Is the Python GIL already dead?
Hello! Next Monday, classes will begin in the new Python Developer group , which means that we have time to publish another interesting material, which we will now do. Enjoy your reading.

Back in 2003, Intel released the new Pentium 4 “HT” processor. This processor overclocked to 3GHz and supported hyperthreading technology.
')

In the following years, Intel and AMD struggled to achieve the highest performance of desktop computers, increasing bus speed, L2 cache size and decreasing matrix size to minimize latency. In 2004, the HT model with a frequency of 3 GHz was replaced by 580 Prescott models with overclocking to 4 GHz.
It seemed that to go ahead you just had to increase the clock frequency, but the new processors suffered from high power consumption and heat dissipation.
Does your desktop processor have 4 GHz today? It is unlikely, because the path to improved performance ultimately led through increased bus speed and an increase in the number of cores. In 2006, Intel Core 2 replaced the Pentium 4 and had a much lower clock speed.
In addition to the release of multi-core processors for a wide user audience in 2006, something else happened. Python 2.5 finally saw the light! It has already been delivered with the beta version of the with keyword, which you all know and love.
Python 2.5 had one major limitation when it came to using Intel Core 2 or AMD Athlon X2.
It was a GIL.
GIL (Global Interpreter Lock) is a Boolean value in the Python interpreter, protected by a mutex. The blocking is used in the main CPython bytecode calculation loop to determine which stream is currently executing instructions.
CPython supports the use of multiple streams in the same interpreter, but streams must request access to GIL in order to perform low-level operations. In turn, this means that Python developers can use asynchronous code, multithreading and no longer worry about blocking any variables or processor-level faults during deadlocks.
GIL simplifies multithreaded programming in Python.

GIL also tells us that while CPython can be multi-threaded, only one thread can be executed at any time. This means that your quad-core processor does something like this (except for the blue screen, I hope).
The current version of GIL was written in 2009 to support asynchronous functions and remained intact even after many attempts to remove it in principle or change the requirements for it.
Any suggestion to remove GIL was justified by the fact that global interpreter locking should not degrade the performance of a single-threaded code. Anyone who tried to include hyper-threading in 2003 will understand what I'm talking about .
If you really want to parallelize the code on CPython, you will have to use several processes.
In CPython 2.6, the multiprocessing module has been added to the standard library. Multiprocessing disguised the spawning of processes in CPython (each process with its own GIL).
Processes are created, commands are sent to them using compiled modules and Python functions, and then they are attached to the main process again.
Multiprocessing also supports the use of variables through a queue or channel. It has a lock object, which is used to lock objects in the main process and write from other processes.
Multiprocessing has one major drawback. It carries a significant computational load, which affects both processing time and memory usage. The launch time of CPython even without no-site is 100-200 ms (take a look at https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b to learn more).
As a result, you may have parallel code on CPython, but you still need to carefully plan the work of long processes that share several objects.
Another alternative is to use a third-party package, such as Twisted.
So let me remind you that multithreading in CPython is simple, but in reality it is not parallelization, but multiprocessing is parallel, but entails significant overhead.
What if there is a better way?
The key to GIL traversal is in the name, the global interpreter lock is part of the global interpreter state. CPython processes can have several interpreters and, consequently, several locks, but this function is rarely used, since it can only be accessed through the C-API.
One of the features of CPython 3.8 is PEP554, the implementation of subinterpreters and APIs with the new
This allows you to create multiple interpreters from Python within the same process. Another new feature of Python 3.8 is that all interpreters will have their own GIL.
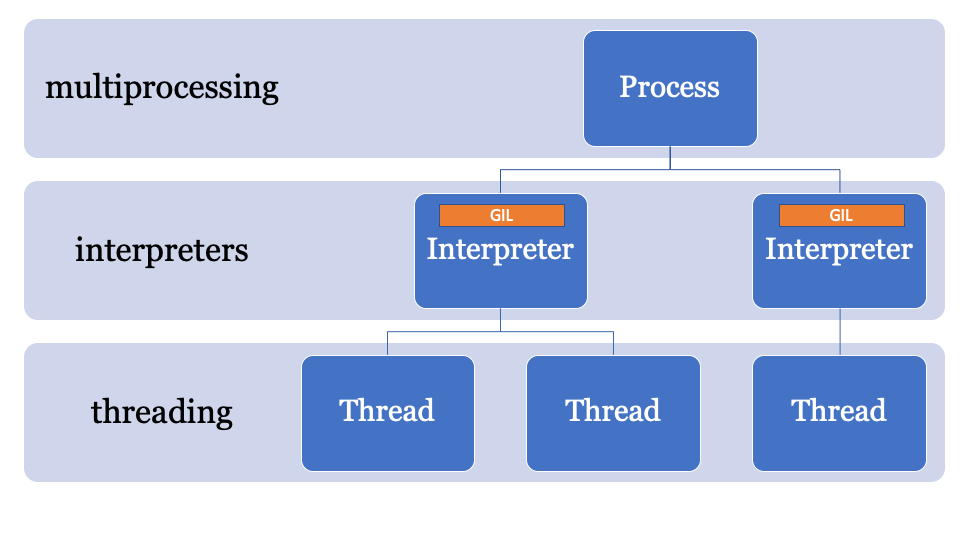
Since the state of the interpreter contains an area allocated in memory, a collection of all pointers to Python objects (local and global), the subinterpreters in PEP554 cannot access the global variables of other interpreters.
Like multiprocessing, sharing by interpreters of objects consists in their serialization and use of the IPC form (network, disk, or shared memory). There are many ways to serialize objects in Python, such as the
It would be best to have a common memory space that can be modified and controlled by a specific process. Thus, objects can be sent by the main interpreter and received by another interpreter. This will be the managed memory space for searching for PyObject pointers that each interpreter can access, and the main process will manage the locks.
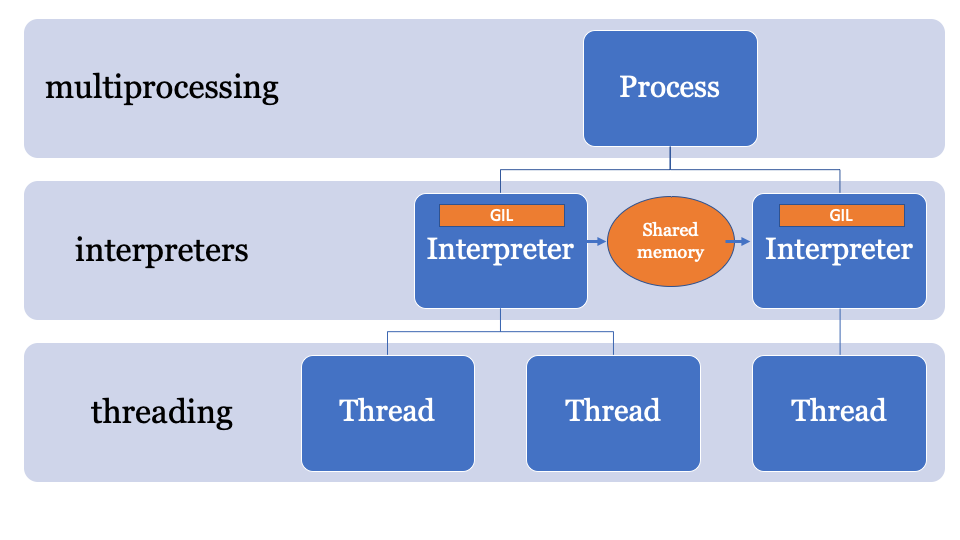
An API for this is still being developed, but it will probably look something like this:
This example uses NumPy. The numpy array is sent over the channel, it is serialized using the
The
PEP574 introduces the new pickle protocol (v5) , which supports the ability to process memory buffers separately from the rest of the pickle stream. As for big data objects, serialization of them all in one breath and deserialization from the subinterpreter will add a large amount of overhead.
The new API can be implemented (purely hypothetical) as follows -
In essence, this example is built on the use of low-level subinterpreters API. If you have not used the
As soon as this PEP merges with others, I think we will see several new APIs in PyPi.
Short answer: More than flow, less than process.
Long answer: The interpreter has its own state, therefore it will need to clone and initialize the following, despite the fact that PEP554 simplifies the creation of subinterpreters:
The kernel configuration can be easily cloned from memory, but with imported modules, things are not that simple. Importing modules to Python is slow, so if creating a subinterpreter means importing modules to a different namespace each time, the benefits are reduced.
The existing implementation of the
After combining PEP554, probably already in Python 3.9, an alternative implementation of the event loop can be used (although no one has yet done this), which in parallel runs asynchronous methods in the subinterpreters.
Well, not quite.
Since CPython has been working on one interpreter for so long, many parts of the code base use “Runtime State” instead of “Interpreter State”, so if PEP554 was introduced now, there would still be a lot of problems.
For example, the state of the garbage collector (in versions 3.7 <) belongs to the runtime environment.
In the changes during the PyCon sprints, the state of the garbage collector began to move to the interpreter, so that each subinterpreter will have its own garbage collector (as it should have been).
Another problem is that there are some “global” variables that were delayed in order in the CPython code base along with many extensions in C. Therefore, when people suddenly began to correctly parallelize their code, we saw some problems.
Another problem is that the file handles belong to the process, so if you have a file open for writing in one interpreter, the subinterpreter will not be able to access this file (without further changes to CPython).
In short, there are still many problems to be solved.
GIL will still be used for single-threaded applications. Therefore, even if you follow PEP554, your single-threaded code will not suddenly become parallel.
If you want to write parallel code in Python 3.8, you will have paralleling problems with the processor, but this is also a ticket to the future!
Pickle v5 and memory sharing for multiprocessing are likely to be in Python 3.8 (October 2019), and subinterpreters will appear between versions 3.8 and 3.9.
If you have a desire to play with the presented examples, then I created a separate branch with all the necessary code: https://github.com/tonybaloney/cpython/tree/subinterpreters.
What do you think about this? Write your comments and see you on the course.
Back in 2003, Intel released the new Pentium 4 “HT” processor. This processor overclocked to 3GHz and supported hyperthreading technology.
')
In the following years, Intel and AMD struggled to achieve the highest performance of desktop computers, increasing bus speed, L2 cache size and decreasing matrix size to minimize latency. In 2004, the HT model with a frequency of 3 GHz was replaced by 580 Prescott models with overclocking to 4 GHz.
It seemed that to go ahead you just had to increase the clock frequency, but the new processors suffered from high power consumption and heat dissipation.
Does your desktop processor have 4 GHz today? It is unlikely, because the path to improved performance ultimately led through increased bus speed and an increase in the number of cores. In 2006, Intel Core 2 replaced the Pentium 4 and had a much lower clock speed.
In addition to the release of multi-core processors for a wide user audience in 2006, something else happened. Python 2.5 finally saw the light! It has already been delivered with the beta version of the with keyword, which you all know and love.
Python 2.5 had one major limitation when it came to using Intel Core 2 or AMD Athlon X2.
It was a GIL.
What is GIL?
GIL (Global Interpreter Lock) is a Boolean value in the Python interpreter, protected by a mutex. The blocking is used in the main CPython bytecode calculation loop to determine which stream is currently executing instructions.
CPython supports the use of multiple streams in the same interpreter, but streams must request access to GIL in order to perform low-level operations. In turn, this means that Python developers can use asynchronous code, multithreading and no longer worry about blocking any variables or processor-level faults during deadlocks.
GIL simplifies multithreaded programming in Python.
GIL also tells us that while CPython can be multi-threaded, only one thread can be executed at any time. This means that your quad-core processor does something like this (except for the blue screen, I hope).
The current version of GIL was written in 2009 to support asynchronous functions and remained intact even after many attempts to remove it in principle or change the requirements for it.
Any suggestion to remove GIL was justified by the fact that global interpreter locking should not degrade the performance of a single-threaded code. Anyone who tried to include hyper-threading in 2003 will understand what I'm talking about .
Refusal from GIL in CPython
If you really want to parallelize the code on CPython, you will have to use several processes.
In CPython 2.6, the multiprocessing module has been added to the standard library. Multiprocessing disguised the spawning of processes in CPython (each process with its own GIL).
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join() Processes are created, commands are sent to them using compiled modules and Python functions, and then they are attached to the main process again.
Multiprocessing also supports the use of variables through a queue or channel. It has a lock object, which is used to lock objects in the main process and write from other processes.
Multiprocessing has one major drawback. It carries a significant computational load, which affects both processing time and memory usage. The launch time of CPython even without no-site is 100-200 ms (take a look at https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b to learn more).
As a result, you may have parallel code on CPython, but you still need to carefully plan the work of long processes that share several objects.
Another alternative is to use a third-party package, such as Twisted.
PEP554 and the death of GIL?
So let me remind you that multithreading in CPython is simple, but in reality it is not parallelization, but multiprocessing is parallel, but entails significant overhead.
What if there is a better way?
The key to GIL traversal is in the name, the global interpreter lock is part of the global interpreter state. CPython processes can have several interpreters and, consequently, several locks, but this function is rarely used, since it can only be accessed through the C-API.
One of the features of CPython 3.8 is PEP554, the implementation of subinterpreters and APIs with the new
interpreters module in the standard library.This allows you to create multiple interpreters from Python within the same process. Another new feature of Python 3.8 is that all interpreters will have their own GIL.
Since the state of the interpreter contains an area allocated in memory, a collection of all pointers to Python objects (local and global), the subinterpreters in PEP554 cannot access the global variables of other interpreters.
Like multiprocessing, sharing by interpreters of objects consists in their serialization and use of the IPC form (network, disk, or shared memory). There are many ways to serialize objects in Python, such as the
marshal module, the pickle module, or more standardized methods, such as json or simplexml . Each of them has its pros and cons, and they all give a computational load.It would be best to have a common memory space that can be modified and controlled by a specific process. Thus, objects can be sent by the main interpreter and received by another interpreter. This will be the managed memory space for searching for PyObject pointers that each interpreter can access, and the main process will manage the locks.
An API for this is still being developed, but it will probably look something like this:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import marshal # Create a sub-interpreter interpid = interpreters.create() # If you had a function that generated some data arry = list(range(0,100)) # Create a channel channel_id = interpreters.channel_create() # Pre-populate the interpreter with a module interpreters.run_string(interpid, "import marshal; import _xxsubinterpreters as interpreters") # Define a def run(interpid, channel_id): interpreters.run_string(interpid, tw.dedent(""" arry_raw = interpreters.channel_recv(channel_id) arry = marshal.loads(arry_raw) result = [1,2,3,4,5] # where you would do some calculating result_raw = marshal.dumps(result) interpreters.channel_send(channel_id, result_raw) """), shared=dict( channel_id=channel_id ), ) inp = marshal.dumps(arry) interpreters.channel_send(channel_id, inp) # Run inside a thread t = threading.Thread(target=run, args=(interpid, channel_id)) t.start() # Sub interpreter will process. Feel free to do anything else now. output = interpreters.channel_recv(channel_id) interpreters.channel_release(channel_id) output_arry = marshal.loads(output) print(output_arry) This example uses NumPy. The numpy array is sent over the channel, it is serialized using the
marshal module, then the subinterpreter processes the data (on a separate GIL), so there may be a parallelization problem associated with the CPU, which is ideal for subinterpreters.It looks ineffective
The
marshal module works really fast, but not as fast as sharing objects directly from memory.PEP574 introduces the new pickle protocol (v5) , which supports the ability to process memory buffers separately from the rest of the pickle stream. As for big data objects, serialization of them all in one breath and deserialization from the subinterpreter will add a large amount of overhead.
The new API can be implemented (purely hypothetical) as follows -
import _xxsubinterpreters as interpreters import threading import textwrap as tw import pickle # Create a sub-interpreter interpid = interpreters.create() # If you had a function that generated a numpy array arry = [5,4,3,2,1] # Create a channel channel_id = interpreters.channel_create() # Pre-populate the interpreter with a module interpreters.run_string(interpid, "import pickle; import _xxsubinterpreters as interpreters") buffers=[] # Define a def run(interpid, channel_id): interpreters.run_string(interpid, tw.dedent(""" arry_raw = interpreters.channel_recv(channel_id) arry = pickle.loads(arry_raw) print(f"Got: {arry}") result = arry[::-1] result_raw = pickle.dumps(result, protocol=5) interpreters.channel_send(channel_id, result_raw) """), shared=dict( channel_id=channel_id, ), ) input = pickle.dumps(arry, protocol=5, buffer_callback=buffers.append) interpreters.channel_send(channel_id, input) # Run inside a thread t = threading.Thread(target=run, args=(interpid, channel_id)) t.start() # Sub interpreter will process. Feel free to do anything else now. output = interpreters.channel_recv(channel_id) interpreters.channel_release(channel_id) output_arry = pickle.loads(output) print(f"Got back: {output_arry}") It looks like a template.
In essence, this example is built on the use of low-level subinterpreters API. If you have not used the
multiprocessing library, some problems will seem familiar to you. This is not as simple as stream processing; you cannot simply, say, run this function with such a list of input data in separate interpreters (for now).As soon as this PEP merges with others, I think we will see several new APIs in PyPi.
How much overhead does the subinterpreter have?
Short answer: More than flow, less than process.
Long answer: The interpreter has its own state, therefore it will need to clone and initialize the following, despite the fact that PEP554 simplifies the creation of subinterpreters:
- Modules in the
__main__andimportlib; - The contents of the
sysdictionary; - Built-in functions (
print(),assert, etc.); - Streams;
- Kernel configuration
The kernel configuration can be easily cloned from memory, but with imported modules, things are not that simple. Importing modules to Python is slow, so if creating a subinterpreter means importing modules to a different namespace each time, the benefits are reduced.
How about asyncio?
The existing implementation of the
asyncio event asyncio in the standard library creates stack frames for evaluation, and also asyncio state in the main interpreter (and, therefore, shares GIL).After combining PEP554, probably already in Python 3.9, an alternative implementation of the event loop can be used (although no one has yet done this), which in parallel runs asynchronous methods in the subinterpreters.
It sounds cool, and wrap me!
Well, not quite.
Since CPython has been working on one interpreter for so long, many parts of the code base use “Runtime State” instead of “Interpreter State”, so if PEP554 was introduced now, there would still be a lot of problems.
For example, the state of the garbage collector (in versions 3.7 <) belongs to the runtime environment.
In the changes during the PyCon sprints, the state of the garbage collector began to move to the interpreter, so that each subinterpreter will have its own garbage collector (as it should have been).
Another problem is that there are some “global” variables that were delayed in order in the CPython code base along with many extensions in C. Therefore, when people suddenly began to correctly parallelize their code, we saw some problems.
Another problem is that the file handles belong to the process, so if you have a file open for writing in one interpreter, the subinterpreter will not be able to access this file (without further changes to CPython).
In short, there are still many problems to be solved.
Conclusion: Is GIL really no longer relevant?
GIL will still be used for single-threaded applications. Therefore, even if you follow PEP554, your single-threaded code will not suddenly become parallel.
If you want to write parallel code in Python 3.8, you will have paralleling problems with the processor, but this is also a ticket to the future!
When?
Pickle v5 and memory sharing for multiprocessing are likely to be in Python 3.8 (October 2019), and subinterpreters will appear between versions 3.8 and 3.9.
If you have a desire to play with the presented examples, then I created a separate branch with all the necessary code: https://github.com/tonybaloney/cpython/tree/subinterpreters.
What do you think about this? Write your comments and see you on the course.
Source: https://habr.com/ru/post/458694/
All Articles