Horizontal autoscale of Kubernetes and Prometheus hearths for high availability and availability of the infrastructure
Salute, habrovchane! The translation of the next article was prepared specifically for students of the course “Infrastructure platform based on Kubernetes” , which classes will start tomorrow. Let's start.

Autoscaling allows you to automatically increase and decrease workloads depending on resource usage.
')
Kubernetes autoscaling has two dimensions:
Cluster autoscaling can be used in conjunction with horizontal automatic scaling of hearths to dynamically adjust computing resources and the degree of system parallelism required to comply with service level agreements (SLAs).
Cluster autoscaling is highly dependent on the capabilities of the cloud infrastructure provider that hosts the cluster, and HPA can operate independently of the IaaS / PaaS provider.
The horizontal autoscaling of the hearth has undergone major changes since it appeared in Kubernetes v1.1. The first version of HPA scaled hearths based on measured CPU consumption, and later on based on memory usage. Kubernetes 1.6 introduced a new API called Custom Metrics, which provided HPA with access to arbitrary metrics. And in Kubernetes 1.7, an aggregation level was added that allows third-party applications to extend the Kubernetes API, registering as an API add-on.
Thanks to the Custom Metrics API and the level of aggregation, monitoring systems such as Prometheus can provide HPA-specific application performance.
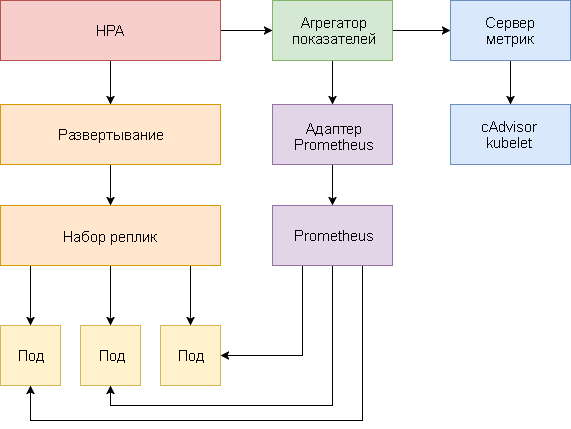
Horizontal autoscale podov implemented in the form of a control loop, which periodically requests the Resource Metrics API (Resource Metrics API) key indicators, such as CPU and memory usage, and in the Custom Metrics API (User Metrics API) specific application indicators.
Below is a step-by-step guide to configuring HPA v2 for Kubernetes 1.9 and later.
Before you start, you must install Go version 1.8 (or later) and clone the k8s-prom-hpa repository in
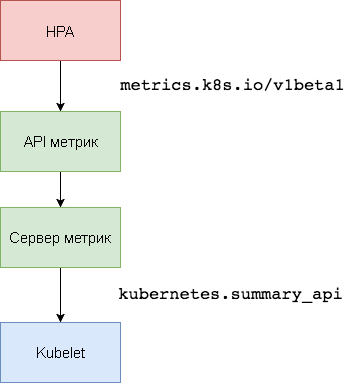
Kubernetes metrics server is an intracluster resource utilization aggregator that replaces Heapster . The metrics server collects information about CPU and memory usage for nodes and pods from
The first version of HPA needed the Heapster aggregator to get CPU and memory metrics. In HPA v2 and Kubernetes 1.8, you only need a metric server with
After 1 minute, the
View node metrics:
View scores:
You can use the Golang web-based small web application to test horizontal auto scaling (HPA).
Deploy podinfo in the
Contact
Specify an HPA that will serve at least two replicas and scale up to ten replicas if the average CPU usage exceeds 80% or if the memory consumption is above 200 Mbyte:
Create an HPA:
After a couple of seconds, the HPA controller will contact the metrics server and get information about CPU and memory usage:
To increase CPU utilization, perform a load test with rakyll / hey:
You can monitor HPA events as follows:
Temporarily remove podinfo (you will have to redeploy it in one of the following steps in this guide).
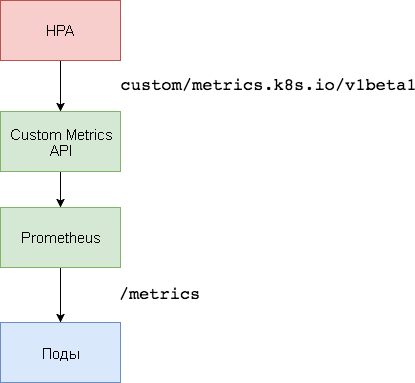
To scale on the basis of special indicators, two components are needed. The first — the Prometheus time series database — collects application metrics and saves them. The second component, k8s-prometheus-adapter , complements Custom Metrics API Kubernetes with indicators provided by the assembler.
A dedicated namespace is used to deploy Prometheus and the adapter.
Create a namespace
Deploy Prometheus v2 in the
Generate the TLS certificates required for the Prometheus adapter:
Deploy the Prometheus Adapter for Custom Metrics API:
Get a list of the special metrics provided by Prometheus:
Then retrieve the file system usage data for all subs in the
Create the NodePort
Get the total requests per second from the Custom Metrics API:
The letter
Create an HPA that will expand the podinfo deployment if the number of requests exceeds 10 requests per second:
After a few seconds, HPA will get the value of
Apply load to the podinfo service with 25 requests per second:
After a few minutes, HPA will begin to scale the deployment:
With the current number of requests per second, the deployment will never reach a maximum value of 10 levels. Three replicas are enough to ensure that the number of requests per second for each pod is less than 10.
When the load tests are complete, HPA will scale down the deployment to the original number of replicas:
You may have noticed that the autoscaling tool does not immediately respond to changes in indicators. By default, they are synchronized every 30 seconds. In addition, scaling occurs only if during the last 3-5 minutes there has been no increase and decrease in workloads. This helps prevent the execution of conflicting solutions and leaves time to connect the cluster autoscaling tool.
Not all systems can enforce SLA requirements only on the basis of CPU or memory utilization rates (or both). Most web servers and mobile servers need to autoscale based on the number of requests per second to handle traffic surges.
For ETL applications (from the English Extract Transform Load - “extraction, transformation, loading”), autoscaling can be launched, for example, when the specified threshold length of the job queue is exceeded.
In all cases, application instrumentation with Prometheus and highlighting the necessary auto-scaling metrics enable fine-tuning of applications to improve the processing of traffic bursts and ensure high infrastructure availability.
Ideas, questions, comments? Join the Slack discussion!
Here is such a material. We are waiting for your comments and see you on the course !
Auto scaling in Kubernetes
Autoscaling allows you to automatically increase and decrease workloads depending on resource usage.
')
Kubernetes autoscaling has two dimensions:
- cluster autoscaling (Cluster Autoscaler), which is responsible for scaling nodes;
- Horizontal Pod Autoscaler (HPA), which automatically scales the number of pitches in a deployment or replica set.
Cluster autoscaling can be used in conjunction with horizontal automatic scaling of hearths to dynamically adjust computing resources and the degree of system parallelism required to comply with service level agreements (SLAs).
Cluster autoscaling is highly dependent on the capabilities of the cloud infrastructure provider that hosts the cluster, and HPA can operate independently of the IaaS / PaaS provider.
HPA development
The horizontal autoscaling of the hearth has undergone major changes since it appeared in Kubernetes v1.1. The first version of HPA scaled hearths based on measured CPU consumption, and later on based on memory usage. Kubernetes 1.6 introduced a new API called Custom Metrics, which provided HPA with access to arbitrary metrics. And in Kubernetes 1.7, an aggregation level was added that allows third-party applications to extend the Kubernetes API, registering as an API add-on.
Thanks to the Custom Metrics API and the level of aggregation, monitoring systems such as Prometheus can provide HPA-specific application performance.
Horizontal autoscale podov implemented in the form of a control loop, which periodically requests the Resource Metrics API (Resource Metrics API) key indicators, such as CPU and memory usage, and in the Custom Metrics API (User Metrics API) specific application indicators.
Below is a step-by-step guide to configuring HPA v2 for Kubernetes 1.9 and later.
- Install the Metrics Server Add-in, which provides key metrics.
- Run the demo application to see how the auto-scaling of the hearths works based on CPU and memory usage.
- Deploy Prometheus and a dedicated API server. Register a special API server at the aggregation level.
- Configure HPA using the special metrics provided by the sample application.
Before you start, you must install Go version 1.8 (or later) and clone the k8s-prom-hpa repository in
GOPATH : cd $GOPATH git clone https://github.com/stefanprodan/k8s-prom-hpa 1. Setting up a metrics server
Kubernetes metrics server is an intracluster resource utilization aggregator that replaces Heapster . The metrics server collects information about CPU and memory usage for nodes and pods from
kubernetes.summary_api . The Summary API is a memory-efficient API for transferring Kubelet / cAdvisor data metrics to the server.The first version of HPA needed the Heapster aggregator to get CPU and memory metrics. In HPA v2 and Kubernetes 1.8, you only need a metric server with
horizontal-pod-autoscaler-use-rest-clients enabled. This option is enabled by default in Kubernetes 1.9. GKE 1.9 comes with a pre-installed metrics server.kube-system metrics server in the kube-system namespace: kubectl create -f ./metrics-server After 1 minute, the
metric-server will begin transmitting data about CPU and memory usage by the nodes and heartbeats.View node metrics:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq . View scores:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq . 2. Autoscale based on CPU and memory usage
You can use the Golang web-based small web application to test horizontal auto scaling (HPA).
Deploy podinfo in the
default namespace: kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml Contact
podinfo using the NodePort service at http://<K8S_PUBLIC_IP>:31198 .Specify an HPA that will serve at least two replicas and scale up to ten replicas if the average CPU usage exceeds 80% or if the memory consumption is above 200 Mbyte:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi Create an HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml After a couple of seconds, the HPA controller will contact the metrics server and get information about CPU and memory usage:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m To increase CPU utilization, perform a load test with rakyll / hey:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http://<K8S_PUBLIC_IP>:31198/ You can monitor HPA events as follows:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target Temporarily remove podinfo (you will have to redeploy it in one of the following steps in this guide).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml 3. Custom Metrics server setup
To scale on the basis of special indicators, two components are needed. The first — the Prometheus time series database — collects application metrics and saves them. The second component, k8s-prometheus-adapter , complements Custom Metrics API Kubernetes with indicators provided by the assembler.
A dedicated namespace is used to deploy Prometheus and the adapter.
Create a namespace
monitoring : kubectl create -f ./namespaces.yaml Deploy Prometheus v2 in the
monitoring namespace: kubectl create -f ./prometheus Generate the TLS certificates required for the Prometheus adapter:
make certs Deploy the Prometheus Adapter for Custom Metrics API:
kubectl create -f ./custom-metrics-api Get a list of the special metrics provided by Prometheus:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq . Then retrieve the file system usage data for all subs in the
monitoring namespace: kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq . 4. Autoscale based on special indicators
Create the NodePort
podinfo service and deploy to the default namespace: kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml podinfo will pass a special indicator http_requests_total . The Prometheus adapter will remove the _total suffix and mark this indicator as a counter-indicator.Get the total requests per second from the Custom Metrics API:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] } The letter
m means milli-units , so, for example, 901m is 901 milliquery.Create an HPA that will expand the podinfo deployment if the number of requests exceeds 10 requests per second:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10 podinfo HPA podinfo in the default namespace: kubectl create -f ./podinfo/podinfo-hpa-custom.yaml After a few seconds, HPA will get the value of
http_requests from the API metrics: kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m Apply load to the podinfo service with 25 requests per second:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http://<K8S-IP>:31198/healthz After a few minutes, HPA will begin to scale the deployment:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target With the current number of requests per second, the deployment will never reach a maximum value of 10 levels. Three replicas are enough to ensure that the number of requests per second for each pod is less than 10.
When the load tests are complete, HPA will scale down the deployment to the original number of replicas:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target You may have noticed that the autoscaling tool does not immediately respond to changes in indicators. By default, they are synchronized every 30 seconds. In addition, scaling occurs only if during the last 3-5 minutes there has been no increase and decrease in workloads. This helps prevent the execution of conflicting solutions and leaves time to connect the cluster autoscaling tool.
Conclusion
Not all systems can enforce SLA requirements only on the basis of CPU or memory utilization rates (or both). Most web servers and mobile servers need to autoscale based on the number of requests per second to handle traffic surges.
For ETL applications (from the English Extract Transform Load - “extraction, transformation, loading”), autoscaling can be launched, for example, when the specified threshold length of the job queue is exceeded.
In all cases, application instrumentation with Prometheus and highlighting the necessary auto-scaling metrics enable fine-tuning of applications to improve the processing of traffic bursts and ensure high infrastructure availability.
Ideas, questions, comments? Join the Slack discussion!
Here is such a material. We are waiting for your comments and see you on the course !
Source: https://habr.com/ru/post/457742/
All Articles