Automate it! How we improved integration testing
In the old days, we had only a few services, and posting more than one update on production in a day was a great success . Then the world accelerated, the system became more complicated, and we were transformed into an organization with microservice architecture. Now we have about a hundred services, and as their number grows, the frequency of releases increases - there are more than 250 of them per week.
And if new features are tested inside product teams, then the task of the integration testing team is to check that the changes included in the release do not break the functionality of the component, the system, and other features.

')
I work as a test automation engineer at Yandex.Money.
In this article I will talk about the evolution of integration testing of web services, as well as about the adaptation of the process to an increase in the number of system components and an increase in the frequency of releases.
About changes in the release cycle and the development of the mechanism of calculations was told by ops and dev in one of the previous articles . I will tell you about the history of changes in the testing process during this transformation.
We now have about 30 development teams. The team typically includes a product manager, project manager, front-end and back-end developers and testers. They are united by work on tasks for a specific product. For the service, as a rule, the team is responsible, which often makes changes to it.
Not so long ago, with the release of each component, only unit-and component tests were run, and after that only a few of the most important end-to-end scripts were performed on a full-fledged test environment before laying out the service in production. Together with the increase in the number of components, the number of links between them began to increase exponentially. Often - completely non-trivial links. I remember how the inaccessibility of the service of issuing marketing data broke the registration of users completely (of course, for a short time).
Such an approach to checking for changes began to fail more and more often - it was necessary to cover all the critical business scenarios with autotests and run them on a full-fledged test environment with a release-ready version of the component.
Okay, auto tests for critical scenarios have appeared - but how to run them? The task arose to integrate into the release cycle, minimally affecting its reliability by false drops of tests. On the other hand, I wanted to carry out the integration testing stage as quickly as possible. This is how the infrastructure for acceptance testing appeared.
We have tried to make maximum use of the tools already used to carry out the component on the release cycle and launch tasks: Jira and Jenkins, respectively.
To carry out acceptance testing identified such a cycle:
The whole cycle was performed manually every time. As a result, already on the tenth release a day from the performance of similar tasks, I wanted to swear, at best, under my breath, clutch at the head and demand valerianbeer .
We realized that tracking new tasks in Jira and notifying about them are important processes that are quickly and easily automated. So there was a bot that does it.
The data for generating alerts come in the form of push-notifications from Jira. After the launch of the bot, we stopped updating the dashboard page with acceptance tasks, and the width of the automator's smile slightly increased.
We decided to simplify the verification that during the deployment in the test environment there were no assembly or installation errors and that the necessary version of the component was raised, and not some other version. The component gives its version and status using the HTTP protocol. And checking that the service returns the correct version would be simple and understandable if different components were not written in different languages - some on Node.js, some on C #. In addition, our most popular Java services also provided a version in a different format.
Plus, I wanted to have real-time information and notifications not only about changing versions, but also about changing the availability of components in the system. To solve this problem, the Pinger service appeared, collecting information on the status and version of components by means of a cyclical survey.
We use the push model of message delivery — an agent is deployed on each instance of the test environment, which collects information about the components of this environment and stores data at the central site once every 10 seconds. In this node we go for the current status - this approach allows you to support more than a hundred test benches.
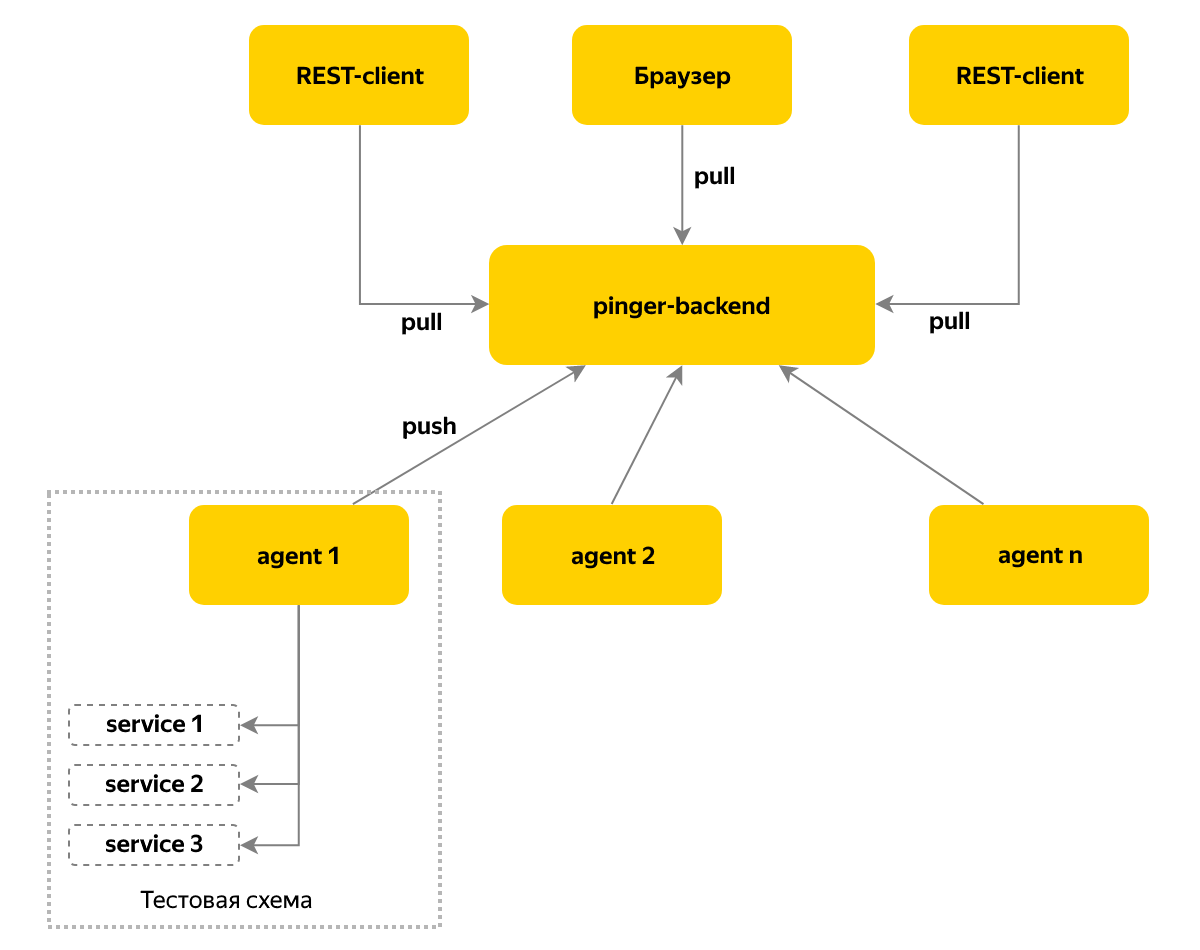
The time has come for more complex tasks - automatic updating of components and running tests. At that time, our team already had 3 test benches in OpenStack for conducting acceptance tests, and first it was necessary to solve the problem of managing test bench resources: it would be unpleasant if the update of the next release “rolls” on the system. It also happens that the test stand is debugged, and then you should not use it for acceptance.
I wanted to be able to see the status of employment and, if necessary, manually block the stand during the analysis of dropped tests or until the completion of other works.
For all this, Locker service appeared. It stores the status of the test bench for a long time (“busy” / “free”), allows you to set a comment on “employment”, so that it is clear that we are currently debugging, re-creating a copy of the test environment or running tests of the next release. We also began to block stands for the night - on them, administrators perform work on a schedule, like backups and database synchronization.
When blocking, the time is always set, after which the lock will expire - now people do not need to participate in the return of stands to the pool available, and the machine does everything.
In order to evenly distribute the load on the analysis of the results of the test runs among the team members, we invented daily duties. The duty officer works with tasks for acceptance testing of releases, parses the fallen autotests and reports bugs. If the duty officer understands that he is not coping with the flow of tasks, he can ask the team for help. At this time, the rest of the team involved in tasks not related to releases.
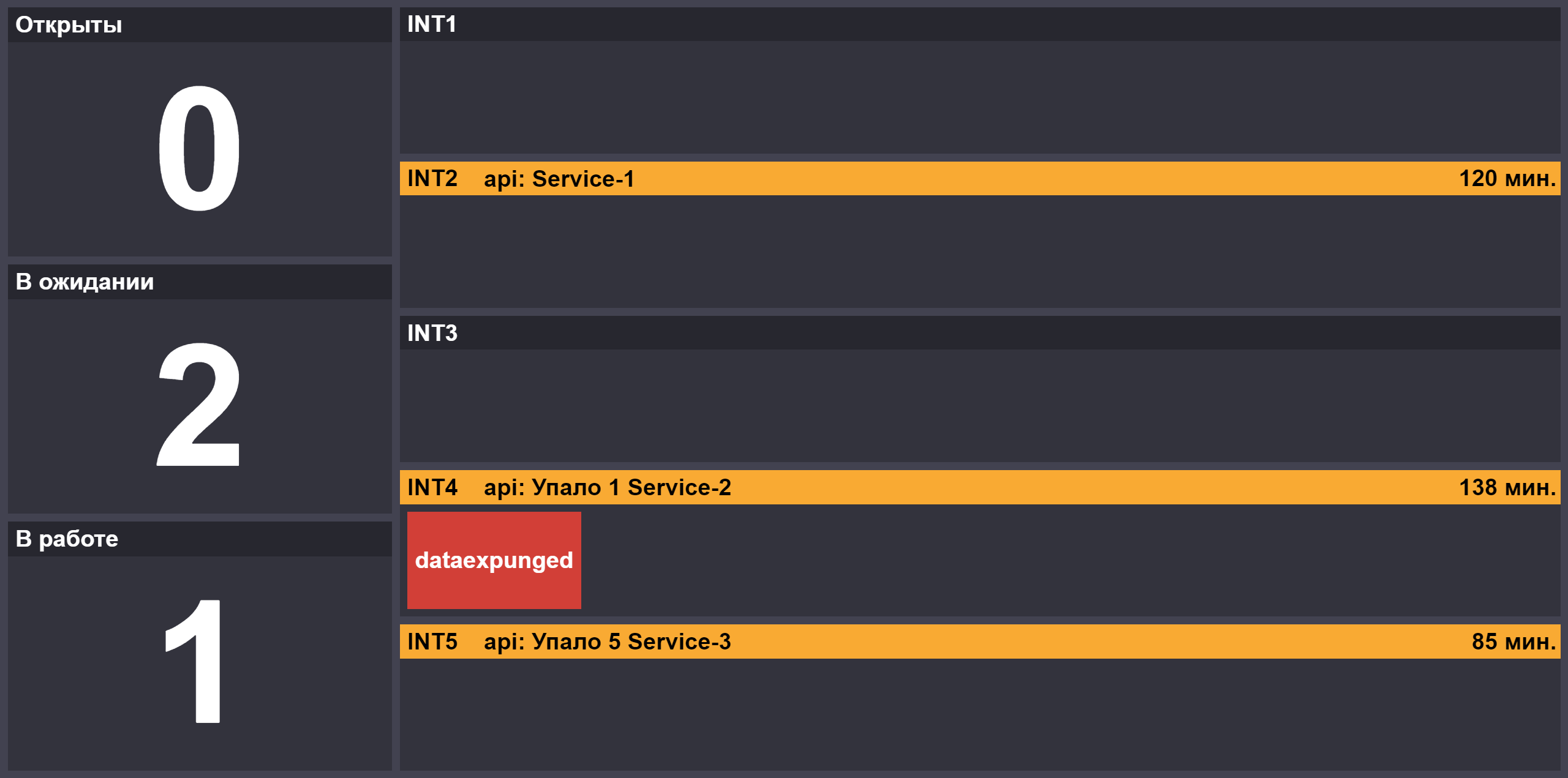
With the increase in the number of releases, the role of the second attendant appeared, which connects to the main one if there are “blockages” or critical releases are in the queue. To provide information on the progress of testing releases, we created a page with the number of tasks in the states "open" / "running" / "waiting for the reaction of the attendant", blocking status of test benches and components unavailable on the stands:
The work of the attendant requires concentration, so he has a bun - on the day of his duty, he can choose a place for lunch for the whole team not far from the office. The bribes of the attendant in the style look especially fun: “Let me help you to make out the tasks, and today we will go to my favorite place” =)
One of the tasks that we faced when we entered duty was the need to transfer knowledge from one person to another, for example, tests falling on a new release or the specifics of updating a particular component.
In addition, we have new features of the work.
This is how the Reporter service appeared. In it, we push the test run results in real time during the testing process. The service has a database of known problems or bugs that are linked to a specific test. A publication on the results of the run from the reporter was also added to the company's wiki portal. This is convenient for managers who do not want to dive into the technical details that the Reporter or Allure interface abounds in.
When a test crashes, you can see in the Reporter a list of related bugs or correction tasks. Such information reduces parsing time and facilitates the exchange of knowledge about problems between members of our team. Records of completed tasks go to the archive, but if necessary, you can “peep” them in a separate list. In order not to load internal services during business hours, we interrogate Jira at night and record for issues with final status we archive.
A bonus from the introduction of Reporter was the emergence of a base of runs, on the basis of which you can analyze the frequency of falls, rank tests by their level of stability or “utility” in terms of the number of bugs found.
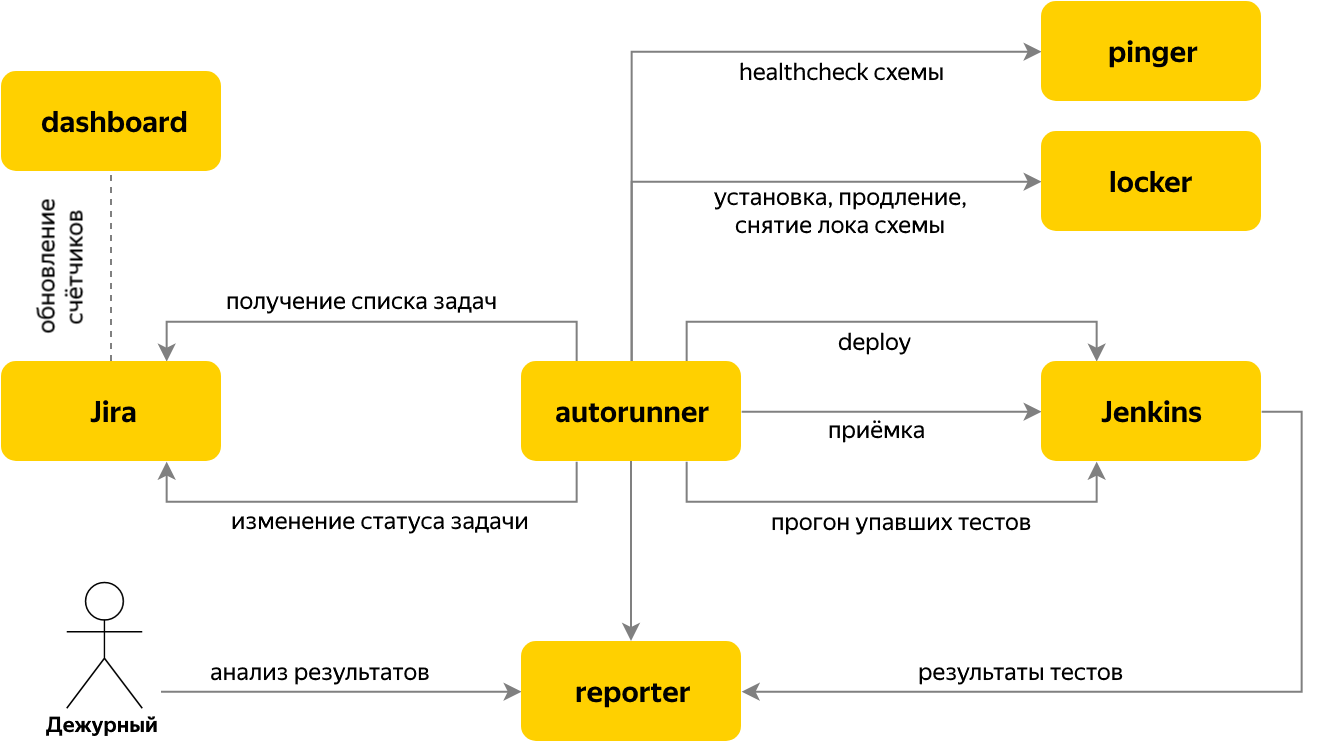
Next, we moved on to automating the launch of tests, when the issue tracker has a task for acceptance testing of the release. For this purpose, the Autorun service was written, which checks whether there are new acceptance tasks in Jira, and if so, it determines the name of the component and its version based on the content of the task.
For a task several steps are performed:
Switches between stages are organized according to the state machine principle. Each stage knows the conditions for the transition to the next. The results of the stage are stored in the task context, which is common to the stages of one task.
All this allows you to automatically transfer further downstream releases, for which 100 percent of tests are green. But what about the instability caused not by problems in the component, but by the “natural” features of the UI tests or by the increased network delays in the test bench?
To do this, we have implemented a mechanism for repeated launches (retry), which many people use, but very few people admit it. Retrai are organized as a sequential test run in Jenkins Pipeline.
After the run, we request a list of dropped tests from Reporter from Jenkins - and restart only failed ones. In addition, we reduce the number of threads at startup. If the number of dropped tests has not decreased compared to the previous run, we immediately end Job. In our case, this approach to restarting allows us to increase the success of acceptance testing by about 2 times.
The resulting system of acceptance testing allowed us to conduct more than 60% of releases without human intervention. But what to do with the rest? If necessary, the duty officer creates a bug report on the component being tested or the task of correcting the tests to the development team. Sometimes - draws a bug configuration test bench in the department of operation.
Tasks to correct tests often block the correct passage of automatic testing, since irrelevant tests will always be "red." Testers from development teams are responsible for writing new tests and updating existing ones - making changes via pull requests to the project with autotests. These edits pass a mandatory review, which requires some time from the reviewer and the author, and I want to temporarily block irrelevant tests before transferring the task to correct them to the final status.
First, we implemented a shutdown mechanism based on test method annotations. Subsequently, it turned out that, due to the presence of a mandatory code review, locking from the code is not always convenient and may take more time than we would like.
Therefore, we moved the list of blocking test tasks to a new service with a web page - Quick-block. So the members of the team responsible for the component can quickly block the test. Before the run, we go to this service and get a list of quarantine tests that we translate into skipped status.
We have gone from the manual acceptance of releases to the almost fully automatic process, which is able to carry out more than 50 releases per day through acceptance testing. This helps the company to reduce the time it takes to change, and our team to find resources for experimentation and the development of testing tools.
In the future, we plan to increase the reliability of the process, for example, by distributing requests between a pair of instances of each service from the list above. This will allow you to update tools without downtime and include new features for only part of the acceptance tests. In addition, we pay attention to the stabilization of the tests themselves. In the development of a generator of tickets for refactoring tests with the lowest success rate.
Improving the reliability of tests will not only increase their credibility, but will also accelerate testing of releases due to the lack of restarts of dropped scripts.
And if new features are tested inside product teams, then the task of the integration testing team is to check that the changes included in the release do not break the functionality of the component, the system, and other features.
')
I work as a test automation engineer at Yandex.Money.
In this article I will talk about the evolution of integration testing of web services, as well as about the adaptation of the process to an increase in the number of system components and an increase in the frequency of releases.
About changes in the release cycle and the development of the mechanism of calculations was told by ops and dev in one of the previous articles . I will tell you about the history of changes in the testing process during this transformation.
We now have about 30 development teams. The team typically includes a product manager, project manager, front-end and back-end developers and testers. They are united by work on tasks for a specific product. For the service, as a rule, the team is responsible, which often makes changes to it.
Acceptance end-to-end testing
Not so long ago, with the release of each component, only unit-and component tests were run, and after that only a few of the most important end-to-end scripts were performed on a full-fledged test environment before laying out the service in production. Together with the increase in the number of components, the number of links between them began to increase exponentially. Often - completely non-trivial links. I remember how the inaccessibility of the service of issuing marketing data broke the registration of users completely (of course, for a short time).
Such an approach to checking for changes began to fail more and more often - it was necessary to cover all the critical business scenarios with autotests and run them on a full-fledged test environment with a release-ready version of the component.
Okay, auto tests for critical scenarios have appeared - but how to run them? The task arose to integrate into the release cycle, minimally affecting its reliability by false drops of tests. On the other hand, I wanted to carry out the integration testing stage as quickly as possible. This is how the infrastructure for acceptance testing appeared.
We have tried to make maximum use of the tools already used to carry out the component on the release cycle and launch tasks: Jira and Jenkins, respectively.
Acceptance Testing Cycle
To carry out acceptance testing identified such a cycle:
- monitoring of incoming testing tasks for release,
- running the Jenkins job to install the release build on the test environment,
- checking that the service has gone up,
- Jenkins job launch with integration tests
- analysis of the results of the run,
- rerun tests (if necessary)
- update of task status - passed or broken, indicating the reason in the comment.
The whole cycle was performed manually every time. As a result, already on the tenth release a day from the performance of similar tasks, I wanted to swear, at best, under my breath, clutch at the head and demand valerian
Bot monitor
We realized that tracking new tasks in Jira and notifying about them are important processes that are quickly and easily automated. So there was a bot that does it.
The data for generating alerts come in the form of push-notifications from Jira. After the launch of the bot, we stopped updating the dashboard page with acceptance tasks, and the width of the automator's smile slightly increased.
Pinger
We decided to simplify the verification that during the deployment in the test environment there were no assembly or installation errors and that the necessary version of the component was raised, and not some other version. The component gives its version and status using the HTTP protocol. And checking that the service returns the correct version would be simple and understandable if different components were not written in different languages - some on Node.js, some on C #. In addition, our most popular Java services also provided a version in a different format.
Plus, I wanted to have real-time information and notifications not only about changing versions, but also about changing the availability of components in the system. To solve this problem, the Pinger service appeared, collecting information on the status and version of components by means of a cyclical survey.
We use the push model of message delivery — an agent is deployed on each instance of the test environment, which collects information about the components of this environment and stores data at the central site once every 10 seconds. In this node we go for the current status - this approach allows you to support more than a hundred test benches.
Locker
The time has come for more complex tasks - automatic updating of components and running tests. At that time, our team already had 3 test benches in OpenStack for conducting acceptance tests, and first it was necessary to solve the problem of managing test bench resources: it would be unpleasant if the update of the next release “rolls” on the system. It also happens that the test stand is debugged, and then you should not use it for acceptance.
I wanted to be able to see the status of employment and, if necessary, manually block the stand during the analysis of dropped tests or until the completion of other works.
For all this, Locker service appeared. It stores the status of the test bench for a long time (“busy” / “free”), allows you to set a comment on “employment”, so that it is clear that we are currently debugging, re-creating a copy of the test environment or running tests of the next release. We also began to block stands for the night - on them, administrators perform work on a schedule, like backups and database synchronization.
When blocking, the time is always set, after which the lock will expire - now people do not need to participate in the return of stands to the pool available, and the machine does everything.
Duty
In order to evenly distribute the load on the analysis of the results of the test runs among the team members, we invented daily duties. The duty officer works with tasks for acceptance testing of releases, parses the fallen autotests and reports bugs. If the duty officer understands that he is not coping with the flow of tasks, he can ask the team for help. At this time, the rest of the team involved in tasks not related to releases.
With the increase in the number of releases, the role of the second attendant appeared, which connects to the main one if there are “blockages” or critical releases are in the queue. To provide information on the progress of testing releases, we created a page with the number of tasks in the states "open" / "running" / "waiting for the reaction of the attendant", blocking status of test benches and components unavailable on the stands:
The work of the attendant requires concentration, so he has a bun - on the day of his duty, he can choose a place for lunch for the whole team not far from the office. The bribes of the attendant in the style look especially fun: “Let me help you to make out the tasks, and today we will go to my favorite place” =)
Reporter
One of the tasks that we faced when we entered duty was the need to transfer knowledge from one person to another, for example, tests falling on a new release or the specifics of updating a particular component.
In addition, we have new features of the work.
- There was a category of tests that fall with more or less frequency due to problems with test benches. Falls may occur due to the increased response time of one of the services or a long load of resources in the browser. I don’t want to turn off the tests, reasonable means of increasing their reliability have been exhausted.
- We have a second, experimental project with auto-tests, and the need has emerged to sort out the runs of two projects at once, looking at the Allure reports.
- The test run can take up to 20 minutes, and I want to start analyzing the results immediately after the start of the first crashes. Especially if the task is critical and the members of the team responsible for the release stand behind you
, putting a knife to the throatwith plaintive eyes.
This is how the Reporter service appeared. In it, we push the test run results in real time during the testing process. The service has a database of known problems or bugs that are linked to a specific test. A publication on the results of the run from the reporter was also added to the company's wiki portal. This is convenient for managers who do not want to dive into the technical details that the Reporter or Allure interface abounds in.
When a test crashes, you can see in the Reporter a list of related bugs or correction tasks. Such information reduces parsing time and facilitates the exchange of knowledge about problems between members of our team. Records of completed tasks go to the archive, but if necessary, you can “peep” them in a separate list. In order not to load internal services during business hours, we interrogate Jira at night and record for issues with final status we archive.
A bonus from the introduction of Reporter was the emergence of a base of runs, on the basis of which you can analyze the frequency of falls, rank tests by their level of stability or “utility” in terms of the number of bugs found.
Autorun
Next, we moved on to automating the launch of tests, when the issue tracker has a task for acceptance testing of the release. For this purpose, the Autorun service was written, which checks whether there are new acceptance tasks in Jira, and if so, it determines the name of the component and its version based on the content of the task.
For a task several steps are performed:
- we take lock of one of the free test stands in the Locker service,
- we start installation of the necessary component in Jenkins, we wait for a component raising with the required version,
- run tests
- waiting for the completion of the test run, in the process of their execution all the results are pushed to the Reporter,
- we request from the Reporter the number of dropped tests, excluding those that have fallen due to known problems,
- if 0 falls, we transfer the task for acceptance testing to “Finish” and complete the work with it. Everything is ready =)
- if there are “red” tests - we transfer the task to “Waiting” and go to the Reporter for their analysis.
Switches between stages are organized according to the state machine principle. Each stage knows the conditions for the transition to the next. The results of the stage are stored in the task context, which is common to the stages of one task.
All this allows you to automatically transfer further downstream releases, for which 100 percent of tests are green. But what about the instability caused not by problems in the component, but by the “natural” features of the UI tests or by the increased network delays in the test bench?
To do this, we have implemented a mechanism for repeated launches (retry), which many people use, but very few people admit it. Retrai are organized as a sequential test run in Jenkins Pipeline.
After the run, we request a list of dropped tests from Reporter from Jenkins - and restart only failed ones. In addition, we reduce the number of threads at startup. If the number of dropped tests has not decreased compared to the previous run, we immediately end Job. In our case, this approach to restarting allows us to increase the success of acceptance testing by about 2 times.
Quick-block
The resulting system of acceptance testing allowed us to conduct more than 60% of releases without human intervention. But what to do with the rest? If necessary, the duty officer creates a bug report on the component being tested or the task of correcting the tests to the development team. Sometimes - draws a bug configuration test bench in the department of operation.
Tasks to correct tests often block the correct passage of automatic testing, since irrelevant tests will always be "red." Testers from development teams are responsible for writing new tests and updating existing ones - making changes via pull requests to the project with autotests. These edits pass a mandatory review, which requires some time from the reviewer and the author, and I want to temporarily block irrelevant tests before transferring the task to correct them to the final status.
First, we implemented a shutdown mechanism based on test method annotations. Subsequently, it turned out that, due to the presence of a mandatory code review, locking from the code is not always convenient and may take more time than we would like.
Therefore, we moved the list of blocking test tasks to a new service with a web page - Quick-block. So the members of the team responsible for the component can quickly block the test. Before the run, we go to this service and get a list of quarantine tests that we translate into skipped status.
Results
We have gone from the manual acceptance of releases to the almost fully automatic process, which is able to carry out more than 50 releases per day through acceptance testing. This helps the company to reduce the time it takes to change, and our team to find resources for experimentation and the development of testing tools.
In the future, we plan to increase the reliability of the process, for example, by distributing requests between a pair of instances of each service from the list above. This will allow you to update tools without downtime and include new features for only part of the acceptance tests. In addition, we pay attention to the stabilization of the tests themselves. In the development of a generator of tickets for refactoring tests with the lowest success rate.
Improving the reliability of tests will not only increase their credibility, but will also accelerate testing of releases due to the lack of restarts of dropped scripts.
Source: https://habr.com/ru/post/458690/
All Articles