Deploying Applications on Multiple Kubernetes Clusters with Helm

How Dailymotion Uses Kubernetes: Application Deployment
We in Dailymotion started using Kubernetes in production 3 years ago. But deploying applications on several clusters is still fun, so in the past few years we have tried to improve our tools and workflows.
How did it start
Here we describe how we deploy our applications on several Kubernetes clusters around the world.
To deploy several Kubernetes objects at once, we use Helm , and all our charts are stored in the same git repository. To deploy a full stack of applications from several services, we use the so-called summary chart. In essence, this is a chart that declares dependencies and allows you to initialize the API and its services with a single command.
We also wrote a small Python script on top of Helm to do checks, create charts, add secrets and deploy applications. All these tasks are performed on the central CI platform using the docker image.
Let's get to the point.
Note. When you read this, the first release candidate for Helm 3 has already been announced. The basic version contains a whole set of improvements designed to solve some of the problems that we faced in the past.
Chart Development Workflow
For applications, we use branching, and decided to apply the same approach to charts.
- The dev branch is used to create charts that will be tested on development clusters.
- When the pull request is passed to the master , they are checked in the staging.
- Finally, we create a pull request to transfer changes to the prod branch and apply them in production.
Each environment has its own private repository that stores our charts, and we use the Chartmuseum with very useful APIs. In this way, we guarantee strict isolation between environments and checking the charts in real conditions, before using them in production.
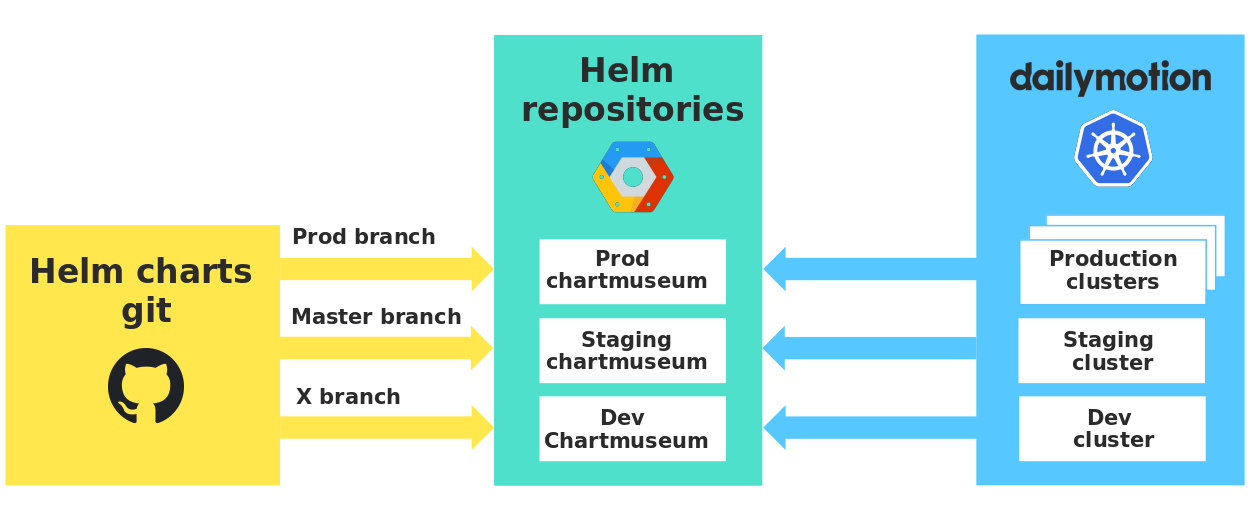
Chart repositories in different environments
It is worth noting that when developers send the dev branch, a version of their chart is automatically sent to the dev Chartmuseum. Thus, all developers use the same dev repository, and you need to carefully indicate your version of the chart in order not to accidentally use someone's changes.
Moreover, our small Python script checks Kubernetes objects against Kubernetes OpenAPI specifications using Kubeval before publishing them to Chartmusem.
General description of the workflow development chart
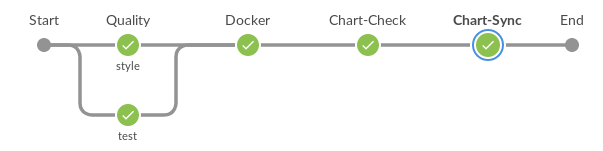
- Setting up pipeline tasks according to gazr.io specification for quality control (lint, unit-test).
- Submitting a docker image with Python tools that deploy our applications.
- Set up the environment by the name of the branch.
- Checking yaml Kubernetes files with Kubeval.
- Automatically increase the version of the chart and its parental charts (charts that depend on the variable chart).
- Sending a chart to the Chartmuseum that fits its environment
Manage Cluster Differences
Cluster Federation
There was a time when we used the Kubernetes cluster federation , where you could declare Kubernetes objects from one API endpoint. But there were problems. For example, some Kubernetes objects could not be created at the end point of the federation, so it was difficult to maintain the merged objects and other objects for individual clusters.
To solve the problem, we began to manage the clusters independently, which greatly simplified the process (using the first version of the federation; in the second, something could change).
Geo-distributed platform
Now our platform is distributed in 6 regions - 3 locally and 3 in the cloud.
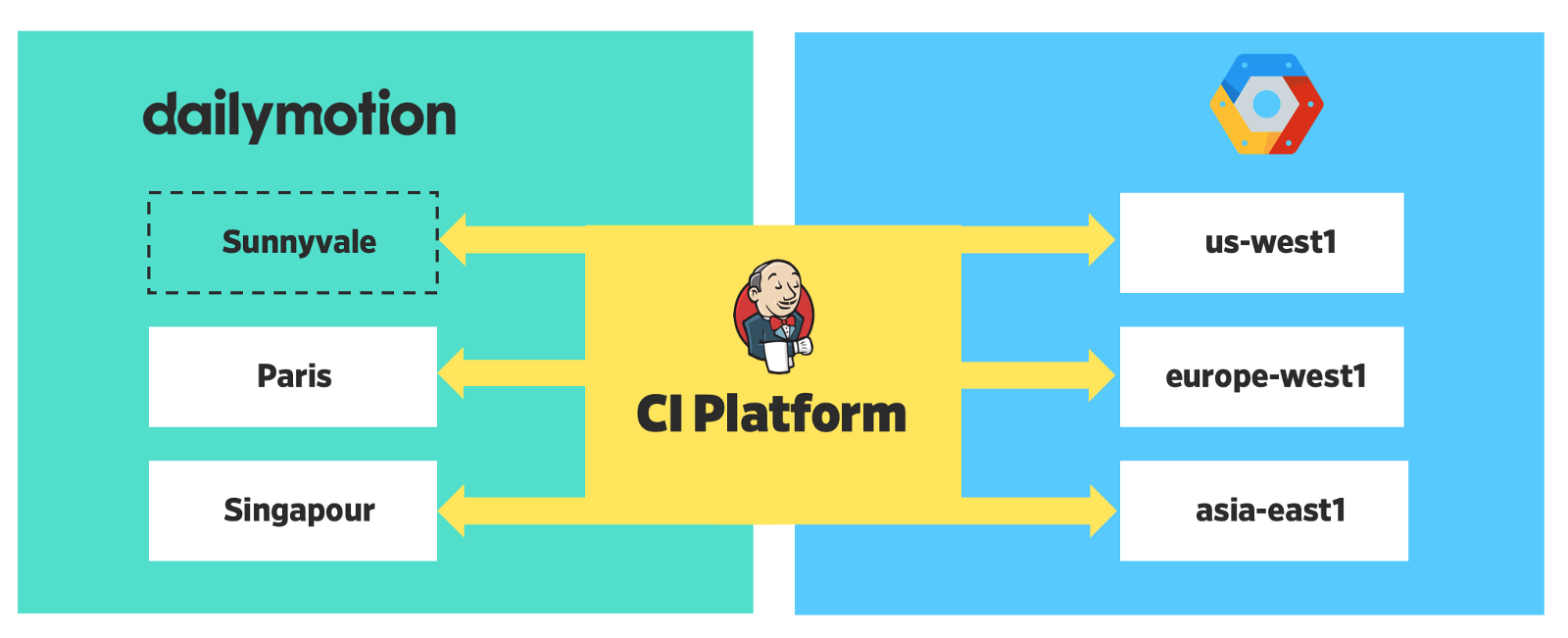
Distributed deployment
Global Helm Values
4 global Helm values allow you to identify differences between clusters. For all of our charts, there are minimal defaults.
global: cloud: True env: staging region: us-central1 clusterName: staging-us-central1 Global values
These values help define the context for our applications and are used for different tasks: monitoring, tracing, logging, making external calls, scaling, etc.
- “Cloud”: we have a hybrid platform Kubernetes. For example, our API is deployed in GCP zones and in our data centers.
- “Env”: some values may vary for non-working environments. For example, resource definitions and autoscaling configurations.
- "Region": this information helps determine the location of the cluster and can be used to determine the nearest endpoints for external services.
- "ClusterName": if and when we want to determine the value for an individual cluster.
Here is a specific example:
{{/* Returns Horizontal Pod Autoscaler replicas for GraphQL*/}} {{- define "graphql.hpaReplicas" -}} {{- if eq .Values.global.env "prod" }} {{- if eq .Values.global.region "europe-west1" }} minReplicas: 40 {{- else }} minReplicas: 150 {{- end }} maxReplicas: 1400 {{- else }} minReplicas: 4 maxReplicas: 20 {{- end }} {{- end -}} Helm Template Example
This logic is defined in an auxiliary template so as not to clutter Kubernetes YAML.
Announcement of the application
Our deployment tools are based on several YAML files. Below is an example of how we declare a service and its scaling topology (number of replicas) in a cluster.
releases: - foo.world foo.world: # Release name services: # List of dailymotion's apps/projects foobar: chart_name: foo-foobar repo: git@github.com:dailymotion/foobar contexts: prod-europe-west1: deployments: - name: foo-bar-baz replicas: 18 - name: another-deployment replicas: 3 Service definition
This is a diagram of all the steps that define our deployment workflow. The last step deploys the application simultaneously to several work clusters.
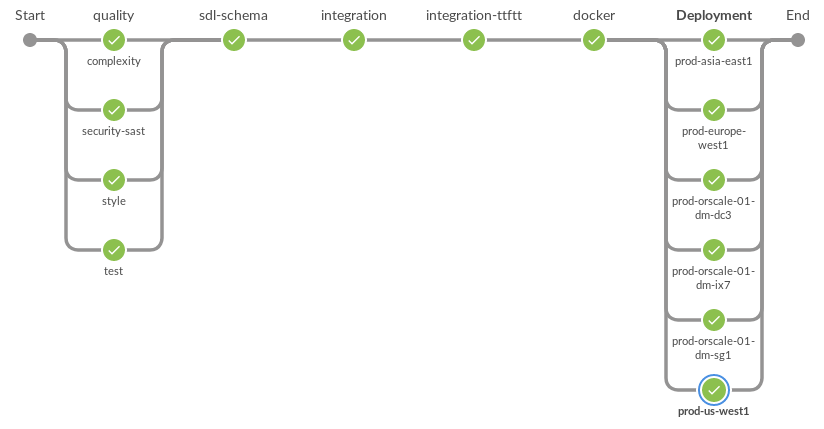
Jenkins deployment steps
And the secrets?
As for security, we keep track of all the secrets from different places and store them in a unique Vault repository in Paris.
Our deployment tools extract secrets from Vault and, when deployment times arrive, insert them into Helm.
To do this, we defined a comparison between the secrets in Vault and the secrets our applications need:
secrets: - secret_id: "stack1-app1-password" contexts: - name: "default" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password" - name: "cluster1" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password" - We defined the general rules to follow when writing secrets to Vault.
- If the secret belongs to a specific context or cluster , you need to add a specific entry. (Here the cluster1 context has its own value for stack-app1-password secret).
- Otherwise, the default value is used.
- For each item in this list, a key-value pair is inserted into the Kubernetes secret . Therefore, the secret pattern in our charts is very simple.
apiVersion: v1 data: {{- range $key,$value := .Values.secrets }} {{ $key }}: {{ $value | b64enc | quote }} {{ end }} kind: Secret metadata: name: "{{ .Chart.Name }}" labels: chartVersion: "{{ .Chart.Version }}" tillerVersion: "{{ .Capabilities.TillerVersion.SemVer }}" type: Opaque Problems and limitations
Work with multiple repositories
Now we share the development of charts and applications. This means that developers have to work in two git repositories: one for the application, and the other to determine its deployment in Kubernetes. 2 git repositories are 2 workflows and it’s easy for a beginner to get confused.
Manage the generalized charts troublesome
As we already said, generalized charts are very convenient for defining dependencies and quickly deploying multiple applications. But we use --reuse-values to avoid passing all values every time we deploy the application included in this generic chart.
In the continuous delivery workflow, we only have two values that change regularly: the number of replicas and the image tag (version). Other, more stable values are changed manually, and this is quite difficult. Moreover, one mistake in the deployment of the generalized chart can lead to serious disruptions, as we have seen from our own experience.
Update multiple configuration files
When a developer adds a new application, he has to change several files: announcement of the application, list of secrets, add an application depending on if it is included in the generalized chart.
Jenkins permissions too extended in Vault
Now we have one AppRole that reads all the secrets from Vault.
The rollback process is not automated.
For rollback, you need to execute the command on several clusters, and this is fraught with errors. We perform this operation manually in order to guarantee the correct version identifier.
We are moving towards GitOps
Our goal
We want to return the chart to the repository of the application that it deploys.
The workflow will be the same as for development. For example, when a branch is sent to the master, the deployment will start automatically. The main difference between this approach and the current workflow will be that everything will be managed in git (the application itself and the way it is deployed to Kubernetes).
There are several advantages:
- Much more understandable for the developer. It's easier to learn how to apply changes in the local chart.
- The definition of the service deployment can be specified in the same place as the service code .
- Manage the removal of generalized charts . The service will have its release Helm. This will allow you to manage the application life cycle (rollback, upgrade) at the smallest level so as not to affect other services.
- The advantages of git for managing charts are: undo changes, audit log, etc. If you need to undo a change in a chart, you can do this with git. Deployment starts automatically.
- You can think of improving your development workflow with tools like Skaffold , with which developers can test changes in a context close to production.
Two Stage Migration
Our developers have been using this workflow for 2 years now, so we need the most painless migration possible. Therefore, we decided to add an intermediate stage on the way to the goal.
The first stage is simple:
- We retain a similar structure for setting up application deployment, but in the same object called DailymotionRelease.
apiVersion: "v1" kind: "DailymotionRelease" metadata: name: "app1.ns1" environment: "dev" branch: "mybranch" spec: slack_channel: "#admin" chart_name: "app1" scaling: - context: "dev-us-central1-0" replicas: - name: "hermes" count: 2 - context: "dev-europe-west1-0" replicas: - name: "app1-deploy" count: 2 secrets: - secret_id: "app1" contexts: - name: "default" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password" - name: "dev-europe-west1-0" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password" - 1 release per application (without generalized charts).
- Charts in the git application repository.
We talked to all the developers, so the migration process has already begun. The first phase is still monitored using the CI platform. Soon I will write another post about the second stage: how we switched to the GitOps workflow with Flux . I will tell you how we set up everything and what difficulties we faced (several repositories, secrets, etc.). Follow the news.
Here we tried to describe our progress in the application deployment workflow in recent years, which has led to thoughts about the GitOps approach. We have not yet reached the goal and will report the results, but now we are convinced that we did the right thing when we decided to simplify everything and bring it closer to the habits of the developers.
')
Source: https://habr.com/ru/post/458934/
All Articles