Patience and labor all text will extract
During the training session (May-June and December-January), users ask us to check for the presence of borrowing up to 500 documents every minute. Documents come in files of various formats, the complexity of working with each of them is different. To check the document for borrowing, we first need to extract its text from the file, and at the same time to deal with formatting. The task is to implement high-quality extraction of half a thousand texts with formatting per minute, while falling infrequently (and it is better not to fall at all), consume few resources and do not pay for the development and operation of the final creation half of the galactic budget.
Yes, yes, we, of course, know that from three things - quickly, cheaply and efficiently - you need to choose any two. But the worst thing is that in our case we can not cross out. The question is how well we did it ...

Image source: Wikipedia
We are often told that the fate of people depends on the quality of our work. Therefore it is necessary to cultivate perfectionists in oneself. Of course, we are constantly improving the quality of the system (in all aspects), as unscrupulous authors come up with new ways to get around. And I hope that the day is close when the complexity of deception, on the one hand, and a feeling of satisfaction from a quality job, on the other, will induce an absolute majority of students to give up their favorite desire to cheat. At the same time, we understand that the price of error may be the possible suffering of innocent people, if we suddenly cheat.
Why am I doing this? If we were perfectionists, we would thoughtfully approach the writing of a series of articles on the work of the Antiplagiat system . We would painstakingly formulate a publication plan in order to present everything in the most logical and expected way for the reader:
- First, we would talk about how our system works (the fifth publication on Habré), and describe the three main stages of processing a document when it is checked for borrowing:
- Extract the text of the document (you are here!);
- Search for borrowing (pieces already exist in several of our articles );
- Building a report on the document (in the plans).
- Further, we would begin to initiate the reader into the device of interesting auxiliary mechanisms, such as the search for transferable borrowings ( first article ), the definition of paraphrase ( fourth ) and thematic classification ( second ).
- And finally, we got to the search engine - the index of shingles ( seventh article ).
The attentive reader probably noticed that we still do not suffer from excessive perfectionism, so the time has come to consider the first stage - extracting text and formatting documents. We will deal with this today, thinking about the frailty of being and the light at the end of the tunnel, about the non-existence of anything ideal and about striving for perfection, about having a plan and following it and about compromises that we always incline towards life.
In the beginning was the word
First, we extracted from the documents only the most necessary things to check for borrowing - the text of the documents themselves. Main formats were supported - docx, doc, txt, pdf, rtf, html. Then less common ppt, pptx, odt, epub, fb2, djvu were added, however, it was necessary to refuse to work with most of them in the future . Each of them was processed in its own way - somewhere by a separate library, somewhere by its parser. On average, text extraction took about hundreds of milliseconds. It would seem that the main and almost the only difficulty in extracting text is the “parsing” of the format itself, which is especially important for binary pdf and doc formats (and the proprietary nature of the latter makes working with it even more problematic). However, already at this stage, when our desires were limited only to extracting the text, it became clear that any way of reading the formats we need brings with it a number of unpleasant features. The most significant of them are:
- There are exceptions even when processing some valid documents, not to mention processing incorrectly formed “broken” documents. Even more problems are caused by the fact that the native code can fall, and the handling of such situations in the .net code is difficult;
- Inadequately high memory consumption, which can hurt both neighboring processes and the current processing "problem" document (out of memory in a managed or unmanaged code);
- Document processing is too long, which is aggravated by the lack of cancellation mechanisms for most libraries, and sometimes by the complexity (read: almost impossible) of canceling the unmanaged code from the managed one;
- "Text extraction from documents." The formation of the text of the pdf-document (and this format is the key for us), the parsing of which has already been done, contrary to expectations, is not a trivial task. The fact is that the pdf format was originally developed primarily for the electronic presentation of printing materials. The text in pdfs is a set of text blocks located on the pages of the document. Moreover, a block can be a paragraph of text, or a single character. The task of restoring text in its original form from a given set of blocks falls on the library (code / program) that reads the document. Yes, the format, starting with a certain version of it, provides the ability to set the order of the blocks, but, unfortunately, documents with a marked order of text blocks are quite rare. Therefore, libraries of reading text pdf'ok contain a number of heuristics (well, it’s standard here: machine learning,
bigdata, blockchain, ...), allowing to restore the text in one form or another with the exact accuracy, and, as expected, the result is different from library to library .

Source of the bottom image: Article
Upper Image Source: Hmm ...
Need more data!
If for analyzing a document for borrowing, we had enough textual background of the document, then the implementation of a number of new features is impossible or very difficult without extracting additional data from the document. Today, in addition to the text substrate, we also extract the formatting of the document and render the images of the pages. We use the latter for optical text recognition ( OCR ), as well as for defining some varieties of detours.
Document formatting includes the geometric arrangement of all words and characters on the pages, as well as the font size of all characters. This information allows us to:
- Beautifully display the report on the verification of the document, drawing the borrowings found directly on the original document;

- Determine document blocks (title page, bibliography ) with greater accuracy and extract its metadata (authors, title of work, year and place of work, etc.);
- Detect attempts to bypass the system.
To unify the processing of documents and a set of extracted data, we convert documents of all formats supported by us into pdf. Thus, the procedure for extracting document data is performed in two stages:
- Document conversion to pdf;
- Extract data from pdf.
Convert to pdf. Library selection
Since it is not so easy to take and convert a document into pdf, we decided not to reinvent the wheel and explore the ready-made solutions, choosing the most suitable for us. It was back in 2017.
Candidate selection criteria:
- Library on .net, ideally - .net core and cross-platformSpoiler!As a result, at that time, the ideal was unreachable.
- Support for required formats - doc, docx, rtf, odf, ppt, pptx
- Stability
- Performance
- Quality technical support
- Issue price
We analyzed the available solutions, selecting among them the 6 most appropriate for our tasks:
| Library | Surface problems |
|---|---|
| MS Word. Interop | Requires: MS Word. Call Microsoft Word via COM. The method has many drawbacks: the need to install MS Word, instability, poor performance. There are licensing restrictions. |
| DevExpress (17) | Does not support ppt, pptx |
| Groupdocs | - |
| Syncfusion | Does not support ppt, pptx, odt |
| Neevia Document Converter Pro | Requires: MS Word. Does not support odt |
| DynamicPdf | Requires: MS Word, Internet Explorer. Does not support odt |
MS Word Interop, Neevia Document Converter Pro and DynamicPdf require the installation of MS Office on production, which could permanently and permanently link us to Windows. Therefore, we no longer considered these options.
Thus, we have three main candidates, and only one of them fully supports all the formats we need. Well, it's time to see what they can do.
To test the libraries, we have formed a sample of 120,000 real user documents, the ratio of formats in which roughly corresponds to what we see every day in production.
So, the first round. Let's see what percentage of documents can be successfully converted into pdf by the libraries in question. Successfully, in our case, is not throwing an exception, meeting a 3-minute timeout and returning a non-empty text.
| Converter | Success (%) | Not successful (%) | ||||
|---|---|---|---|---|---|---|
| Total | Blank text | Exception | Timeout (3 minutes) | Process crash | ||
| Groupdocs | 99.012 | 0.988 | 0.039 | 0.873 | 0.076 | 0 |
| DevExpress | 99.819 | 0.181 | 0.123 | 0.019 | 0.039 | 0 |
| Syncfusion | 98.358 | 1.632 | 0.039 | 0.848 | 0.745 | 0.01 |
Syncfusion immediately stood out, which not only was able to successfully process the smallest number of documents, but also dumped the entire process on some documents (by generating exceptions like OutOfMemoryException or exceptions from the native code that were not caught without dancing with a tambourine).
GroupDocs could not process approximately 5.5 times more documents than DevExpress (everything can be seen on the table above). This is despite the fact that GroupDocs has a license for one developer approximately 9 times more expensive than a license for one developer from DevExpress. This is so, by the way.
The second serious test is the conversion time, the same 120 thousand documents:
| Converter | Mean (sec.) | Median (sec.) | Std (sec.) |
|---|---|---|---|
| Groupdocs | 1.301966 | 0.328000 | 6.401197 |
| DevExpress | 0.523453 | 0.252000 | 1.781898 |
| Syncfusion | 8.922892 | 4.987000 | 12.929588 |
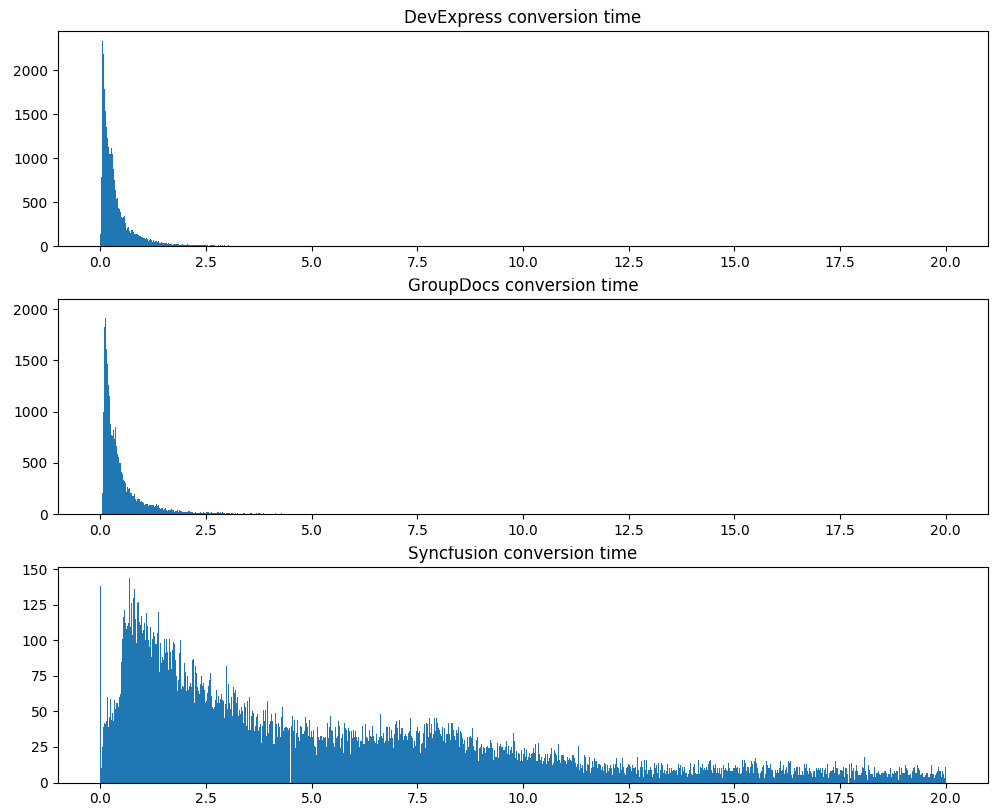
Note that DevExpress not only processes documents on average much faster, but also shows a much more stable processing time.
But the stability and processing speed mean nothing if the output is a bad pdf. Maybe DevExpress skips half the text? We are checking. So, the same 120 thousand documents, this time we calculate the total amount of extracted text and the average share of vocabulary words (the more extracted words are dictionary, the less garbage / incorrectly extracted text):
| Converter | Total amount of text (in characters) | Average share of vocabulary words |
|---|---|---|
| Groupdocs | 6 321 145 966 | 0.949172 |
| DevExpress | 6 135 668 416 | 0.950629 |
| Syncfusion | 5,995,008,572 | 0.938693 |
Partly the assumption turned out to be true. As it turned out, GroupDocs, unlike DevExpress, can work with footnotes. DevExpress simply skips them when converting a document to pdf. By the way, yes, the text from the received pdf'ok in all cases is retrieved by means of DevExpress.
So, we have studied the speed and stability of the libraries in question, now we will carefully evaluate the quality of the conversion of pdf documents. To do this, we will analyze not just the volume of the extracted text and the share of vocabulary words in it, but we will compare the texts extracted from the received pdf's with the texts of the pdf'ok obtained through MS Word. We accept the result of converting a document via MS Word for the reference pdf . For this test about 4500 pairs of “ document, reference pdf'ka ” were prepared.
| Converter | Text extracted (%) | Proximity to the length of the text | Proximity in word frequency | ||||
|---|---|---|---|---|---|---|---|
| The average | Median | SKO | The average | Median | SKO | ||
| Groupdocs | 99.131 | 0.985472 | 0.999756 | 0.095304 | 0.979952 | 1.000000 | 0.102316 |
| DevExpress | 99.726 | 0.971326 | 0.996647 | 0.075951 | 0.965686 | 0.996101 | 0.082192 |
| Syncfusion | 89.336 | 0.880229 | 0.996845 | 0.306920 | 0.815760 | 0.998206 | 0.348621 |
For each pair of “ reference pdf, conversion result ” we calculated the similarity by the length of the extracted text and by the frequencies of the extracted words. Naturally, these metrics were obtained only in cases where the conversion was successful. Therefore, we do not consider the results of Syncfusion here. DevExpress and GroupDocs showed similar performance. On the DevExpress side, a significantly higher percentage of successful conversion, on the GD side, correct work with footnotes.
Given the results, the choice was obvious. We still use the solution from DevExpress and will soon plan to upgrade to its 19th version.
There is a PDF, extract text with formatting
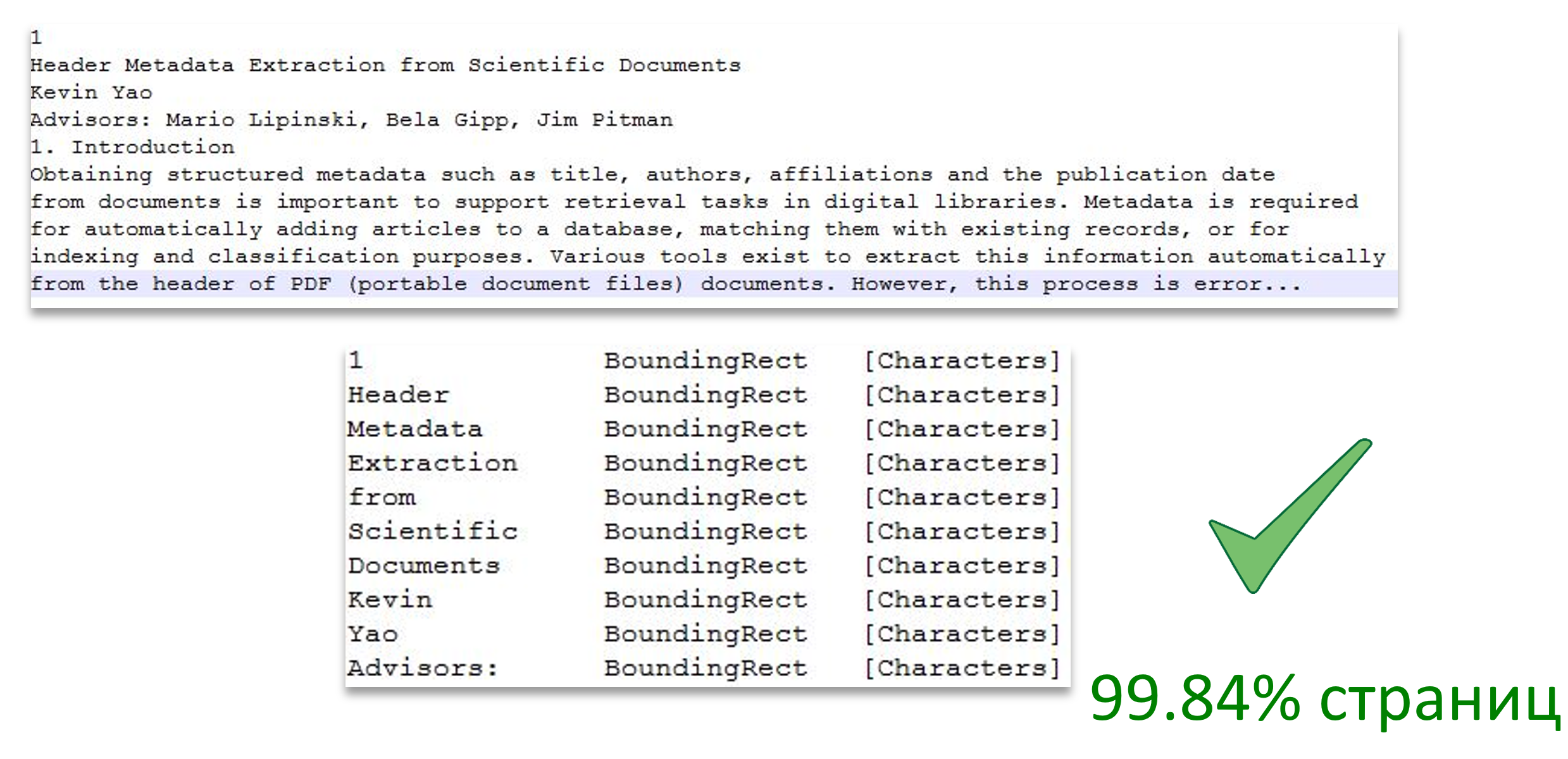
So, we can convert documents to pdf. Now we are faced with another task: using DevExpress to extract text, knowing all the information we need about each word. Namely:
- On which page the word;
- The location of the word on the page (framing rectangle);
- The font size of the word (characters of the word).
The image shows a breakdown of the text into pages, and also illustrates the correspondence of the words of the text of the page area.

Image Source: Header Metadata Extraction from Scientific Documents
It would seem that everything should be simple. We look, what API provides us DevExpress:
- We have a method that returns the text of the entire document. Plain string ;
- We have the ability to iterate through the words of the document. For each word we can get:
- Word text;
- The page on which the word is located;
- Framing a word rectangle;
- Information on individual characters of the word (the value of the symbol, the framing rectangle, the font size, ...).
Okay, everything seems to be there. But how to get the necessary data for each word in the text of the document, which returns DevExpress? We don’t really want to collect the text of a document from words, because, for example, we don’t have information, where between words is just a space, and where is a line break. We'll have to come up with heuristics based on the location of the words ... The text is here, we have already assembled it.

Image source: Eureka!
The obvious solution is to match the words with the text of the document. We look - indeed, in the text of the document the words are arranged in the same order in which the iterator returns them by the words of the document.
We quickly implement a simple word matching algorithm with the text of the document, we add checks that everything is correctly matched, we start ...
Indeed, on the vast majority of pages, everything works correctly, but, unfortunately, not on all pages.

Upper Image Source: Are you sure?
On the part of the documents, we see that the words in the text are not in the order in which they go when iterating through the words of the document. Moreover, it is clear that the opening square bracket in the text in the word list is represented as a closing bracket and is located in another “word”. The correct display of this text fragment can be seen by opening the document in MS Word. What is even more interesting, if the document is not converted into pdf, and the text is directly extracted from the doc, then we get the third version of the text fragment, which does not coincide with either the correct order or the two other orders received from the library. In this fragment, as well as in the majority of others, on which a similar problem arises, it is the case of invisible “RTL” symbols that change the order of the adjacent symbols / words.
Here it is worth remembering that the quality of technical support was called important when choosing a library. As practice has shown, in this aspect, the interaction with DevExpress is quite effective. The problem with the submitted document was promptly corrected after we created the corresponding ticket. A number of other issues related to exceptions / high memory consumption / long processing of documents were also fixed.
However, while DevExpress does not provide a direct way to get the text with the right information for each word, we continue to compare the sometimes incomparable. If we are unable to construct an exact match between the words and the text, we use a series of heuristics that allow small permutations of the words. If nothing has helped - the document is left without formatting. Rarely, but it happens.
Until :)
')
Source: https://habr.com/ru/post/458842/
All Articles