Recent changes to the Linux IO stack from a DBA perspective
The main issues of working with the database are related to the features of the device of the operating system on which the database is running. Now Linux is the main operating system for databases. Solaris, Microsoft and even HPUX are still used in the enterprise, but they will never take first place again, even taken together. Linux is confidently gaining ground, because open source databases are growing. Therefore, the question of the interaction of the database with the OS, obviously, about databases in Linux. This is superimposed on the eternal problem of the database - the performance of IO. It’s good that in Linux the IO-stack is undergoing major overhaul in recent years and there is hope for enlightenment.
Ilya Kosmodemyansky ( hydrobiont ) works for the company Data Egret, which is engaged in consulting and support for PostgreSQL, and knows a lot about the interaction of the OS and databases. In a report on HighLoad ++, Ilya talked about the interaction between IO and the database using the example of PostgreSQL, but also showed how other databases work with IO. Considered the Linux IO stack, what's new and good in it, and why things are not as they were a couple of years ago. A useful checklist is the PostgreSQL and Linux settings checklist for maximum performance of the IO subsystem in new kernels.
In the video report a lot of English, most of which we translated in the article.
Fast I / O is the most critical thing for database administrators . Everyone knows that you can change in working with the CPU, that the memory can be expanded, but I / O can ruin everything. If the disks are bad and there is too much I / O, then the database will groan. IO will become a bottleneck.
')
Not only the database or only iron - everything. Even a high-level Oracle, which is itself an operating system, requires configuration. We read the instructions in the "Installation guide" from Oracle: change these kernel parameters, change others - there are many settings. Apart from the fact that in Unbreakable Kernel a lot of things are already sewn up by default on Oracle's Linux.
For PostgreSQL and MySQL, more changes are required. That's because these technologies rely on OS mechanisms. A DBA that works with PostgreSQL, MySQL, or modern NoSQL should be “Linux operation engineer” and spin different OS nuts.
Anyone who wants to figure out how to tweak the kernel settings refers to the LWN . The resource is brilliant, minimalistic, contains a lot of useful information, but it is written by kernel developers for kernel developers . What do kernel developers write well? The core, not the article, how to use it. Therefore, I will try to explain everything to you for the developers, and they let the kernel write.
Everything is repeatedly complicated by the fact that initially the development of the Linux kernel and the processing of its stack lagged behind, and in recent years have gone very quickly. Neither hardware nor developers are keeping pace with articles.
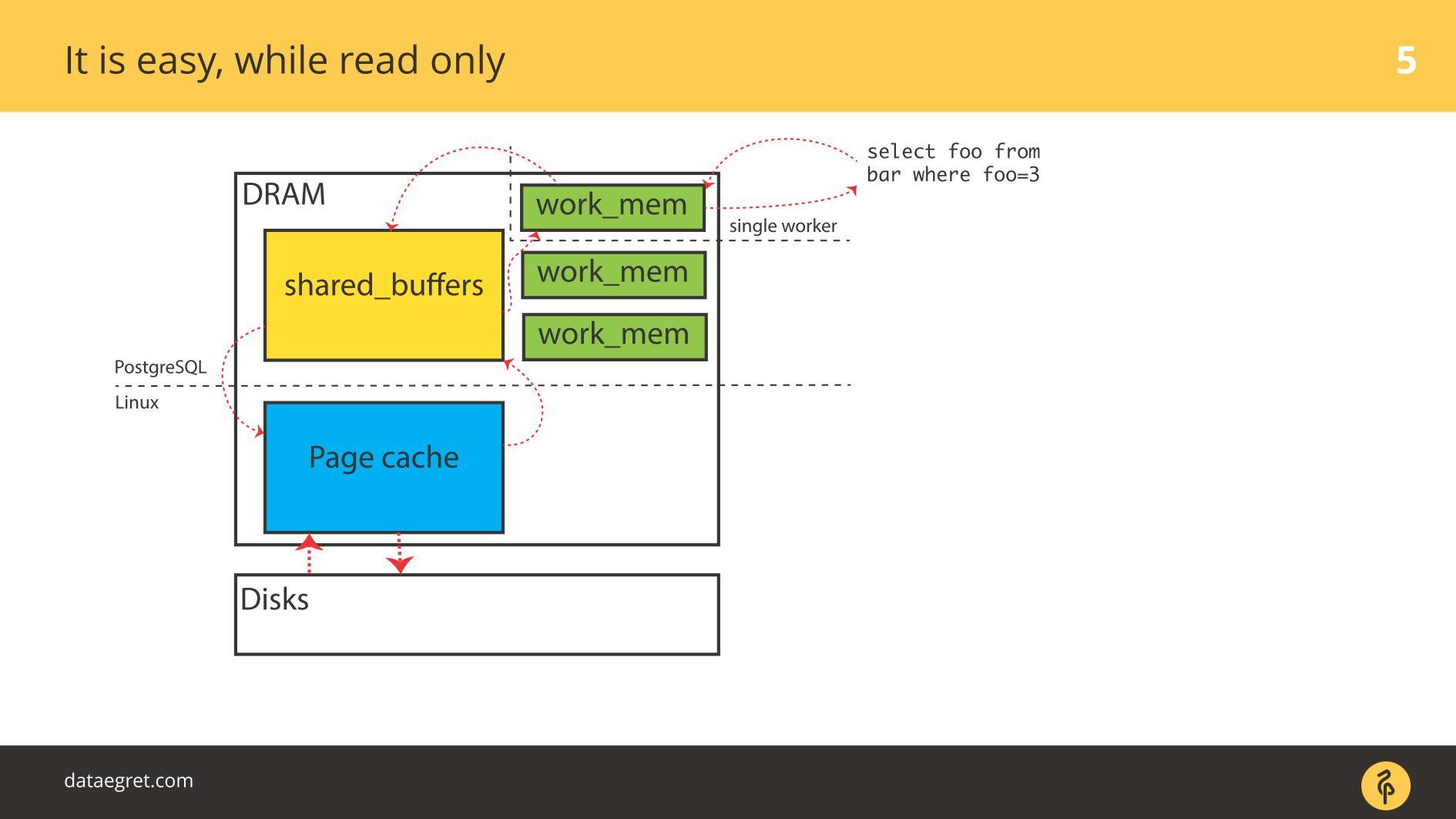
Let's start with PostgreSQL examples — here is buffered I / O. It has a spiced memory, which is distributed in the User space from the point of view of the OS, and has the same cache in the kernel cache in the Kernel space .

The main task of the modern database :
In a PostgreSQL situation, this is a constant round trip: from the spherical memory that PostgreSQL manages to the Page Cache of the kernel, and then to disk through the entire Linux stack. If you use a database on a file system, it will work with this algorithm with any UNIX-like system and with any database. There are differences, but insignificant.
When using Oracle, ASM will be different - Oracle itself interacts with the disk. But the principle is the same: with Direct IO or with Page Cache, but the task is to run the pages as quickly as possible through the entire I / O stack , whatever it may be. And problems can arise at every stage.
While everything is read only , there are no problems. Read and, if there is enough memory, all the data that needs to be counted, are placed in RAM. The fact that in the case of PostgreSQL in Buffer Cache is the same, we are not very worried.
The first problem with IO is cache synchronization. Occurs when recording is required. In this case, you will have to drive much more memory back and forth.
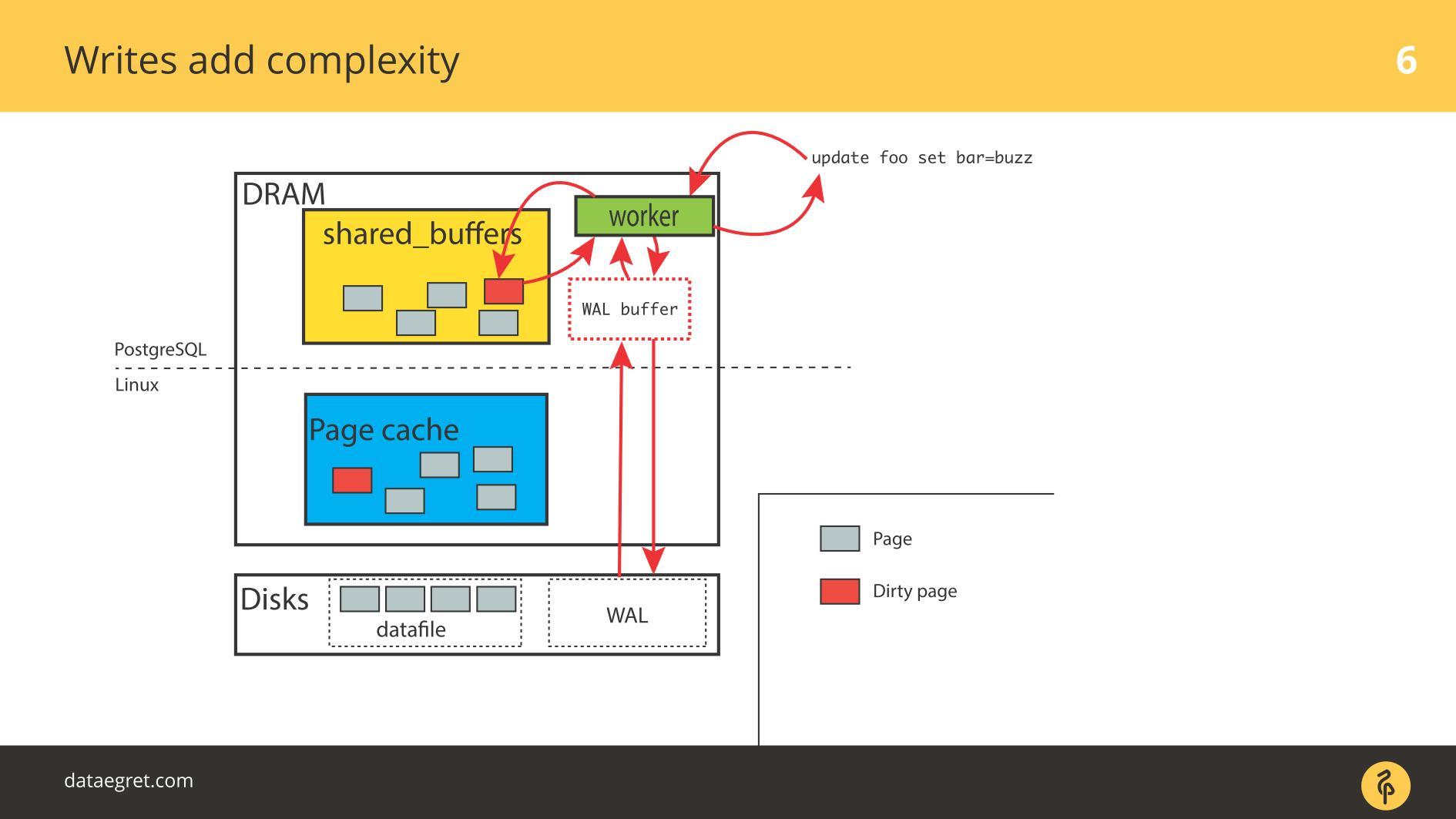
Accordingly, it is necessary to configure PostgreSQL or MySQL, so that everything from a sparse memory gets on the disk. In the case of PostgreSQL, you also need to fine tune the background writing of dirty pages in Linux to send everything to disk.
The second common problem is Write-Ahead Log failure . It appears when the load is so powerful that even a consistently written log rests on the disk. In this situation, it also needs to be recorded quickly.
The situation is a little different from cache synchronization . In PostgreSQL, we work with a large number of spurious buffers, there are mechanisms in the database for writing Write-Ahead Log efficiently, it is optimized to the utmost. The only thing that can be done to write the log itself more efficiently is to change the settings of Linux.
The segment of the memory can be very large . I started talking about this at conferences in 2012. Then I said that the memory has fallen in price, even there are servers with 32 GB of RAM. In 2019, even in laptops, there may be more, on servers, more and more often it costs 128, 256, etc.
Memory is really a lot . Banal recording takes time and resources, and the technologies that we use for this purpose are conservative . The databases are old, they are developed for a long time, they slowly evolve. The mechanisms in the bases are not exactly the latest technology.
Synchronizing pages in memory with a disk results in huge IO operations . When we synchronize caches, a large flow of IO arises, and another problem arises - we cannot twist something and look at the effect. In a scientific experiment, researchers change one parameter - get the effect, the second - get the effect, the third. We do not succeed. We spin some parameters in PostgreSQL, set up checkpoints - we did not see the effect. Then again, adjust the entire stack to catch at least some result. Twist one parameter does not work - we have to adjust everything at once.
Most PostgreSQL IO generates page synchronization: checkpoints and other synchronization mechanisms. If you have worked with PostgreSQL, you may have seen checkpoints spikes when a “saw” periodically appears on the charts. Previously, many faced with such a problem, but now there are manuals on how to fix it, it has become easier.
SSD today greatly save the situation. In PostgreSQL, something rarely rests directly on the value record. It all comes down to synchronization: when checkpoint occurs, fsync is called and there is a sort of “hitting” of one checkpoint to another. Too much IO. One checkpoint has not finished yet, has not completed all of its fsyncs, and another checkpoint has already earned, and it has begun!
PostgreSQL has a unique feature - autovacuum . This is a long history of crutches under the architecture of the database. If autovacuum does not cope, it is usually set up so that it works aggressively and does not interfere with the others: many autovacuum workers, frequent triggered a little bit, processing tables quickly. Otherwise there will be problems with DDL and with locks.
If the autovacuum job is superimposed on checkpoints, then most of the time the disks are utilized by almost 100%, and this is the source of the problems.
Oddly enough, there is a problem Cache refill . It is usually less known to DBA. A typical example: the DB has started, and for some time everything sadly slows down. Therefore, even if you have a lot of RAM, buy good disks so that the stack warms up the cache.
All this seriously affects performance. Problems begin not immediately after restarting the database, but later. For example, passed the checkpoint, and many pages are stained throughout the database. They are copied to disk because they need to be synchronized. Then requests ask for a new version of the pages from the disk, and the database sags. The graphs show how Cache refill after each checkpoint adds a certain percentage to the load.
The most unpleasant in the input / output database - Worker IO. When each worker to whom you address with request, begins to generate the IO. Oracle is easier with it, and PostgreSQL is a problem.
There are many reasons for problems with Worker IO : there is not enough cache to “run” new pages from disk. For example, it happens that all buffers are sparred, they are all stained, there are no checkpoints yet. That vorker executed the elementary select, it is necessary to take a cache from somewhere. To do this, you first need to save it all to disk. You have a non-specialized checkpointer process, and the worker starts running fsync to free it and fill it with something new.
There is an even bigger problem: the worker is a unspecialized thing, and the whole process is not optimized at all. It is possible to optimize somewhere at the Linux level, but in PostgreSQL it is an emergency measure.
What problem do we solve when we set something up? We want to maximize the journey of dirty pages between disk and memory.
But it often happens that these things do not directly concern the disk. A typical case is you see a very large load average. Why is that? Because someone is waiting for the disk, and all other processes are also waiting. It seems that there is no explicit disposal of disks by writing, just something there has blocked the disk, but the problem is still with I / O.
Everything is involved in this problem: disks, memory, CPU, IO Schedulers, file systems and settings of the database itself. Now let's go through the stack, see what to do with it, and what good things were invented in Linux for everything to work better.
For many years the disks were terribly slow and no one was engaged in latency or optimization of the transition stages. Optimizing fsyncs didn't make sense. The disk rotated, heads drove over it as on a record, and fsyncs was so long that problems didn’t come up.
Without setting the database, the top queries are useless to watch. You will configure a sufficient amount of sparred memory, etc., and you will have a new top of requests - you will have to re-configure. Here is the same story. The entire Linux stack was made from this calculation.
Maximizing IO performance through maximizing throughput is easy until a certain point. The auxiliary process of PageWriter in PostgreSQL which unloaded checkpoint is thought up. The work has become parallel, but there is still a reserve for adding parallelism. And to minimize latency is the task of the last mile, for which we need supertechnology.
These supertechnologies have become SSD. When they appeared, latency dropped dramatically. But at all other stages of the stack, problems appeared: from the producers of the database, and from the producers of Linux. Problems require solutions.
Database development focused on maximizing bandwidth, as well as developing the Linux kernel. Many methods of optimizing the I / O era of rotating disks are not so good for SSD.
In the interim, we were forced to put backups for the current Linux infrastructure, but with new drives. We looked at the performance tests from the manufacturer with a large number of different IOPS, and the database did not get any better, because the database is not only and not so much about IOPS. It often happens that we can miss 50,000 IOPS per second, which is good. But if we do not know latency, do not know its distribution, then we can not say anything about performance. At some point, the database will start to do checkpoint, and latency will increase dramatically.
For a long time, as now, it was a big performance problem on virtual servers for databases. Virtual IO is characterized by uneven latency, which, of course, also causes problems.
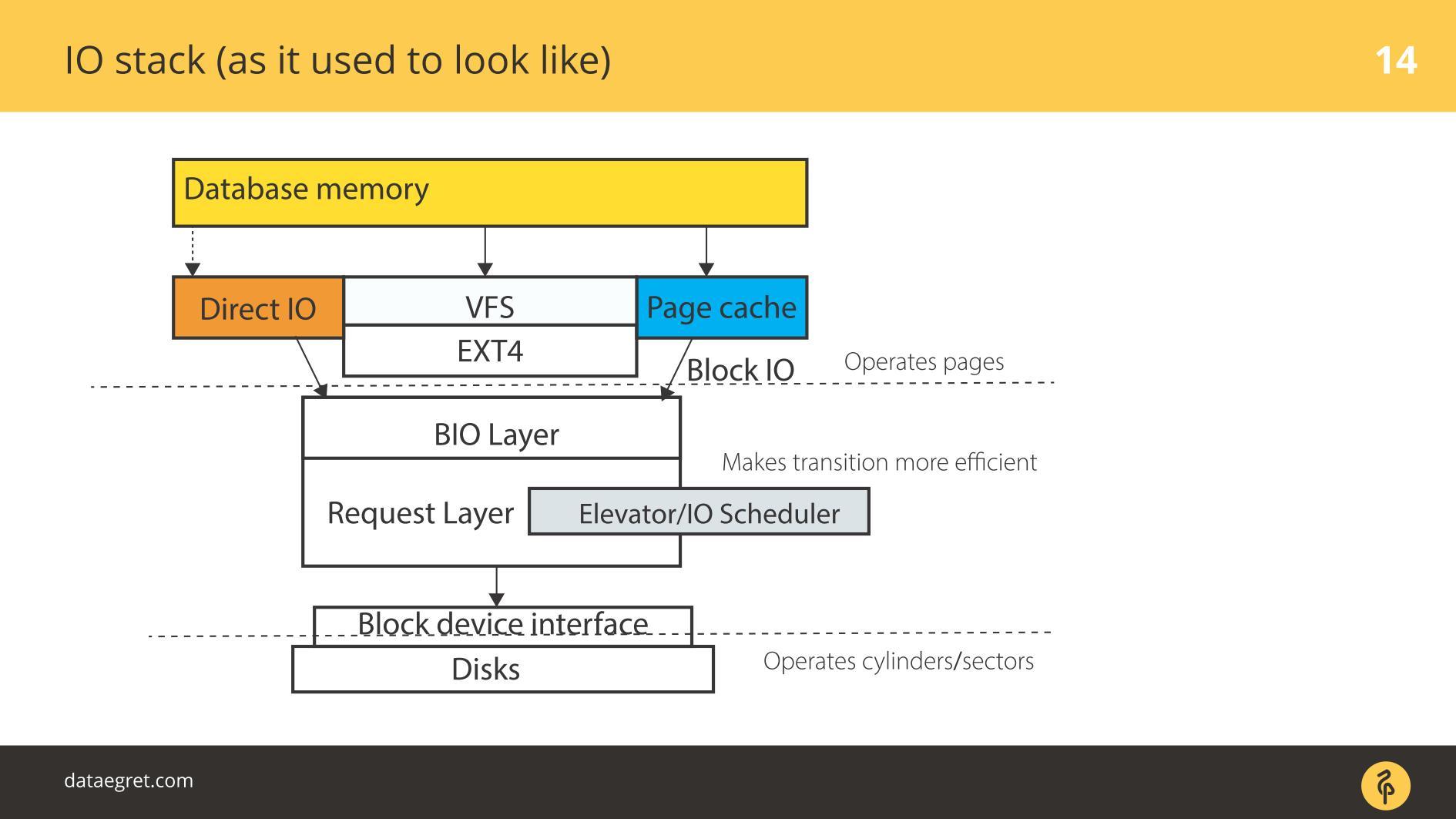
There is a User space - the memory that is controlled by the database itself. In the database, set up so that everything works as it should. About this you can make a separate report, and not even one. Then everything inevitably goes through Page Cache or through the Direct IO interface gets into the Block Input / Output-layer .
Imagine a file system interface. Pages that were in Buffer Cache, as they were originally in the database, that is, blocks, move down through it. Block IO-layer is doing the following. There is a C-structure that describes a block in the kernel. The structure takes these blocks and collects from them vectors (arrays) of requests for input or output. Under the BIO-layer is a layer of rekvestov. On this layer, the vectors are collected and will go on.
For a long time, these two layers in Linux were sharpened to efficiently write to magnetic disks. Without a transition was not enough. There are blocks that are conveniently managed from the database. It is necessary to assemble these blocks into vectors that are conveniently written to disk so that they lie somewhere nearby. That it effectively worked, thought up Elevators, or Schedulers IO.
Elevators were mainly engaged in combining and sorting vectors. All so that the block driver SD - quasidisc driver - blocks for writing come in a convenient order. The driver produced a broadcast from the blocks in their sectors and wrote to the disk.
The problem was that it was necessary to do several transitions, and on each to implement its own logic of the optimal process.
Before the 2.6 kernel, there was a Linus Elevator - the most primitive IO Scheduler, which was written by anyone who guessed it. For a long time, it was considered absolutely unshakable and good, until it developed something new.
Linus Elevator had a lot of problems. He combined and sorted depending on how efficiently to write . In the case of rotating mechanical discs, this led to the appearance of “ starvation” : a situation where the recording efficiency depends on the rotation of the disc. If suddenly you need to read effectively at the same time, but it is already turned wrong, it is badly read from such a disk.
Gradually, it became clear that this is an inefficient way. Therefore, starting with kernel 2.6, a whole zoo schedulers began to appear, which was intended for different tasks.
Many people confuse these schedulers with the schedulers of the operating system, because they have similar names. CFQ - Completely Fair Queuing is not the same thing as the schedulers OS. Just the names are similar. It was coined as a universal scheduler.
What is universal scheduler? Do you think your load is average or, on the contrary, unique? The databases are very bad with versatility. Universal load can be imagined as the work of an ordinary laptop. Everything happens there: we listen to music, we play, we type. For this, universal schedulers were written.
The main task of the universal scheduler: in the case of Linux for each virtual terminal and process, create your own turn of requests. When we want to listen to music in an audio player, IO for the player takes a turn. If we want to backup something with the cp command, something else is involved.
In the case of databases, there is a problem. As a rule, a database is a process that started, and during operation, parallel processes have arisen that always end in the same I / O queue. The reason is that this is the same application, the same parent process. For very small loads such scheduling was suitable, for the rest it did not make sense. It was easier to turn it off and not use it, if possible.
Gradually, the deadline scheduler appeared - it works smarter, but basically it is merge and sorting for rotating disks. Taking into account the device of a specific disk subsystem, we collect block vectors to write them in an optimal way. He had fewer starvation problems, but they were there.
Therefore, closer to the third Linux kernels, noop or none appeared , which worked much better with the prevalent SSDs. Including the scheduler noop, we actually disable scheduling: no sorting, merging or similar things that CFQ and the deadline did.
This works better with SSDs, because SSD is naturally parallel: it has memory cells. The more of these elements crammed on a single PCIe card, the more efficiently everything will work.
Scheduler from some otherworldly, from the point of view of SSD, considerations, collects some vectors and sends them somewhere. This all ends in a funnel. So we kill SSD concurrency, do not use them to the fullest. Therefore, a simple shutdown, when the vectors go haphazardly without any sorting, worked better in terms of performance. Because of this, it is believed that SSD is better to go random read, random write.
Starting with the 3.13 kernel, blk-mq appeared . A bit earlier there was a prototype, but in 3.13 the working version first appeared.
Blk-mq started as a scheduler, but it's difficult to call it a scheduler - it is architecturally separate. This is a replacement for the request layer in the kernel. Slowly the development of blk-mq led to a serious reworking of the entire Linux I / O stack.
The idea is this: let's use the native SSD capability for efficient I / O parallelism for I / O. Depending on how many parallel I / O streams can be used, there are fair queues through which we simply write as is on the SSD. Each CPU has its own queue for writing.
Currently blk-mq is actively developing and working. No reason not to use it. In modern kernels, from 4 and up, blk-mq gains a tangible gain - not 5-10%, but significantly more.
In its current form, blk-mq is directly tied to the NVMe driver Linux. There is not only a driver for Linux, but also a driver for Microsoft. But the idea to make blk-mq and NVMe driver is the very reworking of the Linux stack, from which the databases benefited greatly.
A consortium of several companies decided to make a specification, this very protocol. Now he is already in the production version works fine for local PCIe SSD. Almost ready solution for disk arrays that are connected by optics.
Let's dive into it to understand what it is. The NVMe specification is large, so we will not consider all the details, but just go over them.

The simplest case: there is a CPU, there is its turn, and we somehow go to disk.
More advanced Elevators worked differently. There are several CPUs and several queues. Somehow, for example, depending on which parent process the DB workers have been budding from, the IO gets into the queue and onto the disks.
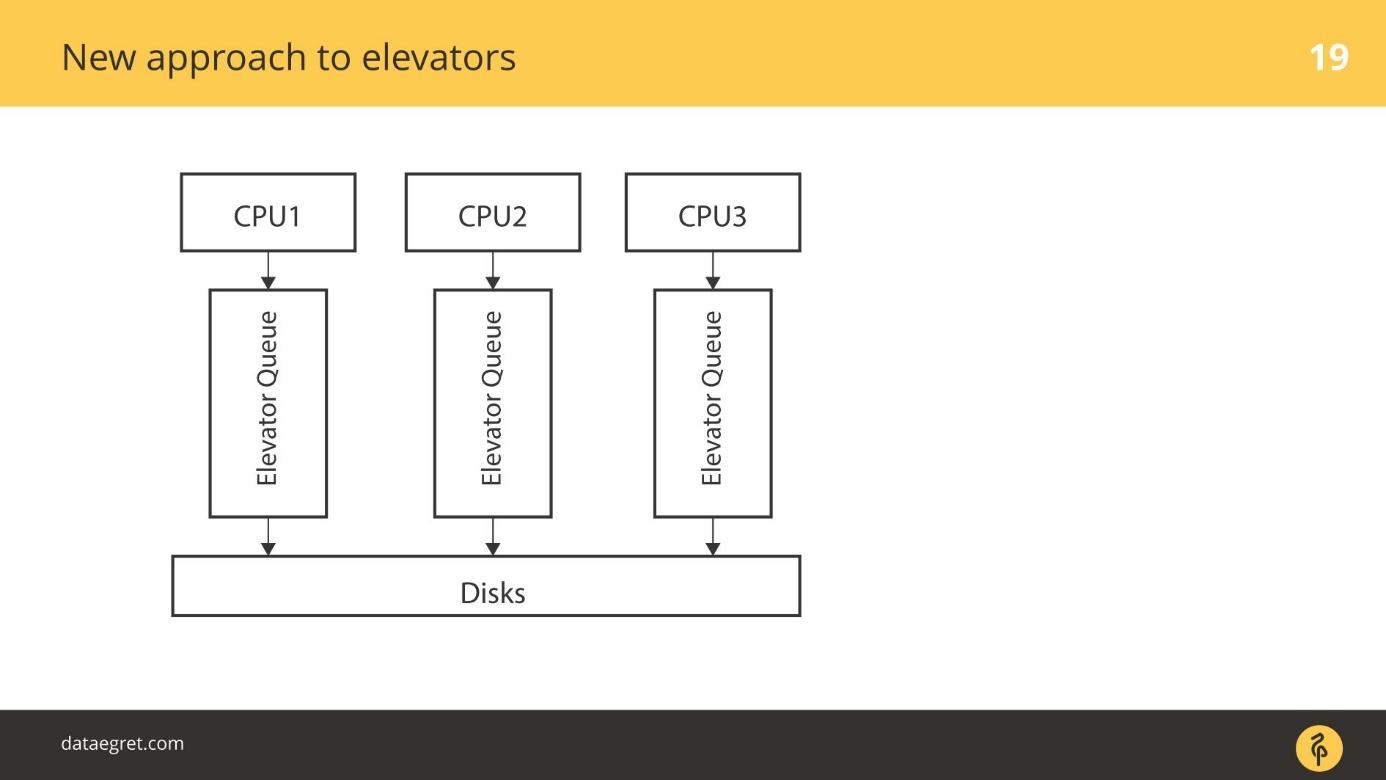
blk-mq is a completely new approach. Each CPU, each NUMA zone adds its I / O to its turn. Then the data gets to the disks, it does not matter how connected, because the driver is new. There is no SD driver that operates on the concepts of cylinders, blocks.
There was a transition period. At some point, all RAID vendors began selling add-ons that allowed to bypass the RAID cache. If SSD is connected, write directly there. They disabled the use of SD drivers for their products, like blq-mq.
This is what the new stack looks like.

From above, everything remains as well. For example, the database is far behind. Input / output from the database, just as before, enters the Block IO-layer. There is the same blk-mq , which replaces the query layer, not the scheduler.
In the 3.13 kernel, this was about the end of all optimization, but in modern kernels new technologies are used. Special schedulers for blk-mq , which are designed for stronger parallelism, began to appear. In today's fourth Linux kernels, two schedulers IO are considered mature - Kyber and BFQ. They are designed to work with parallelism and with blk-mq .
BFQ - Budget Fair Queueing is an analogue of C FQ . They are completely different, although one grew out of another. BFQ is a complex math scheduler. Each application and process has a certain IO quota. The quota depends on the amount of IO that the process / application generates. According to this budget, we have a band to write to. How well it works is a difficult question. If you are interested in BFQ, there are lots of articles that analyze the process math.
Kyber is an alternative . It is like BFQ, but without mathematics. Kyber has a small scheduler for the amount of code. Its main task is to receive from the CPU and send. Kyber is lightweight and works better.
An important point for the entire stack - blk-mq does not look into the SD driver . It does not have another conversion layer, which I complained about when I showed how the IO stack looked before. From blk-mq to NVMe driver, everything comes immediately in finished form. Blocks in cylinders are not recalculated.
In the new approach, several interesting moments have arisen - latency has sharply dropped, including this layer. First there were SSDs that work well - it became possible to recycle this layer. As soon as we stopped converting back and forth, it turned out that both the NVMe layer and blk-mq have their bottlenecks, which also need to be optimized. Now let's talk about them.
Thomas Krenn has a constantly updated and current Linux I / O stack diagram .
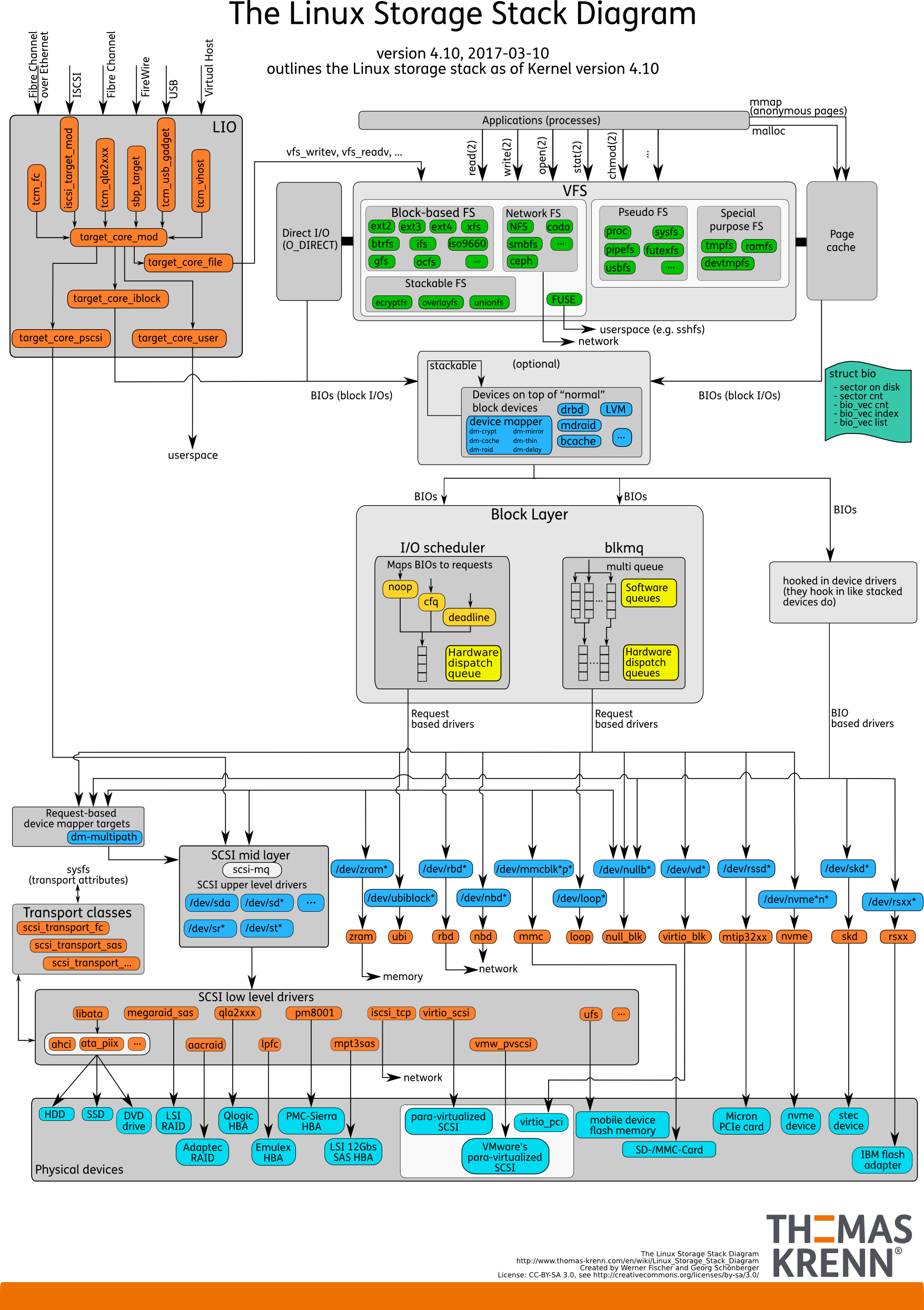
The diagram shows who stood over whom, the relationship between the drivers, which Elevators, which part of which layer.
The diagram is regularly updated, which helps to monitor the evolution of the kernel database administrators and other professionals who work with databases.
NVM Express or NVMe is a specification, a set of standards that help you use SSDs more efficiently. The specification is well implemented in Linux. Linux is one of the driving forces behind the standard.
Now in the third version. The driver of this version, according to the specification, can skip around 20 GB / s for one SSD unit, and NVMe of the fifth version, which is not yet available, up to 32 GB / s . The SD driver has no interfaces or mechanisms inside to provide this bandwidth.
Once, databases were written under rotating disks and oriented towards them - they have indices in the form of a B-tree, for example. The question arises: are you ready for NVMe databases ? Can the DB chew such a load?
Not yet, but they are adapting. Recently there were a couple of
Over the past year and a half, IO polling has been added to NVMe.
At first there were rotating discs with high latency. Then came the SSD, which is much faster. But a jamb appeared: fsync is on, recording starts, and at a very low level - deep in the driver, a request is sent directly to the piece of iron - write it down.
The mechanism was simple - sent and wait for the interrupt to be processed. Waiting for interrupt processing is not a problem compared to writing to a rotating disk. It took so long to wait for the interrupt to work as soon as the recording ended.
Since the SSD is recording very quickly, a mechanism for polling the piece of iron about the recording has appeared. In the first versions, the increase in I / O speed reached 50% due to the fact that we are not waiting for an interruption, but rather actively asking the piece of iron about the record. This mechanism is called IO polling .
It has been introduced in recent versions. In version 4.12, IO schedulers appeared, specially honed to work with blk-mq and NVMe, about which I said Kyber and BFQ . They are already officially in the core, they can be used.
Now in a usable form there is a so-called IO tagging . Basically, cloud and virtual cloud manufacturers contribute to this development. Roughly speaking, input from a specific application can be tagged and given priority. The databases are not ready for this yet, but stay tuned. I think it will be mainstream soon.
PostgreSQL does not support Direct IO and there are a number of issues that prevent the inclusion of support . Now it is supported only for value, and only if replication is not enabled. It is required to write a lot of OS-specific code , and so far everyone has refrained from it.
Despite the fact that Linux strongly curses the idea of Direct IO and how it is implemented, all the databases go there. In Oracle and MySQL Direct IO is actively used. PostgreSQL is the only database that doesn’t transfer Direct IO.
How to protect PostgreSQL from fsync surprises:
Ilya Kosmodemyansky ( hydrobiont ) works for the company Data Egret, which is engaged in consulting and support for PostgreSQL, and knows a lot about the interaction of the OS and databases. In a report on HighLoad ++, Ilya talked about the interaction between IO and the database using the example of PostgreSQL, but also showed how other databases work with IO. Considered the Linux IO stack, what's new and good in it, and why things are not as they were a couple of years ago. A useful checklist is the PostgreSQL and Linux settings checklist for maximum performance of the IO subsystem in new kernels.
In the video report a lot of English, most of which we translated in the article.
Why talk about IO?
Fast I / O is the most critical thing for database administrators . Everyone knows that you can change in working with the CPU, that the memory can be expanded, but I / O can ruin everything. If the disks are bad and there is too much I / O, then the database will groan. IO will become a bottleneck.
')
To make it work well, you need to configure everything.
Not only the database or only iron - everything. Even a high-level Oracle, which is itself an operating system, requires configuration. We read the instructions in the "Installation guide" from Oracle: change these kernel parameters, change others - there are many settings. Apart from the fact that in Unbreakable Kernel a lot of things are already sewn up by default on Oracle's Linux.
For PostgreSQL and MySQL, more changes are required. That's because these technologies rely on OS mechanisms. A DBA that works with PostgreSQL, MySQL, or modern NoSQL should be “Linux operation engineer” and spin different OS nuts.
Anyone who wants to figure out how to tweak the kernel settings refers to the LWN . The resource is brilliant, minimalistic, contains a lot of useful information, but it is written by kernel developers for kernel developers . What do kernel developers write well? The core, not the article, how to use it. Therefore, I will try to explain everything to you for the developers, and they let the kernel write.
Everything is repeatedly complicated by the fact that initially the development of the Linux kernel and the processing of its stack lagged behind, and in recent years have gone very quickly. Neither hardware nor developers are keeping pace with articles.
Typical database
Let's start with PostgreSQL examples — here is buffered I / O. It has a spiced memory, which is distributed in the User space from the point of view of the OS, and has the same cache in the kernel cache in the Kernel space .
The main task of the modern database :
- raise to memory page from the disk;
- when a change occurs, mark the pages as dirty;
- write to Write-Ahead Log;
- after that, synchronize the memory so that it is consistent with the disk.
In a PostgreSQL situation, this is a constant round trip: from the spherical memory that PostgreSQL manages to the Page Cache of the kernel, and then to disk through the entire Linux stack. If you use a database on a file system, it will work with this algorithm with any UNIX-like system and with any database. There are differences, but insignificant.
When using Oracle, ASM will be different - Oracle itself interacts with the disk. But the principle is the same: with Direct IO or with Page Cache, but the task is to run the pages as quickly as possible through the entire I / O stack , whatever it may be. And problems can arise at every stage.
Two IO problems
While everything is read only , there are no problems. Read and, if there is enough memory, all the data that needs to be counted, are placed in RAM. The fact that in the case of PostgreSQL in Buffer Cache is the same, we are not very worried.
The first problem with IO is cache synchronization. Occurs when recording is required. In this case, you will have to drive much more memory back and forth.
Accordingly, it is necessary to configure PostgreSQL or MySQL, so that everything from a sparse memory gets on the disk. In the case of PostgreSQL, you also need to fine tune the background writing of dirty pages in Linux to send everything to disk.
The second common problem is Write-Ahead Log failure . It appears when the load is so powerful that even a consistently written log rests on the disk. In this situation, it also needs to be recorded quickly.
The situation is a little different from cache synchronization . In PostgreSQL, we work with a large number of spurious buffers, there are mechanisms in the database for writing Write-Ahead Log efficiently, it is optimized to the utmost. The only thing that can be done to write the log itself more efficiently is to change the settings of Linux.
The main problems of working with the database
The segment of the memory can be very large . I started talking about this at conferences in 2012. Then I said that the memory has fallen in price, even there are servers with 32 GB of RAM. In 2019, even in laptops, there may be more, on servers, more and more often it costs 128, 256, etc.
Memory is really a lot . Banal recording takes time and resources, and the technologies that we use for this purpose are conservative . The databases are old, they are developed for a long time, they slowly evolve. The mechanisms in the bases are not exactly the latest technology.
Synchronizing pages in memory with a disk results in huge IO operations . When we synchronize caches, a large flow of IO arises, and another problem arises - we cannot twist something and look at the effect. In a scientific experiment, researchers change one parameter - get the effect, the second - get the effect, the third. We do not succeed. We spin some parameters in PostgreSQL, set up checkpoints - we did not see the effect. Then again, adjust the entire stack to catch at least some result. Twist one parameter does not work - we have to adjust everything at once.
Most PostgreSQL IO generates page synchronization: checkpoints and other synchronization mechanisms. If you have worked with PostgreSQL, you may have seen checkpoints spikes when a “saw” periodically appears on the charts. Previously, many faced with such a problem, but now there are manuals on how to fix it, it has become easier.
SSD today greatly save the situation. In PostgreSQL, something rarely rests directly on the value record. It all comes down to synchronization: when checkpoint occurs, fsync is called and there is a sort of “hitting” of one checkpoint to another. Too much IO. One checkpoint has not finished yet, has not completed all of its fsyncs, and another checkpoint has already earned, and it has begun!
PostgreSQL has a unique feature - autovacuum . This is a long history of crutches under the architecture of the database. If autovacuum does not cope, it is usually set up so that it works aggressively and does not interfere with the others: many autovacuum workers, frequent triggered a little bit, processing tables quickly. Otherwise there will be problems with DDL and with locks.
But when Autovacuum is aggressive, it starts chewing on IO.
If the autovacuum job is superimposed on checkpoints, then most of the time the disks are utilized by almost 100%, and this is the source of the problems.
Oddly enough, there is a problem Cache refill . It is usually less known to DBA. A typical example: the DB has started, and for some time everything sadly slows down. Therefore, even if you have a lot of RAM, buy good disks so that the stack warms up the cache.
All this seriously affects performance. Problems begin not immediately after restarting the database, but later. For example, passed the checkpoint, and many pages are stained throughout the database. They are copied to disk because they need to be synchronized. Then requests ask for a new version of the pages from the disk, and the database sags. The graphs show how Cache refill after each checkpoint adds a certain percentage to the load.
The most unpleasant in the input / output database - Worker IO. When each worker to whom you address with request, begins to generate the IO. Oracle is easier with it, and PostgreSQL is a problem.
There are many reasons for problems with Worker IO : there is not enough cache to “run” new pages from disk. For example, it happens that all buffers are sparred, they are all stained, there are no checkpoints yet. That vorker executed the elementary select, it is necessary to take a cache from somewhere. To do this, you first need to save it all to disk. You have a non-specialized checkpointer process, and the worker starts running fsync to free it and fill it with something new.
There is an even bigger problem: the worker is a unspecialized thing, and the whole process is not optimized at all. It is possible to optimize somewhere at the Linux level, but in PostgreSQL it is an emergency measure.
The main problem of IO for DB
What problem do we solve when we set something up? We want to maximize the journey of dirty pages between disk and memory.
But it often happens that these things do not directly concern the disk. A typical case is you see a very large load average. Why is that? Because someone is waiting for the disk, and all other processes are also waiting. It seems that there is no explicit disposal of disks by writing, just something there has blocked the disk, but the problem is still with I / O.
Database I / O problems do not always relate to disks.
Everything is involved in this problem: disks, memory, CPU, IO Schedulers, file systems and settings of the database itself. Now let's go through the stack, see what to do with it, and what good things were invented in Linux for everything to work better.
Discs
For many years the disks were terribly slow and no one was engaged in latency or optimization of the transition stages. Optimizing fsyncs didn't make sense. The disk rotated, heads drove over it as on a record, and fsyncs was so long that problems didn’t come up.
Memory
Without setting the database, the top queries are useless to watch. You will configure a sufficient amount of sparred memory, etc., and you will have a new top of requests - you will have to re-configure. Here is the same story. The entire Linux stack was made from this calculation.
Bandwidth and latency
Maximizing IO performance through maximizing throughput is easy until a certain point. The auxiliary process of PageWriter in PostgreSQL which unloaded checkpoint is thought up. The work has become parallel, but there is still a reserve for adding parallelism. And to minimize latency is the task of the last mile, for which we need supertechnology.
These supertechnologies have become SSD. When they appeared, latency dropped dramatically. But at all other stages of the stack, problems appeared: from the producers of the database, and from the producers of Linux. Problems require solutions.
Database development focused on maximizing bandwidth, as well as developing the Linux kernel. Many methods of optimizing the I / O era of rotating disks are not so good for SSD.
In the interim, we were forced to put backups for the current Linux infrastructure, but with new drives. We looked at the performance tests from the manufacturer with a large number of different IOPS, and the database did not get any better, because the database is not only and not so much about IOPS. It often happens that we can miss 50,000 IOPS per second, which is good. But if we do not know latency, do not know its distribution, then we can not say anything about performance. At some point, the database will start to do checkpoint, and latency will increase dramatically.
For a long time, as now, it was a big performance problem on virtual servers for databases. Virtual IO is characterized by uneven latency, which, of course, also causes problems.
IO stack. As it was before
There is a User space - the memory that is controlled by the database itself. In the database, set up so that everything works as it should. About this you can make a separate report, and not even one. Then everything inevitably goes through Page Cache or through the Direct IO interface gets into the Block Input / Output-layer .
Imagine a file system interface. Pages that were in Buffer Cache, as they were originally in the database, that is, blocks, move down through it. Block IO-layer is doing the following. There is a C-structure that describes a block in the kernel. The structure takes these blocks and collects from them vectors (arrays) of requests for input or output. Under the BIO-layer is a layer of rekvestov. On this layer, the vectors are collected and will go on.
For a long time, these two layers in Linux were sharpened to efficiently write to magnetic disks. Without a transition was not enough. There are blocks that are conveniently managed from the database. It is necessary to assemble these blocks into vectors that are conveniently written to disk so that they lie somewhere nearby. That it effectively worked, thought up Elevators, or Schedulers IO.
Elevator
Elevators were mainly engaged in combining and sorting vectors. All so that the block driver SD - quasidisc driver - blocks for writing come in a convenient order. The driver produced a broadcast from the blocks in their sectors and wrote to the disk.
The problem was that it was necessary to do several transitions, and on each to implement its own logic of the optimal process.
Elevators: up to kernel 2.6
Before the 2.6 kernel, there was a Linus Elevator - the most primitive IO Scheduler, which was written by anyone who guessed it. For a long time, it was considered absolutely unshakable and good, until it developed something new.
Linus Elevator had a lot of problems. He combined and sorted depending on how efficiently to write . In the case of rotating mechanical discs, this led to the appearance of “ starvation” : a situation where the recording efficiency depends on the rotation of the disc. If suddenly you need to read effectively at the same time, but it is already turned wrong, it is badly read from such a disk.
Gradually, it became clear that this is an inefficient way. Therefore, starting with kernel 2.6, a whole zoo schedulers began to appear, which was intended for different tasks.
Elevators: between 2.6 and 3
Many people confuse these schedulers with the schedulers of the operating system, because they have similar names. CFQ - Completely Fair Queuing is not the same thing as the schedulers OS. Just the names are similar. It was coined as a universal scheduler.
What is universal scheduler? Do you think your load is average or, on the contrary, unique? The databases are very bad with versatility. Universal load can be imagined as the work of an ordinary laptop. Everything happens there: we listen to music, we play, we type. For this, universal schedulers were written.
The main task of the universal scheduler: in the case of Linux for each virtual terminal and process, create your own turn of requests. When we want to listen to music in an audio player, IO for the player takes a turn. If we want to backup something with the cp command, something else is involved.
In the case of databases, there is a problem. As a rule, a database is a process that started, and during operation, parallel processes have arisen that always end in the same I / O queue. The reason is that this is the same application, the same parent process. For very small loads such scheduling was suitable, for the rest it did not make sense. It was easier to turn it off and not use it, if possible.
Gradually, the deadline scheduler appeared - it works smarter, but basically it is merge and sorting for rotating disks. Taking into account the device of a specific disk subsystem, we collect block vectors to write them in an optimal way. He had fewer starvation problems, but they were there.
Therefore, closer to the third Linux kernels, noop or none appeared , which worked much better with the prevalent SSDs. Including the scheduler noop, we actually disable scheduling: no sorting, merging or similar things that CFQ and the deadline did.
This works better with SSDs, because SSD is naturally parallel: it has memory cells. The more of these elements crammed on a single PCIe card, the more efficiently everything will work.
Scheduler from some otherworldly, from the point of view of SSD, considerations, collects some vectors and sends them somewhere. This all ends in a funnel. So we kill SSD concurrency, do not use them to the fullest. Therefore, a simple shutdown, when the vectors go haphazardly without any sorting, worked better in terms of performance. Because of this, it is believed that SSD is better to go random read, random write.
Elevators: 3.13 onwards
Starting with the 3.13 kernel, blk-mq appeared . A bit earlier there was a prototype, but in 3.13 the working version first appeared.
Blk-mq started as a scheduler, but it's difficult to call it a scheduler - it is architecturally separate. This is a replacement for the request layer in the kernel. Slowly the development of blk-mq led to a serious reworking of the entire Linux I / O stack.
The idea is this: let's use the native SSD capability for efficient I / O parallelism for I / O. Depending on how many parallel I / O streams can be used, there are fair queues through which we simply write as is on the SSD. Each CPU has its own queue for writing.
Currently blk-mq is actively developing and working. No reason not to use it. In modern kernels, from 4 and up, blk-mq gains a tangible gain - not 5-10%, but significantly more.
blk-mq is probably the best option for working with SSD.
In its current form, blk-mq is directly tied to the NVMe driver Linux. There is not only a driver for Linux, but also a driver for Microsoft. But the idea to make blk-mq and NVMe driver is the very reworking of the Linux stack, from which the databases benefited greatly.
A consortium of several companies decided to make a specification, this very protocol. Now he is already in the production version works fine for local PCIe SSD. Almost ready solution for disk arrays that are connected by optics.
The blk-mq and NVMe driver is larger than the scheduler. The system aims to replace the entire query level.
Let's dive into it to understand what it is. The NVMe specification is large, so we will not consider all the details, but just go over them.
Old elevators approach
The simplest case: there is a CPU, there is its turn, and we somehow go to disk.
More advanced Elevators worked differently. There are several CPUs and several queues. Somehow, for example, depending on which parent process the DB workers have been budding from, the IO gets into the queue and onto the disks.
New approach to elevators
blk-mq is a completely new approach. Each CPU, each NUMA zone adds its I / O to its turn. Then the data gets to the disks, it does not matter how connected, because the driver is new. There is no SD driver that operates on the concepts of cylinders, blocks.
There was a transition period. At some point, all RAID vendors began selling add-ons that allowed to bypass the RAID cache. If SSD is connected, write directly there. They disabled the use of SD drivers for their products, like blq-mq.
New stack with blk-mq
This is what the new stack looks like.
From above, everything remains as well. For example, the database is far behind. Input / output from the database, just as before, enters the Block IO-layer. There is the same blk-mq , which replaces the query layer, not the scheduler.
In the 3.13 kernel, this was about the end of all optimization, but in modern kernels new technologies are used. Special schedulers for blk-mq , which are designed for stronger parallelism, began to appear. In today's fourth Linux kernels, two schedulers IO are considered mature - Kyber and BFQ. They are designed to work with parallelism and with blk-mq .
BFQ - Budget Fair Queueing is an analogue of C FQ . They are completely different, although one grew out of another. BFQ is a complex math scheduler. Each application and process has a certain IO quota. The quota depends on the amount of IO that the process / application generates. According to this budget, we have a band to write to. How well it works is a difficult question. If you are interested in BFQ, there are lots of articles that analyze the process math.
Kyber is an alternative . It is like BFQ, but without mathematics. Kyber has a small scheduler for the amount of code. Its main task is to receive from the CPU and send. Kyber is lightweight and works better.
An important point for the entire stack - blk-mq does not look into the SD driver . It does not have another conversion layer, which I complained about when I showed how the IO stack looked before. From blk-mq to NVMe driver, everything comes immediately in finished form. Blocks in cylinders are not recalculated.
In the new approach, several interesting moments have arisen - latency has sharply dropped, including this layer. First there were SSDs that work well - it became possible to recycle this layer. As soon as we stopped converting back and forth, it turned out that both the NVMe layer and blk-mq have their bottlenecks, which also need to be optimized. Now let's talk about them.
Linux IO stack diagram
Thomas Krenn has a constantly updated and current Linux I / O stack diagram .
The diagram shows who stood over whom, the relationship between the drivers, which Elevators, which part of which layer.
The diagram is regularly updated, which helps to monitor the evolution of the kernel database administrators and other professionals who work with databases.
NVM Express Specification
NVM Express or NVMe is a specification, a set of standards that help you use SSDs more efficiently. The specification is well implemented in Linux. Linux is one of the driving forces behind the standard.
Now in the third version. The driver of this version, according to the specification, can skip around 20 GB / s for one SSD unit, and NVMe of the fifth version, which is not yet available, up to 32 GB / s . The SD driver has no interfaces or mechanisms inside to provide this bandwidth.
This specification is significantly faster than anything that happened before.
Once, databases were written under rotating disks and oriented towards them - they have indices in the form of a B-tree, for example. The question arises: are you ready for NVMe databases ? Can the DB chew such a load?
Not yet, but they are adapting. Recently there were a couple of
pwrite() about pwrite() and similar things on the PostgreSQL mailing list. PostgreSQL and MySQL developers interact with kernel developers. Of course, I would like more interaction.Latest Developments
Over the past year and a half, IO polling has been added to NVMe.
At first there were rotating discs with high latency. Then came the SSD, which is much faster. But a jamb appeared: fsync is on, recording starts, and at a very low level - deep in the driver, a request is sent directly to the piece of iron - write it down.
The mechanism was simple - sent and wait for the interrupt to be processed. Waiting for interrupt processing is not a problem compared to writing to a rotating disk. It took so long to wait for the interrupt to work as soon as the recording ended.
Since the SSD is recording very quickly, a mechanism for polling the piece of iron about the recording has appeared. In the first versions, the increase in I / O speed reached 50% due to the fact that we are not waiting for an interruption, but rather actively asking the piece of iron about the record. This mechanism is called IO polling .
It has been introduced in recent versions. In version 4.12, IO schedulers appeared, specially honed to work with blk-mq and NVMe, about which I said Kyber and BFQ . They are already officially in the core, they can be used.
Now in a usable form there is a so-called IO tagging . Basically, cloud and virtual cloud manufacturers contribute to this development. Roughly speaking, input from a specific application can be tagged and given priority. The databases are not ready for this yet, but stay tuned. I think it will be mainstream soon.
Direct IO Notes
PostgreSQL does not support Direct IO and there are a number of issues that prevent the inclusion of support . Now it is supported only for value, and only if replication is not enabled. It is required to write a lot of OS-specific code , and so far everyone has refrained from it.
Despite the fact that Linux strongly curses the idea of Direct IO and how it is implemented, all the databases go there. In Oracle and MySQL Direct IO is actively used. PostgreSQL is the only database that doesn’t transfer Direct IO.
Check list
How to protect PostgreSQL from fsync surprises:
- Configure checkpoint to be less and more.
- Set up background writer to help checkpoint.
- Ottyunit Autovacuum, so that there is no unnecessary parasitic input / output.
According to the tradition in November, we are waiting for professional developers of high-load services in Skolkovo on HighLoad ++ . There is still a month to apply for a report, but we have already accepted the first reports to the program . Subscribe to the newsletter and will learn about new topics first hand.
Source: https://habr.com/ru/post/459444/
All Articles