Careful error handling in microservices
The article shows how to go in Go to implement error handling and logging on the principle of "Do and forget." The method is designed for Go microservices running in a Docker container and built in compliance with the principles of Clean Architecture.
This article is a detailed version of the report from the recent Go meeting in Kazan . If you are interested in the language of Go and you live in Kazan, Innopolis, the beautiful Yoshkar-Ola or in another city nearby, you should visit the community page: golangkazan.imtqy.com .
At the mitap, our team in two reports showed how we develop microservices on Go — which principles we follow and how we simplify our lives. This article is devoted to our concept of error handling, which we now extend to all our new microservices.
Agreement on the structure of microservice
Before touching on the rules of error handling, it is worth deciding what limitations we follow when designing and coding. For this it is worth telling how our microservices look like.
First of all, we maintain pure architecture. The code is divided into three levels and we follow the rule of dependencies: packages at a deeper level do not depend on external packages and there are no cyclic dependencies. Fortunately, in Go, direct cyclic dependencies of packages are prohibited. Indirect dependencies through borrowing terminology, assumptions about behavior or coercion to type can still appear, they should be avoided.
This is how our levels look like:
- The domain level contains the business logic rules dictated by the subject area.
- sometimes we go without a domain if the task is simple
- rule: code at the domain level depends only on the capabilities of Go, the standard Go library and selected libraries that extend the Go language
- The app level contains business logic rules dictated by application tasks.
- rule: code at app level may depend on domain
- The infrastructure level contains the infrastructure code that connects the application with various storage technologies (MySQL, Redis), transport (GRPC, HTTP), interaction with the external environment and with other services.
- rule: code at infrastructure level may depend on domain and app
- rule: only one technology per go package
- The main package creates all the objects - "life time singltons", connects them to each other and runs long-lived coroutines - for example, starts processing HTTP requests from port 8081
This is the microservice directory tree (the part where the code is on Go):

For each of the application contexts (modules), the package structure looks like this:
- The app package declares the Service interface, which contains all possible actions at a given level, the service structure that implements the interface, and the
func NewService(...) Servicefunction - isolation of work with the database is achieved due to the fact that the domain or app package declares the Repository interface, which is implemented at the infrastructure level in the package with the descriptive name "mysql"
- the transport code is located in the
infrastructure/transportpackage- we use GRPC, so we have server stubs generated from a proto-file (i.e. server interface, Response / Request structures and all client interaction code)
All this is shown in the diagram:

Error handling principles
Everything is simple:
- We believe that errors and panic occur when processing requests to the API - it means that an error or panic should affect only one request.
- We believe that logs are needed only for analyzing incidents (and for debugging there is a debugger), so the log contains information about requests, and above all unexpected errors when processing requests
- We believe that a whole infrastructure is built for processing logs (for example, based on ELK) - and microservice plays a passive role in it, writing logs to stderr
We will not focus on panic: just do not forget to handle the panic in every horizontal and while processing every request, every message, every asynchronous task started by the request. Almost always, a panic can be turned into an error in order not to allow the entire application to be completed.
Idiom Sentinel Errors
At the business logic level, only the expected errors that are determined by business rules are processed. Sentinel Errors will help you identify such errors - we use this particular idiom instead of writing our own data types for errors. Example:
package app import "errors" var ErrNoCake = errors.New("no cake found") Here we declare a global variable, which, according to our gentlemen's agreement, we should not change anywhere. If you do not like global variables and you use a linter to detect them, then you can do with constants alone, as Dave Cheney suggests in the post Constant errors :
package app type Error string func (e Error) Error() string { return string(e) } const ErrNoCake = Error("no cake found") If you like this approach, you may need to add theConstErrortype toConstErrorGo corporate library.
Error composition
The main advantage of Sentinel Errors is the ability to easily compose errors. In particular, when creating an error or when receiving an error from the outside it would be good to add stacktrace to it. For such purposes there are two popular solutions.
- the xerrors package, which will be included in the standard library as an experiment in Go 1.13
- package github.com/pkg/errors by Dave Cheney
- the package is frozen and does not expand, but nevertheless it is good
Our team still uses github.com/pkg/errors and the errors.WithStack functions (when we have nothing to add except stacktrace) or errors.Wrap (when we have something to say about this error). Both functions accept an error at the input and return a new error, but now with stacktrace. Example from infrastructure layer:
package mysql import "github.com/pkg/errors" func (r *repository) FindOne(...) { row := r.client.QueryRow(sql, params...) switch err := row.Scan(...) { case sql.ErrNoRows: // stacktrace return nil, errors.WithStack(app.ErrNoCake) } } We recommend that every mistake be wrapped only once. This is easy to do if you follow the rules:
- any external errors are wrapped once in one of the infrastructure packages
- any errors generated by the rules of business logic are complemented by stacktrace at the time of creation
The root cause of the error
All errors are expectedly divided into expected and unexpected. To handle the expected error, you need to get rid of the effects of the composition. The xerrors and github.com/pkg/errors packages have everything you need: in particular, the errors package contains the errors.Cause function, which returns the root cause of the error. This function, in a loop, one after the other, extracts earlier errors, while the next extracted error has the Cause() error method.
An example to which we extract the root cause and directly compare it with the sentinel error:
func (s *service) SaveCake(...) error { state, err := s.repo.FindOne(...) if errors.Cause(err) == ErrNoCake { err = nil // No cake is OK, create a new one // ... } else if err != nil { // ... } } Error handling in defer
Perhaps you are using linter, which makes you manic checking all errors. In this case, you are probably infuriated when linter asks you to check for errors in the .Close() methods and other methods that you call only in the defer . Have you ever tried to correctly handle the error in defer, especially if before that there was another error? And we tried and hurried to share the recipe.
Imagine that we have all the work with the database is strictly through the transaction. According to the dependency rule, the app and domain levels should not directly or indirectly depend on infrastructure and SQL technology. This means that at the app and domain levels there is no word "transaction" .
The simplest solution is to replace the word "transaction" with something abstract; This is how the Unit of Work pattern is born. In our implementation, the service in the app package receives a factory through the UnitOfWorkFactory interface, and during each operation creates a UnitOfWork object hiding the transaction. The UnitOfWork object allows you to get Repository.
To better understand the use of Unit of Work, take a look at the diagram:
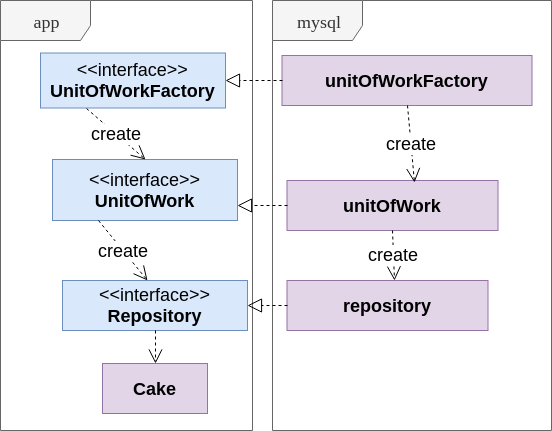
- Repository is an abstract persistent collection of objects (for example, domain-level aggregates) of a defined type.
- UnitOfWork hides the transaction and creates the Repository objects.
- UnitOfWorkFactory simply allows the service to create new transactions without knowing anything about transactions.
Is it not excessive to create a transaction for every operation, even initially atomic? You decide; We believe that maintaining the independence of business logic is more important than saving on transaction creation.
Can UnitOfWork and Repository be combined? It is possible, but we believe that this will violate the principle of Single Responsibility.
This is the interface:
type UnitOfWork interface { Repository() Repository Complete(err *error) } The UnitOfWork interface provides the Complete method, which accepts one in-out parameter: a pointer to the error interface. Yes, it is the pointer, and it is the in-out parameter - in any other cases the code on the caller will be much more complicated.
Example operation with unitOfWork:
Warning: the error must be declared as a named return value. If instead of a named return value err you use the local variable err, then you cannot use it in defer! And no linter will detect this yet - see go-critic # 801
func (s *service) CookCake() (err error) { unitOfWork, err := s.unitOfWorkFactory.New() if err != nil { return err } defer unitOfWork.Complete(&err) repo := unitOfWork.Repository() } // ... So is the completion transactions UnitOfWork:
func (u *unitOfWork) Complete(err *error) { if *err == nil { // - commit txErr := u.tx.Commit() *err = errors.Wrap(txErr, "cannot complete transaction") } else { // - rollback txErr := return u.tx.Rollback() // rollback , *err = mergeErrors(*err, errors.Wrap(txErr, "cannot rollback transaction")) } } The mergeErrors function merges two errors, but will process nil instead of one or both errors without any problems. At the same time, we believe that both errors occurred when performing one operation at different stages, and the first error is more important - therefore, when both errors are not nil, we save the first, and the second error saves only the message:
package errors func mergeErrors(err error, nextErr error) error { if err == nil { err = nextErr } else if nextErr != nil { err = errors.Wrap(err, nextErr.Error()) } return err } Perhaps you should add the function mergeErrors to your corporate library for the Go language.Logging subsystem
Check-list article : what to do before running microservices in prod advises:
- logs are written in stderr
- logs must be in JSON, one compact JSON object per line
- There should be a standard set of fields:
- timestamp - the time of the event with milliseconds , preferably in RFC 3339 format (example: "1985-04-12T23: 20: 50.52Z")
- level - the level of importance, for example, "info" or "error"
- app_name - the name of the application
- and other fields
We prefer to add two more fields to the error messages: "error" and "stacktrace" .
For the Golang language there are many quality logging libraries, for example, sirupsen / logrus , which we use. But we do not use the library directly. First of all, in our log package we reduce the extensive library interface to a single Logger interface:
package log type Logger interface { WithField(string, interface{}) Logger WithFields(Fields) Logger Debug(...interface{}) Info(...interface{}) Error(error, ...interface{}) } If a programmer wants to write logs, he should receive a Logger interface from the outside, and this should be done at the infrastructure level, not app or domain. The logger interface is concise:
- it reduces the number of importance levels to debug, info and error, as the article suggests. Let's talk about logging.
- it introduces specific rules for the Error method: the method always accepts an error object
This rigor allows you to send programmers in the right direction: if someone wants to make an improvement in the logging system itself, it must do so taking into account the entire infrastructure of their collection and processing, which only begins in microservice (and usually ends somewhere in Kibana and Zabbix).
However, there is another interface in the log package that allows you to interrupt the program when a fatal error occurs and therefore can only be used in the main package:
package log type MainLogger interface { Logger FatalError(error, ...interface{}) } Jsonlog package
Logger interface implements our jsonlog package, which configures the logrus library and abstracts work with it. Schematically looks like this:

log.Logger own package allows you to link the needs of microservice (expressed by the interface log.Logger ), the possibilities of the logrus library and the features of your infrastructure and the creation of logs.
For example, we use ELK (Elastic Search, Logstash, Kibana), and therefore in the jsonlog package we:
- set logrus format for
logrus.JSONFormatter- at the same time, we set the FieldMap option, with which we turn the
"time"field into"@timestamp", and the"msg"field - into"message"
- at the same time, we set the FieldMap option, with which we turn the
- choose log level
- add a hook that extracts the stacktrace from the
Error(error, ...interface{})object passed to theError(error, ...interface{})method
Microservice initializes the logger in the main function:
func initLogger(config Config) (log.MainLogger, error) { logLevel, err := jsonlog.ParseLevel(config.LogLevel) if err != nil { return nil, errors.Wrap(err, "failed to parse log level") } return jsonlog.NewLogger(&jsonlog.Config{ Level: logLevel, AppName: "cookingservice" }), nil } Error Handling and Logging Using Middleware
We are switching to GRPC in our microservices on Go. But even if you use the HTTP API, the general principles will suit you.
First of all, error handling and logging should occur at the infrastructure level in the transport package, because it combines the knowledge of the rules of the transport protocol and the knowledge of the app.Service interface app.Service . Recall what the packet interconnection looks like:

It is convenient to handle errors and logs using the Middleware pattern (Middleware is the name of the Decorator pattern in the world of Golang and Node.js):
Where should I add Middleware? How many should there be?
There are various options for adding Middleware, you choose:
- You can decorate the
app.Serviceinterface, but we do not recommend doing so, because this interface does not receive transport-level information, such as client IP - With GRPC, you can hang one handler for all requests (more precisely, two - unary and steam), but then all API methods will be logged in the same style with the same set of fields
- With GRPC, the code generator creates for us a server interface, in which we call the
app.Servicemethod - we decorate this interface, because it contains information of the transport level and the ability to log various API methods in different ways
Schematically looks like this:

You can create different middleware for error handling (and panic) and for logging. You can cross it all in one. We will consider an example in which everything is mated into one Middleware, which is created like this:
func NewMiddleware(next api.BackendService, logger log.Logger) api.BackendService { server := &errorHandlingMiddleware{ next: next, logger: logger, } return server } We receive the api.BackendService interface as api.BackendService and decorate it, returning our api.BackendService interface implementation as api.BackendService .
An arbitrary API method in Middleware is implemented as follows:
func (m *errorHandlingMiddleware) ListCakes( ctx context.Context, req *api.ListCakesRequest) (*api.ListCakesResponse, error) { start := time.Now() res, err := m.next.ListCakes(ctx, req) m.logCall(start, err, "ListCakes", log.Fields{ "cookIDs": req.CookIDs, }) return res, translateError(err) } Here we perform three tasks:
- Call the ListCakes method of the object to be decorated.
- Call your
logCallmethod, passing all the important information to it, including an individually selected set of fields that are logged - At the end, we replace the error by calling translateError.
Error broadcast will be discussed later. And the log entry is performed by the logCall method, which simply calls the correct Logger method:
func (m *errorHandlingMiddleware) logCall(start time.Time, err error, method string, fields log.Fields) { fields["duration"] = fmt.Sprintf("%v", time.Since(start)) fields["method"] = method logger := m.logger.WithFields(fields) if err != nil { logger.Error(err, "call failed") } else { logger.Info("call finished") } } Broadcast errors
We must get the root cause of the error and turn it into an error that is understandable at the transport level and documented in the API of your service.
In GRPC, this is easy - use the status.Errorf function to create an error with a status code. If you have an HTTP API (REST API), you can create your own type of error, which the app and domain levels do not need to know about
In the first approximation, the error broadcast looks like this:
// ! ! - err status.Error func translateError(err error) error { switch errors.Cause(err) { case app.ErrNoCake: err = status.Errorf(codes.NotFound, err.Error()) default: err = status.Errorf(codes.Internal, err.Error()) } return err } The decorated interface can return an error of type status.Status with a status code when validating input arguments, and the first version of translateError will lose this status code.
Make an improved version using the interface type conversion (long live duck typing!):
type statusError interface { GRPCStatus() *status.Status } func isGrpcStatusError(er error) bool { _, ok := err.(statusError) return ok } func translateError(err error) error { if isGrpcStatusError(err) { return err } switch errors.Cause(err) { case app.ErrNoCake: err = status.Errorf(codes.NotFound, err.Error()) default: err = status.Errorf(codes.Internal, err.Error()) } return err } The translateError function is created individually for each context (independent module) in your microservice and translates business logic errors into transport level errors.
Let's sum up
We offer you a few rules for error handling and working with logs. To follow them or not, you decide.
- Follow the principles of Clean Architecture, do not allow direct or indirect violation of the dependency rule. Business logic should depend only on the programming language, and not on external technologies.
- Use a package that offers error composition and stacktrace creation. For example, "github.com/pkg/errors" or the xerrors package, which will soon be included in the standard Go library
- Do not use third-party logging libraries in microservice - create your own library with the log and jsonlog packages, which will hide the details of the logging implementation
- Use the Middleware pattern to handle errors and write logs on the transport direction of the infrastructure level of the program
Here we didn’t say anything about query tracing technologies (for example, OpenTracing), monitoring of metrics (for example, database query performance) and other things like logging. You yourself will figure it out, we believe in you.
')
Source: https://habr.com/ru/post/459130/
All Articles