An example of a simple neural network, as a result of figuring out what's what
Neural networks is a topic that arouses great interest and desire to understand it. But, unfortunately, it is far from everyone. When you see volumes of incomprehensible literature, you lose the desire to study, but you still want to be aware of what is happening.
In the end, as it seemed to me, there is no better way to figure out than to simply take and create your own small project.
You can read the lyric background, expanding the text, or you can skip this and go directly to the description of the neural network.
Specifications:
The main advantage of my library is to create a network with one line of code.
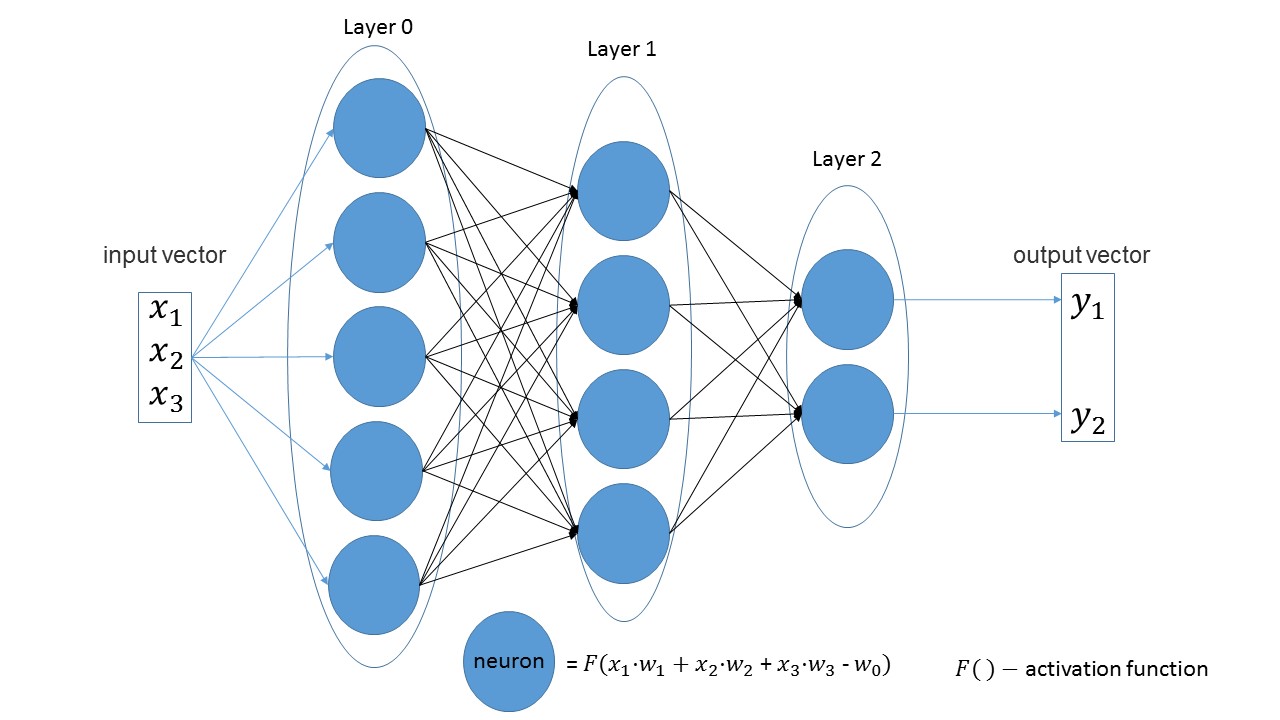
It is easy to see that in linear layers the number of neurons in one layer is equal to the number of input parameters in the next layer. Another obvious statement is that the number of neurons in the last layer equals the number of output values of the network.
Let's create a network that receives three parameters as input, which has three layers with 5, 4 and 2 neurons.
If you look at the picture, you can just see: first 3 input parameters, then a layer with 5 neurons, then a layer with 4 neurons and, finally, the last layer with 2 neurons.
By default, all activation functions are sigmoid (I like them more).
If desired, on any layer can be changed to another function.
Easy to create learning sample. The first vector is the input data, the second vector is the target data.
Network training:
Enable optimization:
And a method to simply get the value of the network:
It has already entered into the unspoken tradition of testing any network based on MNIST . And I did not become an exception. All code with comments can be viewed here .
What happened:
In about 10 minutes (only CPU acceleration), you can get an accuracy of 75%. With the optimization of Adam in 5 minutes you can get an accuracy of 88% percent. In the end, I managed to achieve an accuracy of 97%.
For a small project completeness, this article was lacking. If at least ten people are interested and play around, then there will already be a victory. Welcome to my github .
PS: If you need to create something of your own to figure it out, do not be afraid and create.
In the end, as it seemed to me, there is no better way to figure out than to simply take and create your own small project.
You can read the lyric background, expanding the text, or you can skip this and go directly to the description of the neural network.
What is the point of doing your project.
Pros:
')
Minuses:
')
- You better understand how neurons work
- You better understand how to work with existing libraries.
- In parallel, you are learning something new.
- Tickling your Ego by creating something of your own
Minuses:
- You create a bicycle, and most likely worse than the existing ones.
- No one cares about your project.
Select language.
At the time of choosing the language, I more or less knew C ++, and was familiar with the basics of Python. It is easier to work with neurons in Python, but C ++ knew better and there is no simpler parallelization of computations than OpenMP. Therefore, I chose C ++, and the API under Python, in order not to bother, will create a swig that runs on Windows and Linux. ( An example of how to make a library for Python from C code)
OpenMP and GPU acceleration.
Currently, Visual Studio has OpenMP version 2.0., Which has only CPU acceleration. However, since version 3.0, OpenMP also supports GPU acceleration, and the directive syntax has not become more complicated. It remains only to wait until OpenMP 3.0 will be supported by all compilers. For now, for simplicity, only CPU.
My first rake.
In calculating the value of a neuron there is the following point: before we calculate the activation function, we need to add the weights multiplication by the input data. As taught to do this at the university: before summing up a large vector of small numbers, it must be sorted in ascending order. So here. In neural networks, except for slowing down the program N times, this does not do anything. But I realized this only when I had already tested my network on MNIST.
Posting a project on GitHub.
I'm not the first to upload my creation on GitHub. But in most cases, clicking on the link, you see only a bunch of code with an inscription in README.md "This is my neural network, see and learn . " To be better than others at least in this, more or less described the README.md and filled in the Wiki . The message is simple - fill in the Wiki. An interesting observation: if the title on the Wiki on GitHub is written in Russian, then the anchor for this title does not work.
License.
When you create your own small project, a license is again a way to tickle your Ego. Here is an interesting article on the subject of what a license is needed for. I opted for APACHE 2.0 .
Network description.
Specifications:
| Title | FoxNN (Fox-Neural-Network ) |
| operating system | Windows linux |
| Languages | C ++, Python |
| Acceleration | CPU (GPU in the plans) |
| External dependencies | No (pure C ++, STL, OpenMP) |
| Compilation flags | -std = c ++ 14 -fopenmp |
| Layers | linear (convolutional in the plans) |
| Optimization | Adam, Nesterov |
| Random change of scales | there is |
| Wikipedia (instruction) | there is |
The main advantage of my library is to create a network with one line of code.
It is easy to see that in linear layers the number of neurons in one layer is equal to the number of input parameters in the next layer. Another obvious statement is that the number of neurons in the last layer equals the number of output values of the network.
Let's create a network that receives three parameters as input, which has three layers with 5, 4 and 2 neurons.
import foxnn nn = foxnn.neural_network([3, 5, 4, 2]) If you look at the picture, you can just see: first 3 input parameters, then a layer with 5 neurons, then a layer with 4 neurons and, finally, the last layer with 2 neurons.
By default, all activation functions are sigmoid (I like them more).
If desired, on any layer can be changed to another function.
In the presence of the most popular activation functions.
nn.get_layer(0).set_activation_function("gaussian") Easy to create learning sample. The first vector is the input data, the second vector is the target data.
data = foxnn.train_data() data.add_data([1, 2, 3], [1, 0]) # , Network training:
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98) Enable optimization:
nn.settings.set_mode("Adam") And a method to simply get the value of the network:
nn.get_out([0, 1, 0.1]) A little about the name of the method.
Separately, get means how to get , and out - output . I wanted to get the name " give the output value ", and got it. Only later noticed what happened vymataytes . But so fun, and decided to leave.
Testing
It has already entered into the unspoken tradition of testing any network based on MNIST . And I did not become an exception. All code with comments can be viewed here .
Creates a training sample:
from mnist import MNIST import foxnn mndata = MNIST('C:download/') mndata.gz = True imagesTrain, labelsTrain = mndata.load_training() def get_data(images, labels): train_data = foxnn.train_data() for im, lb in zip(images, labels): data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # len(data_y) == 10 data_y[lb] = 1 data_x = im for j in range(len(data_x)): # (-1, 1) data_x[j] = ((float(data_x[j]) / 255.0) - 0.5) * 2.0 train_data.add_data(data_x, data_y) # return train_data train_data = get_data(imagesTrain, labelsTrain) Create a network: three layers, input 784 parameters, and 10 output:
nn = foxnn.neural_network([784, 512, 512, 10]) nn.settings.n_threads = 7 # 7 nn.settings.set_mode("Adam") # We teach:
nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98) What happened:
In about 10 minutes (only CPU acceleration), you can get an accuracy of 75%. With the optimization of Adam in 5 minutes you can get an accuracy of 88% percent. In the end, I managed to achieve an accuracy of 97%.
The main disadvantages (already in the plans for revision):
- In Python, errors are not yet stretched, i.e. in python, the error will not be intercepted and the program will simply end with an error.
- So far, training is indicated in iterations, and not in epochs, as is customary in other networks.
- No GPU acceleration
- There are no other types of layers yet.
- It is necessary to fill in the project on PyPi.
For a small project completeness, this article was lacking. If at least ten people are interested and play around, then there will already be a victory. Welcome to my github .
PS: If you need to create something of your own to figure it out, do not be afraid and create.
Source: https://habr.com/ru/post/459822/
All Articles