How do GPUs handle branching
About the article
This post is a small note intended for programmers who want to learn more about how the GPU handles branching. It can be considered as an introduction to this topic. I recommend looking at [ 1 ], [ 2 ] and [ 8 ] to get started, to get an idea of how the model of GPU execution looks in general, because we will consider only one particular detail. For curious readers at the end of the post have all the links. If you find any errors, please contact me.
Content
- About the article
- Content
- Vocabulary
- How does a GPU core differ from a CPU core?
- What is consistency / discrepancy?
- Execution mask processing examples
- Fictional ISA
- AMD GCN ISA
- AVX512
- How to deal with the discrepancy?
- Links
Vocabulary
- GPU - Graphics processing unit, graphics processor
- Flynn's classification
- SIMD - Single instruction multiple data, single command stream, multiple data stream
- SIMT - Single instruction multiple threads, single command stream, multiple threads
- Wave (SIMD) - a stream running in SIMD mode
- Line (lane) - a separate data stream in the model SIMD
- SMT - Simultaneous multi-threading, simultaneous multithreading (Intel Hyper-threading) [ 2 ]
- Multiple threads use shared kernel computing resources.
- IMT - Interleaved multi-threading, alternating multithreading [ 2 ]
- Multiple threads share common computational resources of the kernel, but only one is executed per clock.
- BB - Basic Block, basic block - linear sequence of instructions with a single transition at the end
- ILP - Instruction Level Parallelism, instruction-level parallelism [ 3 ]
- ISA - Instruction Set Architecture, command / instruction set architecture
In my post I will adhere to this invented classification. It roughly resembles how a modern GPU is organized.
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1Other names:
')
- The kernel may be called CU, SM, EU
- A wave can be called a wavefront, a hardware flow (HW thread), warp, a context
- A line can be called a program thread (SW thread)
How does a GPU core differ from a CPU core?
Any current generation of GPU cores is less powerful than CPUs: simple ILP / multi-issue [ 6 ] and pre-selection [ 5 ], no prediction or prediction of transitions / returns. All this, along with tiny caches, frees up a rather large area on the crystal, which is filled with many cores. Memory load / storage mechanisms are able to handle channel widths an order of magnitude more (this does not apply to integrated / mobile GPUs) than regular CPUs, but you have to pay for this with high latency. To hide the delays, the GPU uses SMT [ 2 ] - while one wave is idle, others use free kernel computing resources. Typically, the number of waves processed by a single core depends on the registers used and is determined dynamically by allocating a fixed register file [ 8 ]. Hybrid - Dynamic-Static [ 6 ] [ 11 4.4] scheduling instructions execution. SIMT kernels running in SIMD mode achieve high FLOPS values (FLoating-point Operations Per Second, flops, number of floating point operations per second).
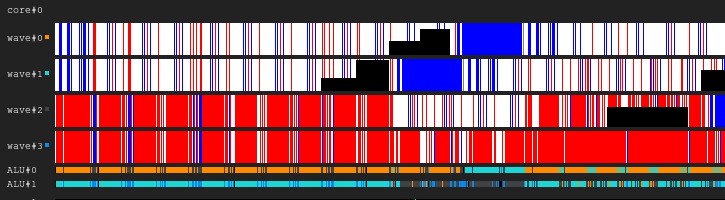
Legend of the chart. Black is inactive, white is active, gray is disabled, blue is idle, red is pending

Figure 1. 4: 2 execution history
The image shows the history of the execution mask, where the time from left to right is plotted on the x axis, and the line identifier going from top to bottom on the y axis. If this is not yet clear to you, then return to the picture after reading the following sections.
This is an illustration of how the execution history of a GPU kernel may look like in a fictional configuration: four waves share one sampler and two ALUs. The wave planner in each cycle releases two instructions from two waves. When a wave is idle when performing a memory access or a long ALU operation, the scheduler switches to another pair of waves, so that the ALU are constantly occupied by almost 100%.

Figure 2. 4: 1 execution history
An example with the same load, but this time in each cycle of the instruction only one wave releases. Notice that the second ALU is starving.
Figure 3. 4: 4 execution history
This time, four instructions are issued for each cycle. Note that the ALU is now too many requests, so the two waves are almost constantly waiting (in fact, this is the error of the scheduling algorithm).
Update For more information about the difficulties of scheduling instructions, see [ 12 ].
In the real world, GPUs have different kernel configurations: some can have up to 40 waves per core and 4 ALUs, others have fixed 7 waves and 2 ALUs. It all depends on many factors and is determined by the painstaking process of architecture simulation.
In addition, a real ALD SIMD may have a narrower width than the waves it serves, and then it takes several cycles to process one issued instruction; the multiplier is called the chime length [ 3 ].
What is consistency / discrepancy?
Let's take a look at the following code snippet:
Example 1
uint lane_id = get_lane_id(); if (lane_id & 1) { // Do smth } // Do some more Here we see a stream of instructions in which the execution path depends on the identifier of the line being executed. Obviously, different lines have different meanings. What should happen? There are different approaches to solving this problem [ 4 ], but in the end, they all do about the same thing. One of these approaches is the execution mask, which I will consider. This approach was used in the Nvidia GPU to Volta and on the AMD GCN GPU. The basic meaning of the execution mask is that we store a bit for each line in the wave. If the corresponding line execution bit is 0, then no registers will be affected for the next instruction issued. In fact, the line should not feel the influence of all executed instructions, because its execution bit is 0. This works as follows: the wave travels through the control flow graph in the depth-first search order, keeping the history of the selected transitions until the bits are set. I think it is better to show it by example.
Suppose we have a wave width of 8. Here’s what the execution mask looks like for a code snippet:
Example 1. Execution mask history
// execution mask uint lane_id = get_lane_id(); // 11111111 if (lane_id & 1) { // 11111111 // Do smth // 01010101 } // Do some more // 11111111 Now let's look at more complex examples:
Example 2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) { // Do smth } Example 3
uint lane_id = get_lane_id(); if (lane_id < 16) { // Do smth } else { // Do smth else } You may notice that history is necessary. When using the execution mask approach, the equipment typically uses some kind of stack. The naive approach is to store a stack of tuples (exec_mask, address) and add convergence instructions that remove the mask from the stack and change the instruction pointer for the wave. In this case, the wave will have enough information to bypass the entire CFG for each line.
In terms of performance, only a couple of cycles are required to process a control flow instruction because of all this data storage. And do not forget that the stack has a limited depth.
Update. Thanks to @craigkolb, I read an article [ 13 ] in which it is noted that the AMD GCN fork / join instructions first choose a path from a smaller number of threads [ 11 4.6], which ensures the sufficiency of the stack depth of the masks equal to log2.
Update. Obviously, it is almost always possible to embed everything in a shader / structure CFG in a shader, and therefore store the entire history of execution masks in registers and plan for traversing / converging CFG statically [ 15 ]. After reviewing the LLVM backend for AMDGPU, I did not find any evidence of processing stacks that are constantly being released by the compiler.
Hardware support for the execution mask
Now take a look at these control flow graphs from Wikipedia:

Figure 4. Some of the types of control flow graphs
What is the minimum set of instructions for managing masks that we need to handle all cases? Here’s how it looks in my artificial ISA with implicit parallelization, explicit mask management and fully dynamic synchronization of data conflicts:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE Let's take a look at how case d) may look.
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret I am not an expert in analyzing control flows or designing ISA, so I’m sure that there is a case that my artificial ISA cannot handle, but this is not important, because a structured CFG should be enough for everyone.
Update. You can read more about GCN support for control flow instructions here: [ 11 ] ch.4, and about implementing LLVM - here: [ 15 ].
Conclusion:
- The discrepancy is an emerging difference in the execution paths chosen by different lines of the same wave.
- Consistency - no discrepancy.
Execution mask processing examples
Fictional ISA
I compiled the previous code snippets in my artificial ISA and ran them on the simulator in SIMD32. See how it handles the execution mask.
Update. Note that the artificial simulator always chooses the true path, and this is not the best way.
Example 1
; uint lane_id = get_lane_id(); mov r0.x, lane_id ; if (lane_id & 1) { push_mask BRANCH_END and r0.y, r0.x, u(1) mask_nz r0.y LOOP_BEGIN: ; // Do smth pop_mask ; pop mask and reconverge BRANCH_END: ; // Do some more ret 
Figure 5. Execution history of example 1
Have you noticed the black area? This time wasted. Some lines are waiting for others to complete the iteration.
Example 2
; uint lane_id = get_lane_id(); mov r0.x, lane_id ; for (uint i = lane_id; i < 16; i++) { push_mask LOOP_END ; Push the current mask and the pointer to reconvergence instruction LOOP_PROLOG: lt.u32 r0.y, r0.x, u(16) ; r0.y <- r0.x < 16 add.u32 r0.x, r0.x, u(1) ; r0.x <- r0.x + 1 mask_nz r0.y ; exec bit <- r0.y != 0 - when all bits are zero next mask is popped LOOP_BEGIN: ; // Do smth jmp LOOP_PROLOG LOOP_END: ; // } ret 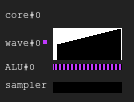
Figure 6. Execution history of example 2
Example 3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16) ; if (lane_id < 16) { ; Push (current mask, CONVERGE) and (else mask, ELSE) ; Also set current execution bit to r0.y != 0 br_push r0.y, ELSE, CONVERGE THEN: ; // Do smth pop_mask ; } else { ELSE: ; // Do smth else pop_mask ; } CONVERGE: ret 
Figure 7. Execution history of Example 3
AMD GCN ISA
Update. GCN also uses explicit processing of masks, more about this can be found here: [ 11 4.x]. I decided to show a few examples with their ISA, thanks to the shader-playground it is easy to do. Maybe someday I will find a simulator and manage to get diagrams.
Note that the compiler is smart, so you can get other results. I tried to trick the compiler so that it doesn’t optimize my branching by putting the pointer-follow cycles there and then cleaning up the assembler code; I am not a GCN specialist, so several important
nop can be skipped.Also note that the S_CBRANCH_I / G_FORK and S_CBRANCH_JOIN instructions are not used in these fragments because they are simple and the compiler does not support them. Therefore, unfortunately, it was not possible to consider the stack of masks. If you know how to force the compiler to issue stack processing, please let me know.
Update. See this talk @ SiNGUL4RiTY about implementing vectorized control flow in the LLVM backend used by AMD.
Example 1
; uint lane_id = get_lane_id(); ; GCN uses 64 wave width, so lane_id = thread_id & 63 ; There are scalar s* and vector v* registers ; Executon mask does not affect scalar or branch instructions v_mov_b32 v1, 0x00000400 ; 1024 - group size v_mad_u32_u24 v0, s12, v1, v0 ; thread_id calculation v_and_b32 v1, 63, v0 ; if (lane_id & 1) { v_and_b32 v2, 1, v0 s_mov_b64 s[0:1], exec ; Save the execution mask v_cmpx_ne_u32 exec, v2, 0 ; Set the execution bit s_cbranch_execz ELSE ; Jmp if all exec bits are zero ; // Do smth ELSE: ; } ; // Do some more s_mov_b64 exec, s[0:1] ; Restore the execution mask s_endpgm Example 2
; uint lane_id = get_lane_id(); v_mov_b32 v1, 0x00000400 v_mad_u32_u24 v0, s8, v1, v0 ; Not sure why s8 this time and not s12 v_and_b32 v1, 63, v0 ; LOOP PROLOG s_mov_b64 s[0:1], exec ; Save the execution mask v_mov_b32 v2, v1 v_cmp_le_u32 vcc, 16, v1 s_andn2_b64 exec, exec, vcc ; Set the execution bit s_cbranch_execz LOOP_END ; Jmp if all exec bits are zero ; for (uint i = lane_id; i < 16; i++) { LOOP_BEGIN: ; // Do smth v_add_u32 v2, 1, v2 v_cmp_le_u32 vcc, 16, v2 s_andn2_b64 exec, exec, vcc ; Mask out lanes which are beyond loop limit s_cbranch_execnz LOOP_BEGIN ; Jmp if non zero exec mask LOOP_END: ; // } s_mov_b64 exec, s[0:1] ; Restore the execution mask s_endpgm Example 3
; uint lane_id = get_lane_id(); v_mov_b32 v1, 0x00000400 v_mad_u32_u24 v0, s12, v1, v0 v_and_b32 v1, 63, v0 v_and_b32 v2, 1, v0 s_mov_b64 s[0:1], exec ; Save the execution mask ; if (lane_id < 16) { v_cmpx_lt_u32 exec, v1, 16 ; Set the execution bit s_cbranch_execz ELSE ; Jmp if all exec bits are zero ; // Do smth ; } else { ELSE: s_andn2_b64 exec, s[0:1], exec ; Inverse the mask and & with previous s_cbranch_execz CONVERGE ; Jmp if all exec bits are zero ; // Do smth else ; } CONVERGE: s_mov_b64 exec, s[0:1] ; Restore the execution mask ; // Do some more s_endpgm AVX512
Update. @tom_forsyth pointed out to me that the AVX512 extension also has explicit mask handling, so here are some examples. Read more about this in [ 14 ], 15.x and 15.6.1. It's not exactly a GPU, but it still has a real 32-bit SIMD16. The code snippets were created using ISPC (–target = avx512knl-i32x16) godbolt and have been extensively reworked, so they may not be 100% correct.
Example 1
; Imagine zmm0 contains 16 lane_ids ; AVXZ512 comes with k0-k7 mask registers ; Usage: ; op reg1 {k[7:0]}, reg2, reg3 ; k0 can not be used as a predicate operand, only k1-k7 ; if (lane_id & 1) { vpslld zmm0 {k1}, zmm0, 31 ; zmm0[i] = zmm0[i] << 31 kmovw eax, k1 ; Save the execution mask vptestmd k1 {k1}, zmm0, zmm0 ; k1[i] = zmm0[i] != 0 kortestw k1, k1 je ELSE ; Jmp if all exec bits are zero ; // Do smth ; Now k1 contains the execution mask ; We can use it like this: ; vmovdqa32 zmm1 {k1}, zmm0 ELSE: ; } kmovw k1, eax ; Restore the execution mask ; // Do some more ret Example 2
; Imagine zmm0 contains 16 lane_ids kmovw eax, k1 ; Save the execution mask vpcmpltud k1 {k1}, zmm0, 16 ; k1[i] = zmm0[i] < 16 kortestw k1, k1 je LOOP_END ; Jmp if all exec bits are zero vpternlogd zmm1 {k1}, zmm1, zmm1, 255 ; zmm1[i] = -1 ; for (uint i = lane_id; i < 16; i++) { LOOP_BEGIN: ; // Do smth vpsubd zmm0 {k1}, zmm0, zmm1 ; zmm0[i] = zmm0[i] + 1 vpcmpltud k1 {k1}, zmm0, 16 ; masked k1[i] = zmm0[i] < 16 kortestw k1, k1 jne LOOP_BEGIN ; Break if all exec bits are zero LOOP_END: ; // } kmovw k1, eax ; Restore the execution mask ; // Do some more ret Example 3
; Imagine zmm0 contains 16 lane_ids ; if (lane_id & 1) { vpslld zmm0 {k1}, zmm0, 31 ; zmm0[i] = zmm0[i] << 31 kmovw eax, k1 ; Save the execution mask vptestmd k1 {k1}, zmm0, zmm0 ; k1[i] = zmm0[i] != 0 kortestw k1, k1 je ELSE ; Jmp if all exec bits are zero THEN: ; // Do smth ; } else { ELSE: kmovw ebx, k1 andn ebx, eax, ebx kmovw k1, ebx ; mask = ~mask & old_mask kortestw k1, k1 je CONVERGE ; Jmp if all exec bits are zero ; // Do smth else ; } CONVERGE: kmovw k1, eax ; Restore the execution mask ; // Do some more ret How to deal with the discrepancy?
I tried to create a simple but complete illustration of how inefficiency arises due to the combination of diverging lines.
Provide a simple code snippet:
uint thread_id = get_thread_id(); uint iter_count = memory[thread_id]; for (uint i = 0; i < iter_count; i++) { // Do smth } Let's create 256 threads and measure their execution duration:
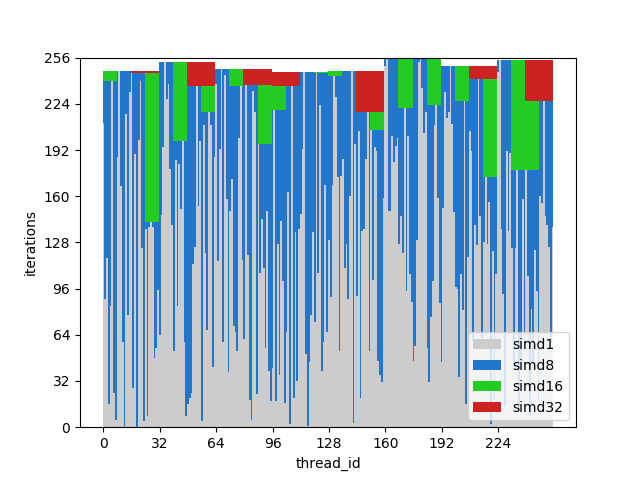
Figure 8. Runtime of diverging threads
The x axis is the identifier of the program flow, the y axis is the clock cycles; different columns show how much time is wasted in grouping streams with different wavelengths compared to single-threaded execution.
The wave execution time is equal to the maximum execution time among the lines contained in it. You can see that the performance drops dramatically already with SIMD8, and further expansion simply makes it a little worse.
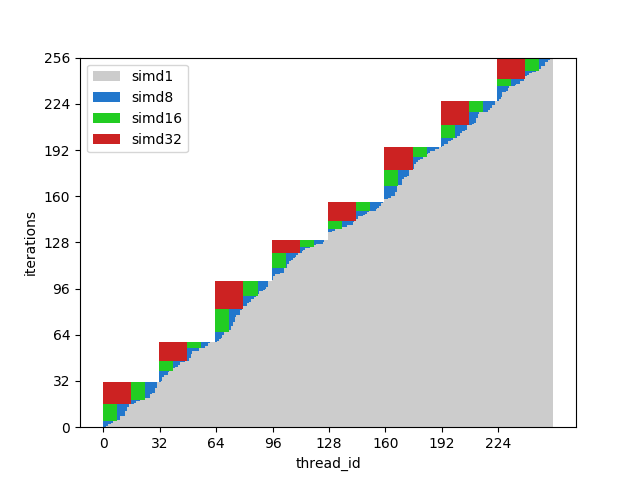
Figure 9. Execution time of matched threads
This picture shows the same columns, but this time the number of iterations is sorted by the thread identifiers, that is, streams with a similar number of iterations are transmitted to the same wavelength.
For this example, execution is potentially about half as fast.
Of course, the example is too simple, but I hope that you understand the meaning: the discrepancy in the implementation stems from the discrepancy of the data, so the CFG should be simple, and the data should be consistent.
For example, if you are writing a ray tracer, you may be given an advantage of grouping rays with the same direction and position, because they are more likely to travel along the same nodes in BVH. For details, see [ 10 ] and other related articles.
It is also worth mentioning that there are techniques for dealing with divergence and at the hardware level, for example, Dynamic Warp Formation [ 7 ] and the predicted performance for small branches.
Links
[1] A trip through the Graphics Pipeline
[2] Kayvon Fatahalian: PARALLEL COMPUTING
[3] Computer Architecture A Quantitative Approach
[4] Stack-less SIMT reconvergence at low cost
[5] Dissecting GPU memory hierarchy through microbenchmarking
[6] Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
[7] Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow
[8] Maurizio Cerrato: GPU Architectures
[9] Toy GPU simulator
[10] Reducing Branch Divergence in GPU Programs
[11] “Vega” Instruction Set Architecture
[12] Joshua Barczak: Simulating Shader Execution for GCN
[13] Tangent Vector: A Digression on Divergence
[14] Intel 64 and IA-32 Architectures Software Developer's Manual
[15] Vectorizing Divergent Control-Flow for SIMD Applications
Source: https://habr.com/ru/post/457704/
All Articles