Do not forget to increase the chance of response to the client, using a second request in L7 balancing
Using nginx to balance HTTP traffic at the L7 level, it is possible to send a client request to the next application server if the target does not return a positive response. A sample of the passively checking the health of the application server showed the ambiguity of the documentation and the specificity of the server exclusion algorithms from the pool of working servers.
There are various ways to balance HTTP traffic. By OSI model levels, there are balancing technologies at the network, transport, and application levels. Depending on the scope of the application , their combinations can be used .
Traffic balancing technology has positive effects in the operation of the application and its maintenance. Here are some of them. Horizontal scaling of the application, in which the load is distributed among several nodes . Planned decommissioning of an application server due to removal of a client request flow from it. Implementation of the A / B strategy for testing the modified application functionality. Improving application resiliency by sending requests to properly functioning application servers .
The last function is implemented in two modes. In passive mode, the balancer in client traffic evaluates the responses of the target application server and, under certain conditions, excludes it from the pool of working servers. In the active mode, the balancer periodically independently sends requests to the application server at a given URI, and, based on certain characteristics of the response, decides to exclude it from the pool of working servers. Further, the balancer, under certain conditions, returns the application server to the pool of working servers.
')
Let us take a closer look at the passive check of the application server in the freely distributed nginx / 1.17.0 edition. Application servers are selected alternately with Round Robin algorithm, their weights are the same.
The three-step scheme presents a time section starting with sending a client request to the application server No. 2. A bright indicator characterizes requests / responses between the client and the balancer. Dark indicator - requests / responses between nginx and application servers.
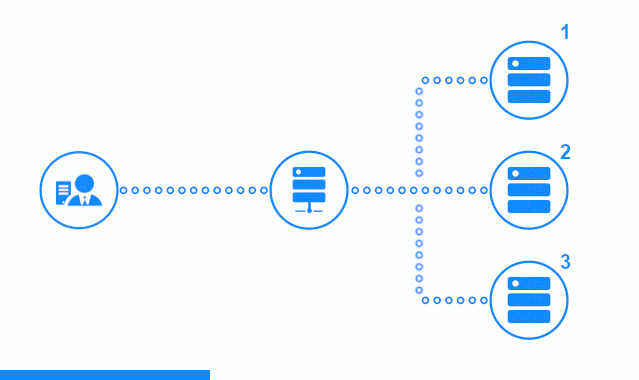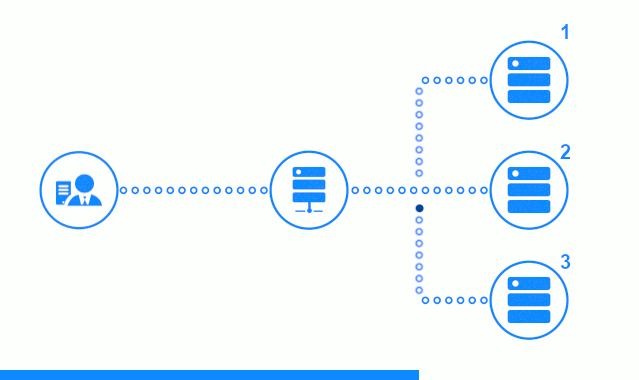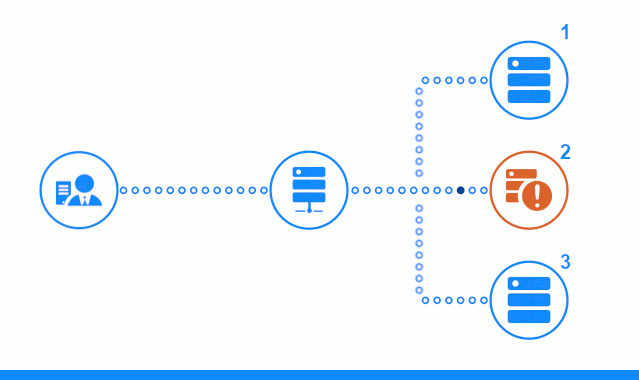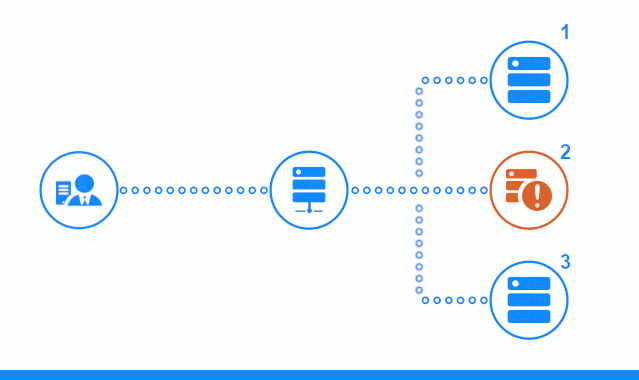
In the third step, the diagram shows how the balancer redirects the client's request to the next application server, in case the target server responded with an error or did not respond at all.
The list of HTTP and TCP errors for which the server uses the next server is specified in the directive proxy_next_upstream .
By default, nginx redirects only requests with idempotent HTTP methods to the next application server.
What does the client get? On the one hand, the ability to redirect a request to the next application server increases the chances of providing a satisfactory response to the client when the target server fails. On the other hand, it is obvious that sequential accessing first to the target server and then to the next one increases the total response time to the client.
In the end, the client returns the response of the application server, on which the proxy_next_upstream_tries valid attempts counter has ended .
When using the redirect function to the next working server, you need to further harmonize the timeouts on the balancer and application servers. The upper limit of the travel time of the request between the application servers and the balancer is the client timeout, or the waiting time defined by the business. When calculating timeouts, it is also necessary to take into account the stock of network events (delays / losses during the delivery of packets). If the client closes the session every time out while the balancer gets a guaranteed response, the good intention to make the application reliable will be in vain.

Management of the passive health check of application servers is performed by directives, for example, with the following variants of their values:
As of 07/02/2019 , the documentation states that the max_fails parameter specifies the number of unsuccessful attempts to work with the server that must occur within the time specified by the fail_timeout parameter.
The fail_timeout parameter specifies the time during which a specified number of failed attempts to work with the server should occur so that the server is considered unavailable; and the time during which the server will be considered unavailable.
In the given example of the part of the configuration file, the balancer is set to catch 5 failed hits for 100 seconds.
As follows from the documentation, the balancer after the expiration of fail_timeout cannot consider the server inoperable. But, unfortunately, the documentation is not explicitly stated how exactly the server’s performance is evaluated.
Without an experiment, one can only assume that the state verification mechanism is similar to the previously described one.
In the presented configuration, the following behavior is expected from the balancer:
After conducting natural tests, according to the balancer journals, it was established that approval number 3 does not work. The balancer eliminates an inoperative server as soon as the condition on the max_fails parameter is met . Thus, a faulty server is excluded from service without waiting for the expiration of 100 seconds. The fail_timeout parameter plays the role of only the upper limit of the error accumulation time.
In part of statement number 4, it turns out that nginx checks the operation of the application server previously excluded from service with only one request. And if the server still responds with an error, then the next check will take place after the fail_timeout expires .

I wanted to ask you if there is a practical benefit from the server health check algorithm, which evaluates the speed of unsuccessful attempts?
HTTP traffic balancing overview
There are various ways to balance HTTP traffic. By OSI model levels, there are balancing technologies at the network, transport, and application levels. Depending on the scope of the application , their combinations can be used .
Traffic balancing technology has positive effects in the operation of the application and its maintenance. Here are some of them. Horizontal scaling of the application, in which the load is distributed among several nodes . Planned decommissioning of an application server due to removal of a client request flow from it. Implementation of the A / B strategy for testing the modified application functionality. Improving application resiliency by sending requests to properly functioning application servers .
The last function is implemented in two modes. In passive mode, the balancer in client traffic evaluates the responses of the target application server and, under certain conditions, excludes it from the pool of working servers. In the active mode, the balancer periodically independently sends requests to the application server at a given URI, and, based on certain characteristics of the response, decides to exclude it from the pool of working servers. Further, the balancer, under certain conditions, returns the application server to the pool of working servers.
')
Passive check of the application server and its exclusion from the pool of working servers
Let us take a closer look at the passive check of the application server in the freely distributed nginx / 1.17.0 edition. Application servers are selected alternately with Round Robin algorithm, their weights are the same.
The three-step scheme presents a time section starting with sending a client request to the application server No. 2. A bright indicator characterizes requests / responses between the client and the balancer. Dark indicator - requests / responses between nginx and application servers.
In the third step, the diagram shows how the balancer redirects the client's request to the next application server, in case the target server responded with an error or did not respond at all.
The list of HTTP and TCP errors for which the server uses the next server is specified in the directive proxy_next_upstream .
By default, nginx redirects only requests with idempotent HTTP methods to the next application server.
What does the client get? On the one hand, the ability to redirect a request to the next application server increases the chances of providing a satisfactory response to the client when the target server fails. On the other hand, it is obvious that sequential accessing first to the target server and then to the next one increases the total response time to the client.
In the end, the client returns the response of the application server, on which the proxy_next_upstream_tries valid attempts counter has ended .
When using the redirect function to the next working server, you need to further harmonize the timeouts on the balancer and application servers. The upper limit of the travel time of the request between the application servers and the balancer is the client timeout, or the waiting time defined by the business. When calculating timeouts, it is also necessary to take into account the stock of network events (delays / losses during the delivery of packets). If the client closes the session every time out while the balancer gets a guaranteed response, the good intention to make the application reliable will be in vain.
Management of the passive health check of application servers is performed by directives, for example, with the following variants of their values:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... } As of 07/02/2019 , the documentation states that the max_fails parameter specifies the number of unsuccessful attempts to work with the server that must occur within the time specified by the fail_timeout parameter.
The fail_timeout parameter specifies the time during which a specified number of failed attempts to work with the server should occur so that the server is considered unavailable; and the time during which the server will be considered unavailable.
In the given example of the part of the configuration file, the balancer is set to catch 5 failed hits for 100 seconds.
Returning the application server to the working server pool
As follows from the documentation, the balancer after the expiration of fail_timeout cannot consider the server inoperable. But, unfortunately, the documentation is not explicitly stated how exactly the server’s performance is evaluated.
Without an experiment, one can only assume that the state verification mechanism is similar to the previously described one.
Expectations and reality
In the presented configuration, the following behavior is expected from the balancer:
- As long as the balancer does not exclude application server No. 2 from the pool of working servers, client requests will be sent to it.
- Requests returned with 500 errors from application server # 2 will be sent to the next application server, and the client will receive positive responses.
- As soon as the balancer within 5 seconds receives 5 responses with code 500, it will exclude application server No. 2 from the pool of working servers. All requests following the 100 second window will be immediately sent to the remaining working application servers without additional time.
- After 100 seconds the balancer must somehow assess the performance of the application server and return it to the pool of working servers.
After conducting natural tests, according to the balancer journals, it was established that approval number 3 does not work. The balancer eliminates an inoperative server as soon as the condition on the max_fails parameter is met . Thus, a faulty server is excluded from service without waiting for the expiration of 100 seconds. The fail_timeout parameter plays the role of only the upper limit of the error accumulation time.
In part of statement number 4, it turns out that nginx checks the operation of the application server previously excluded from service with only one request. And if the server still responds with an error, then the next check will take place after the fail_timeout expires .
What is missing?
- The algorithm implemented in nginx / 1.17.0 may not in a fair way check the server’s performance before returning it to the pool of working servers. At least, according to the current documentation, not 1 request is expected, but the quantity specified in max_fails .
- The state check algorithm does not take into account the speed of requests. The larger it is, the stronger the spectrum with unsuccessful attempts is shifted to the left, and the application server too quickly leaves the pool of working servers. I suppose that this may have a negative impact on applications that allow themselves to “give short errors in clots”. For example, when garbage collection.
I wanted to ask you if there is a practical benefit from the server health check algorithm, which evaluates the speed of unsuccessful attempts?
Source: https://habr.com/ru/post/458594/
All Articles