How to make containers even more isolated: an overview of container sandbox technologies
Despite the fact that most of the IT industry implements infrastructure solutions based on containers and cloud solutions, it is necessary to understand the limitations of these technologies. Traditionally, Docker, Linux Containers (LXC) and Rocket (rkt) are not truly isolated because they share the core of the parent operating system in their work. Yes, they are efficient in terms of resources, but the total number of perceived attack vectors and potential losses from hacking are still large, especially in the case of a multi-tenant cloud environment in which the containers are located.

The root of our problem lies in the weak delimitation of containers at the moment when the host operating system creates a virtual user area for each of them. Yes, research and development has been carried out aimed at creating real “containers” with a full-fledged sandbox. And the majority of the solutions obtained lead to the restructuring of the boundaries between the containers in order to enhance their isolation. In this article, we will look at four unique projects from IBM, Google, Amazon, and OpenStack, respectively, that use different methods to achieve the same goal: to create reliable isolation. For example, IBM Nabla deploys containers on top of Unikernel, Google gVisor creates a dedicated guest kernel, Amazon Firecracker uses an extremely lightweight hypervisor for sandbox applications, and OpenStack places containers in a specialized virtual machine optimized for orchestra tools.
Containers are a modern way to pack, share, and deploy an application. Unlike a monolithic application, in which all functions are packaged into one program, container applications or microservices are designed for narrow purposeful use and specialize only in one task.
')
The container includes all the dependencies (for example, packages, libraries, and binary files) that an application needs to perform its particular task. As a result, containerized applications are platform independent and can run on any operating system regardless of its version or installed packages. This convenience saves developers from a huge piece of work on adapting different versions of software for different platforms or clients. Although conceptually this is not entirely accurate, many people like to think of containers as “lightweight virtual machines.”
When a container is deployed on a host, the resources of each container, such as its file system, process, and network stack, are placed in a virtually isolated environment that other containers cannot access. This architecture allows you to simultaneously run hundreds and thousands of containers in a single cluster, and each application (or microservice) can then easily be scaled by replicating a large number of instances.
In this case, the container deployment is based on two key “building blocks”: the Linux namespace and the Linux control groups (cgroups).
The namespace creates a virtually isolated user space and provides the application with dedicated system resources, such as the file system, the network stack, the process ID, and the user ID. In this isolated user space, the application controls the root directory of the file system and can be run as root. This abstract space allows each application to work independently, without interfering with other applications living on the same host. There are now six namespaces available: mount, inter-process communication (ipc), UNIX time-sharing system (uts), process id (pid), network and user. It is proposed to add two additional namespaces to this list: time and syslog, but the Linux community has not yet decided on the final specifications.
Cgroups provide limited hardware resources, prioritization, monitoring and control of the application. As an example of hardware resources that they can manage, you can call the processor, memory, device, and network. By combining namespaces and cgroups, we can safely run multiple applications on the same host, with each application in its own isolated environment — which is a fundamental property of the container.
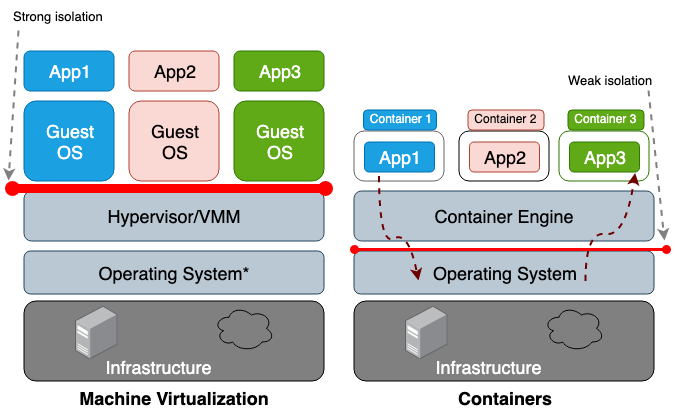
The main difference between a virtual machine (VM) and a container is that the virtual machine is virtualization at the hardware level, and the container is virtualization at the operating system level. The VM hypervisor emulates the hardware environment for each machine, where the container runtime already in turn emulates the operating system for each object. Virtual machines share the physical hardware of the host, and the containers share both the hardware and the OS kernel. Because containers in general share more resources with a host, their work with storage, memory, and CPU cycles is much more efficient than that of a virtual machine. However, the disadvantage of such a public access is problems in the information security plane, since too much trust is established between the containers and the host. Figure 1 illustrates the architectural difference between a container and a virtual machine.
In general, the isolation of virtualized equipment creates a much stronger security perimeter than just the isolation of the namespace. The risk that an attacker successfully leaves an isolated process is much higher than the chance of successfully exiting the virtual machine. The reason for the higher risk of going beyond the confined environment of containers is the weak isolation created by the namespace and cgroups. Linux implements them by associating new property fields with each process. These fields in the
Most kernel exploits create a vector for a successful attack, since they usually translate into privilege escalation and allow a compromised process to gain control outside its intended namespace. In addition to attack vectors in the context of software vulnerabilities, incorrect configuration can also play a role. For example, deploying images with excessive privileges (CAP_SYS_ADMIN, privileged access) or critical mount points (
These problems motivate researchers to create stronger security perimeters. The idea is to create a real sandbox-container, as isolated as possible from the main OS. Most of these solutions include the development of a hybrid architecture that uses a strict demarcation of the application and the virtual machine, and focuses on improving the efficiency of container solutions.
At the time of this writing, there was not a single project that could be called mature enough to be taken as a standard, but in the future, developers will undoubtedly accept some of these concepts as basic ones.
We begin our review with Unikernel, the oldest highly specialized system that packs an application into a single image using the minimum set of operating system libraries. The very concept of Unikernel turned out to be fundamental for a variety of projects whose goal was to create safe, compact and optimized images. After that, we will proceed to reviewing IBM Nabla, a project for launching Unikernel applications, including containers. In addition, we have Google gVisor - a project to launch containers in user kernel space. Next, we will switch to container solutions based on virtual machines - Amazon Firecracker and OpenStack Kata. Summarize this post by comparing all the above solutions.
The development of virtualization technology has allowed us to move to cloud computing. Hypervisors like Xen and KVM laid the foundation for what we now know as Amazon Web Services (AWS) and the Google Cloud Platform (GCP). And although modern hypervisors are able to work with hundreds of virtual machines combined into a single cluster, traditional general-purpose operating systems are not too adapted and optimized for work in such an environment. A general-purpose OS is designed primarily to support and work with as many diverse applications as possible, so their kernels include all types of drivers, libraries, protocols, schedulers, and so on. However, most virtual machines deployed somewhere in the cloud are used to run a single application, for example, to ensure the operation of a DNS, proxy, or some kind of database. Since such a separate application relies in its work only on a specific and small section of the OS kernel, all its other “body kits” simply idle system resources, and by the very fact of their existence they increase the number of vectors for a potential attack. After all, the larger the code base, the more difficult it is to eliminate all the flaws, and the more potential vulnerabilities, errors and other weaknesses. This problem encourages specialists to develop highly specialized operating systems with a minimal set of core functionality, that is, to create tools to support one specific application.
The idea of Unikernel was born for the first time back in the 90s. At the same time, he took shape as a specialized image of a machine with a single address space that can work directly on hypervisors. It packs the core and dependent applications and kernel functions into a single image. Nemesis and Exokernel are the two earliest research versions of the Unikernel project. The packaging and deployment process is shown in Figure 2.
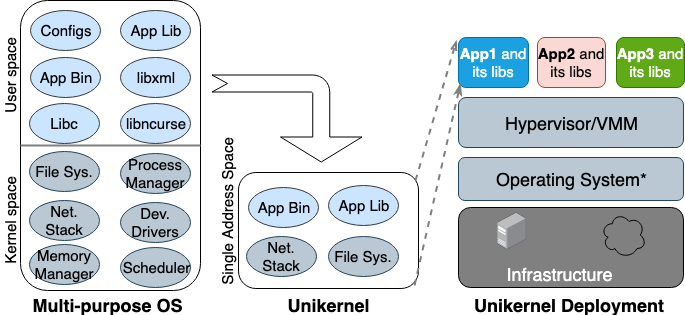
Figure 2. Multi-purpose operating systems are designed to support all types of applications, so many libraries and drivers are loaded into them in advance. Unikernels are highly specialized operating systems that are designed to support one specific application.
Unikernel splits the kernel into several libraries and places only necessary components into the image. Like regular virtual machines, unikernel is deployed and runs on the VM hypervisor. Due to its small size, it can load quickly and also scale quickly. The most important features of Unikernel are enhanced security, small footprint, high degree of optimization and fast loading. Since these images contain only application-dependent libraries, and the OS shell is inaccessible, if it was not connected purposefully, then the number of attack vectors that attackers can use them is minimal.
That is, it is not only difficult for an attacker to gain a foothold in these unique cores, but their influence is also limited to one copy of the core. Since the size of Unikernel images is only a few megabytes, they load in tens of milliseconds, and literally hundreds of copies can be launched on one host. Using memory allocation in a single address space instead of a multi-level page table, as is the case in most modern operating systems, unikernel applications have a lower memory access delay compared to the same application running on a regular virtual machine. Since applications build together with the kernel when building an image, compilers can simply perform static type checking to optimize binary files.
The Unikernel.org website maintains a list of unikernel projects. But with all its distinctive features and properties, unikernel was not widely used. When Docker acquired Unikernel Systems in 2016, the community decided that the company would now pack containers in them. But three years have passed, and there are still no signs of integration. One of the main reasons for this slow implementation is that there is still no mature tool for creating Unikernel applications, and most of these applications can only work on certain hypervisors. In addition, porting an application to unikernel may require manual rewriting of code in other languages, including rewriting dependent kernel libraries. It is also important that monitoring or debugging in unikernels is either impossible or has a significant impact on performance.
All these restrictions keep developers from switching to this technology. It should be noted that unikernel and containers have many similar properties. Both the first and second are narrowly focused, unchangeable images, which means that the components inside them cannot be updated or corrected, that is, for the application patch, you always have to create a new image. Today, Unikernel is similar to Docker's ancestor: then the container runtime was inaccessible, and developers had to use the basic tools for building an isolated application environment (chroot, unshare, and cgroups).
Some time ago, researchers from IBM proposed the concept of “Unikernel as a process” - that is, an unikernel application that would run as a process on a specialized hypervisor. The IBM project “Nabla containers” strengthened the unikernel security perimeter, replacing the universal hypervisor (for example, QEMU) with its own development called Nabla Tender. The rationale for this approach is that calls between unikernel and the hypervisor still provide the most vectors to attack. That is why the use of a dedicated unikernel hypervisor with a smaller number of allowed system calls can significantly strengthen the security perimeter. Nabla Tender intercepts calls that unikernel sends to the hypervisor, and already translates them into system requests. At the same time, the seccomp Linux policy blocks all other system calls that are not needed for the operation of the Tender. Thus, Unikernel in conjunction with the Nabla Tender runs as a process in the user space of the host. Below, in Figure 3, it is reflected how Nabla creates a thin interface between unikernel and the host.
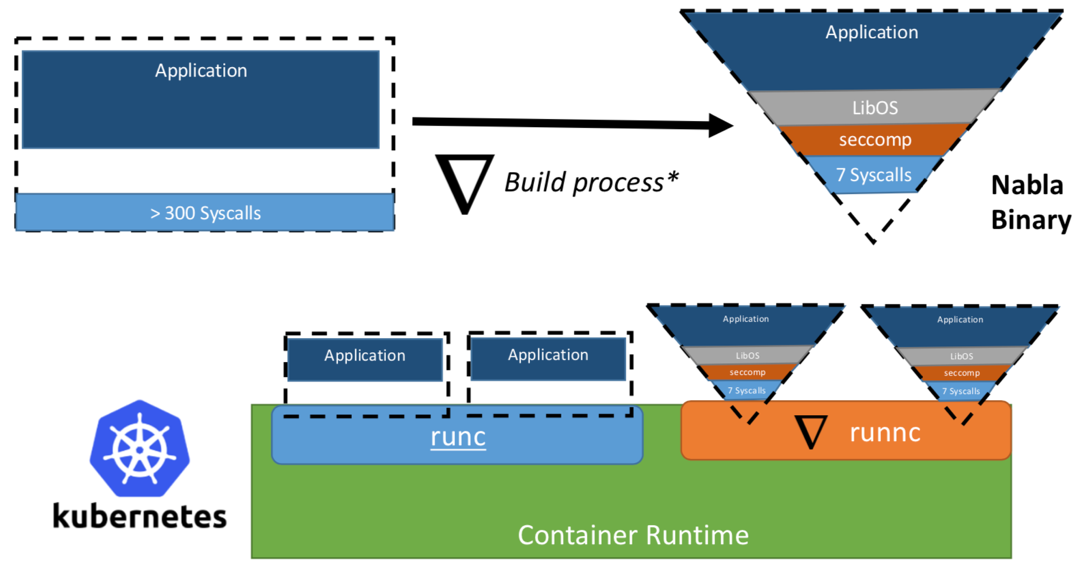
Figure 3. To link Nabla to existing container runtime platforms, Nabla uses an OCI-compatible environment, which in turn can be connected to Docker or Kubernetes.
The developers claim that Nabla Tender uses in its work less than seven system calls to interact with the host. Since system calls serve as a kind of bridge between processes in user space and the operating system kernel, the less system calls available to us, the smaller the number of vectors available to attack the kernel. Another advantage of running unikernel as a process is that debugging of such applications can be performed using a large number of tools, for example, using gdb.
To work with the container orchestration platforms, Nabla provides a dedicated
Google gVisor is a sandbox technology using the Google Cloud Platform (GCP) application engine, cloud functions and CloudML. At some point, Google realized the risk of running unreliable applications in the public cloud infrastructure and the inefficiency of sandbox applications using virtual machines. As a result, a user-space kernel was developed for the isolated environment of such unreliable applications. gVisor puts these applications in a sandbox, intercepting all system calls from them to the host kernel and processing them in the user environment using the gVisor Sentry core. In essence, it functions as a combination of the guest core and the hypervisor. Figure 4 shows the gVisor architecture.
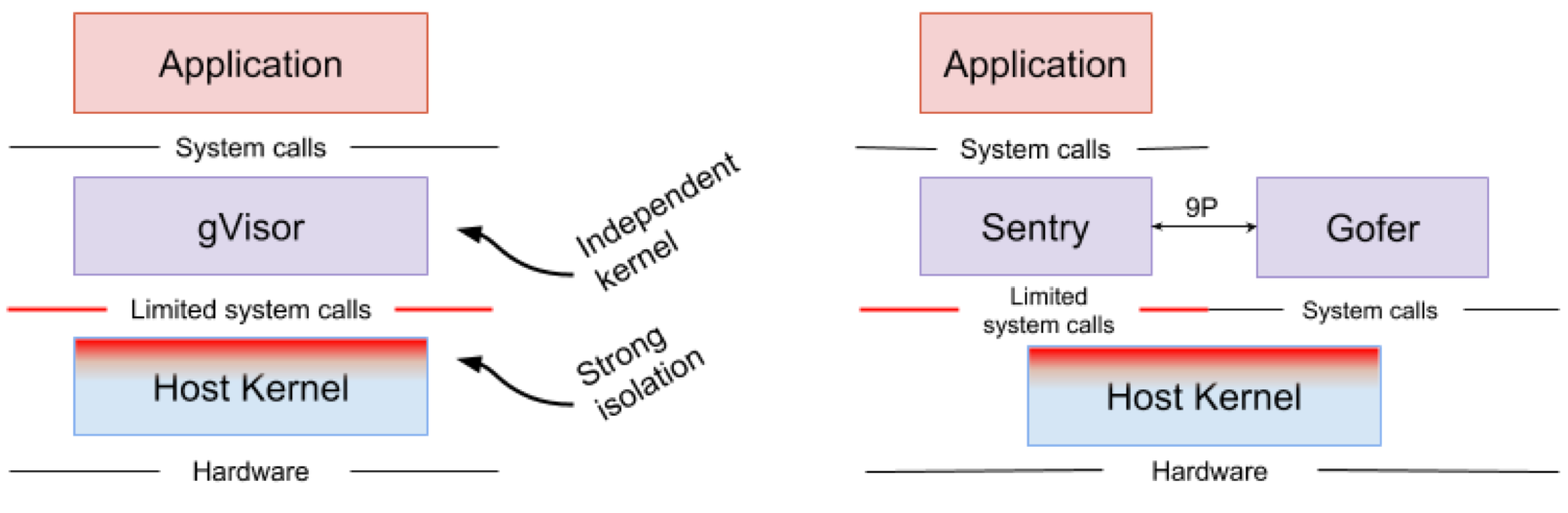
Figure 4. The gVisor kernel implementation // The Sentry and gVisor Gofer file systems use a small number of system calls to interact with the host.
gVisor creates a strong security perimeter between the application and its host. It limits the system calls that applications can use in user space. Without relying on virtualization, gVisor works as a host process that interacts between the isolated application and the host. Sentry supports most Linux system calls and core kernel functions, such as signal delivery, memory management, the network stack, and the threading model. Sentry has implemented more than 70% of the 319 Linux system calls to support isolated applications. At the same time, Sentry uses fewer than 20 Linux system calls to interact with the host kernel. It is worth noting that gVisor and Nabla have a very similar strategy: protecting the host OS and both of these solutions use less than 10% of the Linux system calls to interact with the kernel. But you need to understand that gVisor creates a multipurpose core, and, for example, Nabla relies on unique cores. In this case, both solutions launch a specialized guest kernel in user space to support isolated applications entrusted to them.
Some may wonder why gVisor needs its own kernel when the Linux kernel already has open source and is readily available. , gVisor, Golang, , Linux, C. Golang. gVisor — Docker, Kubernetes OCI. Docker gVisor, gVisor runsc. Kubernetes «» gVisor «»-.
gVisor , . gVisor , , , . ( , Nabla , unikernel . Nabla hypercall). gVisor (passthrough), , , , GPU, . , gVisor 70% Linux, , , gVisor.
Amazon Firecracker — , AWS Lambda AWS Fargate. , « » (MicroVM) multi-tenant . Firecracker Lambda Fargate EC2 , . , , . Firecracker , , . Firecracker , . Linux ext4 . Amazon Firecracker 2017 , 2018 .
unikernel, Firecracker . micro-VM , . , micro-VM Firecracker 5 ~125 2 CPU + 256 RAM. 5 Firecracker .
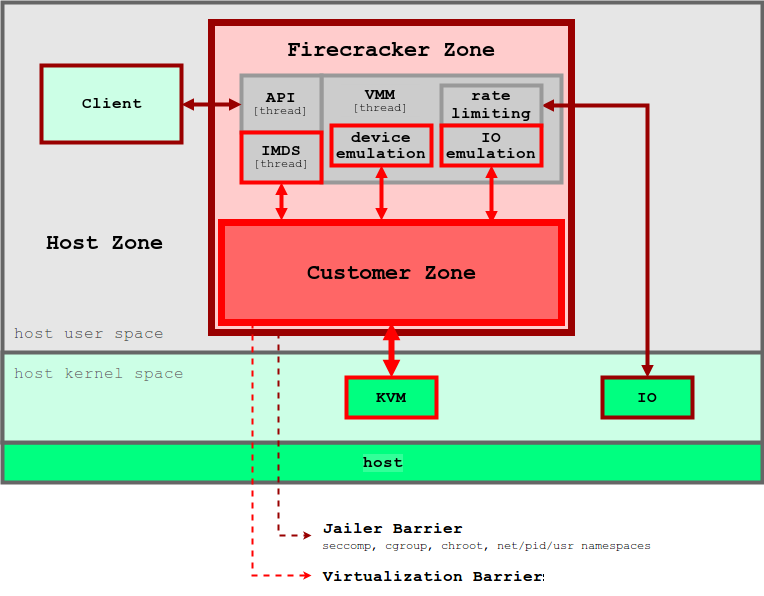
5. Firecracker
Firecracker KVM, . Firecracker seccomp, cgroups namespaces, , , . Firecracker . , API microVM. virtIO ( ). Firecracker microVM: virtio-block, virtio-net, serial console 1-button , microVM. . , , microVM File Block Devices, . , cgroups. , .
Firecracker Docker Kubernetes. Firecracker , , , . . , , OCI .
, 2015 Intel Clear Containers. Clear Containers Intel VT QEMU-KVM
Kata OCI, (CRI) (CNI). (, passthrough, MacVTap, bridge, tc mirroring) , , . 6 , Kata .
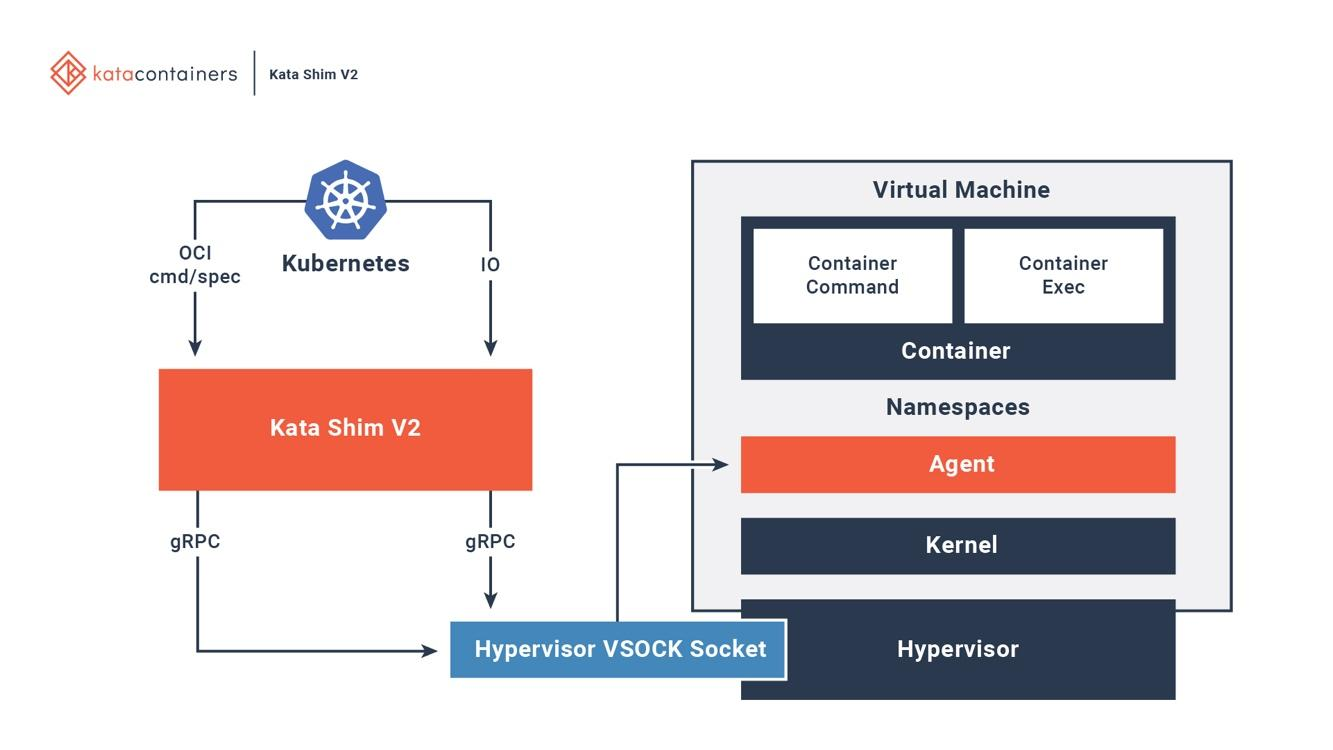
6. Kata Docker Kubernetes
Kata . Kata Kata Shim, API (, docker kubectl) VSock. Kata . NEMU — QEMU ~80% . VM-Templating Kata VM . , , , CVE-2015-2877. « » (, , , virtio), .
Kata Firecracker — «» , . , . Firecracker — , , Kata — , . Kata Firecracker. , .
, — .
IBM Nabla — unikernel, .
Google gVisor — , .
Amazon Firecracker — , .
OpenStack Kata — , .
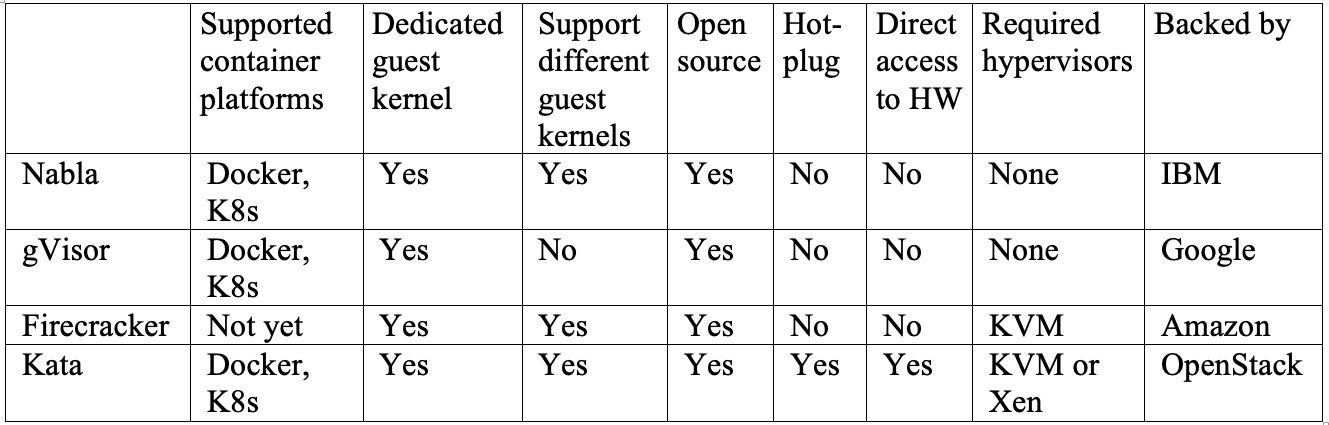
, , . . Nabla , , unikernel-, MirageOS IncludeOS. gVisor Docker Kubernetes, - . Firecracker , . Kata OCI KVM, Xen. .
, , , , .
The root of our problem lies in the weak delimitation of containers at the moment when the host operating system creates a virtual user area for each of them. Yes, research and development has been carried out aimed at creating real “containers” with a full-fledged sandbox. And the majority of the solutions obtained lead to the restructuring of the boundaries between the containers in order to enhance their isolation. In this article, we will look at four unique projects from IBM, Google, Amazon, and OpenStack, respectively, that use different methods to achieve the same goal: to create reliable isolation. For example, IBM Nabla deploys containers on top of Unikernel, Google gVisor creates a dedicated guest kernel, Amazon Firecracker uses an extremely lightweight hypervisor for sandbox applications, and OpenStack places containers in a specialized virtual machine optimized for orchestra tools.
Overview of modern container technology
Containers are a modern way to pack, share, and deploy an application. Unlike a monolithic application, in which all functions are packaged into one program, container applications or microservices are designed for narrow purposeful use and specialize only in one task.
')
The container includes all the dependencies (for example, packages, libraries, and binary files) that an application needs to perform its particular task. As a result, containerized applications are platform independent and can run on any operating system regardless of its version or installed packages. This convenience saves developers from a huge piece of work on adapting different versions of software for different platforms or clients. Although conceptually this is not entirely accurate, many people like to think of containers as “lightweight virtual machines.”
When a container is deployed on a host, the resources of each container, such as its file system, process, and network stack, are placed in a virtually isolated environment that other containers cannot access. This architecture allows you to simultaneously run hundreds and thousands of containers in a single cluster, and each application (or microservice) can then easily be scaled by replicating a large number of instances.
In this case, the container deployment is based on two key “building blocks”: the Linux namespace and the Linux control groups (cgroups).
The namespace creates a virtually isolated user space and provides the application with dedicated system resources, such as the file system, the network stack, the process ID, and the user ID. In this isolated user space, the application controls the root directory of the file system and can be run as root. This abstract space allows each application to work independently, without interfering with other applications living on the same host. There are now six namespaces available: mount, inter-process communication (ipc), UNIX time-sharing system (uts), process id (pid), network and user. It is proposed to add two additional namespaces to this list: time and syslog, but the Linux community has not yet decided on the final specifications.
Cgroups provide limited hardware resources, prioritization, monitoring and control of the application. As an example of hardware resources that they can manage, you can call the processor, memory, device, and network. By combining namespaces and cgroups, we can safely run multiple applications on the same host, with each application in its own isolated environment — which is a fundamental property of the container.
The main difference between a virtual machine (VM) and a container is that the virtual machine is virtualization at the hardware level, and the container is virtualization at the operating system level. The VM hypervisor emulates the hardware environment for each machine, where the container runtime already in turn emulates the operating system for each object. Virtual machines share the physical hardware of the host, and the containers share both the hardware and the OS kernel. Because containers in general share more resources with a host, their work with storage, memory, and CPU cycles is much more efficient than that of a virtual machine. However, the disadvantage of such a public access is problems in the information security plane, since too much trust is established between the containers and the host. Figure 1 illustrates the architectural difference between a container and a virtual machine.
In general, the isolation of virtualized equipment creates a much stronger security perimeter than just the isolation of the namespace. The risk that an attacker successfully leaves an isolated process is much higher than the chance of successfully exiting the virtual machine. The reason for the higher risk of going beyond the confined environment of containers is the weak isolation created by the namespace and cgroups. Linux implements them by associating new property fields with each process. These fields in the
/proc file system indicate the host operating system whether one process can see another, or how much processor / memory resources a particular process can use. When viewing running processes and threads from the parent OS (for example, the top or ps commands), the container process looks just like any other process. As a rule, traditional solutions such as LXC or Docker are not considered to be fully isolated, since they use the same core within the same host. Therefore, it is not surprising that containers have a sufficient number of vulnerabilities. For example, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123 and CVE-2019-5736 could result in an attacker gaining access to data outside the container.Most kernel exploits create a vector for a successful attack, since they usually translate into privilege escalation and allow a compromised process to gain control outside its intended namespace. In addition to attack vectors in the context of software vulnerabilities, incorrect configuration can also play a role. For example, deploying images with excessive privileges (CAP_SYS_ADMIN, privileged access) or critical mount points (
/var/run/docker.sock ) can lead to a leak. Given these potentially disastrous consequences, you should understand the risk that you take when deploying a system in a multi-tenant space or when using containers to store sensitive data.These problems motivate researchers to create stronger security perimeters. The idea is to create a real sandbox-container, as isolated as possible from the main OS. Most of these solutions include the development of a hybrid architecture that uses a strict demarcation of the application and the virtual machine, and focuses on improving the efficiency of container solutions.
At the time of this writing, there was not a single project that could be called mature enough to be taken as a standard, but in the future, developers will undoubtedly accept some of these concepts as basic ones.
We begin our review with Unikernel, the oldest highly specialized system that packs an application into a single image using the minimum set of operating system libraries. The very concept of Unikernel turned out to be fundamental for a variety of projects whose goal was to create safe, compact and optimized images. After that, we will proceed to reviewing IBM Nabla, a project for launching Unikernel applications, including containers. In addition, we have Google gVisor - a project to launch containers in user kernel space. Next, we will switch to container solutions based on virtual machines - Amazon Firecracker and OpenStack Kata. Summarize this post by comparing all the above solutions.
Unikernel
The development of virtualization technology has allowed us to move to cloud computing. Hypervisors like Xen and KVM laid the foundation for what we now know as Amazon Web Services (AWS) and the Google Cloud Platform (GCP). And although modern hypervisors are able to work with hundreds of virtual machines combined into a single cluster, traditional general-purpose operating systems are not too adapted and optimized for work in such an environment. A general-purpose OS is designed primarily to support and work with as many diverse applications as possible, so their kernels include all types of drivers, libraries, protocols, schedulers, and so on. However, most virtual machines deployed somewhere in the cloud are used to run a single application, for example, to ensure the operation of a DNS, proxy, or some kind of database. Since such a separate application relies in its work only on a specific and small section of the OS kernel, all its other “body kits” simply idle system resources, and by the very fact of their existence they increase the number of vectors for a potential attack. After all, the larger the code base, the more difficult it is to eliminate all the flaws, and the more potential vulnerabilities, errors and other weaknesses. This problem encourages specialists to develop highly specialized operating systems with a minimal set of core functionality, that is, to create tools to support one specific application.
The idea of Unikernel was born for the first time back in the 90s. At the same time, he took shape as a specialized image of a machine with a single address space that can work directly on hypervisors. It packs the core and dependent applications and kernel functions into a single image. Nemesis and Exokernel are the two earliest research versions of the Unikernel project. The packaging and deployment process is shown in Figure 2.
Figure 2. Multi-purpose operating systems are designed to support all types of applications, so many libraries and drivers are loaded into them in advance. Unikernels are highly specialized operating systems that are designed to support one specific application.
Unikernel splits the kernel into several libraries and places only necessary components into the image. Like regular virtual machines, unikernel is deployed and runs on the VM hypervisor. Due to its small size, it can load quickly and also scale quickly. The most important features of Unikernel are enhanced security, small footprint, high degree of optimization and fast loading. Since these images contain only application-dependent libraries, and the OS shell is inaccessible, if it was not connected purposefully, then the number of attack vectors that attackers can use them is minimal.
That is, it is not only difficult for an attacker to gain a foothold in these unique cores, but their influence is also limited to one copy of the core. Since the size of Unikernel images is only a few megabytes, they load in tens of milliseconds, and literally hundreds of copies can be launched on one host. Using memory allocation in a single address space instead of a multi-level page table, as is the case in most modern operating systems, unikernel applications have a lower memory access delay compared to the same application running on a regular virtual machine. Since applications build together with the kernel when building an image, compilers can simply perform static type checking to optimize binary files.
The Unikernel.org website maintains a list of unikernel projects. But with all its distinctive features and properties, unikernel was not widely used. When Docker acquired Unikernel Systems in 2016, the community decided that the company would now pack containers in them. But three years have passed, and there are still no signs of integration. One of the main reasons for this slow implementation is that there is still no mature tool for creating Unikernel applications, and most of these applications can only work on certain hypervisors. In addition, porting an application to unikernel may require manual rewriting of code in other languages, including rewriting dependent kernel libraries. It is also important that monitoring or debugging in unikernels is either impossible or has a significant impact on performance.
All these restrictions keep developers from switching to this technology. It should be noted that unikernel and containers have many similar properties. Both the first and second are narrowly focused, unchangeable images, which means that the components inside them cannot be updated or corrected, that is, for the application patch, you always have to create a new image. Today, Unikernel is similar to Docker's ancestor: then the container runtime was inaccessible, and developers had to use the basic tools for building an isolated application environment (chroot, unshare, and cgroups).
Ibm nabla
Some time ago, researchers from IBM proposed the concept of “Unikernel as a process” - that is, an unikernel application that would run as a process on a specialized hypervisor. The IBM project “Nabla containers” strengthened the unikernel security perimeter, replacing the universal hypervisor (for example, QEMU) with its own development called Nabla Tender. The rationale for this approach is that calls between unikernel and the hypervisor still provide the most vectors to attack. That is why the use of a dedicated unikernel hypervisor with a smaller number of allowed system calls can significantly strengthen the security perimeter. Nabla Tender intercepts calls that unikernel sends to the hypervisor, and already translates them into system requests. At the same time, the seccomp Linux policy blocks all other system calls that are not needed for the operation of the Tender. Thus, Unikernel in conjunction with the Nabla Tender runs as a process in the user space of the host. Below, in Figure 3, it is reflected how Nabla creates a thin interface between unikernel and the host.
Figure 3. To link Nabla to existing container runtime platforms, Nabla uses an OCI-compatible environment, which in turn can be connected to Docker or Kubernetes.
The developers claim that Nabla Tender uses in its work less than seven system calls to interact with the host. Since system calls serve as a kind of bridge between processes in user space and the operating system kernel, the less system calls available to us, the smaller the number of vectors available to attack the kernel. Another advantage of running unikernel as a process is that debugging of such applications can be performed using a large number of tools, for example, using gdb.
To work with the container orchestration platforms, Nabla provides a dedicated
runnc runtime runnc , which is implemented according to the Open Container Initiative (OCI) standard. The latter defines an API between clients (for example, Docker, Kubectl) and a runtime environment (eg, runc). Image Designer is also supplied with Nabla, which later will be able to run runnc . However, due to file system differences between unikernels and traditional containers, Nabla images do not conform to the specifications of the OCI image and, therefore, Docker images are not compatible with runnc . At the time of this writing, the project is still in the early development stage. There are other limitations, such as lack of support for mounting / accessing host file systems, adding multiple network interfaces (required for Kubernetes), or using images from other unikernel images (for example, MirageOS).Google gVisor
Google gVisor is a sandbox technology using the Google Cloud Platform (GCP) application engine, cloud functions and CloudML. At some point, Google realized the risk of running unreliable applications in the public cloud infrastructure and the inefficiency of sandbox applications using virtual machines. As a result, a user-space kernel was developed for the isolated environment of such unreliable applications. gVisor puts these applications in a sandbox, intercepting all system calls from them to the host kernel and processing them in the user environment using the gVisor Sentry core. In essence, it functions as a combination of the guest core and the hypervisor. Figure 4 shows the gVisor architecture.
Figure 4. The gVisor kernel implementation // The Sentry and gVisor Gofer file systems use a small number of system calls to interact with the host.
gVisor creates a strong security perimeter between the application and its host. It limits the system calls that applications can use in user space. Without relying on virtualization, gVisor works as a host process that interacts between the isolated application and the host. Sentry supports most Linux system calls and core kernel functions, such as signal delivery, memory management, the network stack, and the threading model. Sentry has implemented more than 70% of the 319 Linux system calls to support isolated applications. At the same time, Sentry uses fewer than 20 Linux system calls to interact with the host kernel. It is worth noting that gVisor and Nabla have a very similar strategy: protecting the host OS and both of these solutions use less than 10% of the Linux system calls to interact with the kernel. But you need to understand that gVisor creates a multipurpose core, and, for example, Nabla relies on unique cores. In this case, both solutions launch a specialized guest kernel in user space to support isolated applications entrusted to them.
Some may wonder why gVisor needs its own kernel when the Linux kernel already has open source and is readily available. , gVisor, Golang, , Linux, C. Golang. gVisor — Docker, Kubernetes OCI. Docker gVisor, gVisor runsc. Kubernetes «» gVisor «»-.
gVisor , . gVisor , , , . ( , Nabla , unikernel . Nabla hypercall). gVisor (passthrough), , , , GPU, . , gVisor 70% Linux, , , gVisor.
Amazon Firecracker
Amazon Firecracker — , AWS Lambda AWS Fargate. , « » (MicroVM) multi-tenant . Firecracker Lambda Fargate EC2 , . , , . Firecracker , , . Firecracker , . Linux ext4 . Amazon Firecracker 2017 , 2018 .
unikernel, Firecracker . micro-VM , . , micro-VM Firecracker 5 ~125 2 CPU + 256 RAM. 5 Firecracker .
5. Firecracker
Firecracker KVM, . Firecracker seccomp, cgroups namespaces, , , . Firecracker . , API microVM. virtIO ( ). Firecracker microVM: virtio-block, virtio-net, serial console 1-button , microVM. . , , microVM File Block Devices, . , cgroups. , .
Firecracker Docker Kubernetes. Firecracker , , , . . , , OCI .
OpenStack Kata
, 2015 Intel Clear Containers. Clear Containers Intel VT QEMU-KVM
qemu-lite . 2017 Clear Containers Hyper RunV, OCI, Kata. Clear Containers, Kata .Kata OCI, (CRI) (CNI). (, passthrough, MacVTap, bridge, tc mirroring) , , . 6 , Kata .
6. Kata Docker Kubernetes
Kata . Kata Kata Shim, API (, docker kubectl) VSock. Kata . NEMU — QEMU ~80% . VM-Templating Kata VM . , , , CVE-2015-2877. « » (, , , virtio), .
Kata Firecracker — «» , . , . Firecracker — , , Kata — , . Kata Firecracker. , .
Conclusion
, — .
IBM Nabla — unikernel, .
Google gVisor — , .
Amazon Firecracker — , .
OpenStack Kata — , .
, , . . Nabla , , unikernel-, MirageOS IncludeOS. gVisor Docker Kubernetes, - . Firecracker , . Kata OCI KVM, Xen. .
, , , , .
Source: https://habr.com/ru/post/457760/
All Articles