Ceph - from “on the knee” to “production” part 2
(the first part is here: https://habr.com/ru/post/456446/ )
CEPH
Introduction
Since the network is one of the key elements of Ceph, and it is a bit specific in our company - we will tell you a little about it first.
There will be much less descriptions of Ceph itself, mainly the network infrastructure. Only Ceph servers and some features of Proxmox virtualization servers will be described.
So: The network topology itself is built as Leaf-Spine. The classical three-tier architecture is a network where there are Core (core routers), Aggregation (aggregation routers) and directly connected to Access clients (access routers):
Three-level scheme
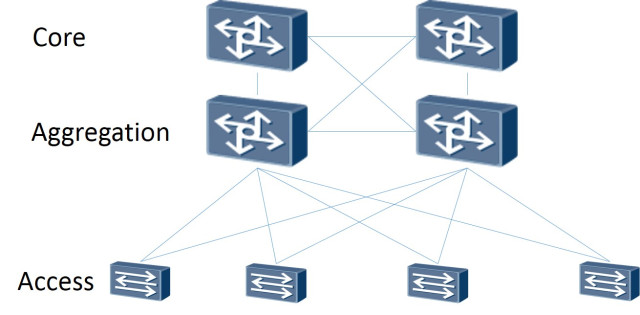
Leaf-Spine topology consists of two levels: Spine (roughly the main router) and Leaf (branches).
Two-tier scheme

All internal and external routing is built on BGP. The main system that deals with access management, announcements, etc. is XCloud.
Servers, to reserve a channel (as well as to expand it) are connected to two L3 switches (most servers are included in Leaf switches, but some servers with increased network load are connected directly to the Spine switch), and via BGP they announce their unicast address, as well as anycast address for the service, if several servers serve the service traffic and ECMP balancing is enough for them. A separate feature of this scheme, which allowed us to save on addresses, but also required engineers to get acquainted with the world of IPv6, was the use of the BGP unnumbered standard based on RFC 5549. For a while, to ensure that BGP works in this scheme for servers, Quagga was used and periodically There were problems with loss of peers and connectivity. But after the transition to FRRouting (whose active distributors are our network software vendors: Cumulus and XCloudNetworks), we didn’t observe any more such problems.
For convenience, we call this whole scheme "factory".
Finding the way
Cluster network setup options:
1) Second Network on BGP
2) Second network on two separate stacked switches with LACP
3) Second network on two separate isolated switches with OSPF
Tests
Tests were conducted in two types:
a) network, using iperf, qperf, nuttcp utilities
b) Ceph ceph-gobench internal tests, the rados bench, created rbd and tested it with dd in one and several streams using fio
All tests were performed on test machines with SAS disks. Rbd didn’t look much at the numbers themselves, only used for comparison. Interested in changes depending on the type of connection.
First option
Network cards are connected to the factory, configured by BGP.
Using this scheme for the internal network was considered not the best choice:
Firstly, an extra amount of intermediate elements in the form of switches, giving additional latency (this was the main reason).
Secondly, originally, to send statics via s3, they used anycast address, raised on several machines with radosgateway. This resulted in the fact that the traffic from the front-end machines to the RGW was not evenly distributed, but passed along the shortest route - that is, the front-end Nginx always addressed the node with the RGW that was connected to the common leaf (it was, of course, not the main argument - we simply refused to have anycast addresses for the return of statics). But for the purity of the experiment, they decided to conduct tests on such a scheme in order to have data for comparison.
We were afraid to run tests on the entire bandwidth, since the factory is used by prod servers, and if we filled up the links between the leaf and the spine, it would hurt some of the sales.
Actually, this was another reason for the rejection of such a scheme.
Iperf tests with a BW limit of 3Gbps at 1, 10, and 100 streams were used to compare with other schemes.
Tests showed the following results:
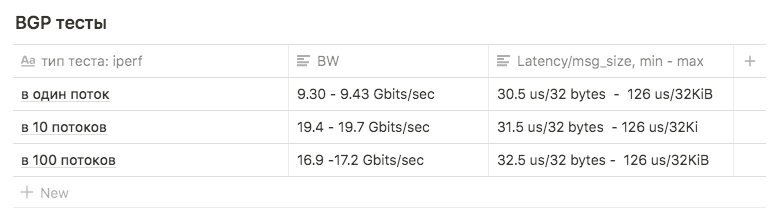
1 stream is approximately 9.30 - 9.43 Gbits / sec (at the same time the number of retransmitts grows to 39148 ). The figure turned out to be close to the maximum of one interface indicates that one of the two is used. The number of retransmit with about 500-600.
in 10 streams of 9.63 Gbits / sec per interface, while the number of retransmitts grew to an average of 17045.
in 100 streams, the result was worse than 10 , while the number of retransmitters is less: the average value is 3354
Second option
LACP
There were two Juniper EX4500 switches. We collected them into the stack, connected the servers with the first links to one switch, the second to the second.
The initial setting of the bond was:
root@ceph01-test:~# cat /etc/network/interfaces auto ens3f0 iface ens3f0 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f0 rx 8192 post-up /sbin/ethtool -G ens3f0 tx 8192 post-up /sbin/ethtool -L ens3f0 combined 32 post-up /sbin/ip link set ens3f0 txqueuelen 10000 mtu 9000 auto ens3f1 iface ens3f1 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f1 rx 8192 post-up /sbin/ethtool -G ens3f1 tx 8192 post-up /sbin/ethtool -L ens3f1 combined 32 post-up /sbin/ip link set ens3f1 txqueuelen 10000 mtu 9000 auto bond0 iface bond0 inet static address 10.10.10.1 netmask 255.255.255.0 slaves none bond_mode 802.3ad bond_miimon 100 bond_downdelay 200 bond_xmit_hash_policy 3 #(layer3+4 ) mtu 9000 The iperf and qperf tests showed Bw up to 16Gbits / sec. We decided to compare different types of mod:
rr, balance-xor and 802.3ad. Also, different types of hashing layer2 + 3 and layer3 + 4 were compared (hoping to gain an advantage on hash calculations).
We also compared the results for various sysctl values to the variable net.ipv4.fib_multipath_hash_policy, (well, we played a little with net.ipv4.tcp_congestion_control , although it has no relation to bonding. There is a good article on ValdikSS )).
But on all tests, it was not possible to overcome the threshold of 18Gbits / sec (this figure was achieved using balance-xor and 802.3ad , there was not much difference between them in the test results) and this value was achieved "in jump" by bursts.
Third option
Ospf
To configure this option, LACP was removed from the switches (stacking was left, but it was used only for management). Each switch has a separate vlan for a group of ports (with an eye to the future, that both QA and PROD servers will be plugged into the same switches).
Configured two flat private networks for each vlan (one interface per switch). On top of these addresses is the announcement of another address from the third private network, which is the cluster network for CEPH.
Since the public network (which we use for SSH) runs on BGP, we used frr, which is already in the system, to configure OSPF.
10.10.10.0/24 and 20.20.20.0/24 - two flat networks on the switches
172.16.1.0/24 - network for announcement
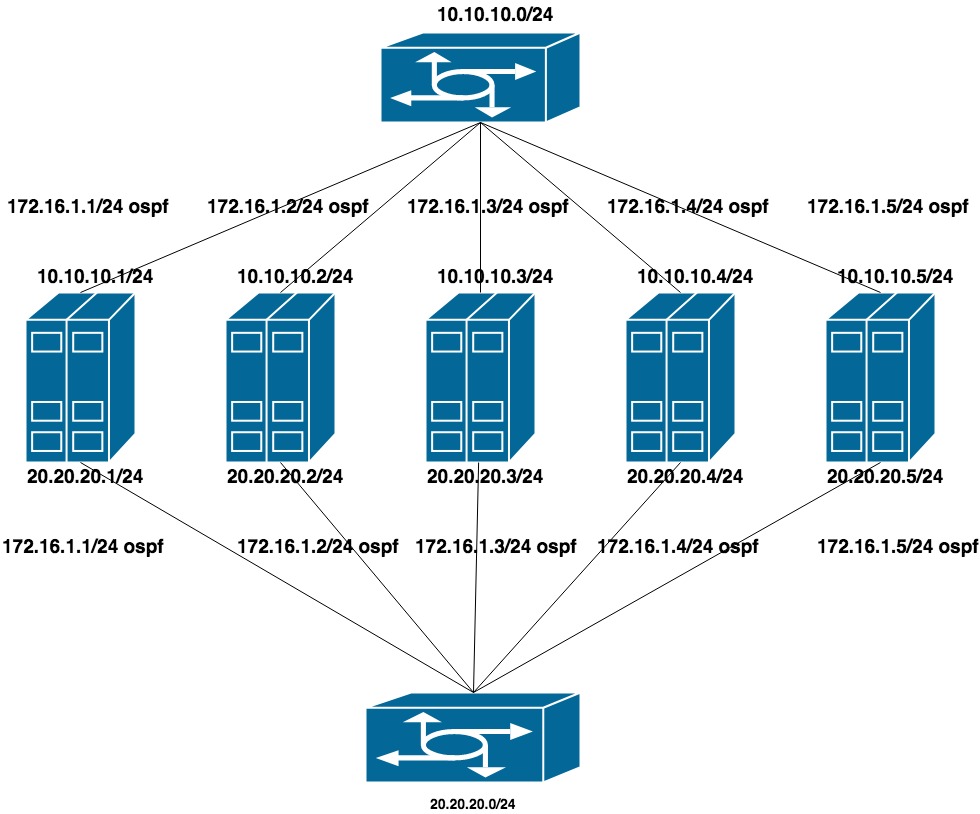
Machine setting:
interfaces ens1f0 ens1f1 look into the private network
interfaces ens4f0 ens4f1 look to the public network
The network config on the machine looks like this:
oot@ceph01-test:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto ens1f0 iface ens1f0 inet static post-up /sbin/ethtool -G ens1f0 rx 8192 post-up /sbin/ethtool -G ens1f0 tx 8192 post-up /sbin/ethtool -L ens1f0 combined 32 post-up /sbin/ip link set ens1f0 txqueuelen 10000 mtu 9000 address 10.10.10.1/24 auto ens1f1 iface ens1f1 inet static post-up /sbin/ethtool -G ens1f1 rx 8192 post-up /sbin/ethtool -G ens1f1 tx 8192 post-up /sbin/ethtool -L ens1f1 combined 32 post-up /sbin/ip link set ens1f1 txqueuelen 10000 mtu 9000 address 20.20.20.1/24 auto ens4f0 iface ens4f0 inet manual post-up /sbin/ethtool -G ens4f0 rx 8192 post-up /sbin/ethtool -G ens4f0 tx 8192 post-up /sbin/ethtool -L ens4f0 combined 32 post-up /sbin/ip link set ens4f0 txqueuelen 10000 mtu 9000 auto ens4f1 iface ens4f1 inet manual post-up /sbin/ethtool -G ens4f1 rx 8192 post-up /sbin/ethtool -G ens4f1 tx 8192 post-up /sbin/ethtool -L ens4f1 combined 32 post-up /sbin/ip link set ens4f1 txqueuelen 10000 mtu 9000 # loopback-: auto lo:0 iface lo:0 inet static address 55.66.77.88/32 dns-nameservers 55.66.77.88 auto lo:1 iface lo:1 inet static address 172.16.1.1/32 Frr configs look like this:
root@ceph01-test:~# cat /etc/frr/frr.conf frr version 6.0 frr defaults traditional hostname ceph01-prod log file /var/log/frr/bgpd.log log timestamp precision 6 no ipv6 forwarding service integrated-vtysh-config username cumulus nopassword ! interface ens4f0 ipv6 nd ra-interval 10 ! interface ens4f1 ipv6 nd ra-interval 10 ! router bgp 65500 bgp router-id 55.66.77.88 # , timers bgp 10 30 neighbor ens4f0 interface remote-as 65001 neighbor ens4f0 bfd neighbor ens4f1 interface remote-as 65001 neighbor ens4f1 bfd ! address-family ipv4 unicast redistribute connected route-map redis-default exit-address-family ! router ospf ospf router-id 172.16.0.1 redistribute connected route-map ceph-loopbacks network 10.10.10.0/24 area 0.0.0.0 network 20.20.20.0/24 area 0.0.0.0 ! ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32 ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 ! route-map ceph-loopbacks permit 10 match ip address prefix-list ceph-loopbacks ! route-map redis-default permit 10 match ip address prefix-list default-out ! line vty ! On these settings, network tests iperf, qperf, etc. showed maximum utilization of both channels at 19.8 Gbit / sec, while latency dropped to 20us
Bgp router-id field : Used to identify a node when processing route information and building routes. If not specified in the config, then one of the host IP addresses is selected. Different vendors of hardware and software may have different algorithms, in our case FRR used the largest IP address on the loopback. This led to two problems:
1) If we tried to hang another address (for example, a private one from the network 172.16.0.0) more than the current one, this led to a change in the router-id and, accordingly, to the reinstallation of the current sessions. And this means a short-term rupture and loss of network connectivity.
2) If we tried to hang up anycast address common to several machines and it was selected as a router-id , two nodes with the same router-id appeared on the network .
Part 2
After testing for QA, we started upgrading the combat Ceph.
NETWORK
Moving from one network to two
The cluster network parameter is one of those that cannot be changed on the fly by specifying its OSD via ceph tell osd. * Injectargs. Changing it in the config and restarting the entire cluster is a tolerable solution, but I really did not want to have even a small downtime. It is also impossible to restart one OSD with a new network parameter - at some point we would have two polclusters - the old OSD on the old network, the new ones on the new one. Fortunately, the cluster network parameter (as, by the way, and public_network) is a list, that is, you can specify several values. We decided to move gradually - first add a new network to the configs, then remove the old one. Ceph follows the list of networks sequentially - OSD starts working first with the network that is listed first in the list.
The difficulty was that the first network worked through bgp and was connected to one switch, and the second was connected to ospf and connected to others that were not physically connected with the first. At the time of the transition, it was necessary to have temporarily network access between the two networks. The customization feature of our factory was that ACLs cannot be configured on the network if it is not on the list advertised (in this case, it is “external” and the ACL for it can only be created externally. It was created on spain, but did not arrive on leaf).
The solution was a crutch, difficult, but it worked: to announce the internal network via bgp, simultaneously with ospf.
The sequence of the transition was as follows:
1) Configure the cluster network for ceph on two networks: via bgp and via ospf
There was nothing to change in the frr configs, string
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 does not limit us in the advertised addresses, the address for the internal network is raised on the loopback interface, it was enough for the routers to configure the reception of the announcement of this address.
2) Add a new network to the ceph.conf config
cluster network = 172.16.1.0/24, 55.66.77.88/27 and we start one by one to restart the OSD, until everyone switches to the 172.16.1.0/24 network .
root@ceph01-prod:~#ceph osd set noout # - OSD # . , # , OSD 30 . root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \ root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done 3) Then remove the extra network from the config
cluster network = 172.16.1.0/24 and repeat the procedure.
Everything, we smoothly moved to a new network.
References:
https://shalaginov.com/2016/03/26/online- topology-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/enmanzo/ceph-gobench
')
Source: https://habr.com/ru/post/458390/
All Articles