LLVM for Tensorflow, or the compiler of the era of the end of Moore's law
The TensorFlow ecosystem contains a number of compilers and optimizers operating at different levels of software and hardware stack. For those who use Tensorflow daily, this multilevel stack can generate difficult to understand errors, both compile times and runtimes, associated with the use of various kinds of hardware (GPU, TPU, mobile platforms, etc.)
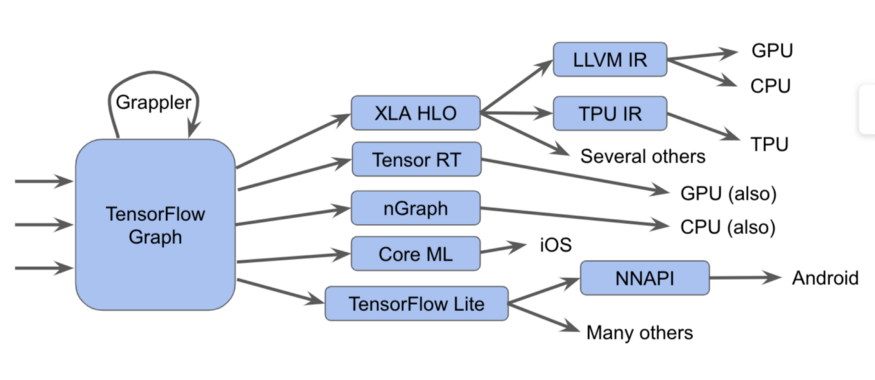
These components, starting with the Tensorflow graph, can be represented as such a diagram:
')
In fact, everything is more complicated
In this diagram, we can see that Tensorflow graphs can be run in several different ways.
For example:
There are also more sophisticated methods, including many optimization passes on each layer, such as in the Grappler framework, which optimizes operations in TensorFlow.
Although these various implementations of compilers and intermediate representations improve performance, their diversity presents a problem for end users, such as confusing error messages when pairing these subsystems. Also, the creators of new software and hardware stacks should adjust the optimization and conversion passes for each new case.
And because of all this, we are pleased to announce the MLIR, Multi-Level Intermediate Representation. It is an intermediate representation format and compilation libraries intended for use between a model representation and a low-level compiler that generates hardware-dependent code. Introducing MLIR, we want to give way to new research in the development of optimizing compilers and implementations of compilers built on components of industrial quality.
We expect MLIR to be of interest to many groups, including:
MLIR is, in fact, a flexible infrastructure for modern optimizing compilers. This means that it consists of a specification of an intermediate representation (IR) and a set of tools for converting this representation. When we talk about compilers, the transition from a higher-level representation to a lower-level representation is called lowering, and we will use this term in the future.
MLIR is built under the influence of LLVM and shamelessly borrows many good ideas from it. It has a flexible type system, and is designed to represent, analyze and convert graphs, combining multiple levels of abstraction in one compilation level. These abstractions include Tensorflow operations, nested regions of polyhedral cycles, LLVM instructions, and fixed-point operations and types.
In order to separate various software and hardware targets, MLIR has “dialects” including:
Each dialect contains a set of specific operations using invariants, such as: “this is a binary operator, and its input and output are of the same type”.
MLIR does not have a fixed and built-in list of global intrinsic operations. Dialects can define completely custom types, and thus MLIR can model things like the LLVM IR type system (having first class aggregates), domain language abstractions such as quantized types important for ML-optimized accelerators, and, in the future, even a Swift or Clang type system.
If you want to attach a new low-level compiler to this system, you can create a new dialect and descend from the dialect of the TensorFlow graph to your dialect. This simplifies the way for hardware developers and compiler developers. You can target the dialect at different levels of the same model; high-level optimizers will be responsible for specific parts of the IR.
For compiler researchers and framework developers, MLIR allows you to create transformations at every level, you can define your own operations and abstractions in IR, allowing you to better model your application tasks. Thus, MLIR is more than pure compiler infrastructure, which is LLVM.
Although MLIR works as a compiler for ML, it also allows you to use machine learning technology! This is very important for engineers who develop digital libraries and cannot provide support for the whole variety of ML-models and hardware. The flexibility of MLIR makes it easier to explore descent strategies for moving between levels of abstraction.
We have opened a GitHub repository and invite everyone interested (study our tutorial!). We will be releasing more than this toolkit - specifications for TensorFlow and TF Lite dialects in the coming months. We can tell you more to learn more, see Chris Luttner’s presentation and our README on Github .
If you want to be aware of all things related to MLIR, join our new mailing list , which will soon be focused on announcements of future releases of our project. Stay with us!
These components, starting with the Tensorflow graph, can be represented as such a diagram:
')
In fact, everything is more complicated
In this diagram, we can see that Tensorflow graphs can be run in several different ways.
note
In TensorFlow 2.0, columns can be implicit, greedy execution can run operations individually, in groups, or on a full graph. These graphs or graph fragments should be optimized and executed.
For example:
- We send graphs to the performer Tensorflow, which calls hand-written specialized kernels
- We convert them to XLA HLO (XLA High-Level Optimizer representation) —a high-level representation of the XLA optimizer, which in turn can invoke the LLVM compiler for a CPU or GPU, or continue to use XLA for TPU , or combine them.
- Convert them to TensorRT , nGraph , or another format for a specialized set of instructions implemented in hardware.
- Convert them to TensorFlow Lite format, running in TensorFlow Lite runtime, or converted to code for running on a GPU or DSP via Android Neural Networks API (NNAPI) or a similar way.
There are also more sophisticated methods, including many optimization passes on each layer, such as in the Grappler framework, which optimizes operations in TensorFlow.
Although these various implementations of compilers and intermediate representations improve performance, their diversity presents a problem for end users, such as confusing error messages when pairing these subsystems. Also, the creators of new software and hardware stacks should adjust the optimization and conversion passes for each new case.
And because of all this, we are pleased to announce the MLIR, Multi-Level Intermediate Representation. It is an intermediate representation format and compilation libraries intended for use between a model representation and a low-level compiler that generates hardware-dependent code. Introducing MLIR, we want to give way to new research in the development of optimizing compilers and implementations of compilers built on components of industrial quality.
We expect MLIR to be of interest to many groups, including:
- compiler researchers, as well as practitioners who want to optimize the performance and memory consumption of machine learning models;
- hardware manufacturers looking for a way to combine their hardware with Tensorflow, such as TPU, mobile neuroprocessors in smartphones, and other custom ASICs;
- people who want to give programming languages the benefits provided by optimizing compilers and hardware accelerators;
What is MLIR?
MLIR is, in fact, a flexible infrastructure for modern optimizing compilers. This means that it consists of a specification of an intermediate representation (IR) and a set of tools for converting this representation. When we talk about compilers, the transition from a higher-level representation to a lower-level representation is called lowering, and we will use this term in the future.
MLIR is built under the influence of LLVM and shamelessly borrows many good ideas from it. It has a flexible type system, and is designed to represent, analyze and convert graphs, combining multiple levels of abstraction in one compilation level. These abstractions include Tensorflow operations, nested regions of polyhedral cycles, LLVM instructions, and fixed-point operations and types.
MLIR dialects
In order to separate various software and hardware targets, MLIR has “dialects” including:
- TensorFlow IR, which includes everything that is possible to do in the TensorFlow columns
- XLA HLO IR, designed to get all the advantages provided by the XLA compiler, at the output of which we can get the code for TPU, and not only.
- Experimental affine dialect designed specifically for polyhedral representations and optimizations
- LLVM IR, 1: 1 matching LLVM's own representation, allowing MLIR to generate code for the GPU and CPU using LLVM.
- TensorFlow Lite, designed to generate code for mobile platforms
Each dialect contains a set of specific operations using invariants, such as: “this is a binary operator, and its input and output are of the same type”.
MLIR Extensions
MLIR does not have a fixed and built-in list of global intrinsic operations. Dialects can define completely custom types, and thus MLIR can model things like the LLVM IR type system (having first class aggregates), domain language abstractions such as quantized types important for ML-optimized accelerators, and, in the future, even a Swift or Clang type system.
If you want to attach a new low-level compiler to this system, you can create a new dialect and descend from the dialect of the TensorFlow graph to your dialect. This simplifies the way for hardware developers and compiler developers. You can target the dialect at different levels of the same model; high-level optimizers will be responsible for specific parts of the IR.
For compiler researchers and framework developers, MLIR allows you to create transformations at every level, you can define your own operations and abstractions in IR, allowing you to better model your application tasks. Thus, MLIR is more than pure compiler infrastructure, which is LLVM.
Although MLIR works as a compiler for ML, it also allows you to use machine learning technology! This is very important for engineers who develop digital libraries and cannot provide support for the whole variety of ML-models and hardware. The flexibility of MLIR makes it easier to explore descent strategies for moving between levels of abstraction.
What's next
We have opened a GitHub repository and invite everyone interested (study our tutorial!). We will be releasing more than this toolkit - specifications for TensorFlow and TF Lite dialects in the coming months. We can tell you more to learn more, see Chris Luttner’s presentation and our README on Github .
If you want to be aware of all things related to MLIR, join our new mailing list , which will soon be focused on announcements of future releases of our project. Stay with us!
Source: https://habr.com/ru/post/457826/
All Articles