Automation for the smallest. Part One (which is after zero). Network virtualization
In the previous issue, I described the network automation framework. According to reviews from some people, even this first approach to the problem has already arranged some questions on the shelves. And it makes me very happy, because our goal in the cycle is not to plaster the anzibl with Python scripts, but to build a system.
The same framework sets the order in which we will deal with the question.
And the network virtualization, to which this issue is dedicated, does not really fit into the subject of ADSM, where we disassemble automation.
But let's take a look at it from a different angle.
')
For a long time, many services have been using the same network. In the case of a carrier, these are 2G, 3G, LTE, broadband access and B2B, for example. In the case of DC: connectivity for different clients, the Internet, block storage, object storage.
And all services require isolation from each other. This is how overlay networks appeared.
And all the services do not want to wait for the person to configure them manually. That is how the orchestrators and SDN appeared.
The first approach to the systematic automation of the network, or rather its parts, has long been undertaken and implemented in many places: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Here with him today and ponder.

And since we started talking about this, it is worth mentioning the prerequisites for network virtualization. In fact, this process did not begin yesterday.
Probably, you have often heard that the network has always been the most inert part of any system. And this is true in all senses. The network is the basis on which everything rests, and it is quite difficult to make changes on it - services do not tolerate when the network is lying. Often, decommissioning a single node can add up most of the applications and affect many customers. This is partly why the network team can resist any changes - because now it somehow works ( we may not even know how ), and here we need to configure something new, and it is not known how it will affect the network.
In order not to wait for networkers to drop VLANs and not to prescribe any services on each node of the network, people have come up with the use of overlays — overlay networks — of which there is a great variety: GRE, IPinIP, MPLS, MPLS L2 / L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE, etc.
Their appeal lies in two simple things:
In this not quite high-grade release, I do not plan to disassemble all possible technologies, but rather describe the framework of work of overlay networks in DC.
The whole series will describe a data center consisting of rows of racks of the same type, in which the same server hardware is installed.
This equipment runs virtual machines / containers / serverless, implementing services.

In the loop, I will call the server a program that implements the server side of client-server communication.
Physical machines in racks will not be called servers.
The physical machine is an x86 rack-mounted computer. The most commonly used term is host . So let's call it " machine " or host .
A hypervisor is an application running on a physical machine that emulates the physical resources on which Virtual Machines are started. Sometimes in literature and networks the word “hypervisor” is used as a synonym for “host”.
A virtual machine is an operating system running on a physical machine on top of the hypervisor. For us, in this cycle it is not so important whether it really is a virtual machine or just a container. Let's call it " VM "
Tenant is a broad concept that I will define in this article as a separate service or a separate client.
Multi-tenancy or multi-tenancy - using the same application by different clients / services. At the same time, the isolation of clients from each other is achieved due to the architecture of the application, rather than separately-running instances.
ToR - Top of the Rack switch - a switch mounted in a rack to which all physical machines are connected.
Overlay network or overlay network or overlay is a virtual network of tunnels running on top of the physical.
L3-factory or IP-factory - a terrific invention of mankind, which allows for interviews not to repeat STP and not to learn TRILL. A concept in which the entire network down to the access level is exclusively L3, without a VLAN and consequently huge stretched broadcast domains. Where does the word "factory" come from here?
SDN - Software Defined Network. Hardly needs any introduction. An approach to network management when changes on the network are performed not by a person, but by a program. Usually means taking Control Plane beyond the end network devices to the controller.
NFV - Network Function Virtualization - virtualization of network devices, suggesting that some of the network functions can be run as virtual machines or containers to speed up the introduction of new services, organize Service Chaining and more simple horizontal scalability.
VNF - Virtual Network Function. Specific virtual device: router, switch, firewall, NAT, IPS / IDS, etc.
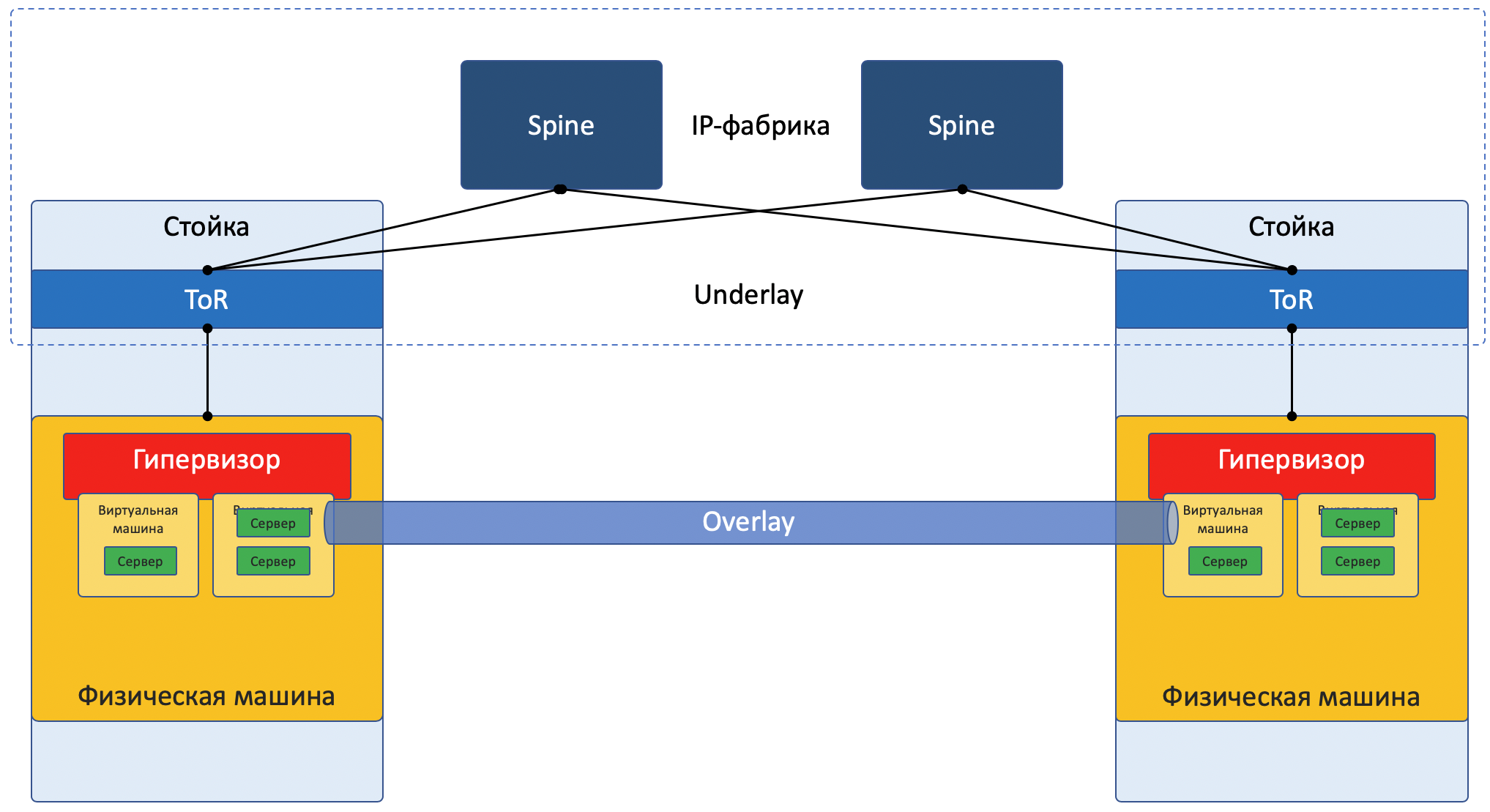
Most networks today can be clearly divided into two parts:
Underlay is a physical network with a stable configuration.
Overlay - an abstraction over underlay to isolate tenants.
This is true both for the DC case (which we will discuss in this article) and for the ISP (which we will not analyze, because we already had it in the UFSR ). With enterprise networks, of course, the situation is somewhat different.
Network focused image:

Underlay is a physical network: hardware switches and cables. Devices in the underlay know how to get to the physical machines.
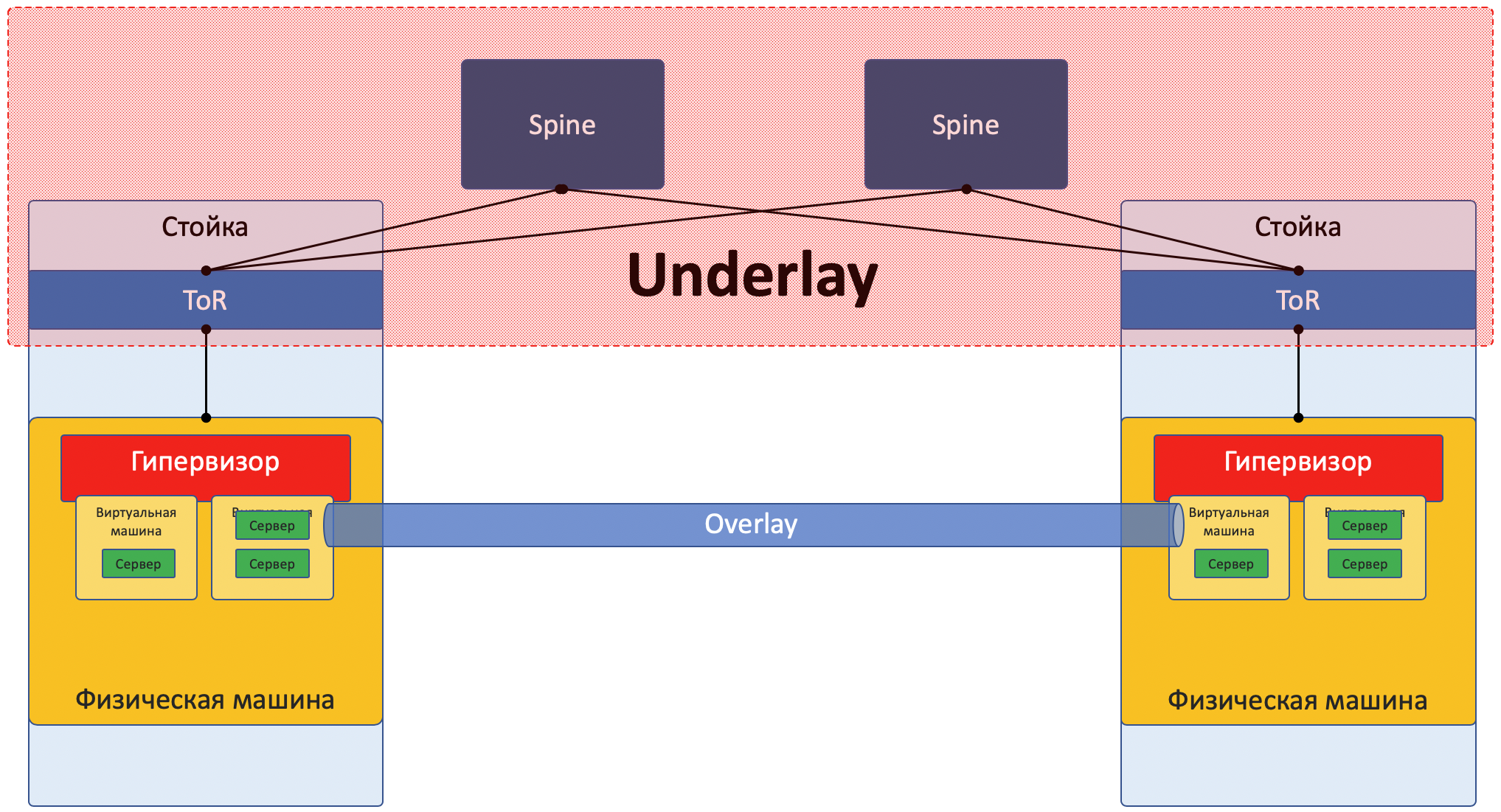
It relies on standard protocols and technologies. Not least because hardware devices still work on proprietary software that does not allow chip programming or implementation of their protocols, respectively, compatibility with other vendors and standardization are needed.
Underlay can be for example:
The Underlay network is configured in the classic way: CLI / GUI / NETCONF.
Manually, scripts, proprietary utilities.
The next article of the cycle will be devoted to the underlay in more detail.
Overlay - a virtual network of tunnels stretched over the Underlay, it allows the VMs of one client to communicate with each other, while providing isolation from other clients.
Client data is encapsulated in any tunneling headers for transmission over a common network.

So VMs of one client (one service) can communicate with each other through Overlay, without even knowing what path the package actually goes.
Overlay can be for example the same as I mentioned above:
An overlay network is usually configured and maintained through a central controller. From it, the configuration, Control Plane and Data Plane are delivered to devices that route and encapsulate client traffic. Below we analyze it in examples.
Yes, this is pure SDN.
There are two fundamentally different approaches to the organization of Overlay-network:
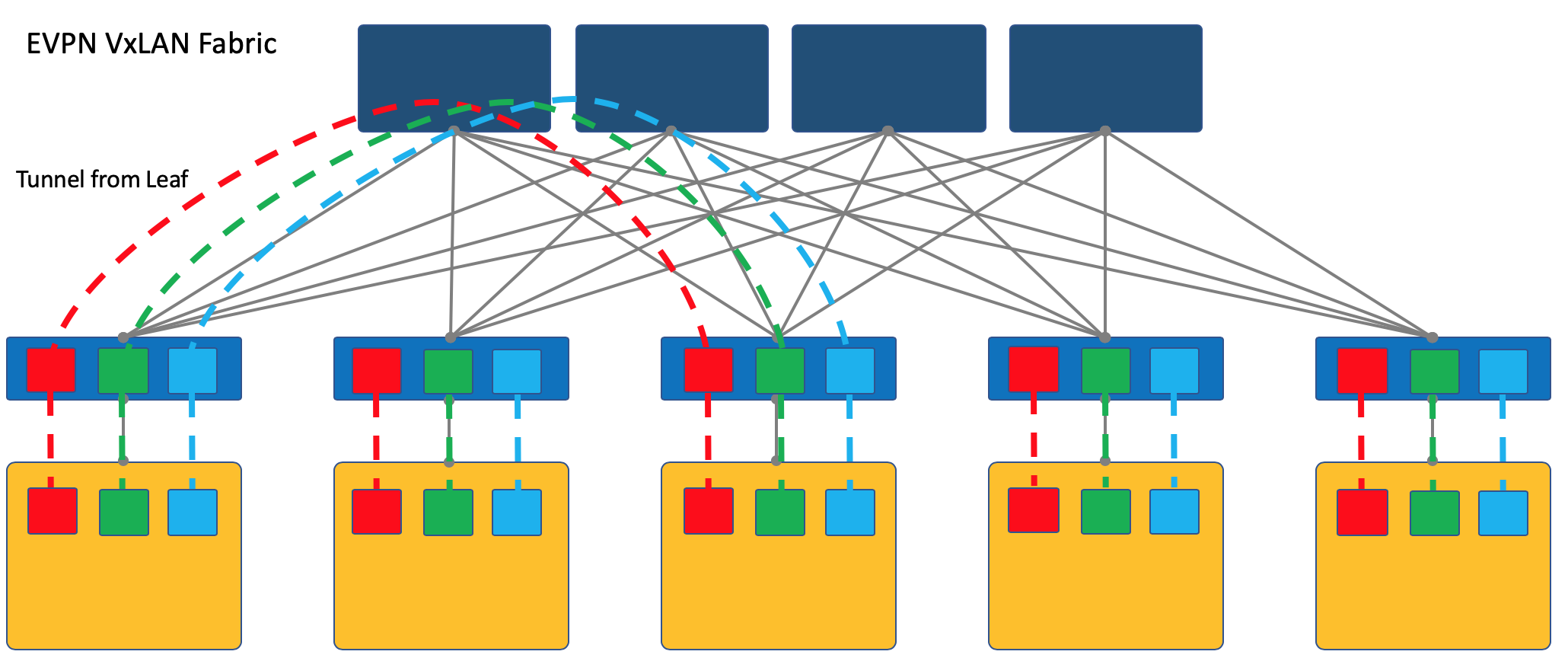
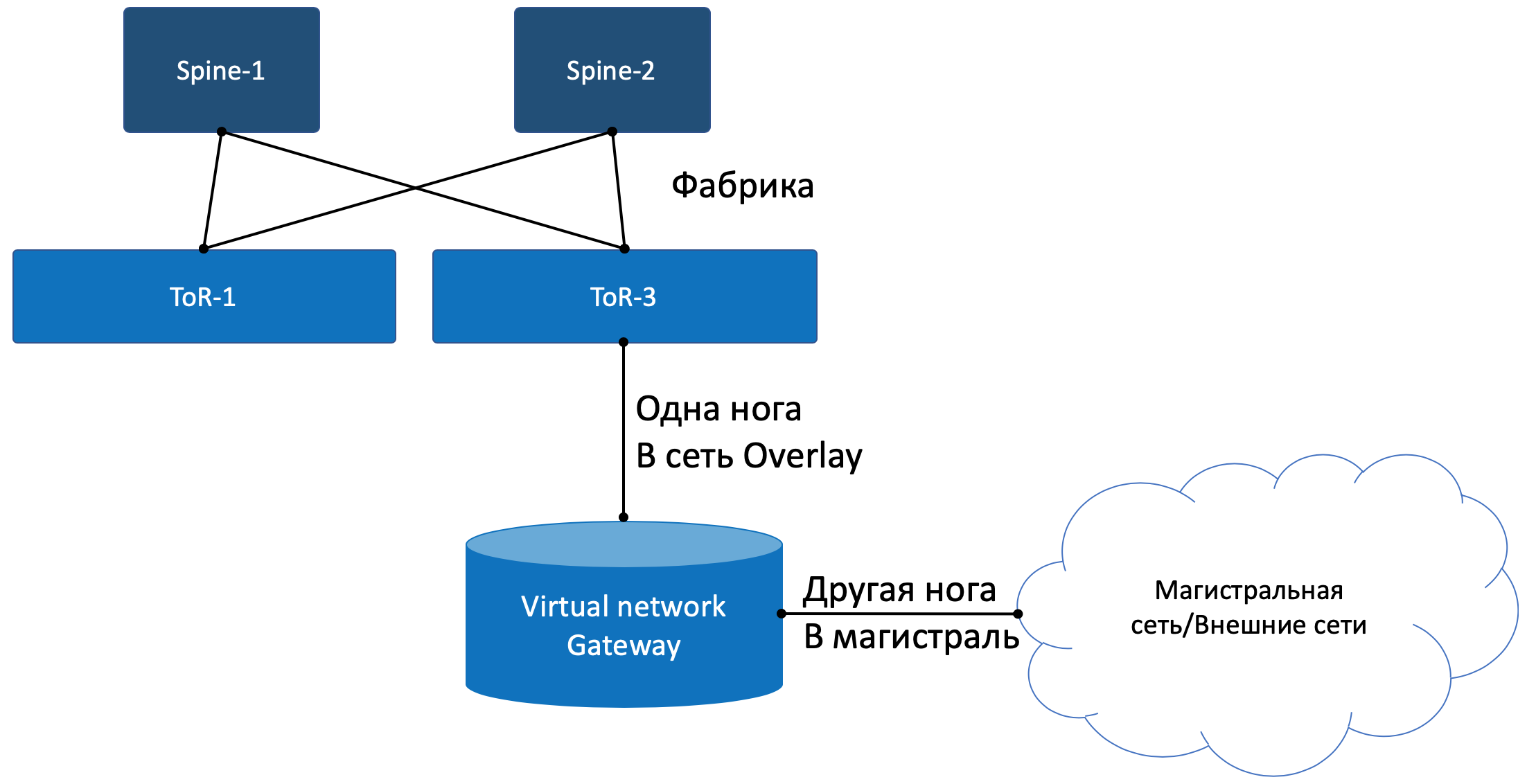
Overlay can begin on an access switch (ToR) that is in a rack, as is the case, for example, in the case of a VXLAN fabric.
This is a time-tested mechanism on the ISP networks and all network equipment vendors support it.
However, in this case, the ToR switch must be able to separate different services, respectively, and the network administrator must cooperate to a certain extent with the administrators of the virtual machines and make changes (albeit automatically) in the device configuration.
Here I will refer the reader to an article on VxLAN on the habr of our old friend @bormoglotx .
This presentation with ENOG describes in detail the approaches to building a DC network with an EVPN VXLAN factory.
And for a more complete immersion in reality, you can read tsiskinu book A Modern, Open, and Scalable Fabric: VXLAN EVPN .
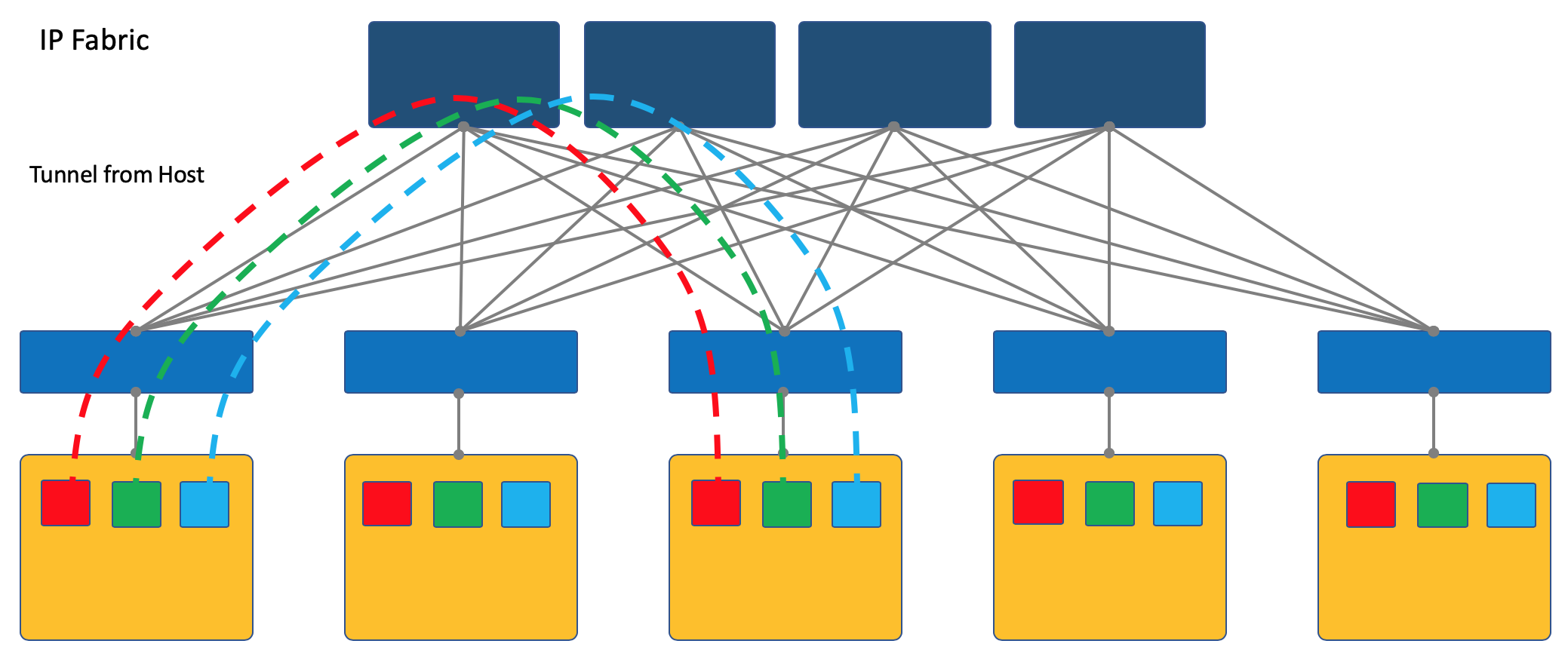
Another approach is to start and terminate tunnels on end hosts.
In this case, the network (Underlay) remains as simple and static as possible.
And the host itself does all the necessary encapsulations.
This will require, of course, run a special application on the hosts, but it is worth it.
First, it is easier to start the client on a linux machine or, let's say, in general, while the switch will most likely have to access proprietary SDN solutions for now, which kills the idea of multi-vendor.
Secondly, the ToR switch in this case can be left as simple as possible, both from the point of view of the Control Plane and the Data Plane. Indeed, it doesn’t need to communicate with the SDN controller, and it is enough to store the network / ARPs of all connected clients — also, you only need to know the IP address of the physical machine, which greatly simplifies the switching / routing tables.
In the ADSM series, I choose the overlay approach from the host - then we only talk about it and we will not return to the VXLAN factory.
The easiest way to look at examples. And as an experimental we will take the OpenSource SDN platform OpenContrail, now known as Tungsten Fabric .
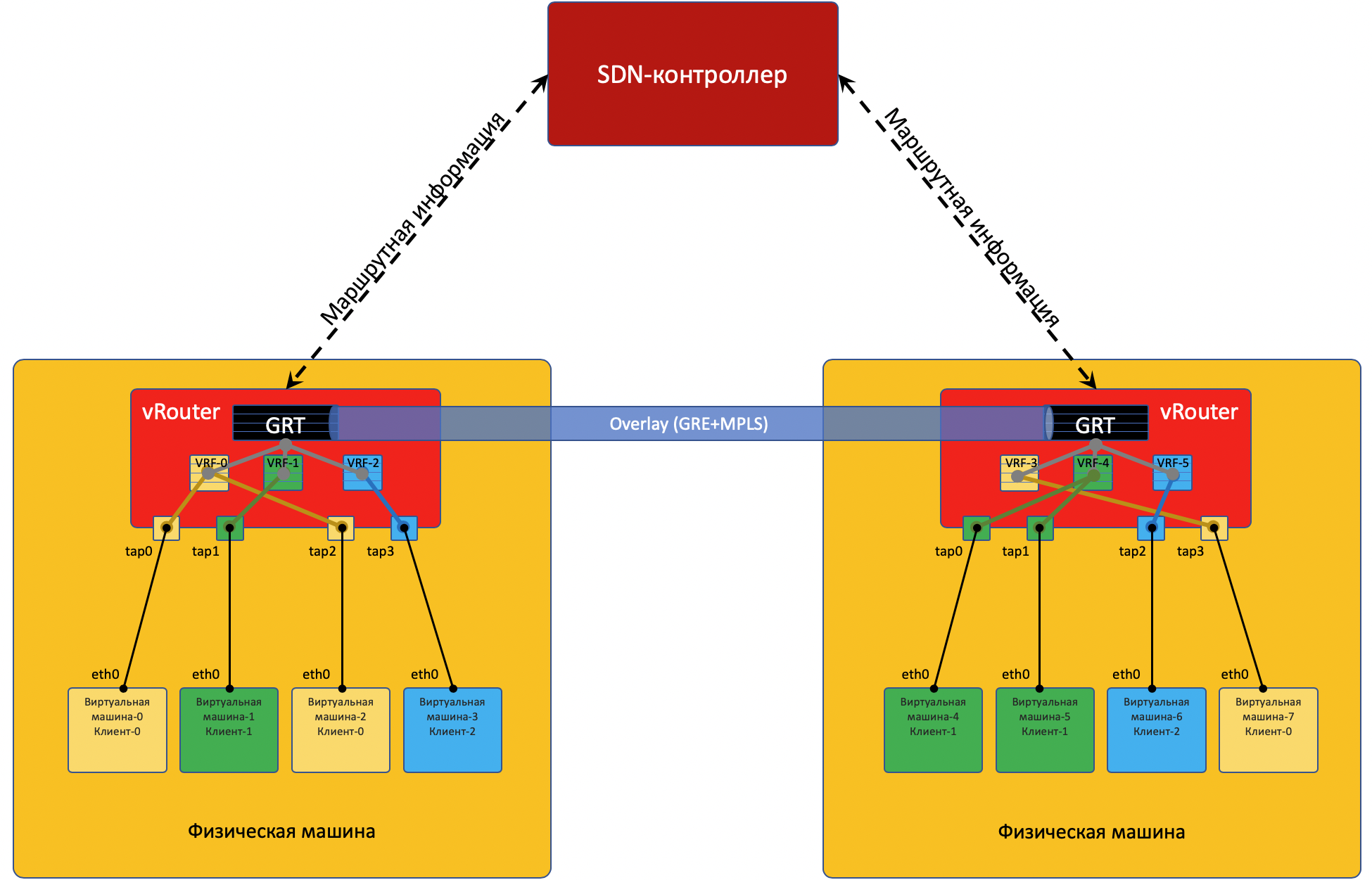
Each physical machine has a vRouter - a virtual router that knows about the networks connected to it and which clients they belong to - in fact - a PE router. For each client, it maintains an isolated routing table (read VRF). And actually vRouter does Overlay'no tunneling.
A little more about vRouter - at the end of the article.
Each VM located on the hypervisor connects to the vRouter of this machine via the TAP interface .
TAP - Terminal Access Point - a virtual interface in the linux kernel that allows network interaction.

If there are several networks behind vRouter, then for each of them a virtual interface is created, to which an IP address is assigned - it will be the address of the default gateway.
All networks of one client are placed in one VRF (one table), different - in different.
I will make a reservation here that everything is not so simple, and send an inquisitive reader to the end of the article .
In order for vRouters to communicate with each other, and accordingly the VMs behind them, they exchange routing information via an SDN controller .
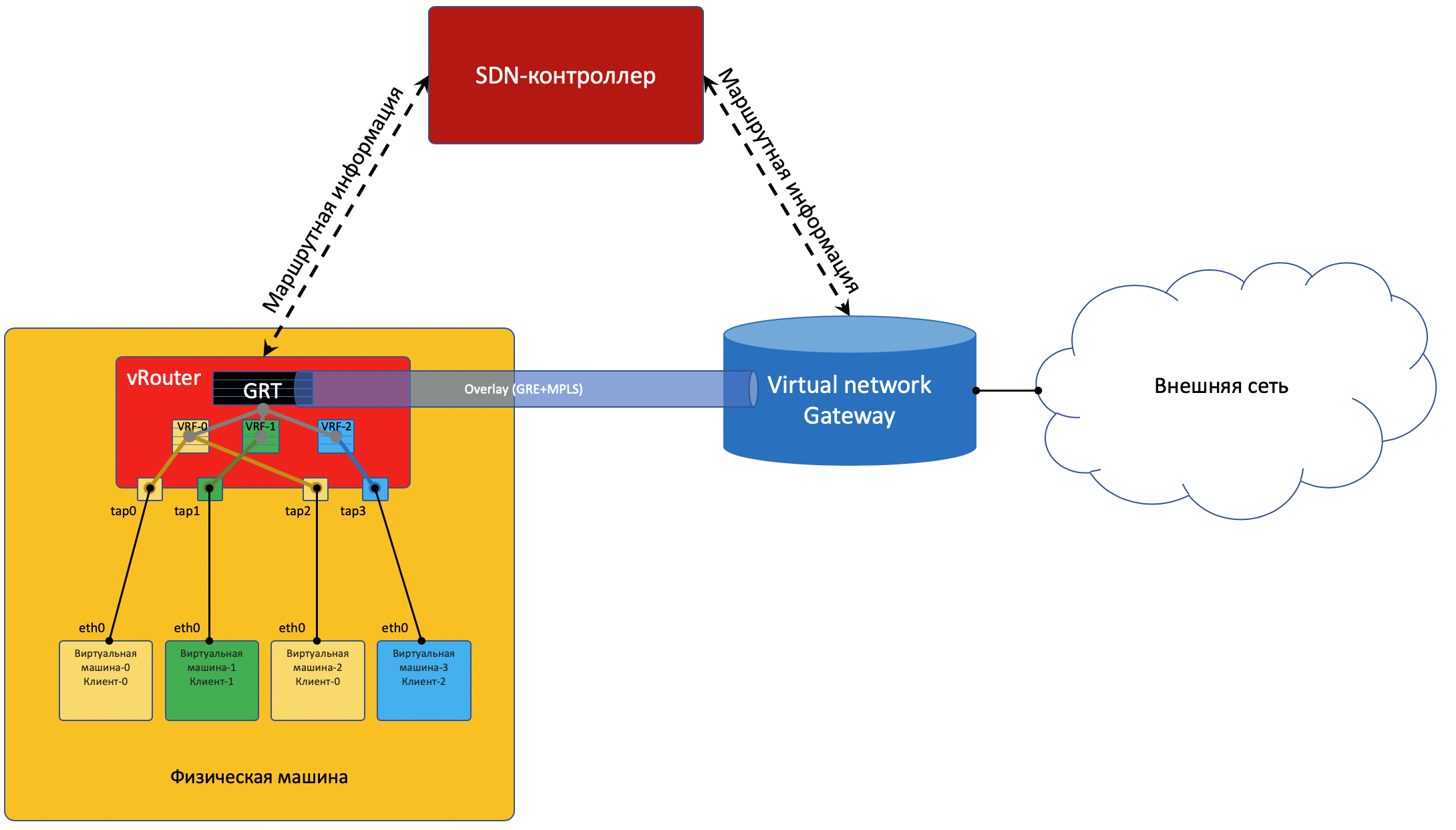
To get to the outside world, there is an exit point from the matrix — the VNGW virtual network gateway ( my term ).
Now consider the examples of communications - and there will be clarity.
VM0 wants to send a packet to VM2. Suppose for now that this is a VM of one client.
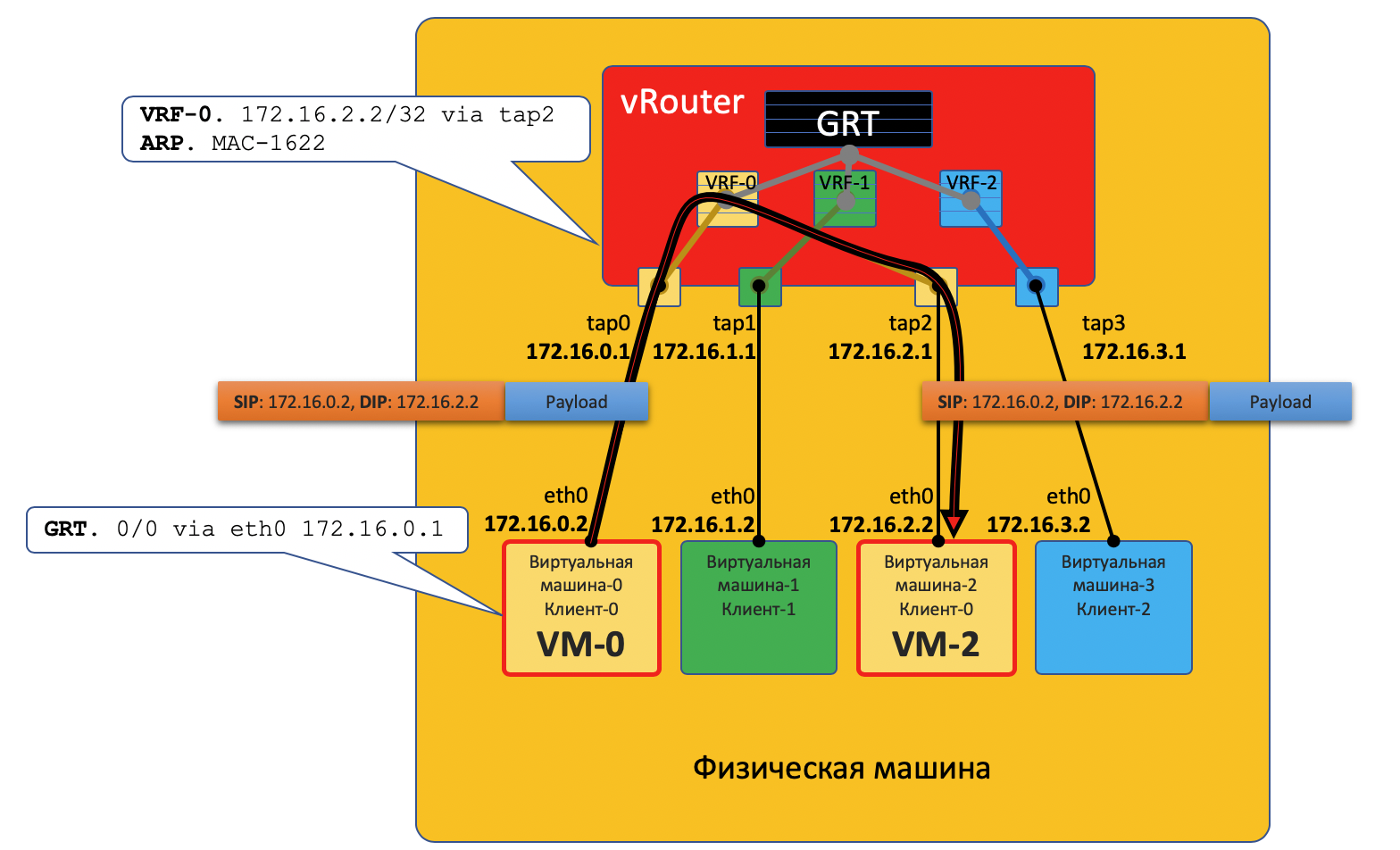
The packet in this case does not fall into the physical network - it was routed inside vRouter.
When the virtual machine starts, the hypervisor tells it:
vRouter through a special API hypervisor reports:

Thus, all VMs of a single client on a given machine vRouter sees how directly connected networks can be routed between them.
But VM0 and VM1 belong to different clients, respectively, are in different tables vRouter'a.
Whether they can communicate directly with each other depends on the vRouter settings and network design.
For example, if both clients' VMs use public addresses, or NAT occurs at the vRouter itself, then direct routing to the vRouter can be done.
In the opposite situation, it is possible to intersect address spaces - you need to go through a NAT server to get a public address - this looks like going out to external networks, which are described below.
When you start the machine, everything happens as described above.
And plus the following:
The same thing happens in the opposite direction.

Overlay can change at least every minute. Something like this happens in public clouds when customers regularly start and shut down their virtual machines.
The central controller assumes all the difficulties with maintaining the configuration and monitoring of the switching / routing tables on the vRouter.
Roughly speaking, the controller is locked with all vRouters via BGP (or a protocol similar to it) and simply sends routing information. BGP, for example, already has an Address-Family to transmit the MPLS-in-GRE or MPLS-in-UDP encapsulation method.
At the same time, the configuration of the Underlay-network does not change in any way, which, by the way, is much more difficult to automate by an order of magnitude, and easier to break with an awkward movement.
Somewhere the simulation must end, and from the virtual world you need to go to the real one. And you need apayphone gateway.
Practice two approaches:
With the other leg, the gateway is already looking into the backbone network and knows how to get on the Internet.
That is, the process looks like this:
Traffic in the opposite direction passes the same steps in the opposite order.

VNGW1 establishes a BGP neighborhood with an SDN controller, from which it receives all routing information about clients: which IP address (vRouter'om) which client is located, and which MPLS tag is it identified.
Similarly, he himself tells the SDN controller the default route with the label of this client, indicating itself as nexthop. And then this default comes to vRouters.
On VNGW, route aggregation or NAT translation usually occurs.
And in the other direction in the session with boarders or Route Reflectors, he gives exactly this aggregated route. And from them gets the default route or Full-View, or something else.
In terms of encapsulation and traffic exchange, VNGW is no different from vRouter.
If you expand the area a bit, then you can add other network devices to VNGW and vRouters, such as firewalls, traffic cleaning or traffic enrichment farms, IPS, and so on.
And with the help of sequential creation of the VRF and the correct announcement of the routes, you can force traffic to loop as you like, which is called Service Chaining.
That is, here the SDN controller acts as a Route-Reflector between VNGW, vRouters and other network devices.
But in fact, the controller also releases information about ACL and PBR (Policy Based Routing), forcing individual traffic flows to go differently than the route tells them.
Why do you always make a GRE / UDP remark?
Well, in general, it can be said that it is specific to Tungsten Fabric - you can not take it into account at all.
But if you take, then TF itself, while still being OpenContrail, supported both encapsulations: MPLS in GRE and MPLS in UDP.
UDP is good because in the Source Port in its header it is very easy to encode a hash function from the original IP + Proto + Port, which will allow balancing.
In the case of GRE, alas, there are only external headers IP and GRE, which are the same for all encapsulated traffic and we are not talking about balancing - few people can look so deep inside the packet.
Until some time, routers, if they knew how to use dynamic tunnels, then only in MPLSoGRE, and only very recently, did they learn in MPLSoUDP. Therefore, you always have to make a remark about the possibility of two different encapsulations.
In fairness, it is worth noting that TF fully supports L2 connectivity using VXLAN.
You promised to draw parallels with OpenFlow.
They are indeed asking for it. vSwitch in the same OpenStack does very similar things using VXLAN, which, by the way, also has a UDP header.
In Data Plane, they work about the same, the Control Plane is significantly different. Tungsten Fabric uses XMPP to deliver route information to the vRouter, while OpenStack is running Openflow.
Can I have a little more about vRouter?
It is divided into two parts: vRouter Agent and vRouter Forwarder.
The first is launched in the User Space of the host OS and communicates with the SDN controller, exchanging information about routes, VRF and ACL.
The second implements Data Plane - usually in Kernel Space, but it can also run on SmartNICs - network cards with a CPU and a separate programmable switching chip, which allows you to remove the load from the host’s CPU and make the network faster and more predictable.
Another possible scenario is when vRouter is a DPDK application in User Space.
vRouter Agent down the settings on the vRouter Forwarder.
What is the virtual network?
I mentioned at the beginning of the VRF article that they say each tenant is tied to its own VRF.And if this was sufficient for a superficial understanding of the work of the overlay network, then the next iteration should be clarified.
Usually, in the virtualization mechanisms, the essence of the Virtual Network (which can be considered as a proper name) is introduced separately from clients / tenants / virtual machines — quite an independent thing. And this Virtual Network through the interfaces can already be connected to one tenant, to another, to two, and at least where. So, for example, Service Chaining is implemented, when traffic needs to be passed through certain nodes in the right sequence, simply creating and setting up a Virtual Network in the correct sequence.
Therefore, as such, there is no direct correspondence between the Virtual Network and the tenant.
This is a very superficial description of the virtual network with an overlay from the host and an SDN controller. But whatever virtualization platform you take today, it will work in a similar way, be it VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric or Juniper Contrail. They will differ in the types of encapsulations and headers, protocols for delivering information to end network devices, but the principle of a software-configured overlay network running on a relatively simple and static underlay network will remain the same.
It can be said that the domain of creating a private cloud for today, SDN based on the overlay network has won. However, this does not mean that Openflow has no place in the modern world - it is used in OpenStacke and in the same VMWare NSX, as far as I know, it is used by Google to configure the underlay network.
Below, I gave references to more detailed materials if I want to study the issue further.
And what about our Underlay?
But in general, nothing. He did not change all the way. All he needs to do in the case of an overlay from the host is to update routes and ARPs as vRouter / VNGW appears and disappears and to drag packets between them.
Let's formulate a list of requirements for the Underlay network.
I devoted very little time to the work of the Underlay-network itself. This is because later in the series I’ll focus on her, and we will only touch Overlay in passing.
Obviously, I severely limit us all, using as an example the network of DCs built in the Kloza factory with pure IP routing and overlay from the host.
However, I am sure that any network that has a design can be described in formal terms and automated. It's just that I aim here to understand the approaches to automation, and not to confuse everyone in general, solving the problem in general.
In the framework of ADSM, Roman Gorge and I plan to publish a separate issue about the virtualization of computing power and its interaction with network virtualization. Stay in touch.
The same framework sets the order in which we will deal with the question.
And the network virtualization, to which this issue is dedicated, does not really fit into the subject of ADSM, where we disassemble automation.
But let's take a look at it from a different angle.
')
For a long time, many services have been using the same network. In the case of a carrier, these are 2G, 3G, LTE, broadband access and B2B, for example. In the case of DC: connectivity for different clients, the Internet, block storage, object storage.
And all services require isolation from each other. This is how overlay networks appeared.
And all the services do not want to wait for the person to configure them manually. That is how the orchestrators and SDN appeared.
The first approach to the systematic automation of the network, or rather its parts, has long been undertaken and implemented in many places: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Here with him today and ponder.
Content
- The reasons
- Terminology
- Underlay - physical network
- Overlay - virtual network
- Overlay with ToR'a
- Overlay from host
- On the example of Tungsten Fabric
- Communication within a single physical machine
- Communication between VMs located on different physical machines.
- Exit to the outside world
- FAQ
- Conclusion
- useful links
The reasons
And since we started talking about this, it is worth mentioning the prerequisites for network virtualization. In fact, this process did not begin yesterday.
Probably, you have often heard that the network has always been the most inert part of any system. And this is true in all senses. The network is the basis on which everything rests, and it is quite difficult to make changes on it - services do not tolerate when the network is lying. Often, decommissioning a single node can add up most of the applications and affect many customers. This is partly why the network team can resist any changes - because now it somehow works ( we may not even know how ), and here we need to configure something new, and it is not known how it will affect the network.
In order not to wait for networkers to drop VLANs and not to prescribe any services on each node of the network, people have come up with the use of overlays — overlay networks — of which there is a great variety: GRE, IPinIP, MPLS, MPLS L2 / L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE, etc.
Their appeal lies in two simple things:
- Only end nodes are configured - no need to touch transit nodes. This significantly speeds up the process, and sometimes even allows you to exclude the network infrastructure department from the process of entering new services.
- The load is hidden deep inside the headers - the transit nodes do not need to know anything about it, about the addressing on the hosts, the routes of the superimposed network. And this means you need to store less information in the tables, it means to take a simpler / cheaper device.
In this not quite high-grade release, I do not plan to disassemble all possible technologies, but rather describe the framework of work of overlay networks in DC.
The whole series will describe a data center consisting of rows of racks of the same type, in which the same server hardware is installed.
This equipment runs virtual machines / containers / serverless, implementing services.
Terminology
In the loop, I will call the server a program that implements the server side of client-server communication.
Physical machines in racks will not be called servers.
The physical machine is an x86 rack-mounted computer. The most commonly used term is host . So let's call it " machine " or host .
A hypervisor is an application running on a physical machine that emulates the physical resources on which Virtual Machines are started. Sometimes in literature and networks the word “hypervisor” is used as a synonym for “host”.
A virtual machine is an operating system running on a physical machine on top of the hypervisor. For us, in this cycle it is not so important whether it really is a virtual machine or just a container. Let's call it " VM "
Tenant is a broad concept that I will define in this article as a separate service or a separate client.
Multi-tenancy or multi-tenancy - using the same application by different clients / services. At the same time, the isolation of clients from each other is achieved due to the architecture of the application, rather than separately-running instances.
ToR - Top of the Rack switch - a switch mounted in a rack to which all physical machines are connected.
In addition to the topology of ToR, different providers practice End of Row (EoR) or Middle of Row (although the latter is a scornful rarity and I did not see MoR abbreviations).Underlay network or underlying network or underlay — physical network infrastructure: switches, routers, cables.
Overlay network or overlay network or overlay is a virtual network of tunnels running on top of the physical.
L3-factory or IP-factory - a terrific invention of mankind, which allows for interviews not to repeat STP and not to learn TRILL. A concept in which the entire network down to the access level is exclusively L3, without a VLAN and consequently huge stretched broadcast domains. Where does the word "factory" come from here?
SDN - Software Defined Network. Hardly needs any introduction. An approach to network management when changes on the network are performed not by a person, but by a program. Usually means taking Control Plane beyond the end network devices to the controller.
NFV - Network Function Virtualization - virtualization of network devices, suggesting that some of the network functions can be run as virtual machines or containers to speed up the introduction of new services, organize Service Chaining and more simple horizontal scalability.
VNF - Virtual Network Function. Specific virtual device: router, switch, firewall, NAT, IPS / IDS, etc.
I now intentionally simplify the description to a specific implementation in order not to confuse the reader much. For a more thoughtful reading, refer it to the Links section. In addition, Roma Gorga, who criticizes this article for inaccuracies, promises to write a separate issue about server and network virtualization technologies, which is deeper and more attentive to details.
Most networks today can be clearly divided into two parts:
Underlay is a physical network with a stable configuration.
Overlay - an abstraction over underlay to isolate tenants.
This is true both for the DC case (which we will discuss in this article) and for the ISP (which we will not analyze, because we already had it in the UFSR ). With enterprise networks, of course, the situation is somewhat different.
Network focused image:
Underlay
Underlay is a physical network: hardware switches and cables. Devices in the underlay know how to get to the physical machines.
It relies on standard protocols and technologies. Not least because hardware devices still work on proprietary software that does not allow chip programming or implementation of their protocols, respectively, compatibility with other vendors and standardization are needed.
But someone like Google can afford the development of its own switches and the rejection of generally accepted protocols. But LAN_DC is not Google.Underlay changes relatively rarely because its task is basic IP connectivity between physical machines. Underlay knows nothing about the services running on top of him, clients, tenants - he only needs to deliver the package from one machine to another.
Underlay can be for example:
- IPv4 + OSPF
- IPv6 + ISIS + BGP + L3VPN
- L2 + TRILL
- L2 + STP
The Underlay network is configured in the classic way: CLI / GUI / NETCONF.
Manually, scripts, proprietary utilities.
The next article of the cycle will be devoted to the underlay in more detail.
Overlay
Overlay - a virtual network of tunnels stretched over the Underlay, it allows the VMs of one client to communicate with each other, while providing isolation from other clients.
Client data is encapsulated in any tunneling headers for transmission over a common network.
So VMs of one client (one service) can communicate with each other through Overlay, without even knowing what path the package actually goes.
Overlay can be for example the same as I mentioned above:
- GRE tunnel
- VXLAN
- EVPN
- L3VPN
- GENEVE
An overlay network is usually configured and maintained through a central controller. From it, the configuration, Control Plane and Data Plane are delivered to devices that route and encapsulate client traffic. Below we analyze it in examples.
Yes, this is pure SDN.
There are two fundamentally different approaches to the organization of Overlay-network:
- Overlay with ToR'a
- Overlay from host
Overlay with ToR'a
Overlay can begin on an access switch (ToR) that is in a rack, as is the case, for example, in the case of a VXLAN fabric.
This is a time-tested mechanism on the ISP networks and all network equipment vendors support it.
However, in this case, the ToR switch must be able to separate different services, respectively, and the network administrator must cooperate to a certain extent with the administrators of the virtual machines and make changes (albeit automatically) in the device configuration.
Here I will refer the reader to an article on VxLAN on the habr of our old friend @bormoglotx .
This presentation with ENOG describes in detail the approaches to building a DC network with an EVPN VXLAN factory.
And for a more complete immersion in reality, you can read tsiskinu book A Modern, Open, and Scalable Fabric: VXLAN EVPN .
I note that VXLAN is only a method of encapsulation and tunnel termination can occur not on ToR'e, but on a host, as it happens in the case of OpenStack, for example.
However, the VXLAN factory where overlay starts at ToR is one of the well-established overlay network designs.
Overlay from host
Another approach is to start and terminate tunnels on end hosts.
In this case, the network (Underlay) remains as simple and static as possible.
And the host itself does all the necessary encapsulations.
This will require, of course, run a special application on the hosts, but it is worth it.
First, it is easier to start the client on a linux machine or, let's say, in general, while the switch will most likely have to access proprietary SDN solutions for now, which kills the idea of multi-vendor.
Secondly, the ToR switch in this case can be left as simple as possible, both from the point of view of the Control Plane and the Data Plane. Indeed, it doesn’t need to communicate with the SDN controller, and it is enough to store the network / ARPs of all connected clients — also, you only need to know the IP address of the physical machine, which greatly simplifies the switching / routing tables.
In the ADSM series, I choose the overlay approach from the host - then we only talk about it and we will not return to the VXLAN factory.
The easiest way to look at examples. And as an experimental we will take the OpenSource SDN platform OpenContrail, now known as Tungsten Fabric .
At the end of the article I will give some thoughts on the analogy with OpenFlow and OpenvSwitch.
On the example of Tungsten Fabric
Each physical machine has a vRouter - a virtual router that knows about the networks connected to it and which clients they belong to - in fact - a PE router. For each client, it maintains an isolated routing table (read VRF). And actually vRouter does Overlay'no tunneling.
A little more about vRouter - at the end of the article.
Each VM located on the hypervisor connects to the vRouter of this machine via the TAP interface .
TAP - Terminal Access Point - a virtual interface in the linux kernel that allows network interaction.
If there are several networks behind vRouter, then for each of them a virtual interface is created, to which an IP address is assigned - it will be the address of the default gateway.
All networks of one client are placed in one VRF (one table), different - in different.
I will make a reservation here that everything is not so simple, and send an inquisitive reader to the end of the article .
In order for vRouters to communicate with each other, and accordingly the VMs behind them, they exchange routing information via an SDN controller .
To get to the outside world, there is an exit point from the matrix — the VNGW virtual network gateway ( my term ).
Now consider the examples of communications - and there will be clarity.
Communication within a single physical machine
VM0 wants to send a packet to VM2. Suppose for now that this is a VM of one client.
Data plane
- VM-0 has a default route to its eth0 interface. The package is sent there.
This eth0 interface is actually virtually connected to the vRouter virtual router via the tap0 interface tap0. - vRouter analyzes which interface the packet came to, that is, which client (VRF) it belongs to, checks the address of the recipient with the routing table of this client.
- Finding that the recipient is on the same machine after another port, vRouter simply sends the packet to it without any additional headers - in this case, there is already an ARP entry on vRouter.
The packet in this case does not fall into the physical network - it was routed inside vRouter.
Control plane
When the virtual machine starts, the hypervisor tells it:
- Her own IP address.
- The default route is via the vRouter's IP address on this network.
vRouter through a special API hypervisor reports:
- What you need to create a virtual interface.
- What it (VM) needs to create a Virtual Network.
- To which VRF it (VN) to tie.
- Static ARP entry for this VM — what interface is its IP address and what MAC address is it associated with.
And again, the real interaction procedure is simplified in order to understand the concept.
Thus, all VMs of a single client on a given machine vRouter sees how directly connected networks can be routed between them.
But VM0 and VM1 belong to different clients, respectively, are in different tables vRouter'a.
Whether they can communicate directly with each other depends on the vRouter settings and network design.
For example, if both clients' VMs use public addresses, or NAT occurs at the vRouter itself, then direct routing to the vRouter can be done.
In the opposite situation, it is possible to intersect address spaces - you need to go through a NAT server to get a public address - this looks like going out to external networks, which are described below.
Communication between VMs located on different physical machines.
Data plane
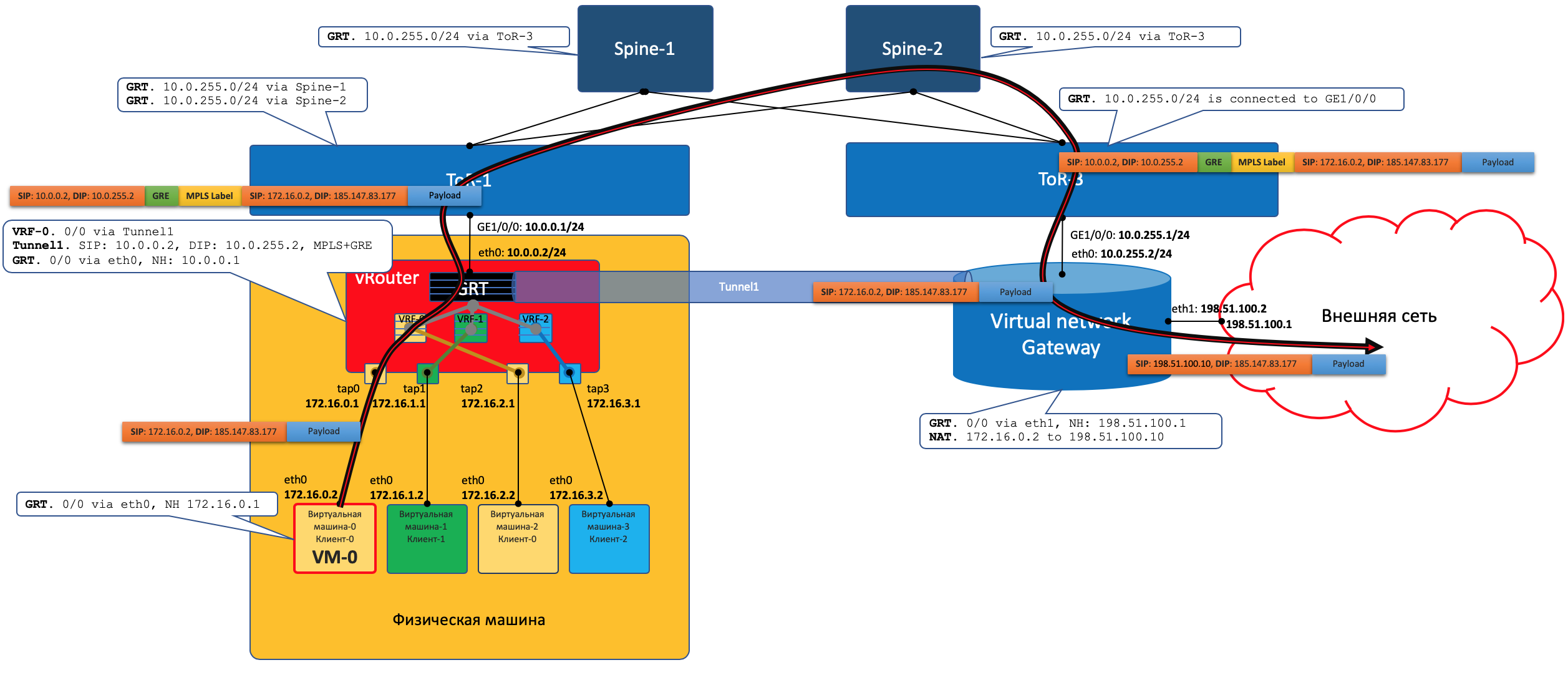
- The beginning is exactly the same: VM-0 sends a packet with a VM-7 destination (172.17.3.2) in its default.
- vRouter receives it and this time sees that the addressee is on another machine and is available through the Tunnel0 tunnel.
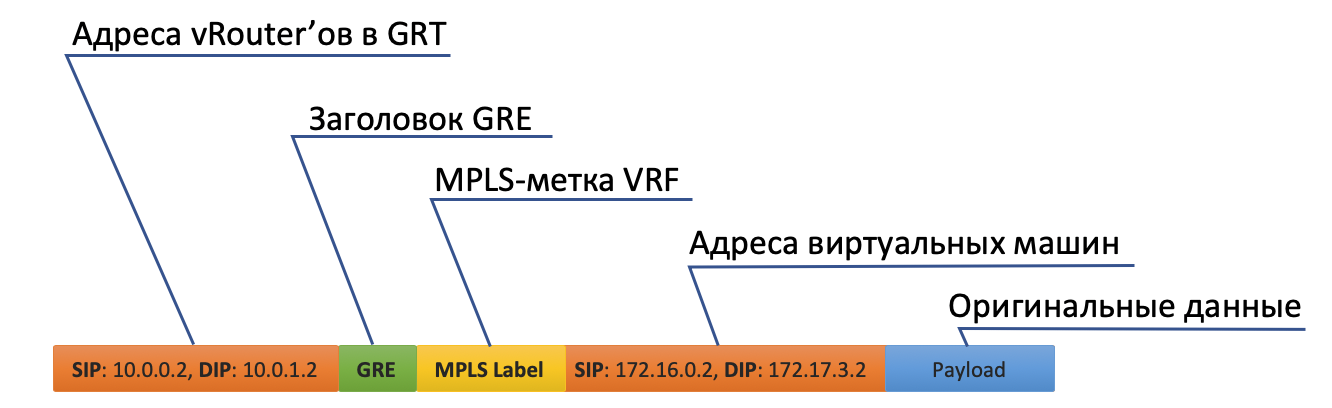
- First, he hangs the MPLS tag, which identifies the remote interface, so that on the reverse side of the vRouter can determine where to put this packet without additional lukapov.

- Tunnel0 has source 10.0.0.2, recipient: 10.0.1.2.
vRouter adds GRE (or UDP) headers and a new IP to the original packet. - In the vRouter routing table there is a default route through the address ToR1 10.0.0.1. There and sends.
- ToR1 as a member of the Underlay network knows (for example, via OSPF) how to get to 10.0.1.2, and sends the packet along the route. Please note that ECMP is enabled here. In the illustration, two nextopes and different streams will be decomposed into them according to a hash. In the case of a real factory, there will most likely be 4 nextopes.
At the same time, he does not need to know what is under the external IP header. That is, in fact, under the IP there can be a sandwich from IPv6 over MPLS over Ethernet over MPLS over GRE over over over Greco. - Accordingly, on the receiving side, vRouter removes the GRE and, using the MPLS tag, understands which interface this packet should be sent to, strips it and sends it to its original form to the recipient.
Control plane
When you start the machine, everything happens as described above.
And plus the following:
- For each client, vRouter allocates an MPLS tag. This is the service label L3VPN, according to which customers will be divided within the same physical machine.
In fact, the MPLS-tag is always highlighted by vRouter, because it is not known in advance that the machine will interact only with other machines behind the same vRouter, and this is most likely not the case.
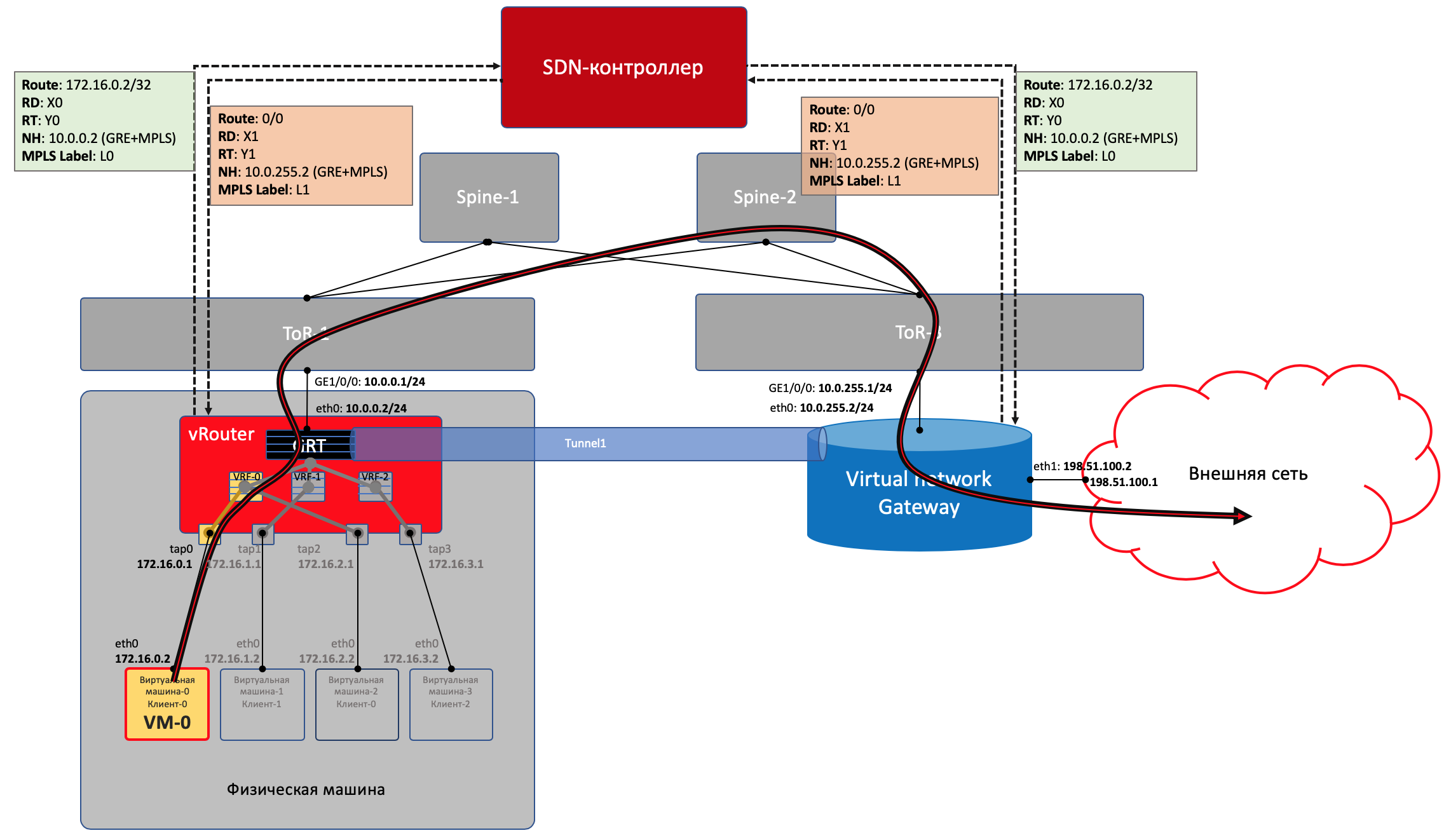
- vRouter establishes a connection with the SDN controller via BGP protocol (or similar to it — in the case of TF, this is XMPP 0_o).
- Through this session, vRouter informs the SDN controller the routes to the connected networks:
- Network address
- Encapsulation Method (MPLSoGRE, MPLSoUDP, VXLAN)
- MPLS client label
- Your IP address as nexthop
- The SDN controller receives such routes from all connected vRouters, and reflects them to others. That is, he stands Route Reflector'om.
The same thing happens in the opposite direction.
Overlay can change at least every minute. Something like this happens in public clouds when customers regularly start and shut down their virtual machines.
The central controller assumes all the difficulties with maintaining the configuration and monitoring of the switching / routing tables on the vRouter.
Roughly speaking, the controller is locked with all vRouters via BGP (or a protocol similar to it) and simply sends routing information. BGP, for example, already has an Address-Family to transmit the MPLS-in-GRE or MPLS-in-UDP encapsulation method.
At the same time, the configuration of the Underlay-network does not change in any way, which, by the way, is much more difficult to automate by an order of magnitude, and easier to break with an awkward movement.
Exit to the outside world
Somewhere the simulation must end, and from the virtual world you need to go to the real one. And you need a
Practice two approaches:
- Put a hardware router.
- Any appliance is launched that implements the functions of the router (yes, after SDN, we also ran into VNF). Let's call it a virtual gateway.
The advantage of the second approach in cheap horizontal scalability - not enough power - launched another virtual machine with a gateway. On any physical machine, without the need to search for free racks, units, power supply, buy the piece of hardware itself, carry it, install, switch, tune, and then change the faulty components in it.With one foot, the gateway looks into the Overlay virtual network, like a regular Virtual Machine, and can interact with all other VMs. At the same time, it can terminate the networks of all clients on itself and, accordingly, carry out routing between them.
The drawbacks of the virtual gateway are that the unit of the physical router is still orders of magnitude more powerful than the multi-core virtual machine, and its software, tailored to its hardware basis, is much more stable ( no ). It is difficult to deny the fact that the hardware and software complex just works, requiring only configuration, while launching and servicing the virtual gateway is an exercise for powerful engineers.
With the other leg, the gateway is already looking into the backbone network and knows how to get on the Internet.
Data plane
That is, the process looks like this:
- VM-0, having defaulted to the same vRouter, sends a packet with the addressee in the outside world (185.147.83.177) to the eth0 interface.
- vRouter receives this packet and makes a destination address in the routing table — finds the default route through the VNGW1 gateway through Tunnel 1.
He also sees that this is a GRE tunnel with SIP 10.0.0.2 and DIP 10.0.255.2, and you also need to first hang the MPLS tag of this client that VNGW1 expects. - vRouter packs the original packet in MPLS, GRE, and new IP headers and sends them to ToR1 10.0.0.1 by default.
- Anderlee network delivers the packet to the VNGW1 gateway.
- The VNGW1 gateway removes the GRE and MPLS tunneling headers, sees the destination address, consults its routing table, and understands that it is directed to the Internet — that is, via Full View or Default. If necessary, produces NAT-broadcast.
- From VNGW to a border, there can be a regular IP network, which is unlikely.
There may be a classic MPLS network (IGP + LDP / RSVP TE), it may be back factory with a BGP LU or a GRE tunnel from VNGW to a border through an IP network.
Be that as it may, VNGW1 performs the necessary encapsulations and sends the original packet towards the border.
Traffic in the opposite direction passes the same steps in the opposite order.
- Border drops package to VNGW1
- He undresses him, looks at the recipient's address and sees that he is available through the Tunnel1 tunnel (MPLSoGRE or MPLSoUDP).
- Accordingly, it hangs the MPLS tag, the GRE / UDP header and the new IP and sends it to its ToR3 10.0.255.1.
The destination address of the tunnel is the IP address of the vRouter, followed by the target VM - 10.0.0.2. - Anderley network delivers the package to the desired vRouter'a.
- The target vRouter removes GRE / UDP, identifies the interface by MPLS tag and sends a bare IP packet to its TAP interface associated with the eth0 VM.
Control plane
VNGW1 establishes a BGP neighborhood with an SDN controller, from which it receives all routing information about clients: which IP address (vRouter'om) which client is located, and which MPLS tag is it identified.
Similarly, he himself tells the SDN controller the default route with the label of this client, indicating itself as nexthop. And then this default comes to vRouters.
On VNGW, route aggregation or NAT translation usually occurs.
And in the other direction in the session with boarders or Route Reflectors, he gives exactly this aggregated route. And from them gets the default route or Full-View, or something else.
In terms of encapsulation and traffic exchange, VNGW is no different from vRouter.
If you expand the area a bit, then you can add other network devices to VNGW and vRouters, such as firewalls, traffic cleaning or traffic enrichment farms, IPS, and so on.
And with the help of sequential creation of the VRF and the correct announcement of the routes, you can force traffic to loop as you like, which is called Service Chaining.
That is, here the SDN controller acts as a Route-Reflector between VNGW, vRouters and other network devices.
But in fact, the controller also releases information about ACL and PBR (Policy Based Routing), forcing individual traffic flows to go differently than the route tells them.
FAQ
Why do you always make a GRE / UDP remark?
Well, in general, it can be said that it is specific to Tungsten Fabric - you can not take it into account at all.
But if you take, then TF itself, while still being OpenContrail, supported both encapsulations: MPLS in GRE and MPLS in UDP.
UDP is good because in the Source Port in its header it is very easy to encode a hash function from the original IP + Proto + Port, which will allow balancing.
In the case of GRE, alas, there are only external headers IP and GRE, which are the same for all encapsulated traffic and we are not talking about balancing - few people can look so deep inside the packet.
Until some time, routers, if they knew how to use dynamic tunnels, then only in MPLSoGRE, and only very recently, did they learn in MPLSoUDP. Therefore, you always have to make a remark about the possibility of two different encapsulations.
In fairness, it is worth noting that TF fully supports L2 connectivity using VXLAN.
You promised to draw parallels with OpenFlow.
They are indeed asking for it. vSwitch in the same OpenStack does very similar things using VXLAN, which, by the way, also has a UDP header.
In Data Plane, they work about the same, the Control Plane is significantly different. Tungsten Fabric uses XMPP to deliver route information to the vRouter, while OpenStack is running Openflow.
Can I have a little more about vRouter?
It is divided into two parts: vRouter Agent and vRouter Forwarder.
The first is launched in the User Space of the host OS and communicates with the SDN controller, exchanging information about routes, VRF and ACL.
The second implements Data Plane - usually in Kernel Space, but it can also run on SmartNICs - network cards with a CPU and a separate programmable switching chip, which allows you to remove the load from the host’s CPU and make the network faster and more predictable.
Another possible scenario is when vRouter is a DPDK application in User Space.
vRouter Agent down the settings on the vRouter Forwarder.
What is the virtual network?
I mentioned at the beginning of the VRF article that they say each tenant is tied to its own VRF.And if this was sufficient for a superficial understanding of the work of the overlay network, then the next iteration should be clarified.
Usually, in the virtualization mechanisms, the essence of the Virtual Network (which can be considered as a proper name) is introduced separately from clients / tenants / virtual machines — quite an independent thing. And this Virtual Network through the interfaces can already be connected to one tenant, to another, to two, and at least where. So, for example, Service Chaining is implemented, when traffic needs to be passed through certain nodes in the right sequence, simply creating and setting up a Virtual Network in the correct sequence.
Therefore, as such, there is no direct correspondence between the Virtual Network and the tenant.
Conclusion
This is a very superficial description of the virtual network with an overlay from the host and an SDN controller. But whatever virtualization platform you take today, it will work in a similar way, be it VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric or Juniper Contrail. They will differ in the types of encapsulations and headers, protocols for delivering information to end network devices, but the principle of a software-configured overlay network running on a relatively simple and static underlay network will remain the same.
It can be said that the domain of creating a private cloud for today, SDN based on the overlay network has won. However, this does not mean that Openflow has no place in the modern world - it is used in OpenStacke and in the same VMWare NSX, as far as I know, it is used by Google to configure the underlay network.
Below, I gave references to more detailed materials if I want to study the issue further.
And what about our Underlay?
But in general, nothing. He did not change all the way. All he needs to do in the case of an overlay from the host is to update routes and ARPs as vRouter / VNGW appears and disappears and to drag packets between them.
Let's formulate a list of requirements for the Underlay network.
- To be able to use some kind of routing protocol, in our situation - BGP.
- , , - .
- ECMP — .
- QoS, , ECN.
- NETCONF — .
I devoted very little time to the work of the Underlay-network itself. This is because later in the series I’ll focus on her, and we will only touch Overlay in passing.
Obviously, I severely limit us all, using as an example the network of DCs built in the Kloza factory with pure IP routing and overlay from the host.
However, I am sure that any network that has a design can be described in formal terms and automated. It's just that I aim here to understand the approaches to automation, and not to confuse everyone in general, solving the problem in general.
In the framework of ADSM, Roman Gorge and I plan to publish a separate issue about the virtualization of computing power and its interaction with network virtualization. Stay in touch.
useful links
- Tungsten Fabric Archvitecture .
- about:cloud . 6 ., TF.
- What Is Open vSwitch?
- VxLAN .
- RFC 7348. Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks.
- Scaleway approach to VXLAN EVPN Fabric . , Underlay, Overlay, - .
- — linkmeup, . . .
- — . .
- Valentina Sinitsyna - my colleague and expert in the field of Tungsten Fabric. For comments and edits.
- Artem Chernobay - linkmeup illustrator. For KDPV.
- Alexander Limonov. For meme "automato".
Source: https://habr.com/ru/post/458622/
All Articles