_id]) AS [schema_name] , o.name AS parent_name , o.[type] AS parent_type , i.name , i.type_desc , s.avg_fragmentation_in_percent , s.page_count , p.partition_number , p.[rows] , ISNULL(lob.is_lob_legacy, 0) AS is_lob_legacy , ISNULL(lob.is_lob, 0) AS is_lob , CASE WHEN ds.[type] = 'PS' THEN 1 ELSE 0 END AS is_partitioned FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s JOIN sys.partitions p ON s.[object_id] = p.[object_id] AND s.index_id = p.index_id AND s.partition_number = p.partition_number JOIN sys.indexes i ON i.[object_id] = s.[object_id] AND i.index_id = s.index_id LEFT JOIN ( SELECT c.[object_id] , index_id = ISNULL(i.index_id, 1) , is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END) , is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END) FROM sys.columns c LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id AND i.index_id > 0 WHERE c.system_type_id IN (34, 35, 99) OR c.max_length = -1 GROUP BY c.[object_id], i.index_id ) lob ON lob.[object_id] = i.[object_id] AND lob.index_id = i.index_id JOIN sys.objects o ON o.[object_id] = i.[object_id] JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id WHERE i.[type] IN (1, 2) AND i.is_disabled = 0 AND i.is_hypothetical = 0 AND s.index_level = 0 AND s.alloc_unit_type_desc = 'IN_ROW_DATA' AND o.[type] IN ('U', 'V') The main problem with the veil of similar queries in a competing product was eliminated, but the drawbacks of this implementation are that no additional parameters are passed to the sys.dm_db_index_physical_stats function, which can limit the scanning of obviously unnecessary indexes. In fact, this leads to obtaining information on all indices in the system and unnecessary disk loads at the scanning stage.
It is important to note that the data obtained from sys.dm_db_index_physical_stats is not permanently cached in the buffer pool, therefore minimizing physical reads when obtaining information about index fragmentation was one of the priority tasks during development.
After several experiments, it turned out to combine both approaches, dividing the scan into two parts. First, the size of the sections is determined by one large query, filtering in advance those that are not included in the filtering range:
INSERT INTO #AllocationUnits (ContainerID, ReservedPages, UsedPages) SELECT [container_id] , SUM([total_pages]) , SUM([used_pages]) FROM sys.allocation_units WITH(NOLOCK) GROUP BY [container_id] HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize Next, we get only those sections that contain data to avoid unnecessary reads from empty indexes.
SELECT [object_id] , [index_id] , [partition_id] , [partition_number] , [rows] , [data_compression] INTO #Partitions FROM sys.partitions WITH(NOLOCK) WHERE [object_id] > 255 AND [rows] > 0 AND [object_id] NOT IN (SELECT * FROM #ExcludeList) Depending on the settings, only the types of indexes that the user wants to analyze are obtained (work with heaps, cluster / non-clustered indexes and columnistors is supported).
INSERT INTO #Indexes SELECT ObjectID = i.[object_id] , IndexID = i.index_id , IndexName = i.[name] , PagesCount = a.ReservedPages , UnusedPagesCount = a.ReservedPages - a.UsedPages , PartitionNumber = p.[partition_number] , RowsCount = ISNULL(p.[rows], 0) , IndexType = i.[type] , IsAllowPageLocks = i.[allow_page_locks] , DataSpaceID = i.[data_space_id] , DataCompression = p.[data_compression] , IsUnique = i.[is_unique] , IsPK = i.[is_primary_key] , FillFactorValue = i.[fill_factor] , IsFiltered = i.[has_filter] FROM #AllocationUnits a JOIN #Partitions p ON a.ContainerID = p.[partition_id] JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id] AND p.[index_id] = i.[index_id] WHERE i.[type] IN (0, 1, 2, 5, 6) AND i.[object_id] > 255 After this, a little magic begins: for all small indices we determine the level of fragmentation by repeatedly calling the function sys.dm_db_index_physical_stats with full indication of all parameters.
INSERT INTO #Fragmentation (ObjectID, IndexID, PartitionNumber, Fragmentation) SELECT i.ObjectID , i.IndexID , i.PartitionNumber , r.[avg_fragmentation_in_percent] FROM #Indexes i CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r WHERE i.PagesCount <= @PreDescribeSize AND r.[index_level] = 0 AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA' AND i.IndexType IN (0, 1, 2) Next, we return all possible information to the client, filtering out the extra data:
SELECT i.ObjectID , i.IndexID , i.IndexName , ObjectName = o.[name] , SchemaName = s.[name] , i.PagesCount , i.UnusedPagesCount , i.PartitionNumber , i.RowsCount , i.IndexType , i.IsAllowPageLocks , u.TotalWrites , u.TotalReads , u.TotalSeeks , u.TotalScans , u.TotalLookups , u.LastUsage , i.DataCompression , f.Fragmentation , IndexStats = STATS_DATE(i.ObjectID, i.IndexID) , IsLobLegacy = ISNULL(lob.IsLobLegacy, 0) , IsLob = ISNULL(lob.IsLob, 0) , IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT) , IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT) , FileGroupName = fg.[name] , i.IsUnique , i.IsPK , i.FillFactorValue , i.IsFiltered , a.IndexColumns , a.IncludedColumns FROM #Indexes i JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id] LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID AND a.IndexID = i.IndexID LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID AND f.IndexID = i.IndexID AND f.PartitionNumber = i.PartitionNumber LEFT JOIN ( SELECT ObjectID = [object_id] , IndexID = [index_id] , TotalWrites = NULLIF([user_updates], 0) , TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0) , TotalSeeks = NULLIF([user_seeks], 0) , TotalScans = NULLIF([user_scans], 0) , TotalLookups = NULLIF([user_lookups], 0) , LastUsage = ( SELECT MAX(dt) FROM ( VALUES ([last_user_seek]) , ([last_user_scan]) , ([last_user_lookup]) , ([last_user_update]) ) t(dt) ) FROM sys.dm_db_index_usage_stats WITH(NOLOCK) WHERE [database_id] = @DBID ) u ON i.ObjectID = u.ObjectID AND i.IndexID = u.IndexID LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID AND lob.IndexID = i.IndexID LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id] AND i.PartitionNumber = dds.[destination_id] JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id] WHERE o.[type] IN ('V', 'U') AND ( f.Fragmentation >= @Fragmentation OR i.PagesCount > @PreDescribeSize OR i.IndexType IN (5, 6) ) After that, point queries determine the level of fragmentation for large indices.
EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'') WHERE [index_level] = 0 AND [alloc_unit_type_desc] = ''IN_ROW_DATA''' , N'@ObjectID int,@IndexID int,@PartitionNumber int' , @ObjectId = 1044198770, @IndexId = 1, @PartitionNumber = 1 EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'') WHERE [index_level] = 0 AND [alloc_unit_type_desc] = ''IN_ROW_DATA''' , N'@ObjectID int,@IndexID int,@PartitionNumber int' , @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1 Due to this approach, when generating queries, it turned out to solve problems with scanning performance that were encountered in competitors' applications. This could be completed, but in the process of development, new ideas gradually emerged that made it possible to expand the scope of application of their product.
Initially, support for working with WAIT_AT_LOW_PRIORITY was implemented, then it became possible to use DATA_COMPRESSION and FILL_FACTOR for rebuild indexes.
The application has slightly overgrown with previously unplanned functionality like servicing columns:
SELECT * FROM ( SELECT IndexID = [index_id] , PartitionNumber = [partition_number] , PagesCount = SUM([size_in_bytes]) / 8192 , UnusedPagesCount = ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) / 8192 , Fragmentation = CAST(ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) * 100. / SUM([size_in_bytes]) AS FLOAT) FROM sys.fn_column_store_row_groups(@ObjectID) GROUP BY [index_id] , [partition_number] ) t WHERE Fragmentation >= @Fragmentation AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize Or the ability to create nonclustered indexes based on information from dm_db_missing_index:
SELECT ObjectID = d.[object_id] , UserImpact = gs.[avg_user_impact] , TotalReads = gs.[user_seeks] + gs.[user_scans] , TotalSeeks = gs.[user_seeks] , TotalScans = gs.[user_scans] , LastUsage = ISNULL(gs.[last_user_scan], gs.[last_user_seek]) , IndexColumns = CASE WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NOT NULL THEN d.[equality_columns] + ', ' + d.[inequality_columns] WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NULL THEN d.[equality_columns] ELSE d.[inequality_columns] END , IncludedColumns = d.[included_columns] FROM sys.dm_db_missing_index_groups g WITH(NOLOCK) JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle] JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle] WHERE d.[database_id] = DB_ID() Results
After six months of the active development phase, I am glad that the plans do not end there, because I want to further develop this product. The next step is to add functionality for finding duplicate or unused indexes, as well as implement full support for maintaining statistics within SQL Server.
Based on the fact that there are a lot of paid solutions on the market now, I want to believe that due to free positioning, more optimized metadata descraib and the availability of various useful trifles for someone, this product will definitely become useful in everyday tasks.
The current version of the application can be downloaded on GitHub . Sources are in the same place.
Source: https://habr.com/ru/post/459914/
All Articles