Research of speed of a DBMS MS SQL Server Developer 2016 and PostgreSQL 10.5 for 1C
Objectives and requirements for testing "1C Accounting"
The main goal of the testing is to compare the behavior of the 1C system on two different DBMS, all other conditions being the same. Those. The configuration of the 1C database and the initial data filling should be the same for each test.
The main parameters that must be obtained when testing:
- Time to complete each test (removed by 1C Development Department)
- The load on the DBMS and the server environment during the test is removed by the DBMS administrators, as well as by the system administrators in the server environment
Testing of the 1C system should be performed taking into account the client-server architecture, therefore it is necessary to produce a full-fledged emulation of the user or several users in the system with the development of input information in the interface and storing this information in the database. At the same time, it is necessary that a large amount of periodic information be distributed over a large period of time to create totals in accumulation registers.
')
To perform the testing, an algorithm was developed in the form of a scenario testing script for the 1C Accounting 3.0 configuration, in which sequential input of test data to the 1C system is performed. The script allows you to specify various settings for the actions performed and the amount of test data. Detailed description below.
Description of the settings and characteristics of the tested media
At Fortis, we decided to double-check the results, including using the well-known Gilev test .
Also, we were encouraged to test, including some publications on the results of performance changes during the transition from MS SQL Server to PostgreSQL. Such as: 1C Battle: PostgreSQL 9.10 vs MS SQL 2016 .
So, here is the infrastructure for testing:
| 1C | PostgreSQL | ||
|---|---|---|---|
| eight | eight | eight | |
| sixteen | 32 | 32 | |
| OS | |||
| Digit | x64 | x64 | x64 |
| 8.3.13.1865 | - | - | |
| DBMS Version | - | 13.0.5264.1 | 10.5 (4.8.5.20150623) |
Servers for MS SQL and PostgreSQL were virtual and started alternately for the required test. 1C stood on a separate server.
Details
Hypervisor Specification:
Model: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5-2630 v3 @ 2.40GHz (2 sockes * 16 CPU HT = 32CPU)
RAM: 212 GB
OS: VMWare ESXi 6.5
PowerProfile: Performance
Hypervisor Disk Subsystem:
Controller: Adaptec 6805, Cache size: 512MB
Volume: RAID 10, 5.7 TB
Stripe-size: 1024 KB
Write-cache: on
Read-cache: off
Wheels: 6 pcs. HGST HUS726T6TAL,
Sector-Size: 512 Bytes
Write Cache: on
PostgreSQL has been configured as follows:
The entire contents of the postgresql.conf file:
MS SQL was configured as follows:
and
Cluster 1C settings were left standard:

and
Model: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5-2630 v3 @ 2.40GHz (2 sockes * 16 CPU HT = 32CPU)
RAM: 212 GB
OS: VMWare ESXi 6.5
PowerProfile: Performance
Hypervisor Disk Subsystem:
Controller: Adaptec 6805, Cache size: 512MB
Volume: RAID 10, 5.7 TB
Stripe-size: 1024 KB
Write-cache: on
Read-cache: off
Wheels: 6 pcs. HGST HUS726T6TAL,
Sector-Size: 512 Bytes
Write Cache: on
PostgreSQL has been configured as follows:
- postgresql.conf:
The basic setting was made on the calculator - pgconfigurator.cybertec.at , the parameters huge_pages, checkpoint_timeout, max_wal_size, min_wal_size, random_page_cost were changed based on information obtained from the sources mentioned at the end of the publication. The temp_buffers parameter value increased, based on the suggestion that 1C actively uses temporary tables:listen_addresses = '*' max_connections = 1000 # . . 32 25% . shared_buffers = 9GB # ( Linux - vm.nr_hugepages). huge_pages = on # . temp_buffers = 256MB # ORDER BY, DISTINCT, merge joins, join, hash-based aggregation, hash-based processing of IN subqueries. # , 1 ( "Mostly complicated real-time SQL queries" ). 64MB. work_mem = 128MB # . VACUUM, , etc. maintenance_work_mem = 512MB # (vm.dirty_background_bytes, vm.dirty_bytes), IO CHECKPOINT. checkpoint_timeout = 30min max_wal_size = 3GB min_wal_size = 512MB checkpoint_completion_target = 0.9 seq_page_cost = 1 # . - - 4. RAID10 . random_page_cost = 2.5 # postgres , PageCache. effective_cache_size = 22GB - Kernel OS settings:
Settings are specified in the profile file format for the tuned daemon:[sysctl] # (PageCache), / . #- (10,30) /. # CHECKPOINT I/O. # RAID- write-back cache 512MB. vm.dirty_background_bytes = 67108864 vm.dirty_bytes = 536870912 # SWAP -. , OOM. vm.swappiness = 1 # , CPU. # CPU . # . kernel.sched_migration_cost_ns = 5000000 # CPU . # 0. . kernel.sched_autogroup_enabled = 0 # . . # - https://www.postgresql.org/docs/11/kernel-resources.html#LINUX-HUGE-PAGES vm.nr_hugepages = 5000 [vm] # . , . , . transparent_hugepages=never # CPU. , . [cpu] force_latency=1 governor=performance energy_perf_bias=performance min_perf_pct=100 - File system:
# : #stride stripe_width RAID 10 6- stripe 1024kb mkfs.ext4 -E stride=256,stripe_width=768 /dev/sdb # : /dev/sdb /var/lib/pgsql ext4 noatime,nodiratime,data=ordered,barrier=0,errors=remount-ro 0 2 #noatime,nodiratime - #data=ordered - . #barrier=0 - . RAID- .
The entire contents of the postgresql.conf file:
# ----------------------------- # PostgreSQL configuration file # ----------------------------- # # This file consists of lines of the form: # # name = value # # (The "=" is optional.) Whitespace may be used. Comments are introduced with # "#" anywhere on a line. The complete list of parameter names and allowed # values can be found in the PostgreSQL documentation. # # The commented-out settings shown in this file represent the default values. # Re-commenting a setting is NOT sufficient to revert it to the default value; # you need to reload the server. # # This file is read on server startup and when the server receives a SIGHUP # signal. If you edit the file on a running system, you have to SIGHUP the # server for the changes to take effect, run "pg_ctl reload", or execute # "SELECT pg_reload_conf()". Some parameters, which are marked below, # require a server shutdown and restart to take effect. # # Any parameter can also be given as a command-line option to the server, eg, # "postgres -c log_connections=on". Some parameters can be changed at run time # with the "SET" SQL command. # # Memory units: kB = kilobytes Time units: ms = milliseconds # MB = megabytes s = seconds # GB = gigabytes min = minutes # TB = terabytes h = hours # d = days #------------------------------------------------------------------------------ # FILE LOCATIONS #------------------------------------------------------------------------------ # The default values of these variables are driven from the -D command-line # option or PGDATA environment variable, represented here as ConfigDir. #data_directory = 'ConfigDir' # use data in another directory # (change requires restart) #hba_file = 'ConfigDir/pg_hba.conf' # host-based authentication file # (change requires restart) #ident_file = 'ConfigDir/pg_ident.conf' # ident configuration file # (change requires restart) # If external_pid_file is not explicitly set, no extra PID file is written. #external_pid_file = '' # write an extra PID file # (change requires restart) #------------------------------------------------------------------------------ # CONNECTIONS AND AUTHENTICATION #------------------------------------------------------------------------------ # - Connection Settings - listen_addresses = '*' # what IP address(es) to listen on; # comma-separated list of addresses; # defaults to 'localhost'; use '*' for all # (change requires restart) #port = 5432 # (change requires restart) max_connections = 1000 # (change requires restart) #superuser_reserved_connections = 3 # (change requires restart) #unix_socket_directories = '/var/run/postgresql, /tmp' # comma-separated list of directories # (change requires restart) #unix_socket_group = '' # (change requires restart) #unix_socket_permissions = 0777 # begin with 0 to use octal notation # (change requires restart) #bonjour = off # advertise server via Bonjour # (change requires restart) #bonjour_name = '' # defaults to the computer name # (change requires restart) # - Security and Authentication - #authentication_timeout = 1min # 1s-600s ssl = off #ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL' # allowed SSL ciphers #ssl_prefer_server_ciphers = on #ssl_ecdh_curve = 'prime256v1' #ssl_dh_params_file = '' #ssl_cert_file = 'server.crt' #ssl_key_file = 'server.key' #ssl_ca_file = '' #ssl_crl_file = '' #test #password_encryption = md5 # md5 or scram-sha-256 #db_user_namespace = off row_security = off # GSSAPI using Kerberos #krb_server_keyfile = '' #krb_caseins_users = off # - TCP Keepalives - # see "man 7 tcp" for details #tcp_keepalives_idle = 0 # TCP_KEEPIDLE, in seconds; # 0 selects the system default #tcp_keepalives_interval = 0 # TCP_KEEPINTVL, in seconds; # 0 selects the system default #tcp_keepalives_count = 0 # TCP_KEEPCNT; # 0 selects the system default #------------------------------------------------------------------------------ # RESOURCE USAGE (except WAL) #------------------------------------------------------------------------------ # - Memory - shared_buffers = 9GB # min 128kB # (change requires restart) huge_pages = on # on, off, or try # (change requires restart) temp_buffers = 256MB # min 800kB #max_prepared_transactions = 0 # zero disables the feature # (change requires restart) # Caution: it is not advisable to set max_prepared_transactions nonzero unless # you actively intend to use prepared transactions. # work_mem = 128MB # min 64kB maintenance_work_mem = 512MB # min 1MB #replacement_sort_tuples = 150000 # limits use of replacement selection sort #autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem #max_stack_depth = 2MB # min 100kB dynamic_shared_memory_type = posix # the default is the first option # supported by the operating system: # posix # sysv # windows # mmap # use none to disable dynamic shared memory # (change requires restart) # - Disk - #temp_file_limit = -1 # limits per-process temp file space # in kB, or -1 for no limit # - Kernel Resource Usage - max_files_per_process = 10000 # min 25 # (change requires restart) shared_preload_libraries = 'online_analyze, plantuner' # (change requires restart) # - Cost-Based Vacuum Delay - #vacuum_cost_delay = 0 # 0-100 milliseconds #vacuum_cost_page_hit = 1 # 0-10000 credits #vacuum_cost_page_miss = 10 # 0-10000 credits #vacuum_cost_page_dirty = 20 # 0-10000 credits #vacuum_cost_limit = 200 # 1-10000 credits # - Background Writer - bgwriter_delay = 20ms # 10-10000ms between rounds bgwriter_lru_maxpages = 400 # 0-1000 max buffers written/round bgwriter_lru_multiplier = 4.0 # 0-10.0 multiplier on buffers scanned/round bgwriter_flush_after = 0 # measured in pages, 0 disables # - Asynchronous Behavior - effective_io_concurrency = 3 # 1-1000; 0 disables prefetching max_worker_processes = 8 # (change requires restart) max_parallel_workers_per_gather = 4 # taken from max_parallel_workers max_parallel_workers = 8 # maximum number of max_worker_processes that # can be used in parallel queries #old_snapshot_threshold = -1 # 1min-60d; -1 disables; 0 is immediate # (change requires restart) #backend_flush_after = 0 # measured in pages, 0 disables #------------------------------------------------------------------------------ # WRITE AHEAD LOG #------------------------------------------------------------------------------ # - Settings - wal_level = minimal # minimal, replica, or logical # (change requires restart) #fsync = on # flush data to disk for crash safety # (turning this off can cause # unrecoverable data corruption) #synchronous_commit = on # synchronization level; # off, local, remote_write, remote_apply, or on wal_sync_method = fdatasync # the default is the first option # supported by the operating system: # open_datasync # fdatasync (default on Linux) # fsync # fsync_writethrough # open_sync #wal_sync_method = open_datasync #full_page_writes = on # recover from partial page writes wal_compression = on # enable compression of full-page writes #wal_log_hints = off # also do full page writes of non-critical updates # (change requires restart) wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers # (change requires restart) wal_writer_delay = 200ms # 1-10000 milliseconds wal_writer_flush_after = 1MB # measured in pages, 0 disables commit_delay = 1000 # range 0-100000, in microseconds #commit_siblings = 5 # range 1-1000 # - Checkpoints - checkpoint_timeout = 30min # range 30s-1d max_wal_size = 3GB min_wal_size = 512MB checkpoint_completion_target = 0.9 # checkpoint target duration, 0.0 - 1.0 #checkpoint_flush_after = 256kB # measured in pages, 0 disables #checkpoint_warning = 30s # 0 disables # - Archiving - #archive_mode = off # enables archiving; off, on, or always # (change requires restart) #archive_command = '' # command to use to archive a logfile segment # placeholders: %p = path of file to archive # %f = file name only # eg 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f' #archive_timeout = 0 # force a logfile segment switch after this # number of seconds; 0 disables #------------------------------------------------------------------------------ # REPLICATION #------------------------------------------------------------------------------ # - Sending Server(s) - # Set these on the master and on any standby that will send replication data. max_wal_senders = 0 # max number of walsender processes # (change requires restart) #wal_keep_segments = 130 # in logfile segments, 16MB each; 0 disables #wal_sender_timeout = 60s # in milliseconds; 0 disables #max_replication_slots = 10 # max number of replication slots # (change requires restart) #track_commit_timestamp = off # collect timestamp of transaction commit # (change requires restart) # - Master Server - # These settings are ignored on a standby server. #synchronous_standby_names = '' # standby servers that provide sync rep # method to choose sync standbys, number of sync standbys, # and comma-separated list of application_name # from standby(s); '*' = all #vacuum_defer_cleanup_age = 0 # number of xacts by which cleanup is delayed # - Standby Servers - # These settings are ignored on a master server. #hot_standby = on # "off" disallows queries during recovery # (change requires restart) #max_standby_archive_delay = 30s # max delay before canceling queries # when reading WAL from archive; # -1 allows indefinite delay #max_standby_streaming_delay = 30s # max delay before canceling queries # when reading streaming WAL; # -1 allows indefinite delay #wal_receiver_status_interval = 10s # send replies at least this often # 0 disables #hot_standby_feedback = off # send info from standby to prevent # query conflicts #wal_receiver_timeout = 60s # time that receiver waits for # communication from master # in milliseconds; 0 disables #wal_retrieve_retry_interval = 5s # time to wait before retrying to # retrieve WAL after a failed attempt # - Subscribers - # These settings are ignored on a publisher. #max_logical_replication_workers = 4 # taken from max_worker_processes # (change requires restart) #max_sync_workers_per_subscription = 2 # taken from max_logical_replication_workers #------------------------------------------------------------------------------ # QUERY TUNING #------------------------------------------------------------------------------ # - Planner Method Configuration - #enable_bitmapscan = on #enable_hashagg = on #enable_hashjoin = on #enable_indexscan = on #enable_indexonlyscan = on #enable_material = on #enable_mergejoin = on #enable_nestloop = on #enable_seqscan = on #enable_sort = on #enable_tidscan = on # - Planner Cost Constants - seq_page_cost = 1 # measured on an arbitrary scale random_page_cost = 2.5 # same scale as above #cpu_tuple_cost = 0.01 # same scale as above #cpu_index_tuple_cost = 0.005 # same scale as above #cpu_operator_cost = 0.0025 # same scale as above #parallel_tuple_cost = 0.1 # same scale as above #parallel_setup_cost = 1000.0 # same scale as above #min_parallel_table_scan_size = 8MB #min_parallel_index_scan_size = 512kB effective_cache_size = 22GB # - Genetic Query Optimizer - #geqo = on #geqo_threshold = 12 #geqo_effort = 5 # range 1-10 #geqo_pool_size = 0 # selects default based on effort #geqo_generations = 0 # selects default based on effort #geqo_selection_bias = 2.0 # range 1.5-2.0 #geqo_seed = 0.0 # range 0.0-1.0 # - Other Planner Options - #default_statistics_target = 100 # range 1-10000 #constraint_exclusion = partition # on, off, or partition #cursor_tuple_fraction = 0.1 # range 0.0-1.0 from_collapse_limit = 20 join_collapse_limit = 20 # 1 disables collapsing of explicit # JOIN clauses #force_parallel_mode = off #------------------------------------------------------------------------------ # ERROR REPORTING AND LOGGING #------------------------------------------------------------------------------ # - Where to Log - log_destination = 'stderr' # Valid values are combinations of # stderr, csvlog, syslog, and eventlog, # depending on platform. csvlog # requires logging_collector to be on. # This is used when logging to stderr: logging_collector = on # Enable capturing of stderr and csvlog # into log files. Required to be on for # csvlogs. # (change requires restart) # These are only used if logging_collector is on: log_directory = 'pg_log' # directory where log files are written, # can be absolute or relative to PGDATA log_filename = 'postgresql-%a.log' # log file name pattern, # can include strftime() escapes #log_file_mode = 0600 # creation mode for log files, # begin with 0 to use octal notation log_truncate_on_rotation = on # If on, an existing log file with the # same name as the new log file will be # truncated rather than appended to. # But such truncation only occurs on # time-driven rotation, not on restarts # or size-driven rotation. Default is # off, meaning append to existing files # in all cases. log_rotation_age = 1d # Automatic rotation of logfiles will # happen after that time. 0 disables. log_rotation_size = 0 # Automatic rotation of logfiles will # happen after that much log output. # 0 disables. # These are relevant when logging to syslog: #syslog_facility = 'LOCAL0' #syslog_ident = 'postgres' #syslog_sequence_numbers = on #syslog_split_messages = on # This is only relevant when logging to eventlog (win32): # (change requires restart) #event_source = 'PostgreSQL' # - When to Log - #client_min_messages = notice # values in order of decreasing detail: # debug5 # debug4 # debug3 # debug2 # debug1 # log # notice # warning # error #log_min_messages = warning # values in order of decreasing detail: # debug5 # debug4 # debug3 # debug2 # debug1 # info # notice # warning # error # log # fatal # panic #log_min_error_statement = error # values in order of decreasing detail: # debug5 # debug4 # debug3 # debug2 # debug1 # info # notice # warning # error # log # fatal # panic (effectively off) #log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements # and their durations, > 0 logs only # statements running at least this number # of milliseconds # - What to Log - #debug_print_parse = off #debug_print_rewritten = off #debug_print_plan = off #debug_pretty_print = on log_checkpoints = on log_connections = on log_disconnections = on log_duration = on #log_error_verbosity = default # terse, default, or verbose messages #log_hostname = off log_line_prefix = '< %m >' # special values: # %a = application name # %u = user name # %d = database name # %r = remote host and port # %h = remote host # %p = process ID # %t = timestamp without milliseconds # %m = timestamp with milliseconds # %n = timestamp with milliseconds (as a Unix epoch) # %i = command tag # %e = SQL state # %c = session ID # %l = session line number # %s = session start timestamp # %v = virtual transaction ID # %x = transaction ID (0 if none) # %q = stop here in non-session # processes # %% = '%' # eg '<%u%%%d> ' log_lock_waits = on # log lock waits >= deadlock_timeout log_statement = 'all' # none, ddl, mod, all #log_replication_commands = off log_temp_files = 0 # log temporary files equal or larger # than the specified size in kilobytes; # -1 disables, 0 logs all temp files log_timezone = 'W-SU' # - Process Title - #cluster_name = '' # added to process titles if nonempty # (change requires restart) #update_process_title = on #------------------------------------------------------------------------------ # RUNTIME STATISTICS #------------------------------------------------------------------------------ # - Query/Index Statistics Collector - #track_activities = on #track_counts = on #track_io_timing = on #track_functions = none # none, pl, all #track_activity_query_size = 1024 # (change requires restart) #stats_temp_directory = 'pg_stat_tmp' # - Statistics Monitoring - #log_parser_stats = off #log_planner_stats = off #log_executor_stats = off #log_statement_stats = off #------------------------------------------------------------------------------ # AUTOVACUUM PARAMETERS #------------------------------------------------------------------------------ autovacuum = on # Enable autovacuum subprocess? 'on' # requires track_counts to also be on. log_autovacuum_min_duration = 0 # -1 disables, 0 logs all actions and # their durations, > 0 logs only # actions running at least this number # of milliseconds. autovacuum_max_workers = 4 # max number of autovacuum subprocesses # (change requires restart) #autovacuum_naptime = 20s # time between autovacuum runs #autovacuum_vacuum_threshold = 50 # min number of row updates before # vacuum #autovacuum_analyze_threshold = 50 # min number of row updates before # analyze #autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum #autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze #autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum # (change requires restart) #autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age # before forced vacuum # (change requires restart) #autovacuum_vacuum_cost_delay = 20ms # default vacuum cost delay for # autovacuum, in milliseconds; # -1 means use vacuum_cost_delay #autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for # autovacuum, -1 means use # vacuum_cost_limit #------------------------------------------------------------------------------ # CLIENT CONNECTION DEFAULTS #------------------------------------------------------------------------------ # - Statement Behavior - #search_path = '"$user", public' # schema names #default_tablespace = '' # a tablespace name, '' uses the default #temp_tablespaces = '' # a list of tablespace names, '' uses # only default tablespace #check_function_bodies = on #default_transaction_isolation = 'read committed' #default_transaction_read_only = off #default_transaction_deferrable = off #session_replication_role = 'origin' #statement_timeout = 0 # in milliseconds, 0 is disabled #lock_timeout = 0 # in milliseconds, 0 is disabled #idle_in_transaction_session_timeout = 0 # in milliseconds, 0 is disabled #vacuum_freeze_min_age = 50000000 #vacuum_freeze_table_age = 150000000 #vacuum_multixact_freeze_min_age = 5000000 #vacuum_multixact_freeze_table_age = 150000000 #bytea_output = 'hex' # hex, escape #xmlbinary = 'base64' #xmloption = 'content' #gin_fuzzy_search_limit = 0 #gin_pending_list_limit = 4MB # - Locale and Formatting - datestyle = 'iso, dmy' #intervalstyle = 'postgres' timezone = 'W-SU' #timezone_abbreviations = 'Default' # Select the set of available time zone # abbreviations. Currently, there are # Default # Australia (historical usage) # India # You can create your own file in # share/timezonesets/. #extra_float_digits = 0 # min -15, max 3 #client_encoding = sql_ascii # actually, defaults to database # encoding # These settings are initialized by initdb, but they can be changed. lc_messages = 'ru_RU.UTF-8' # locale for system error message # strings lc_monetary = 'ru_RU.UTF-8' # locale for monetary formatting lc_numeric = 'ru_RU.UTF-8' # locale for number formatting lc_time = 'ru_RU.UTF-8' # locale for time formatting # default configuration for text search default_text_search_config = 'pg_catalog.russian' # - Other Defaults - #dynamic_library_path = '$libdir' #local_preload_libraries = '' #session_preload_libraries = '' #------------------------------------------------------------------------------ # LOCK MANAGEMENT #------------------------------------------------------------------------------ #deadlock_timeout = 1s max_locks_per_transaction = 256 # min 10 # (change requires restart) #max_pred_locks_per_transaction = 64 # min 10 # (change requires restart) #max_pred_locks_per_relation = -2 # negative values mean # (max_pred_locks_per_transaction # / -max_pred_locks_per_relation) - 1 #max_pred_locks_per_page = 2 # min 0 #------------------------------------------------------------------------------ # VERSION/PLATFORM COMPATIBILITY #------------------------------------------------------------------------------ # - Previous PostgreSQL Versions - #array_nulls = on #backslash_quote = safe_encoding # on, off, or safe_encoding #default_with_oids = off escape_string_warning = off #lo_compat_privileges = off #operator_precedence_warning = off #quote_all_identifiers = off standard_conforming_strings = off #synchronize_seqscans = on # - Other Platforms and Clients - #transform_null_equals = off #------------------------------------------------------------------------------ # ERROR HANDLING #------------------------------------------------------------------------------ #exit_on_error = off # terminate session on any error? #restart_after_crash = on # reinitialize after backend crash? #------------------------------------------------------------------------------ # CONFIG FILE INCLUDES #------------------------------------------------------------------------------ # These options allow settings to be loaded from files other than the # default postgresql.conf. #include_dir = 'conf.d' # include files ending in '.conf' from # directory 'conf.d' #include_if_exists = 'exists.conf' # include file only if it exists #include = 'special.conf' # include file #------------------------------------------------------------------------------ # CUSTOMIZED OPTIONS #------------------------------------------------------------------------------ online_analyze.threshold = 50 online_analyze.scale_factor = 0.1 online_analyze.enable = on online_analyze.verbose = off online_analyze.local_tracking = on online_analyze.min_interval = 10000 online_analyze.table_type = 'temporary' online_analyze.verbose='off' plantuner.fix_empty_table='on' MS SQL was configured as follows:
and
Cluster 1C settings were left standard:
and
The servers did not have an antivirus program and nothing else was installed.
For MS SQL, the tempdb database was moved to a separate logical disk. However, the data files and transaction log files for the databases were located on the same logical drive (that is, no separation of the data files and transaction logs into separate logical drives was done).
Disk indexing in Windows, where MS SQL Server was located, was disabled on all logical drives (as is commonly done in most cases on prodovskikh environments).
Description of the basic algorithm of the automated testing script
The main estimated testing period is 1 year, during which documents and background information are generated for each day using the specified parameters.
For each day of execution, the input and output information blocks are started:
At the end of each month, in which the creation of documents was performed, the input and output information blocks are executed:
As a result of the test, information about the test time is given in hours, minutes, seconds and milliseconds.
Key features of the test script:
Basic test plan for each database:
:
For each day of execution, the input and output information blocks are started:
- Block 1 "SPR_PTU" - "The receipt of goods and services"
- The "Counterparts" directory opens.
- A new element of the "Counterparts" directory is created with the "Supplier" type
- A new element of the “Contracts” directory is created with the “Supplier” type for a new counterparty
- The “Nomenclature” directory opens.
- A set of elements of the “Nomenclature” directory is created with the “Product” type.
- A set of elements of the “Nomenclature” directory is created with the “Service” view.
- A list of documents "Income of goods and services"
- A new document “Receipt of goods and services” is created in which the tabular parts “Goods” and “Services” are filled with the created data sets
- The report "Account Card 41" for the current month is formed (if the interval of additional formation is indicated)
- Block 2 "SPR_RTU" - "Sales of goods and services"
- The "Counterparts" directory opens.
- A new element of the "Counterparts" directory is created with the "Buyer" view.
- A new element of the “Contracts” directory is created with the view “With the buyer” for a new counterparty
- A list of documents "Sales of goods and services"
- A new document “Sales of goods and services” is being created in which the tabular parts “Goods” and “Services” are filled in according to the specified parameters from previously created data
- The report "Account Card 41" for the current month is formed (if the interval of additional formation is indicated)
- The report “Account Card 41” for the current month is formed.
At the end of each month, in which the creation of documents was performed, the input and output information blocks are executed:
- The report “Account Card 41” is formed from the beginning of the year at the end of the month.
- Formed report "turnover balance sheet" from the beginning of the year at the end of the month
- Regular procedure “Closing of the month” is carried out.
As a result of the test, information about the test time is given in hours, minutes, seconds and milliseconds.
Key features of the test script:
- The ability to disable / enable individual blocks
- Ability to specify the total number of documents for each of the blocks
- Ability to specify the number of documents for each of the blocks per day
- The ability to specify the number of goods and services within the documents
- Ability to set lists of quantitative and price indicators for the record. Used to create different sets of values in documents.
Basic test plan for each database:
- "First Test". A small number of documents with simple tables are created under one user, “closing months” are formed
- — 20 . 1 . : 50 «», 50 «», 100 «», 50 «» + «», 50 «» + «», 2 « ». 1 1
- « ». ,
- — 50-60 . 3 . : 90 «», 90 «», 540 «», 90 «» + «», 90 «» + «», 3 « ». 3 3
- « ». . .
- — 40-60 . 2 . : 50 «», 50 «», 300 «», 50 «» + «», 50 «» + «». 3 3
:
- , :
- « »
- « » « »
- 1 "*.dt"
- « »
results
And now the most interesting is the results on MS SQL Server DBMS:
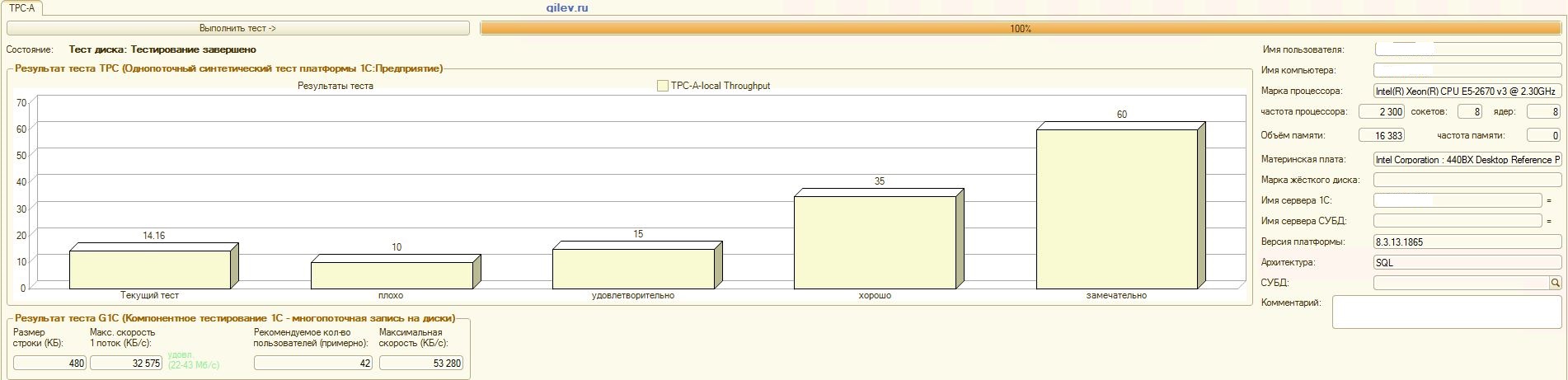
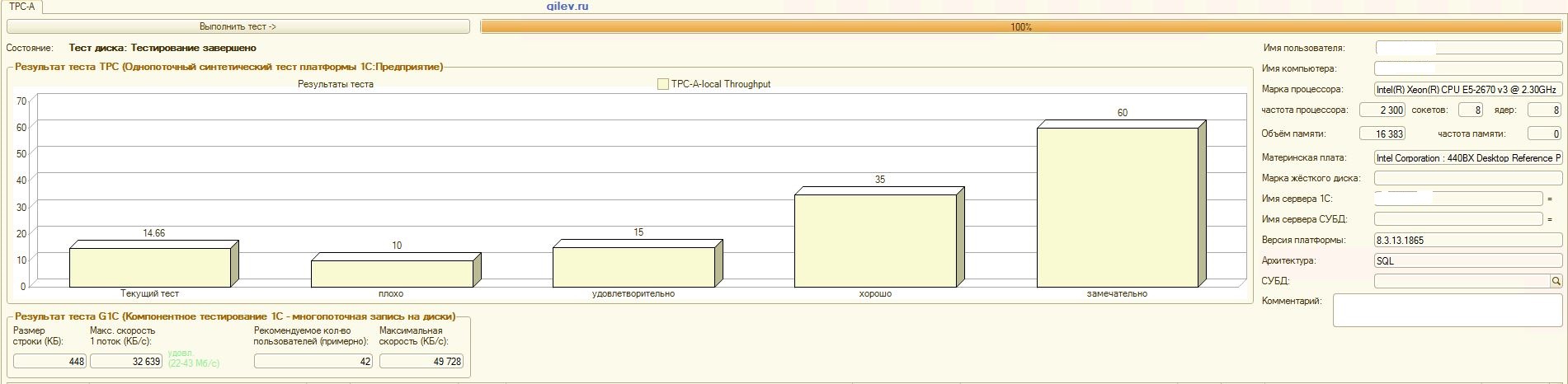

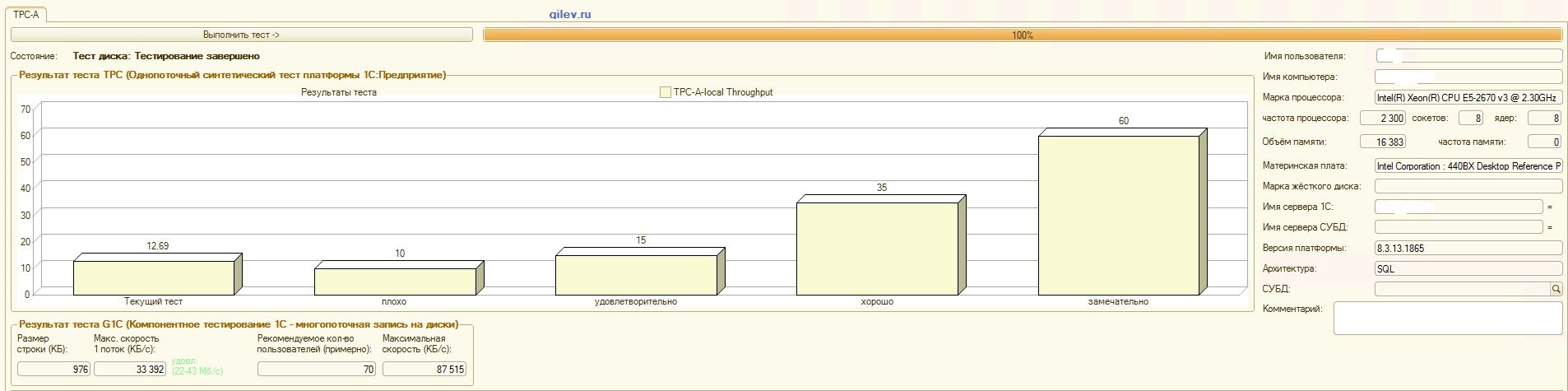
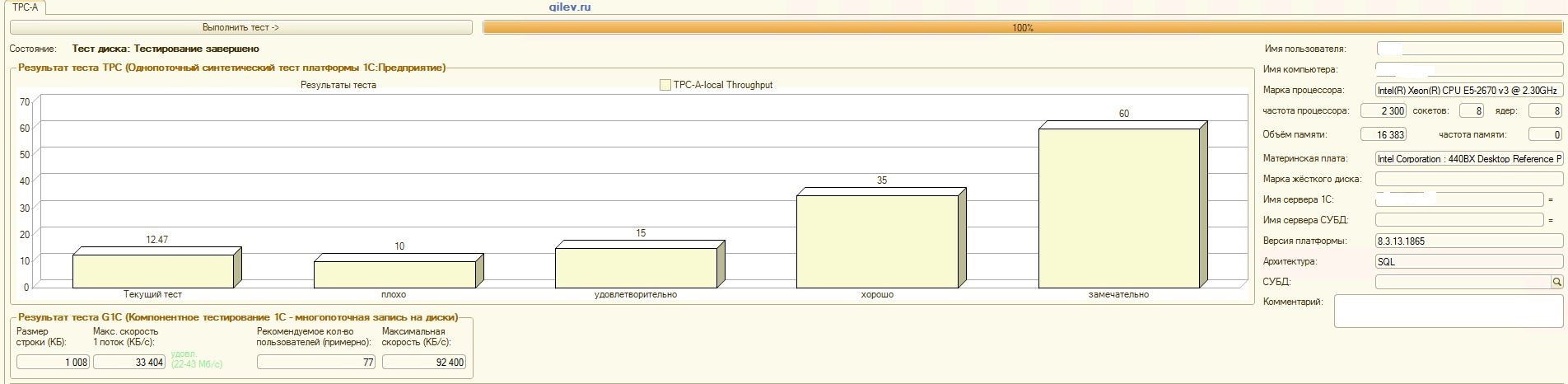

Gilev test:
| Indicator | PostgreSQL | % difference (improvement) in PostgreSQL DBMS relative to MS SQL DBMS | |
|---|---|---|---|
| 14.41 | 12.55 | -14,82 | |
| +3.3 | |||
| +66.83 | |||
| 42 | 70 | +66.67 |
As can be seen from the results, in the general synthetic benchmark, the PostgreSQL DBMS lost an average of 14.82% in performance to the MS SQL DBMS . However, according to the last two indicators, PostgreSQL showed a much better result than MS SQL.
Specialized tests for 1C Accounting:
| Test description | PostgreSQL, sec | % difference (improvement) in PostgreSQL DBMS relative to MS SQL DBMS | |
|---|---|---|---|
| 1056.45 | 1064 | -0.7 | |
| 3230,8 | 3236.6 | -0,2 | |
| 1707,45 | 1738,8 | -1,8 | |
| 1859,1 | 1864,9 | -0,3 | |
| thirty | 22 | +26,7 | |
| 01.01.2018 31.12.2018 | 138,5 | 164,5 | -15,8 |
| 316 | 397 | -20,4 | |
| *.dt | 87 | 87 | 0 |
| *.dt | 201 | 207 | -2,9 |
| « 2018 . | 78 | 64,5 | +17,3 |
As can be seen from the results, 1C Accounting works approximately equally on both MS SQL and PostgreSQL with the above settings.
In both cases, the DBMS worked stably.
Of course, you may need more fine tuning from both the DBMS and the OS side and the file system. Everything was done the way the publications were broadcast, which said that there would be a significant performance increase or approximately the same when switching from MS SQL to PostgreSQL. Moreover, in this testing a number of measures were taken to optimize the OS itself and the file system for CentOS, which are described above.
It is worth noting that the Gilev test was run repeatedly for PostgreSQL — the best results are given. According to MS SQL, the Gilev test was launched 3 times, that is, they were not further optimized for MS SQL. All subsequent attempts were to bring the elephant to MS SQL.
After achieving the optimal difference in the Gilev synthetic test between MS SQL and PostgreSQL, specialized tests were conducted for 1C Accounting, as described above.
The general conclusion is that, despite a significant drawdown in performance on the Gilev synthetic test, PostgreSQL DBMS relative to MS SQL, with proper settings given above, 1C Accounting can be installed on both MS SQL DBMS and PostgreSQL DBMS .
Remarks
Immediately it should be noted that this analysis was done only to compare the performance of 1C in different DBMS.
This analysis and conclusion is correct only for 1C Accounting under the conditions and software versions described above. Based on the analysis obtained, it is impossible to conclude exactly what will happen with other settings and software versions, as well as with a different 1C configuration.
However, the result of the Gilev test suggests that in all configurations of 1C version 8.3 and newer with proper settings, the maximum performance drawdown is likely to be no more than 15% for PostgreSQL DBMS relative to MS SQL DBMS. It is also worth considering that any detailed testing for accurate comparison takes considerable time and resources. Based on this, it is possible to make a more likely assumption that1C version 8.3 and newer can be transferred from MS SQL to PostgreSQL with a maximum performance loss of up to 15%. Objective barriers to the transition were not identified, t to these 15% may not appear, and in the event of their manifestation, it is enough just to buy a little more powerful equipment if necessary.
It is also important to note that the tested databases were small, that is, significantly less than 100 GB of data size, and the maximum number of simultaneously running threads was 4. This means that for large databases that are significantly larger than 100 GB (for example, about 1 TB) , as well as for databases with intensive calls (tens and hundreds of simultaneous active threads), these results may be incorrect.
For a more objective analysis, it will be useful in the future to compare the released MS SQL Server 2019 Developer and PostgreSQL 12 installed on the same CentOS OS, and also when MS SQL is on the latest version of the Windows Server OS. Now, no one puts PostgreSQL on Windows OS, and the PostgreSQL DBMS performance will be very significant.
Of course, the Gilev test speaks in general about performance and not only for 1C. However, at the moment it is time to say that MS SQL DBMS will always be much better than PostgreSQL DBMS early, because there are not enough facts. To confirm or refute this statement, you must do a number of other tests. For example, for .NET you need to write both atomic actions and complex tests, run them repeatedly and under different conditions, fix the execution time and take the average value. After that, compare these values. This will be an objective analysis.
At the moment we are not ready to conduct such an analysis, but in the future it is quite possible that we will conduct it. Then we will write in more detail at what operations PostgreSQL is better than MS SQL and how much in percents, and where MS SQL is better than PostgreSQL and how many in percents.
Also, in our test, optimization methods for MS SQL, which are described here, were not applied . Perhaps in this article just forgot to turn off the indexing of Windows disks.
When comparing two DBMS, one more weighty moment must be remembered: PostgreSQL DBMS is free and open, while MS SQL DBMS is paid and has a closed source code.
Acknowledgments
- set up 1C and run the Gilev tests, and also made a significant contribution to the creation of this publication:
- Roman Buts - team leader 1C
- Alexander Gryaznov - 1C programmer
- Fortis colleagues who have made significant contributions to optimizing CentOS, PostgreSQL, and more, but have chosen to remain incognito
Also a special thank you to uaggster and BP1988 for consultation in some points on MS SQL and Windows.
Afterword
Also an interesting analysis was done in this article .
What were your results and how did you do the testing?
Sources
- PostgreSQL 10.9 Documentation
- Postgres Pro Standard 10.7.1 Documentation
- 1C Battle: PostgreSQL 9.10 vs MS SQL 2016
- Gilev test
- Appendix I. Configuring Postgres Pro for 1C Solutions
- Cybertec PostgreSQL Configurator
- PostgreSQL vs MS SQL for 1C
- Basics of Tuning Checkpoints
- PostgreSQL tuning for high performance
- Ilya Kosmodemyansky: „Linux tuning to improve PostgreSQL performance“
- How PostgreSQL works with disk / Ilya Kosmodemyansky (PostgreSQL Consulting)
- 1C performance comparison when using PostgreSQL and MS SQL DBMS
- PostgreSQL 1: . Part 2
Source: https://habr.com/ru/post/457602/
All Articles