What is GitOps?
Note trans. : After the recent publication of material about the methods of pull and push in GitOps, we saw an interest in this model as a whole, but there were very few Russian-language publications on this topic (there are simply not any at the Habré). Therefore, we are pleased to offer you a translation of another article - even if it is almost a year old! - from the company Weaveworks, the head of which coined the term “GitOps”. The text explains the essence of the approach and the key differences from the existing ones.

A year ago, we published an introduction to GitOps . Then we described how the Weaveworks team launched SaaS, based entirely on Kubernetes, and developed a set of prescriptive best practices for deploying, managing, and monitoring in a cloud native environment.
')
The article proved popular. Other people started talking about GitOps, began to publish new tools for git push , development , secrets , functions , continuous integration , etc. A large number of publications and use cases of GitOps have appeared on our website. But some people still have questions. How does the model differ from traditional infrastructure as code and continuous delivery? Do I have to use Kubernetes?
Soon we realized that a new description was needed, offering:
In this article we tried to cover all these topics. In it, you will find an updated introduction to GitOps and a look at it from the developers and CI / CD. We mainly focus on Kubernetes, although the model can be quite generalized.
Imagine Alice. She manages Family Insurance, which offers health, car, real estate and travel insurance to people who are too busy to figure out the nuances of contracts on their own. Her business began as a side project when Alice worked at the bank as a data scientist. Once she realized that she could use advanced computer algorithms for more efficient data analysis and the formation of insurance packages. Investors financed the project, and now her company brings more than $ 20 million a year and is growing rapidly. Currently, 180 people work in various positions. Among them is a technology team that develops, maintains a site, a database and analyzes customer base. The team of 60 people is headed by Bob, the company's technical director.
Bob's team deploys production systems in the cloud. Their main apps run on GKE, taking advantage of Kubernetes in Google Cloud. In addition, they use in their work various tools for working with data and analytics.
Family Insurance was not going to use containers, but it caught the enthusiasm around Docker. Soon, the company's specialists discovered that GKE allows you to deploy clusters to test new features easily and naturally. Jenkins for CI and Quay were added to organize the container registry, Jenkins scripts were written, which push or new containers and configurations in GKE.
Some time has passed. Alice and Bob were disappointed in the performance of the chosen approach and its impact on the business. The introduction of containers did not increase productivity as much as the team had hoped. Sometimes the deployment broke down, and it was unclear if the code changes were to blame. It also turned out to be difficult to track changes to configs. Often we had to create a new cluster and move applications into it, since it was the easiest way to eliminate the mess that the system had become. Alice was afraid that the situation would worsen as the application developed (besides, a new project was brewing based on machine learning). Bob automated most of the work and did not understand why the pipeline is still unstable, does not scale well, and periodically requires manual intervention?
Then they learned about GitOps. This decision turned out to be exactly what they needed to move forward with confidence.
Alice and Bob have been hearing about Git, DevOps and infrastructure as code-based workflows for years. The uniqueness of GitOps is that it introduces a number of best practices - categorical and normative - for implementing these ideas in the context of Kubernetes. This topic has been raised several times , including in the Weaveworks blog .
Family Insurance decides to implement GitOps. The company now has an automated operating model that is compatible with Kubernetes and combines speed with stability because they:
GitOps are two things:
If you are unfamiliar with version control systems and Git-based workflows, we highly recommend learning them. At first, working with branches and pull requests may seem like black magic, but the pros are worth the effort. Here is a good article to start with.
In our story, Alice and Bob turned to GitOps, having worked for a while with Kubernetes. Indeed, GitOps is closely related to Kubernetes - an operating model for infrastructure and applications based on Kubernetes.
Here are some basic features:
When the administrator makes changes to the configuration, the Kubernetes orchestrator will apply them to the cluster until his state approaches the new configuration . This model works for any Kubernetes resource and is extended with Custom Resource Definitions (CRDs). Therefore, deployment Kubernetes have the following wonderful properties:
We've learned enough about Kubernetes to explain how GitOps works.
Let's go back to the Family Insurance teams associated with microservices. What do they usually have to do? Look at the list below (if some items in it seem strange or unfamiliar - please wait a while with criticism and stay with us). These are just examples of Jenkins-based workflows. There are many other processes when working with other tools.
The main thing - we see that each update ends with making changes to the configuration files and Git repositories. These changes in Git cause the “GitOps Operator” to update the cluster:
1. Workflow: " Jenkins build - master branch ".
Task list:
2. Build Jenkins - release or hotfix thread :
3. Build Jenkins - develop or feature branch :
4. Adding a new client :
Once again: all the desired properties of the cluster must be observed in the cluster itself .
Some examples of divergence:
A few examples:
GitOps combines Git with Kubernetes' excellent convergence mechanism, offering a model for exploitation.
GitOps allows us to state: automation and control can only be those systems that can be described and monitored .
GitOps is not just Kubernetes. We want the entire system to be managed declaratively and use convergence. By the entire system, we mean a set of environments that work with Kubernetes — for example, “dev cluster 1”, “production”, etc. Each Wednesday includes machines, clusters, applications, as well as interfaces for external services that provide data, monitoring and t. n.
Notice how important Terraform is in this case for the bootstrapping problem. Kubernetes should be deployed somewhere, and using Terraform means that we can apply the same GitOps workflow to create the control layer that underlies Kubernetes and the applications. This is a useful best practice.
Much attention is paid to the application of GitOps concepts to the layers above Kubernetes. At the moment there are GitOps-type solutions for Istio, Helm, Ksonnet, OpenFaaS and Kubeflow, as well as, for example, for Pulumi, which create a layer for developing applications for cloud native.
As stated, GitOps are two things:
For many, GitOps is primarily a Git push based workflow. We like it too. But that's not all: let's look at the CI / CD pipelines now.
GitOps offers a continuous deployment mechanism that eliminates the need for separate “deployment management systems”. Kubernetes does all the work for you.
You should avoid using Kubectl to update the cluster, and in particular - scripts for grouping kubectl commands. Instead, using a GitOps Pipeline, a user can update his Kubernetes cluster via Git.
Benefits include:
GitOps improves existing CI / CD models.
A modern CI server is a tool for orchestration. In particular, it is a tool for orchestrating the CI pipelines. These include build, test, merge to trunk, etc. CI servers automate the management of complex multi-step pipelines. A common temptation is to create a script for the Kubernetes update set and execute it as part of the pipeline for push changes to the cluster. Indeed, so do many experts. However, this is not optimal, and this is why.
CI should be used to make updates to the trunk, and the Kubernetes cluster must change itself based on these updates in order to manage the CD “internally”. We call this the CD pull model , unlike the CI push model. The CD is part of a runtime orchestration .
Do not use a CI server to orchestrate direct updates to Kubernetes as a set of CI tasks. This is an anti-pattern, which we already talked about in our blog.
Let's go back to Alice and Bob.
What problems did they encounter? Bob's CI server applies the changes to the cluster, but if it drops in the process, Bob will not know what state the cluster is (or should be) and how to fix it. The same is true if successful.
Let's assume that the Bob team assembled a new image and then patched its deployments to deploy the image (all from the CI Pipeline).
If the image is collected normally, but the pipeline falls, the team will have to find out:
Organizing a Git-based workflow does not guarantee that the Bob team will not encounter these problems. They may still be wrong with the commit push, tag, or some other parameter; however, this approach is still much closer to an explicit all-or-nothing.
Summing up, this is why CI servers should not deal with a CD:
A note about Helm: if you want to use Helm, we recommend combining it with a GitOps operator, such as Flux-Helm . This will help ensure convergence. Helm itself is neither deterministic nor atomic.
The team of Alice and Bob implements GitOps and discovers that it has become much easier to work with software products and maintain high performance and stability. Let's finish this article with illustrations showing what their new approach looks like. Consider that we are mainly talking about applications and services, however GitOps can be used to manage the entire platform.
Look at the following chart. It presents Git and the container image repository as shared resources for two orchestrated life cycles:
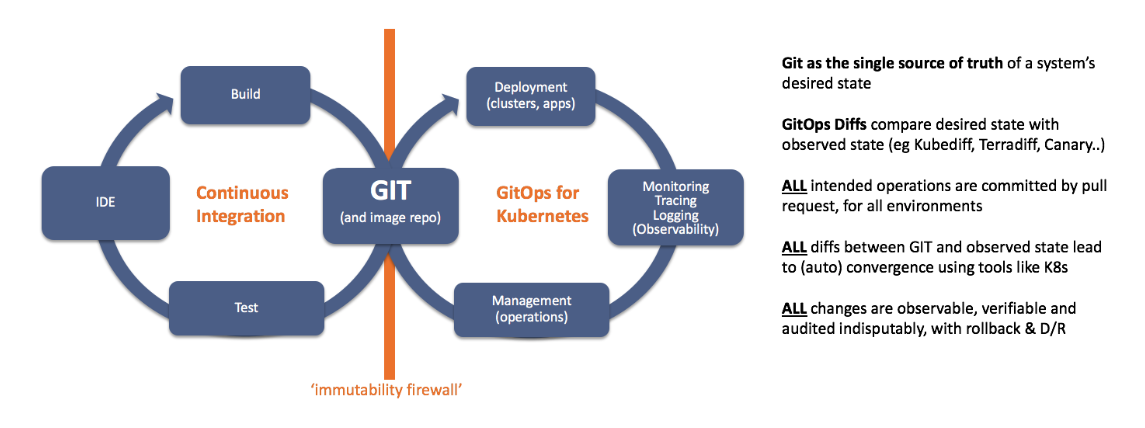

GitOps provides the essential upgrade guarantee required for any modern CI / CD tool:
This is important because it offers an exploitation model for cloud native developers.
Imagine a multitude of clusters scattered across different clouds and a multitude of services with your own teams and deployment plans. GitOps offers a scale-invariant model to manage all this abundance.
Read also in our blog:
A year ago, we published an introduction to GitOps . Then we described how the Weaveworks team launched SaaS, based entirely on Kubernetes, and developed a set of prescriptive best practices for deploying, managing, and monitoring in a cloud native environment.
')
The article proved popular. Other people started talking about GitOps, began to publish new tools for git push , development , secrets , functions , continuous integration , etc. A large number of publications and use cases of GitOps have appeared on our website. But some people still have questions. How does the model differ from traditional infrastructure as code and continuous delivery? Do I have to use Kubernetes?
Soon we realized that a new description was needed, offering:
- A large number of examples and stories;
- The specific definition of GitOps;
- Comparison with traditional continuous delivery.
In this article we tried to cover all these topics. In it, you will find an updated introduction to GitOps and a look at it from the developers and CI / CD. We mainly focus on Kubernetes, although the model can be quite generalized.
Meet GitOps
Imagine Alice. She manages Family Insurance, which offers health, car, real estate and travel insurance to people who are too busy to figure out the nuances of contracts on their own. Her business began as a side project when Alice worked at the bank as a data scientist. Once she realized that she could use advanced computer algorithms for more efficient data analysis and the formation of insurance packages. Investors financed the project, and now her company brings more than $ 20 million a year and is growing rapidly. Currently, 180 people work in various positions. Among them is a technology team that develops, maintains a site, a database and analyzes customer base. The team of 60 people is headed by Bob, the company's technical director.
Bob's team deploys production systems in the cloud. Their main apps run on GKE, taking advantage of Kubernetes in Google Cloud. In addition, they use in their work various tools for working with data and analytics.
Family Insurance was not going to use containers, but it caught the enthusiasm around Docker. Soon, the company's specialists discovered that GKE allows you to deploy clusters to test new features easily and naturally. Jenkins for CI and Quay were added to organize the container registry, Jenkins scripts were written, which push or new containers and configurations in GKE.
Some time has passed. Alice and Bob were disappointed in the performance of the chosen approach and its impact on the business. The introduction of containers did not increase productivity as much as the team had hoped. Sometimes the deployment broke down, and it was unclear if the code changes were to blame. It also turned out to be difficult to track changes to configs. Often we had to create a new cluster and move applications into it, since it was the easiest way to eliminate the mess that the system had become. Alice was afraid that the situation would worsen as the application developed (besides, a new project was brewing based on machine learning). Bob automated most of the work and did not understand why the pipeline is still unstable, does not scale well, and periodically requires manual intervention?
Then they learned about GitOps. This decision turned out to be exactly what they needed to move forward with confidence.
Alice and Bob have been hearing about Git, DevOps and infrastructure as code-based workflows for years. The uniqueness of GitOps is that it introduces a number of best practices - categorical and normative - for implementing these ideas in the context of Kubernetes. This topic has been raised several times , including in the Weaveworks blog .
Family Insurance decides to implement GitOps. The company now has an automated operating model that is compatible with Kubernetes and combines speed with stability because they:
- found that the team has doubled its productivity and no one is going crazy;
- stopped serving scripts. Instead, they can now concentrate on new features and improve engineering techniques — for example, implement canary rollouts and improve testing;
- improved the deployment process - now it rarely breaks down;
- got the opportunity to restore deployments after partial failures without manual intervention;
- gained greater confidence in delivery systems. Alice and Bob found that it is possible to divide the team into microservice groups and working in parallel;
- can make 30-50 changes to the project every day with the efforts of each group and try new equipment;
- easily attract new developers to the project, who have the ability to roll up updates to production using pull requests in just a few hours;
- easy to pass an audit within SOC2
What happened?
GitOps are two things:
- Exploitation model for Kubernetes and cloud native. It provides a set of best practices for deploying, managing, and monitoring clusters and applications assembled into containers. An elegant definition of a single slide from Luis Faceira :

- The path to creating a developer-centric application management environment. We apply the Git workflow to both exploitation and development. Please note that this is not just about Git push, but about organizing the entire CI / CD and UI / UX toolkit.
Couple of words about git
If you are unfamiliar with version control systems and Git-based workflows, we highly recommend learning them. At first, working with branches and pull requests may seem like black magic, but the pros are worth the effort. Here is a good article to start with.
How Kubernetes works
In our story, Alice and Bob turned to GitOps, having worked for a while with Kubernetes. Indeed, GitOps is closely related to Kubernetes - an operating model for infrastructure and applications based on Kubernetes.
What does Kubernetes give users?
Here are some basic features:
- In the Kubernetes model, everything can be described in a declarative form.
- The Kubernetes API server accepts such a declaration as input, and then constantly tries to bring the cluster to the state described in the declaration.
- The declarations are sufficient to describe and manage a wide variety of workloads - “applications”.
- As a result, changes to the application and cluster occur due to:
- changes in the images of containers;
- changes in the declarative specification;
- errors in the environment - for example, the fall of the containers.
Kubernetes excellent convergence abilities
When the administrator makes changes to the configuration, the Kubernetes orchestrator will apply them to the cluster until his state approaches the new configuration . This model works for any Kubernetes resource and is extended with Custom Resource Definitions (CRDs). Therefore, deployment Kubernetes have the following wonderful properties:
- Automation : Kubernetes updates provide a mechanism to automate the process of applying changes correctly and in a timely manner.
- Convergence : Kubernetes will continue to attempt upgrades until success is achieved.
- Idempotency : reapplication of convergence leads to the same result.
- Determinism : with sufficient resources, the state of the updated cluster depends only on the desired state.
How GitOps works
We've learned enough about Kubernetes to explain how GitOps works.
Let's go back to the Family Insurance teams associated with microservices. What do they usually have to do? Look at the list below (if some items in it seem strange or unfamiliar - please wait a while with criticism and stay with us). These are just examples of Jenkins-based workflows. There are many other processes when working with other tools.
The main thing - we see that each update ends with making changes to the configuration files and Git repositories. These changes in Git cause the “GitOps Operator” to update the cluster:
1. Workflow: " Jenkins build - master branch ".
Task list:
- Jenkins push'it tagged images in quay;
- Jenkins push'it config and Helm-charts in the master-storage bucket;
- The cloud function copies the config and charts from the master storage bucket to the master's Git repository;
- GitOps operator updates the cluster.
2. Build Jenkins - release or hotfix thread :
- Jenkins push 'untagged images on Quay;
- Jenkins push'it config and Helm-charts in the staging-storage buck;
- The cloud function copies the config and charts from the staging storage bucket to the staging Git repository;
- GitOps operator updates the cluster.
3. Build Jenkins - develop or feature branch :
- Jenkins push 'untagged images on Quay;
- Jenkins push'it config and Helm-charts in bucket develop-storage;
- The cloud function copies the config and charts from the develop-storage bucket to the develop git repository;
- GitOps operator updates the cluster.
4. Adding a new client :
- The manager or administrator (LCM / ops) calls Gradle to initially deploy and configure network load balancers (NLB);
- LCM / ops commits a new config to prepare the deployment for updates;
- GitOps operator updates the cluster.
GitOps Short Description
- Describe the desired state of the entire system using declarative specifications for each environment (in our history, the Bob team defines the entire system configuration in Git).
- The git repository is the only source of truth regarding the desired state of the entire system.
- All changes to the desired state are made by commits to Git.
- All desired cluster parameters are also observable in the cluster itself. Thus, we can determine whether the desired and observable states differ (converge, converge ) or differ ( diverge , diverge ).
- If the desired and observed states are different, then:
- There is a convergence mechanism that sooner or later automatically synchronizes the target and the observed state. Inside the cluster, Kubernetes does this.
- The process starts immediately with a “change committed” alert.
- After some customizable period of time, a “diff” alert may be sent if the states are different.
- Thus, all commits in Git cause checked and idempotent updates in the cluster.
- A pullback is a convergence to a previously desired state.
- Convergence is final. About its occurrence testify:
- No diff notifications for a certain period of time.
- A “converged” alert (for example, a webhook, a git writeback event).
What is divergence?
Once again: all the desired properties of the cluster must be observed in the cluster itself .
Some examples of divergence:
- Change in configuration file due to merging branches in git.
- Change in configuration file due to a commit in Git made by a GUI client.
- Multiple changes in the desired state due to PR in Git with the subsequent assembly of the container image and changes in the config.
- A change in cluster status due to an error, a conflict of resources leading to a “bad behavior”, or simply a random deviation from the original state.
What is the convergence mechanism?
A few examples:
- For containers and clusters, the convergence mechanism is provided by Kubernetes.
- The same mechanism can be used to manage Kubernetes-based applications and constructs (for example, Istio and Kubeflow).
- The mechanism for managing the working interaction between Kubernetes, the image repositories and Git is provided by the GitOps Weave Flux operator , which is part of the Weave Cloud .
- For base machines, the convergence mechanism must be declarative and autonomous. In our experience, we can say that Terraform is closest to this definition, but it still requires human control. In this sense, GitOps extends the traditions of Infrastructure as Code.
GitOps combines Git with Kubernetes' excellent convergence mechanism, offering a model for exploitation.
GitOps allows us to state: automation and control can only be those systems that can be described and monitored .
GitOps is intended for the entire cloud native stack (for example, Terraform, etc.)
GitOps is not just Kubernetes. We want the entire system to be managed declaratively and use convergence. By the entire system, we mean a set of environments that work with Kubernetes — for example, “dev cluster 1”, “production”, etc. Each Wednesday includes machines, clusters, applications, as well as interfaces for external services that provide data, monitoring and t. n.
Notice how important Terraform is in this case for the bootstrapping problem. Kubernetes should be deployed somewhere, and using Terraform means that we can apply the same GitOps workflow to create the control layer that underlies Kubernetes and the applications. This is a useful best practice.
Much attention is paid to the application of GitOps concepts to the layers above Kubernetes. At the moment there are GitOps-type solutions for Istio, Helm, Ksonnet, OpenFaaS and Kubeflow, as well as, for example, for Pulumi, which create a layer for developing applications for cloud native.
Kubernetes CI / CD: Comparing GitOps with Other Approaches
As stated, GitOps are two things:
- The exploitation model for Kubernetes and cloud native, described above.
- The path to organizing a developer-centric application management environment.
For many, GitOps is primarily a Git push based workflow. We like it too. But that's not all: let's look at the CI / CD pipelines now.
GitOps provides continuous deployment (CD) under Kubernetes
GitOps offers a continuous deployment mechanism that eliminates the need for separate “deployment management systems”. Kubernetes does all the work for you.
- Updating an application requires updating in Git. This is a transactional update to the desired state. Deployment is then carried out within the cluster by Kubernetes itself based on the updated description.
- Due to the nature of Kubernetes, these updates are convergent. This provides a mechanism for continuous deployment in which all updates are atomic.
- Note: Weave Cloud offers a GitOps operator that integrates Git and Kubernetes and allows you to run a CD by matching the desired and current status of the cluster.
No kubectl and scripts
You should avoid using Kubectl to update the cluster, and in particular - scripts for grouping kubectl commands. Instead, using a GitOps Pipeline, a user can update his Kubernetes cluster via Git.
Benefits include:
- Correctness The update group can be applied, converged and finally validated, which brings us closer to the goal of atomic deployment. On the contrary, the use of scripts does not give any guarantees of convergence (more on this below).
- Safety To quote Kelsey Hightower: “Restrict access to the Kubernetes cluster to automation tools and administrators who are responsible for debugging it or maintaining its functionality.” See also my security and compliance statement, and the Homebrew hacking article by stealing credentials from a carelessly written Jenkins script.
- User experience Kubectl exposes the mechanics of the Kubernetes object model, which is quite complex. Ideally, users should interact with the system at a higher level of abstraction. Here I refer again to Kelsey and recommend viewing this summary .
Difference between CI and CD
GitOps improves existing CI / CD models.
A modern CI server is a tool for orchestration. In particular, it is a tool for orchestrating the CI pipelines. These include build, test, merge to trunk, etc. CI servers automate the management of complex multi-step pipelines. A common temptation is to create a script for the Kubernetes update set and execute it as part of the pipeline for push changes to the cluster. Indeed, so do many experts. However, this is not optimal, and this is why.
CI should be used to make updates to the trunk, and the Kubernetes cluster must change itself based on these updates in order to manage the CD “internally”. We call this the CD pull model , unlike the CI push model. The CD is part of a runtime orchestration .
Why CI servers should not make a CD through direct updates to Kubernetes
Do not use a CI server to orchestrate direct updates to Kubernetes as a set of CI tasks. This is an anti-pattern, which we already talked about in our blog.
Let's go back to Alice and Bob.
What problems did they encounter? Bob's CI server applies the changes to the cluster, but if it drops in the process, Bob will not know what state the cluster is (or should be) and how to fix it. The same is true if successful.
Let's assume that the Bob team assembled a new image and then patched its deployments to deploy the image (all from the CI Pipeline).
If the image is collected normally, but the pipeline falls, the team will have to find out:
- Has the update unfolded?
- Are we launching a new build? Will this lead to unnecessary side effects - with the ability to get two assemblies of the same unchanging image?
- Should we wait for the next update before running the build?
- What exactly went wrong? What steps need to be repeated (and which ones are safe to repeat)?
Organizing a Git-based workflow does not guarantee that the Bob team will not encounter these problems. They may still be wrong with the commit push, tag, or some other parameter; however, this approach is still much closer to an explicit all-or-nothing.
Summing up, this is why CI servers should not deal with a CD:
- Update scripts are not always deterministic; they are easy to make mistakes.
- CI servers do not converge to a declarative cluster model.
- Difficult to guarantee idempotency. Users must understand the deep semantics of the system.
- More difficult to recover from a partial failure.
A note about Helm: if you want to use Helm, we recommend combining it with a GitOps operator, such as Flux-Helm . This will help ensure convergence. Helm itself is neither deterministic nor atomic.
GitOps as the best way to implement Continuous Delivery for Kubernetes
The team of Alice and Bob implements GitOps and discovers that it has become much easier to work with software products and maintain high performance and stability. Let's finish this article with illustrations showing what their new approach looks like. Consider that we are mainly talking about applications and services, however GitOps can be used to manage the entire platform.
Operation Model for Kubernetes
Look at the following chart. It presents Git and the container image repository as shared resources for two orchestrated life cycles:
- A continuous integration pipeline that reads and writes files to Git and can update the repository of container images.
- Pipeline Runtime GitOps, combining deploy with control and observability. It reads and writes files to Git and can load images of containers.
What are the main findings?
- Separation of problems : Please note that both pipelines can exchange data only by updating Git or the image repository. In other words, there is a firewall between the CI and the runtime environment. We call it the immutability firewall , because all the repository updates create new versions. For more information on this topic, see slides 72-87 of this presentation .
- You can use any CI and Git server : GitOps works with any components. You can continue to use your favorite CI and Git servers, image repositories and test suites. Almost all other tools for Continuous Delivery on the market require their own CI / Git server or image storage. This may be a limiting factor in the development of cloud native. In the case of GitOps, you can use familiar tools.
- Events as an integration tool : As soon as the data in Git is updated, Weave Flux (or the operator of the Weave Cloud) notifies about this runtime. Whenever Kubernetes accepts a change set, Git is updated. This provides a simple integration model for organizing workflows for GitOps, as shown below.
Conclusion
GitOps provides the essential upgrade guarantee required for any modern CI / CD tool:
- automation;
- convergence;
- idempotency;
- determinism.
This is important because it offers an exploitation model for cloud native developers.
- Traditional tools for managing and monitoring systems are associated with operating teams that operate within the runbook (set of routine procedures and operations - approx. Transl.) , Tied to a specific deployment.
- In managing cloud native systems, monitoring tools are the best way to evaluate deployment results so that the development team can respond to them quickly.
Imagine a multitude of clusters scattered across different clouds and a multitude of services with your own teams and deployment plans. GitOps offers a scale-invariant model to manage all this abundance.
PS from translator
Read also in our blog:
Source: https://habr.com/ru/post/458878/
All Articles