Top 13 Scala libraries for data analysis
Recently, the Scala language has become widely used by Data Science. It gained popularity mainly due to the appearance of Spark, which is written in Scala. In practice, often at the research stage, analysis and model creation are performed in Python, and then implemented in Scala, since this language is more suitable for production.
We have prepared a detailed overview of the most interesting libraries used to implement the tasks of machine learning and data science in Scala. Some of them are used in our educational program " Scala Data Analysis ".
For convenience, all the libraries represented in the rating were divided into 5 groups: data analysis and mathematics, NLP, visualization, machine learning, and so on.
Data Analysis and Mathematics
№1. Breeze (Commits: 3316, Contributors: 84)
The Breeze library is known as the main scientific library for Scala. It has similar things from MATLAB (in terms of data structures), and from Python, the NumPy classes. Breeze provides fast and efficient data manipulations and allows you to perform many other operations, including the following:
- Matrix and vector operations for creating, transposing, performing elementwise operations, inverting, calculating determinants and many other things.
- Probabilistic and statistical functions: from statistical distributions and calculating descriptive statistics (such as mean, variance, and standard deviation) to Markov chain models. The main packages for statistics are breeze.stats and breeze.stats.distributions.
- Optimization, which implies the study of the function for a local or global minimum. Optimization methods are stored in the breeze.optimize package.
- Linear algebra: all basic operations are based on the netlib-java library, which makes Breeze extremely fast for algebraic calculations.
- Signal processing operations. Examples of such operations in Breeze are convolution and Fourier transform, which splits a given function into a sum of sine and cosine components.
It is worth noting that Breeze also allows you to build graphs, but we'll talk about this later.
№2. Saddle (Commits: 184, Contributors: 10)
Another data tool for Scala is Saddle. This is an analogue of Pandas in Python, but only for Scala. Like the data frames in Pandas or R, Saddle is based on a frame structure (two-dimensional indexed matrix).
In total there are five basic data structures, namely:
Vec (1D vector)
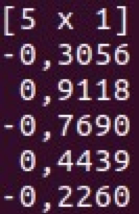
Mat (2D matrix)
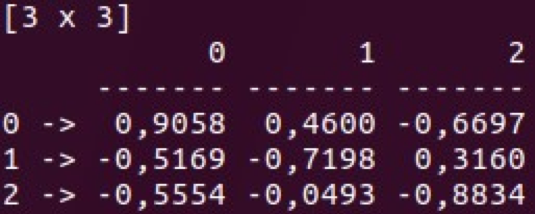
Series (1D indexed matrix)

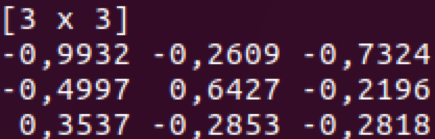
Frame (2D indexed matrix)
- Index (in the form of hashmap)
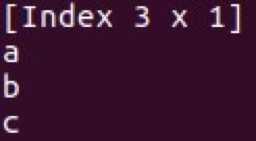
Classes Vec and Mat are located in Series and Frame. You can perform various manipulations with these data structures and use them for basic data analysis. Another great feature of Saddle is its tolerance to gaps in the data.
Number 3. ScalaLab (Commits: 23, Contributors: 1)
ScalaLab is a kind of MATLAB in Scala. Moreover, ScalaLab can directly invoke and access the results of MATLAB scripts.
The main difference from previous computation libraries is that ScalaLab uses its own domain-specific language, called ScalaSci. Scalalab is convenient because it accesses many scientific libraries of Java and Scala, so you can easily import your data and then use various methods to perform manipulations and calculations. Most things are like Breeze and Saddle. Moreover, as in Breeze, there are possibilities for constructing graphs that allow you to further interpret the data.
NLP
№4. Epic (Commits: 1790, Contributors: 15) and Puck (Commits: 536, Contributors: 1)
Scala has several good natural language processing libraries as part of ScalaNLP, including Epic and Puck. These libraries are mainly used as text analysis tools. At the same time, Puck is more convenient if it is necessary to analyze thousands of sentences due to its high speed and the use of a graphics processor. In addition, Epic is known as a forecasting framework that uses structured forecasting to build complex systems.
Visualization
№5. Breeze-viz (Commits: 29, Contributors: 3)
As the name implies, Breeze-viz is a visualization library developed by Breeze for Scala. It is based on the well-known Java library JFreeChart and creating graphs is somewhat similar to MATLAB. Although Breeze-viz has far fewer features than MATLAB, matplotlib in Python or R, it is nevertheless useful in creating models and analyzing data.
№6. Vegas (Commits: 210, Contributors: 14)
Another Scala library for data visualization is Vegas. It is much more functional than Breeze-viz, and allows you to do some transformations that are useful for graphs: filtering, transformation, and aggregation. In general, the library is similar to Bokeh and Plotly in Python.
Vegas allows you to write code in a declarative style, which makes it possible to focus mainly on determining what needs to be done with the data, and conducting further analysis of the visualizations, without worrying about the implementation of the code.

Machine learning
№7. Smile (Commits: 1019, Contributors: 21)
The Statistical Machine Intelligence and Learning Engine, or simply Smile, is a promising modern machine learning library, somewhat similar to scikit-learn in Python. It is developed in Java, but it also has an API for Scala. The library is quite fast and productive: efficient use of memory, a large set of machine learning algorithms for classification, regression, NNS, function selection, etc.

№8. Spark ML
A machine learning library that works out of the box in Apache Spark. Spark itself is written in Scala and has an appropriate API for all of its libraries.
Spark ML - in contrast to Spark MLlib (an older library), works with data frames. It also allows you to build pipelines of various transformations on your data. This can be seen as a sequence of steps, where each step is either a Transformer that converts one data frame into another, or an Estimator, for example, a machine learning algorithm that learns on a data frame.
№9. DeepLearning.scala (Commits: 1647, Contributors: 14)
DeepLearning.scala is an alternative machine learning tool that allows you to build deep learning models. The library uses mathematical formulas to create complex dynamic neural networks through a combination of object-oriented and functional programming. It uses a wide range of types as well as classes of applicative types. The latter allows you to start multiple calculations simultaneously, which improves performance.
№10. Summing Bird (Commits: 1772, Contributors: 31)
Summingbird is a data processing framework that allows you to use batch and real-time MapReduce calculations. The main catalyst for the development of the language was the Twitter developers, who often worked on writing the same code twice: first for the batch processing, then again for streaming.
Summingbird uses and generates two types of data: streams (infinite sequences of tuples) and snapshots, which at a certain point in time are considered to be the complete state of a data set. Finally, Summingbird provides a platform for Storm, Scalding and an in-memory computation engine for testing purposes.
№11. PredictionIO (Commits: 4343, Contributors: 125)
It is also worth mentioning a machine learning service for creating and deploying predictive mechanisms called PredictionIO. It is built on Apache Spark MLlib and HBase and was even rated on Github as the most popular Apache Spark based machine learning product. It allows you to easily and efficiently create, evaluate and deploy services, implement your own machine learning models and incorporate them into your service.
Other
№12. Akka (Commits: 21430, Contributors: 467)
Akka, developed by Scala, is a parallel environment for building distributed JVM applications. It uses the model based on actors (actor), where the actor is an object that receives messages and performs the appropriate actions.
The main difference is the additional level between actors and the framework, which only requires the actors to process messages, while the framework takes care of the rest. All actors are hierarchically organized, it helps actors to more effectively interact with each other and solve complex problems, dividing them into smaller tasks.
№13. Slick (Commits: 1940, Contributors: 92)
The latest library is Slick, which means the Scala Language-Integrated Connection Kit. This is a library for creating and executing queries to databases: H2, MySQL, PostgreSQL, etc. Some databases are accessible through extensions slick-extensions.
To build queries, Slick provides powerful DSL, which makes the code as if you were using Scala collections. Slick supports both simple SQL queries and strongly typed joins for several tables. In addition, simple subqueries can be used to create more complex ones.
Conclusion
In this article, we have identified and briefly described some of the Scala libraries, which can be very useful when performing basic data processing tasks.
If you have experience with any other useful Scala libraries or platforms that should be added to this list, please feel free to share them in the comments.
')
Source: https://habr.com/ru/post/459172/
All Articles