XLNet vs. BERT
At the end of June, a team from Carnegie Mellon University showed us XLNet, immediately laying out the publication , the code and the finished model ( XLNet-Large , Cased: 24-layer, 1024-hidden, 16-heads). This is a pre-trained model for solving various problems of natural language processing.
In the publication, they immediately identified a comparison of their model with Google BERT . They write that XLNet surpasses BERT in a large number of tasks. And it shows in 18 tasks state-of-the-art results.
BERT, XLNet and Transformers
One of the latest trends in deep learning is Transfer Learning. We train models to solve simple problems on a huge amount of data, and then we use these pre-trained models, but already to solve other, more specific tasks. BERT and XLNet are just such pre-trained networks that can be used to solve natural language processing tasks.
')
These models develop the idea of transformers - the currently dominant approach to building models for working with sequences. Very detailed and with examples of the code on transformers and the attentional mechanism (Attention mechanism) is written in the article The Annotated Transformer .
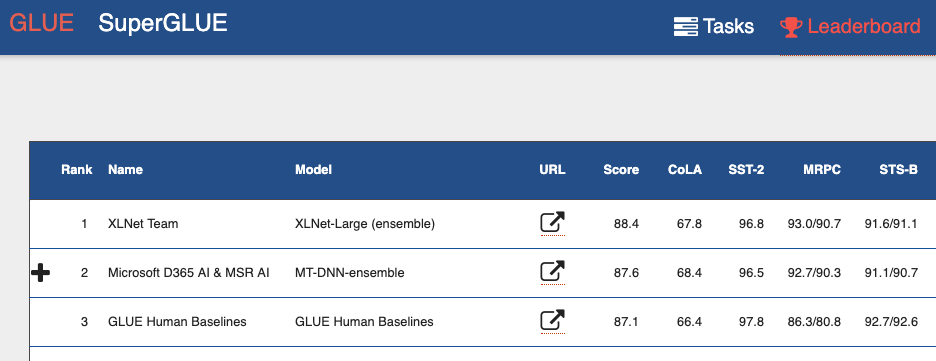
If you look at the General Language Understanding Evaluation (GLUE) benchmark Leaderboard , from the top you can see many models based on transformers. Including both models, which show the result better than man. We can say that with the transformers we see a mini-revolution in the processing of natural language.
BERT disadvantages
BERT is an auto encoder (autoencoder, AE). He hides and corrupts some words in a sequence and tries to restore the original sequence of words from the context.
This leads to shortcomings of the model:
- Each hidden word is predicted separately. We lose information about possible links between masked words. The article gives an example with the name "New York". If we try to independently predict these words by context, we will not take into account the connection between them.
- The mismatch between the phases of training the BERT model and the use of the pre-trained BERT model. When we train a model, we have hidden words ([MASK] tokens), when we use the pre-trained model, we don’t submit such tokens to it.
And yet, despite these problems, BERT showed state-of-the-art results on many natural language processing tasks.
XLNet Features
XLNet is an autoregressive model (AR LM). She tries to predict the next token by the sequence of the previous ones. In classical autoregressive models, this context sequence is taken independently from the two directions of the source line.
XLNet summarizes this method and forms the context from different places in the original sequence. How he does it. It takes all (in theory) possible permutations of the original sequence and predicts each token in the sequence according to the previous ones.
Here is an example from the article how the token x3 is predicted from various permutations of the original sequence.
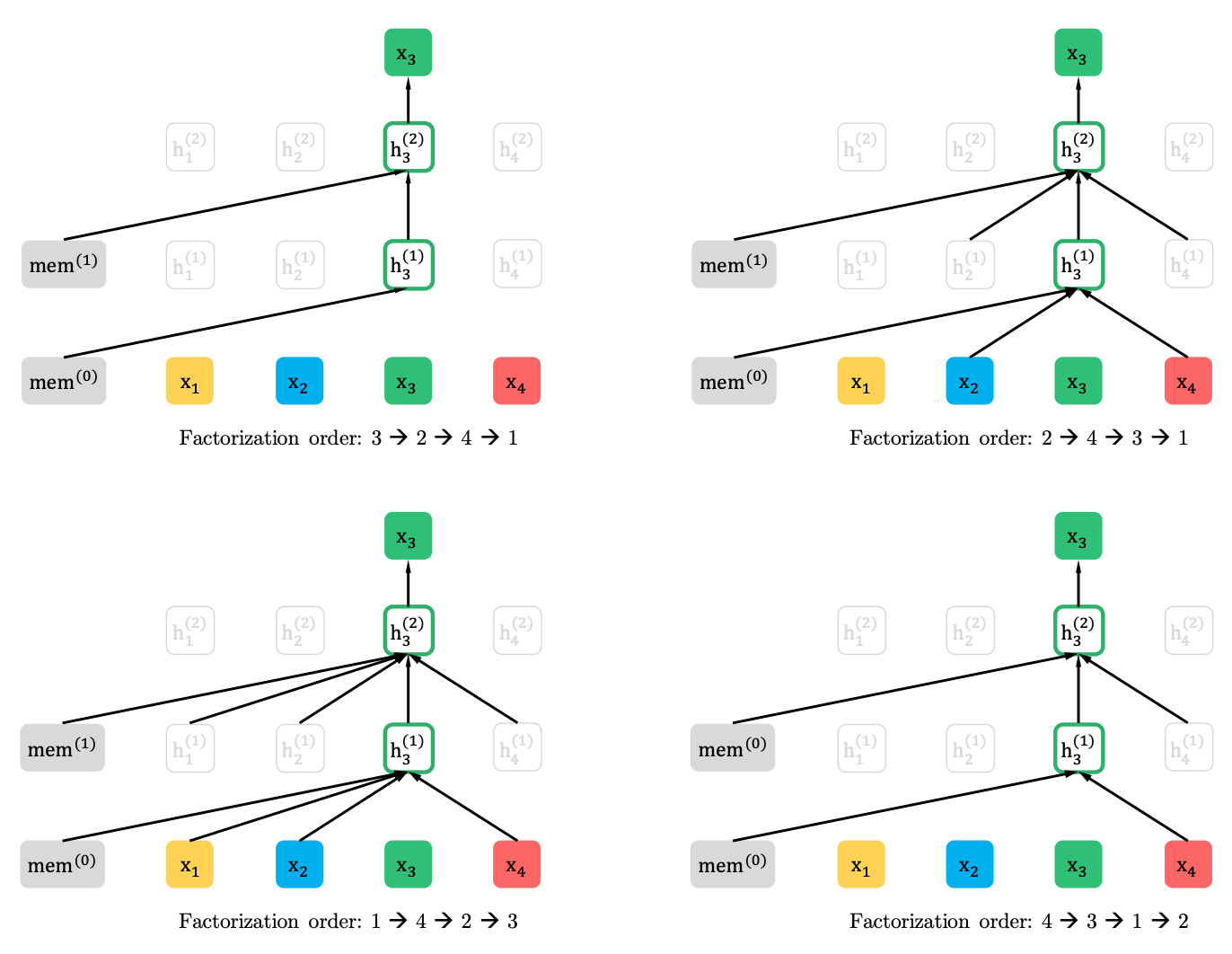
The context is not a bag of words. Information about the initial order of tokens is also supplied to the model.
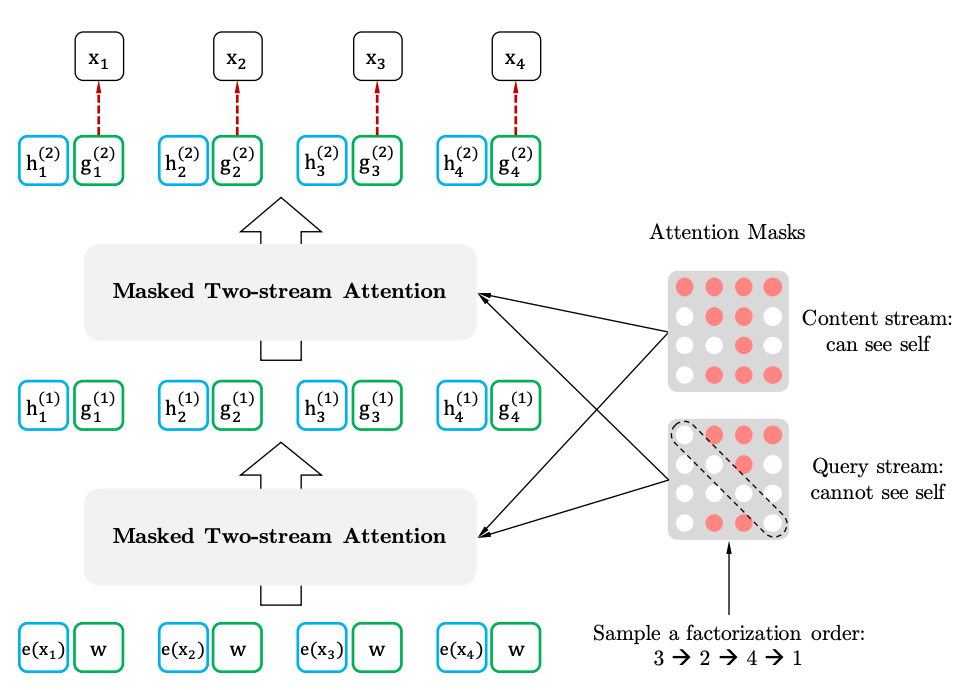
If we draw analogies with BERT, it turns out that we do not mask tokens in advance, but rather use different sets of hidden tokens for different permutations. At the same time, the second problem of BERT also disappears - the absence of hidden tokens when using a pre-trained model. In the case of XLNet, the entire sequence arrives at the input, without masks.
Where XL in the title. XL - because XLNet uses the Attention mechanism and ideas from the Transformer-XL model. Although evil tongues claim that XL hints at the amount of resources needed to train a network.
And about the resources. On Twitter, they posted a calculation of how much it would cost to train a network with parameters from the article. It turned out 245,000 dollars. True, an engineer came from Google and corrected that the article mentions 512 TPU chips, which are four on the device. That is, the cost is already 62440 dollars, or even 32720 dollars, if we take into account the 512 cores, which are also mentioned in the article.
XLNet vs. BERT
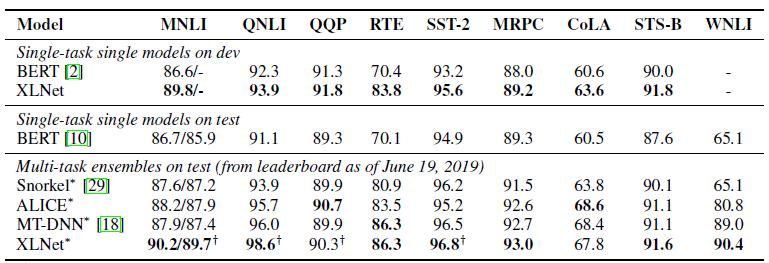
So far, only one pre-trained model for the English language has been laid out for the article (XLNet-Large, Cased). But the article mentions experiments with smaller models. And in many tasks, XLNet models show better results compared to similar BERT models.
The emergence of BERT and especially pre-trained models attracted a lot of attention from researchers and led to a huge number of related works. Now here's the XLNet. It is interesting to see whether it will for some time become the de facto standard in NLP, or vice versa, will spur researchers in search of new architectures and approaches for processing natural language.
Source: https://habr.com/ru/post/458928/
All Articles