Read between notes: data transfer system inside music

Express what words cannot convey; feel a variety of emotions, intertwined in a hurricane of feelings; take off from the earth, the sky and even the universe itself, having gone on a journey where there are no maps, no roads, no signs; invent, tell and relive the whole story, which will always remain unique and unique. All this allows us to make music - an art that has been around for thousands of years and soothes our hearts and ears.
However, music, or rather musical works, can serve not only for aesthetic pleasure, but also for transmitting information encoded in them, intended for any device and invisible to the listener. Today we will get acquainted with a very unusual study, in which graduate students from Zurich Swiss Higher Technical School were able to implant certain data into musical works unnoticed by the human ear, due to which the music itself becomes a data transmission channel. How exactly did they implement their technology, are the melodies very different from and without embedded data, and what did the practical tests show? About this we learn from the report of the researchers. Go.
')
The basis of the study
Researchers call their technology acoustic data transmission technology. When the speaker plays the modified melody, the person perceives it as normal, but, for example, the smartphone can read the encoded information between the lines, more precisely between the notes, if I may say so. The most important aspect in the implementation of this data transfer method, scientists (the fact that these guys are still graduate students does not prevent them from being scientists) call the speed and reliability of transmission while maintaining the level of these parameters, regardless of the selected audio file. The psychoacoustics, which studies the psychological and physiological aspects of human perception of sounds, helps to cope with this task.
The core of acoustic data transmission can be called OFDM (orthogonal frequency division multiplexing), which, along with the adaptation of subcarriers to the original music over time, allowed the maximum use of the transmitted frequency spectrum for information transmission. Due to this, it was possible to achieve a transmission speed of 412 bps at a distance of up to 24 meters (error rate <10%). Practical experiments with the participation of 40 volunteers confirmed the fact that it is almost impossible to hear the difference between the original melody and the one into which the information was introduced.
Where can such technology be applied in practice? The researchers have their own answer: almost all modern smartphones, laptops and other handheld devices are equipped with microphones, and in many public places (cafes, restaurants, shopping centers, etc.) there are speakers with background music. In this background melody, you can embed, for example, data for connecting to a Wi-Fi network without the need for additional actions.
The general features of acoustic data transmission have become clear to us, now we turn to a detailed study of the structure of this system.
System description
The introduction of data into the melody occurs due to frequency masking. In time intervals, the masking frequencies are identified, and OFDM subcarriers close to these masking elements are filled with data.
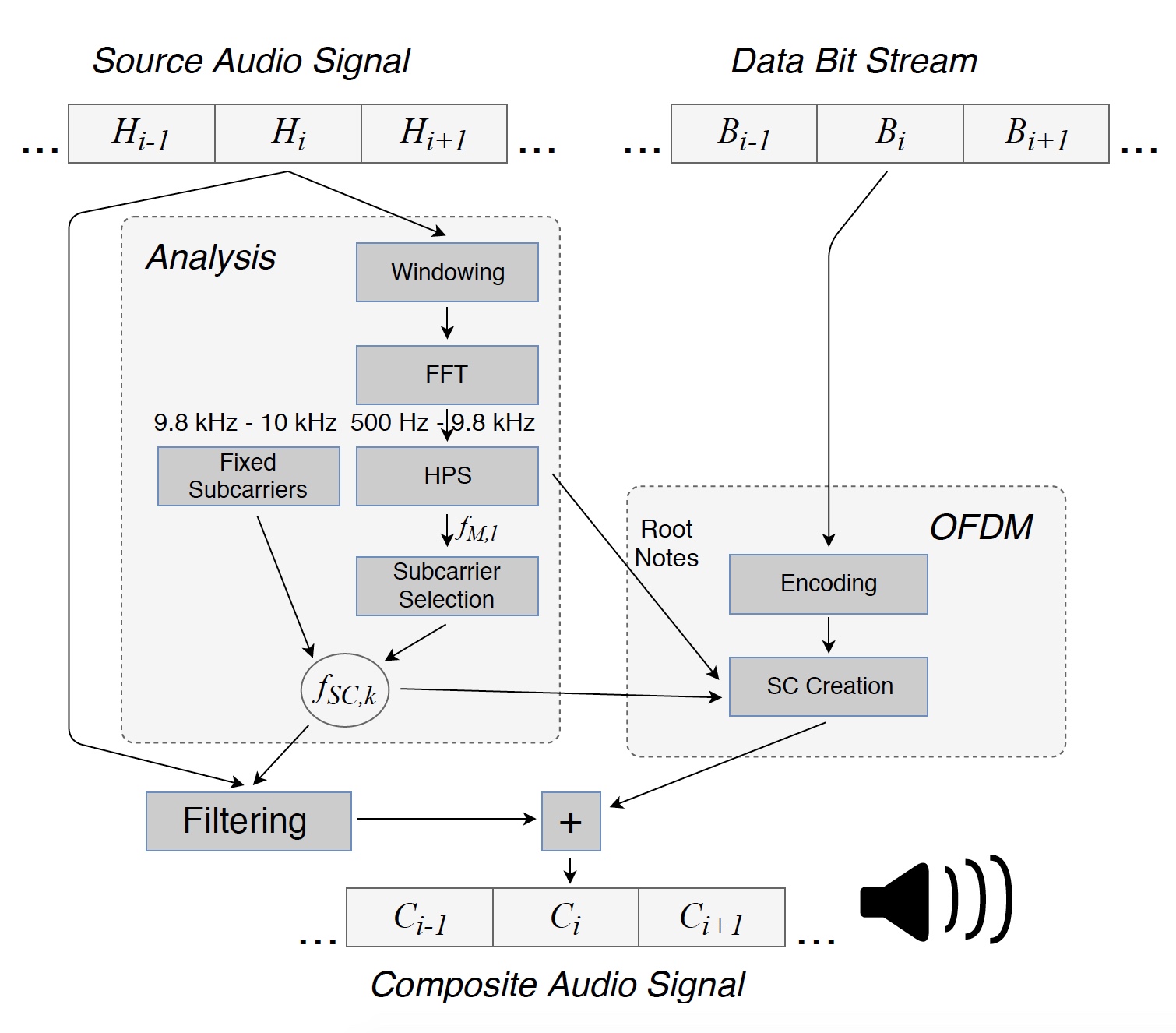
Image number 1: convert the original file into a composite signal (melody + data) transmitted through the speakers.
To begin with, the original audio signal is divided into consecutive segments for analysis. Each such segment (H i ) of L = 8820 samples, equal to 200 ms, is multiplied by the window * to minimize the boundary effects.
Window * is a weight function used to control the effects caused by the presence of side lobes in the spectral estimates.Further, the dominant frequencies of the original signal were detected in the range from 500 Hz to 9.8 kHz, which made it possible to obtain the masking frequencies f M, l for this segment. In addition, data was transmitted in a small range from 9.8 to 10 kHz to establish the location of the subcarriers in the receiver. The upper limit of the frequency range used was set to 10 kHz due to the low sensitivity of the smartphone’s microphones at high frequencies.
The masking frequencies were determined for each analyzed segment individually. Through the HPS method (harmonic spectrum of products), three dominant frequencies were established, after which they were rounded to the nearest notes of a harmonic chromatic scale. This is how the basic notes f F, i = 1 ... 3, were found, lying between the keys C0 (16.35 Hz) and B0 (30.87 Hz). Assuming that the main notes are too low for use in data transmission, in the range of 500 Hz ... 9.8 kHz their higher octaves were calculated 2 k f F, i . Many of these frequencies (f O, l 1 ) were more pronounced due to the nature of HPS.
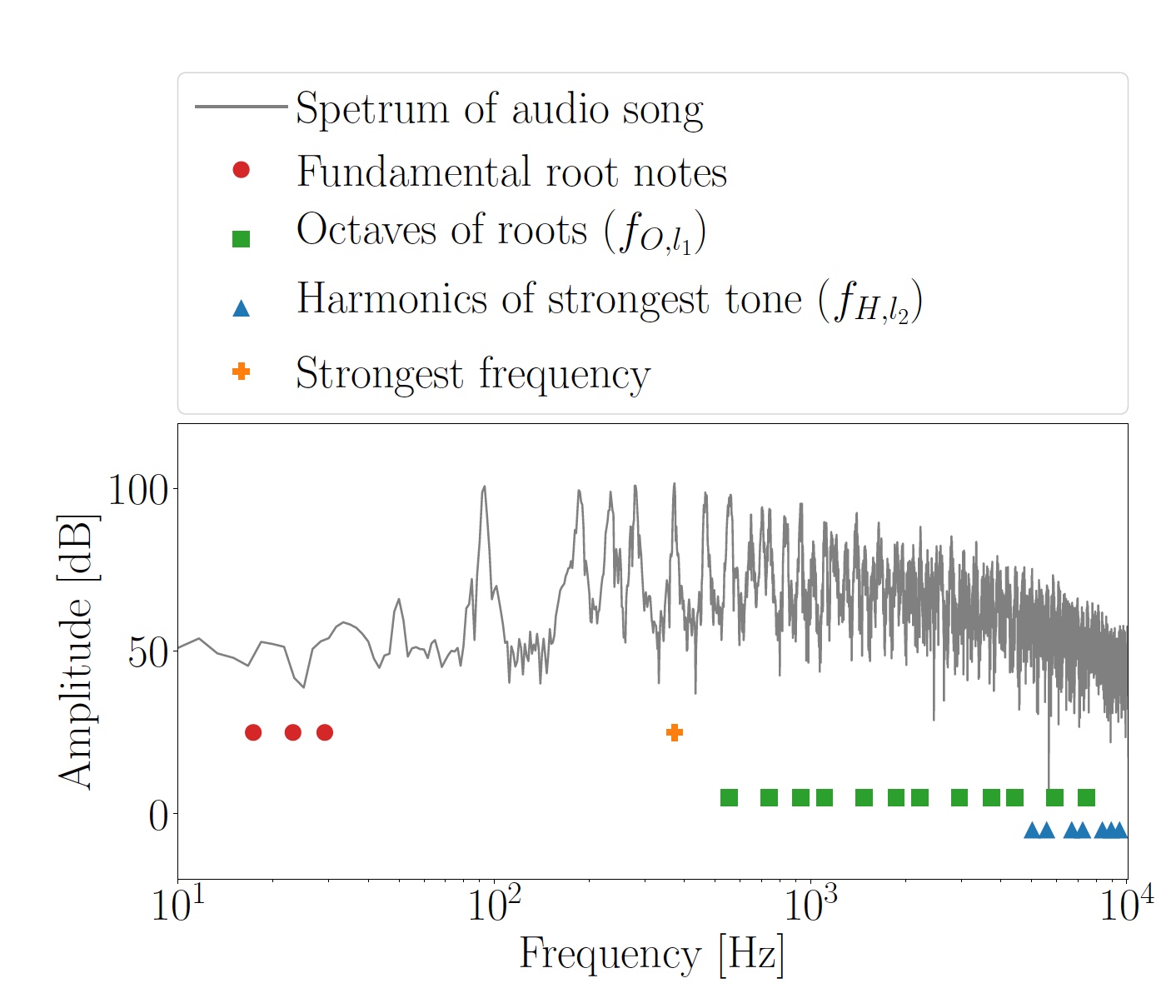
Image No. 2: the calculated octaves f O, l 1 for the fundamental notes and harmonics f H, l 2 of the strongest tone.
The set of octaves and harmonics as a result was used as masking frequencies, on the basis of which OFDM frequencies f SC, k were obtained. Two subcarriers were inserted below and above each masking frequency.
Next, the spectrum of the audio segment H i was filtered at subcarrier frequencies f SC, k . After that, based on the information bits, an OFDM symbol was created in Bi, due to which the composite segment C i could be transmitted through the speaker. The sizes and phases of the subcarriers must be selected in such a way that the receiver can retrieve the transmitted data while the listener does not notice any changes in the melody.
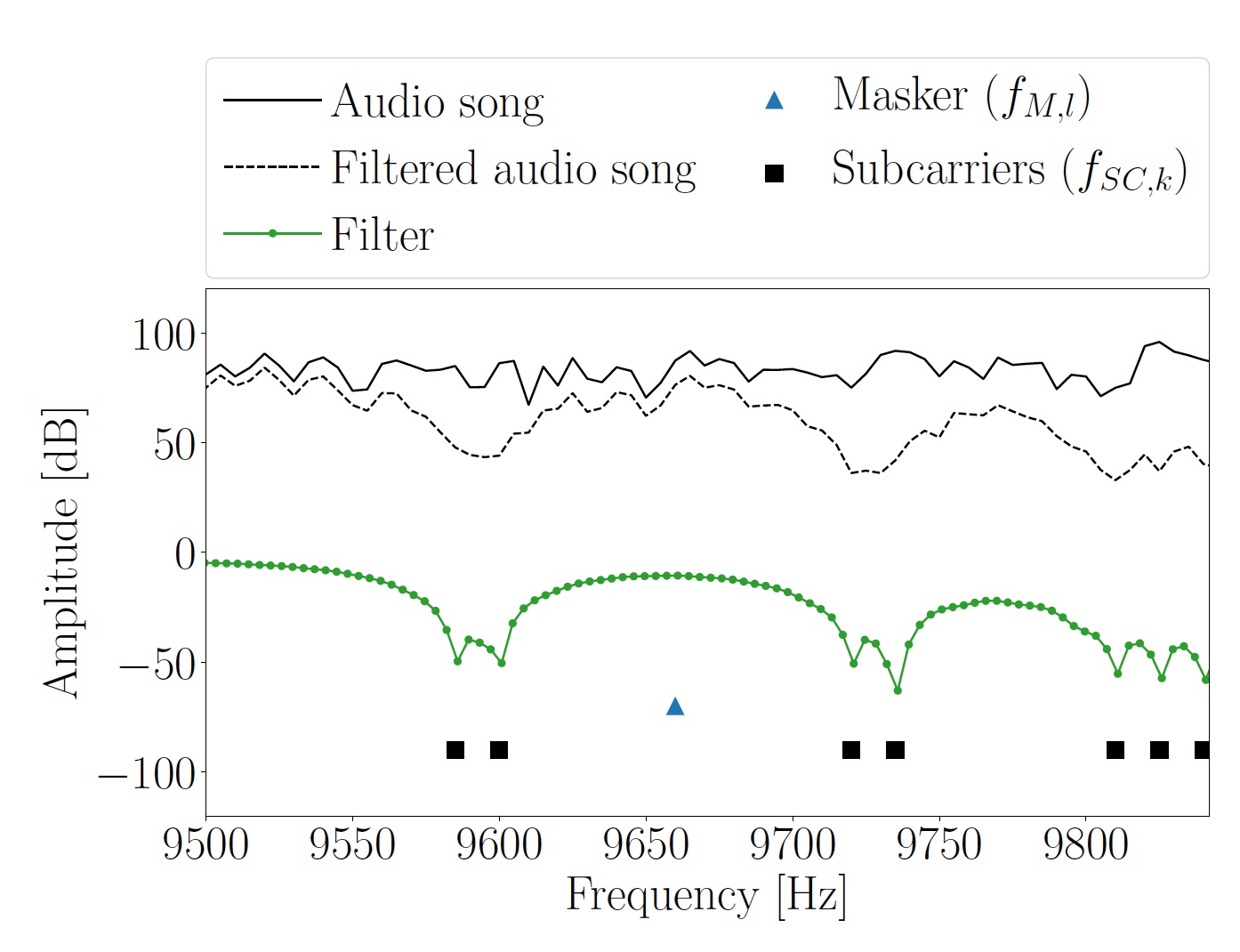
Image number 3: part of the spectrum and the frequency of the subcarriers of the Hi segment of the original melody.
When an audio signal with information encoded in it is played through the speakers, the receiver’s microphone records it. To find the starting positions of the built-in OFDM symbols, the entries must first be passed through band-pass filtering. Thus, the upper frequency range is extracted, where there is no musical signal-interference between the subcarriers. Find the beginning of the OFDM symbols using the cyclic prefix.
After detecting the beginning of the OFDM symbols, the receiver obtains information about the most dominant notes by decoding the upper frequency domain. In addition, OFDM is sufficiently robust to sources of narrowband interference, since they only affect some of the subcarriers.
Practical tests
The KRK Rokit 8 speaker was the source of the modified tunes, and the Nexus 5X smartphone played the role of the host.

Image No. 4: the difference between the actual manifestations of OFDM and the correlation peaks measured indoors at a distance of 5 m between the speaker and microphone.
Most OFDM points are in the range of 0 to 25 ms, so you can find a valid start within the cyclic prefix of 66.6 ms. The researchers note that the receiver (in this experience, the smartphone) takes into account that OFDM symbols are reproduced periodically, which improves their detection.
The first thing to check was the effect of distance on the bit error rate (BER). For this, three tests were carried out in different types of premises: a corridor with carpet, a room with linoleum on the floor and an audience with a wooden floor.
The song “And The Cradle Will Rock” by Van Halen was chosen as the “test subject”.
The volume of the sound was adjusted so that the sound level measured by the smartphone at a distance of 2 m from the speaker was 63 dB.
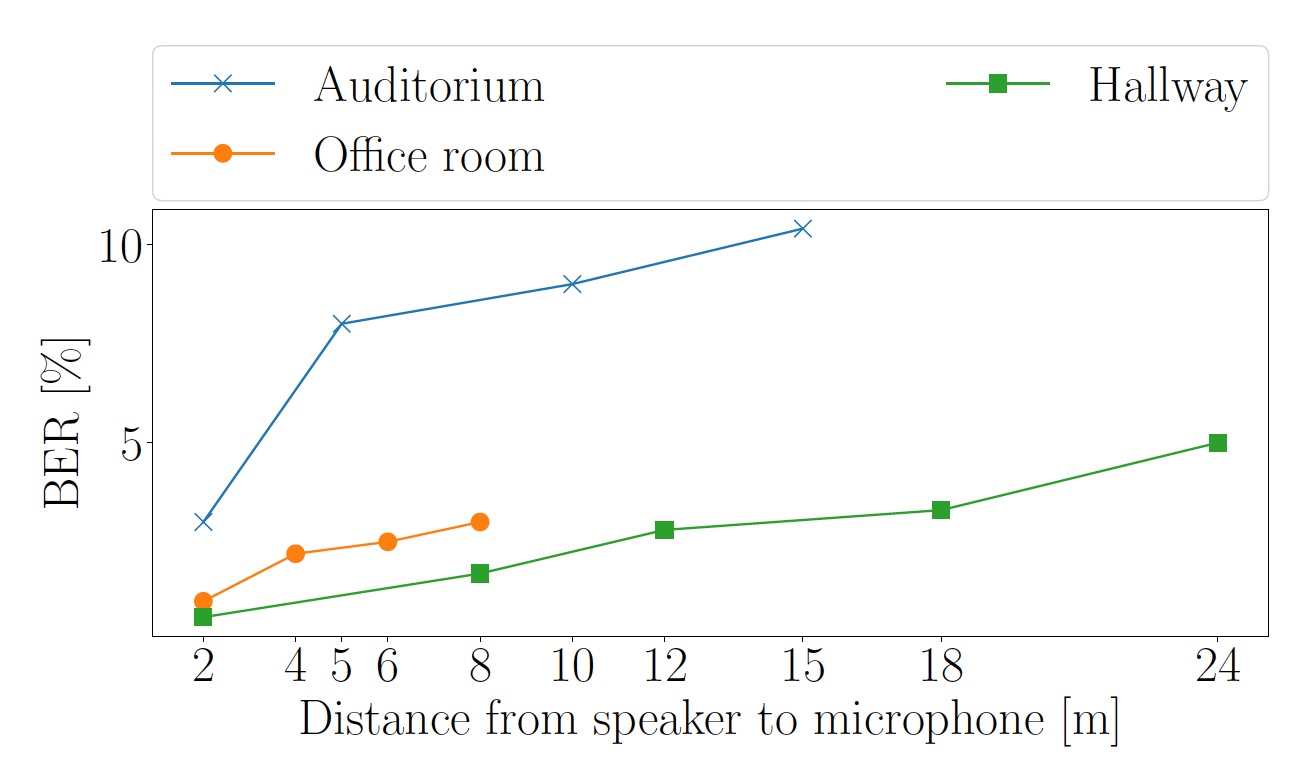
Image No. 5: BER indicators depending on the distance between the speaker and microphone (the blue line is the audience, the green is the corridor, the orange is the office).
In the corridor, the sound of 40 dB was picked up by the smartphone at a distance of up to 24 meters from the speaker. In the audience at a distance of 15 m, the sound was 55 dB, and in the office, at a distance of 8 meters, the level of sound perceived by the smartphone reached 57 dB.
Due to the fact that the audience and the office are more reverberant, later echoes of the OFDM symbols exceed the length of the cyclic prefix and increase the BER.
Reverberation * - a gradual decrease in the sound intensity due to its multiple reflection.Next, the researchers demonstrated the versatility of their system by applying it to 6 different songs of three genres (table below).
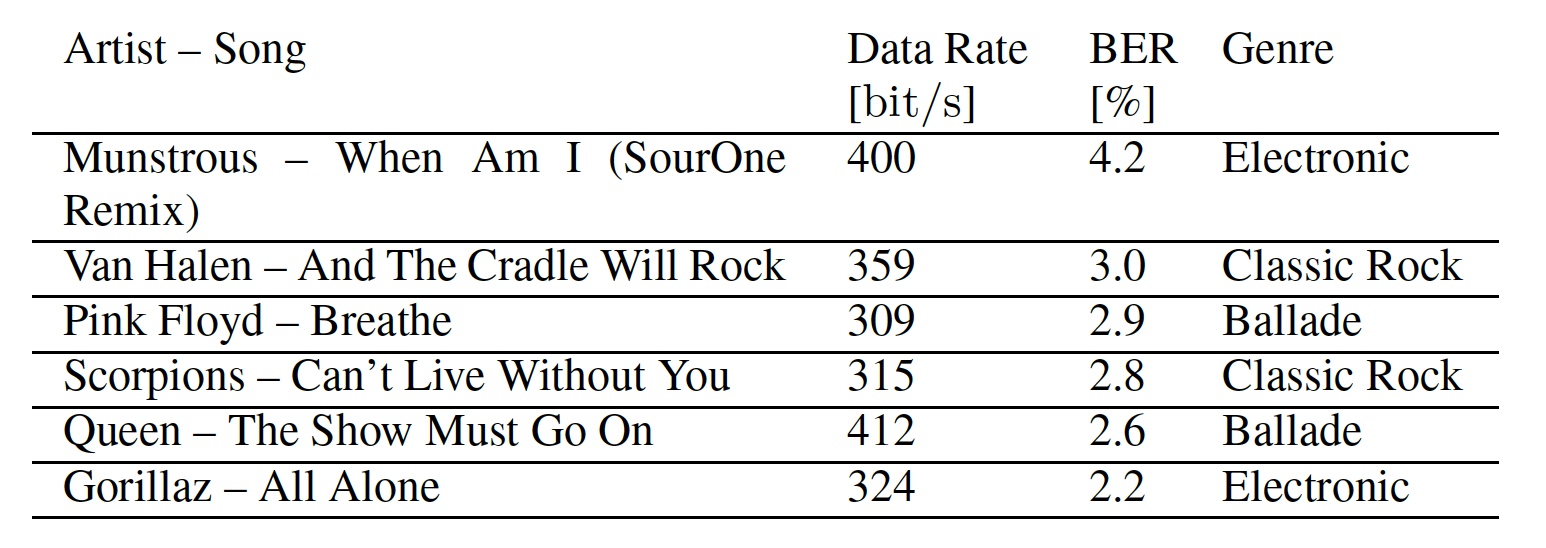
Table 1: used in the test songs.
Also, through the table data, we can see the transmission rate and bit error rates for each song. The data transfer rate is different because differential BPSK (phase shift keying) works better when the same subcarriers are used. And this is possible when neighboring segments contain the same masking elements. Continuously loud songs provide an optimal base for hiding data, since the masking frequencies are more pronounced in a wide frequency range. Rapidly changing music can mask OFDM symbols only partially due to the fixed length of the analysis window.
Next, people started testing the system, which should have determined which melody was original and which was modified by the information embedded in it. To do this, 12-second passages of songs from table number 1 were posted on a special website.
In the first experiment (E1), each participant was provided with either a modified or original fragment for listening, and he had to decide whether this fragment was original or modified. In the second experiment (E2), participants could listen to both versions as many times as they like, and then decide which one was original and which one was changed.
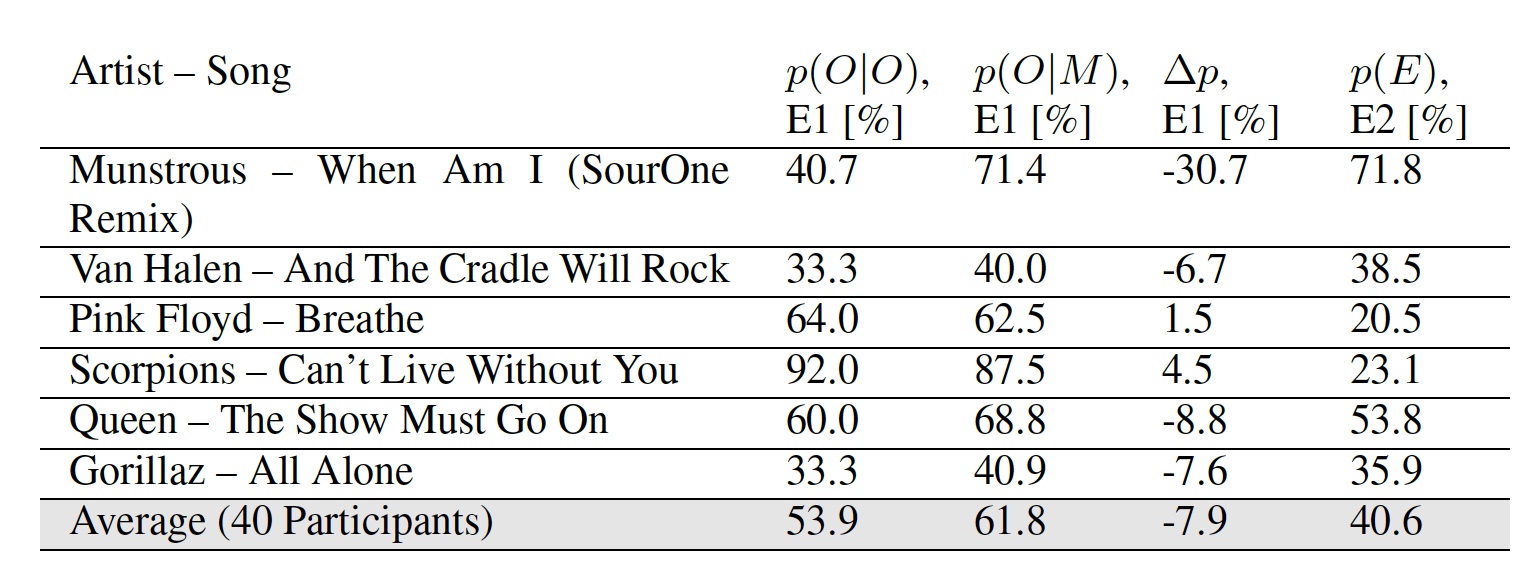
Table 2: the results of experiments E1 and E2.
There are two indicators in the results of the first experiment: p (O | O) - the percentage of participants who correctly marked the original melody and p (O | M) - the percentage of participants who marked the modified version of the melody as original.
It is curious that some participants, according to the researchers, considered certain modified melodies to be more original than the original itself. The average of both experiments suggests that the average listener will not notice the difference between the usual melody and the one into which the data was embedded.
Naturally, connoisseurs of music and musicians will be able to catch some inaccuracies and suspicious elements in the modified melodies, but these elements are not so significant as to cause discomfort.
And now we ourselves can participate in the experiment. Below are two versions of the same melody - original and modified. Do you hear the difference?
Original version of the melody
vs
Modified version of the melody
For a more detailed acquaintance with the nuances of the study I recommend to look into the report of the research group.
You can also download a zip archive of original and modified melodies used in the study via this link .
Epilogue
In this work, the graduate students of the Swiss Higher Technical School Zurich described an amazing data transfer system inside the music. To do this, they applied frequency masking, which made it possible to embed data into the melody played by the speaker. This tune is perceived by the microphone of the device, which recognizes the hidden data and decodes it, while the average listener will not even notice the difference. In the future, the guys plan to develop their system, selecting more advanced methods for embedding data in audio.
When someone comes up with something unusual, and most importantly working, we are always happy. But even more joy from the fact that this invention was created by young people. Science has no age limit. And if young people consider science to be boring, then it is presented not from that angle, so to speak. After all, as we know, science is a wonderful world that never ceases to amaze.
Friday off-top:
Since we are talking about music, or rather about rock music, then here's a great journey through the expanses of rock.
Queen, "Radio Ga Ga" (1984).
Thank you for your attention, remain curious, and have a great weekend, guys! :)
Since we are talking about music, or rather about rock music, then here's a great journey through the expanses of rock.
Queen, "Radio Ga Ga" (1984).
Thank you for your attention, remain curious, and have a great weekend, guys! :)
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - from $ 99! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
Source: https://habr.com/ru/post/459594/
All Articles