Obfuscation of data for performance tests
ClickHouse users know that its main advantage is the high speed of processing analytical queries. But how can we make such statements? This should be confirmed by performance tests that can be trusted. We will talk about them today.
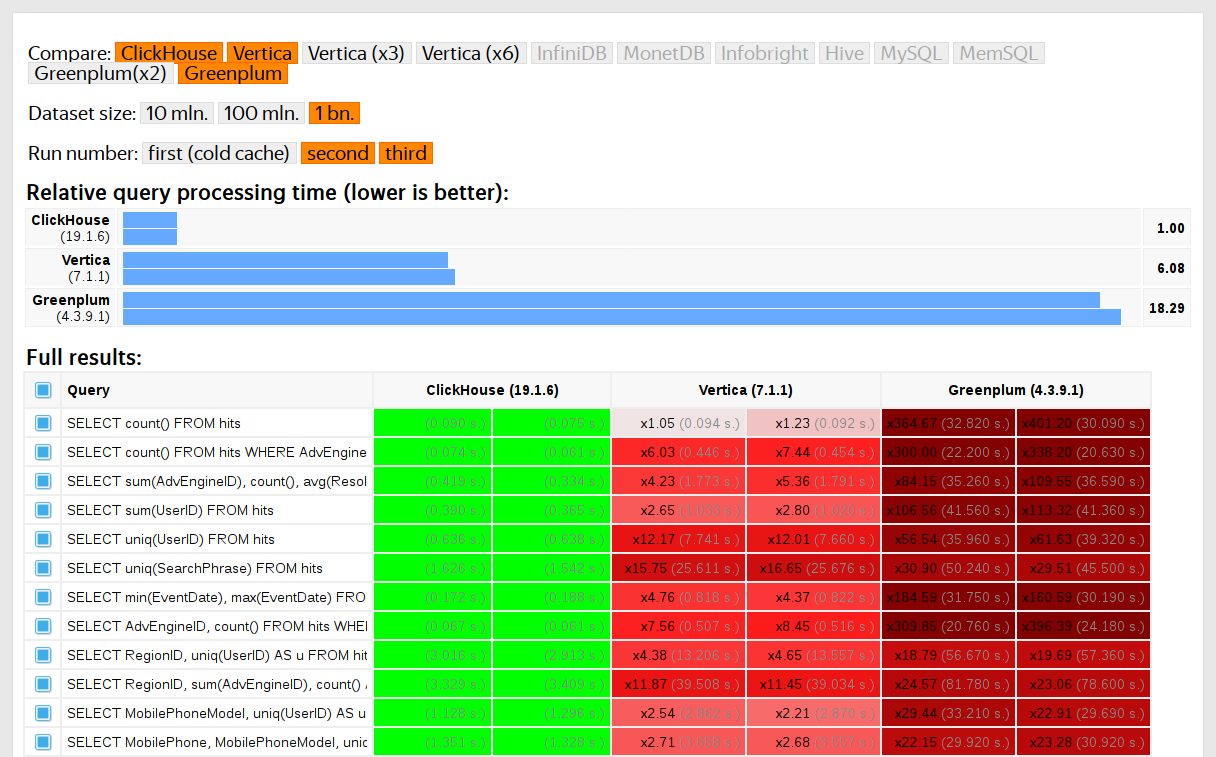
We started conducting such tests in 2013, long before the product became available in the open source. Like now, then we were most interested in the speed of data service Yandex.Metrica. We have already stored data in ClickHouse since January 2009. Some of the data has been recorded in the database since 2012, and some has been converted from OLAPServer and Metrage , the data structures that Yandex.Metric has used before. Therefore, for tests, we took the first available subset of 1 billion pageview data. There were no queries in the Metric yet, and we came up with the queries that were most interesting to us (all sorts of filtering, aggregation and sorting).
')
ClickHouse has been tested against similar systems, such as Vertica and MonetDB. For the integrity of testing, it was conducted by an employee who had not previously been a ClickHouse developer, and special cases in the code were not optimized before receiving the results. Similarly, we obtained a data set for functional tests.
After ClickHouse came to open source in 2016, there are more questions for the tests.
Performance tests:
You can solve these problems by discarding old tests and making new ones based on open data. Among the open data, you can take flight data to the United States , taxi trips to New York, or use ready-made benchmarks TPC-H, TPC-DS, Star Schema Benchmark . The inconvenience is that this data is far from Yandex.Metrica data, and I would like to keep the test queries.
Testing the performance of the service is necessary only on real data from the production. Consider a few examples.
Example 1
Suppose you populate a database with uniformly distributed pseudo-random numbers. In this case, data compression will not work. But data compression is an important feature for analytical DBMSs. Choosing the right compression algorithm and the right way to integrate it into the system is a non-trivial task, in which there is no one correct solution, because data compression requires a compromise between the speed of compression and decompression and the potential degree of compression. Systems that cannot compress data are guaranteed to lose. But if uniformly distributed pseudo-random numbers are used for tests, this factor is not considered, and all other results will be distorted.
Conclusion: test data should have a realistic compression ratio.
I talked about optimizing data compression algorithms in ClickHouse in a previous post .
Example 2
Let us be interested in the speed of the SQL query:
This is a typical query for Yandex. Metrics. What is important for the speed of its work?
But it is also very important that the amount of data for different regions is unevenly distributed. (Probably, it is distributed according to a power law. I plotted the log-log scale, but I am not sure.) And if so, then it is important for us that the states of the uniq aggregate function with a small number of values use little memory. When there are a lot of aggregation keys, the count goes to units of bytes. How to get the generated data that has all these properties? Of course, it is better to use real data.
Many DBMSs implement the HyperLogLog data structure for an approximate calculation of COUNT (DISTINCT), but they all work relatively poorly because this data structure uses a fixed amount of memory. And in ClickHouse there is a function that uses a combination of three different data structures , depending on the size of the set.
Conclusion: test data should represent the properties of the distribution of values in the data - cardinality (the number of values in the columns) and mutual cardinality of several different columns.
Example 3
Okay, let us test the performance of non-analytical ClickHouse DBMS, but something simpler, for example, hash tables. For hash tables, the correct choice of hash function is very important. For std :: unordered_map, it is slightly less important because it is a hash table based on chains, and a prime number is used as the size of the array. In the implementation of the standard library in gcc and clang, the default hash function for numeric types is the trivial hash function. But std :: unordered_map is not the best choice when we want to get maximum speed. When using open-addressing hash tables, choosing the right hash function becomes a decisive factor, and we cannot use the trivial hash function.
It is easy to find the performance tests of hash tables on random data, without considering the hash functions used. It is also easy to find tests of hash functions with an emphasis on the speed of computation and some quality criteria, although apart from the data structures used. But the fact is that hash tables and HyperLogLog require different quality criteria for hash functions.
Read more about this in the report “How hash tables are organized in ClickHouse” . It is a bit outdated, as swiss tables are not considered in it.
We want to obtain data for testing the performance of the structure is the same as Yandex.Metrica data, for which all properties important for benchmarks are saved, but so that no trace of real site visitors is left in these data. That is, the data must be anonymized, while maintaining:
And what do you need for data to have a similar compression ratio? For example, if LZ4 is used, the substrings in the binary data should be repeated at approximately the same distances and the repetitions should be approximately the same length. For ZSTD, a byte entropy match is added.
The maximum task: to make a tool available to external people, with which everyone can anonymize their data set for publication. So that we can debug and test the performance on someone else's data similar to production data. And I would also like the generated data to be interesting to watch.
This is an informal formulation of the problem. However, no one was going to give a formal statement.
We should not exaggerate the importance of this task for us. In fact, it was never in the plans and no one was even going to do it. I just did not leave hopes that something would come up by itself, and suddenly I will have a good mood and a lot of things that can be put off until later.
The first idea is to select for each column of the table a family of probability distributions that models it. Then, based on the statistics of the data, select the parameters (model fitting) and use the selected distribution to generate new data. You can use a pseudo-random number generator with a predefined seed to get a reproducible result.
For text fields you can use Markov chains - a clear model for which you can make an effective implementation.
True, some tricks will be required:
All this is presented in the form of a program in which all distributions and dependencies are hard coded — the so-called “C ++ script”. However, Markov models are still calculated from the sum of statistics, smoothing and desensitization using noise. I started writing this script, but for some reason after I wrote the model for ten columns explicitly, it suddenly became unbearably boring. And in the hits table in Yandex.Metrica back in 2012 there were more than 100 columns.
This approach to the problem was a failure. If I approached her more diligently, surely the script would have been written.
Advantages:
Disadvantages:
And I would like a more general solution - so that it can be applied not only for Yandex.Metrica data, but also for obfuscation of any other data.
However, improvements are possible here. You can not manually select the models, but implement the catalog of models and choose the best among them (best fit + some kind of regularization). Or maybe you can use Markov models for all types of fields, and not just for text. The dependencies between the data can also be understood automatically. To do this, calculate the relative entropy (relative amount of information) between the columns, or, more simply, the relative cardinality (something like “how many are on average different values of A for a fixed value B”) for each pair of columns. This will allow you to understand, for example, that URLDomain depends entirely on the URL, and not vice versa.
But I also refused this idea, because there are too many options for what needs to be taken into account, and it will take a long time to write.
I have already told how important this task is for us. No one even thought about making any attempts to implement it. Fortunately, a colleague Ivan Puzyrevsky then worked as a teacher at the HSE and at the same time worked on the development of the YT core. He asked if I had any interesting tasks that could be offered to students as a diploma topic. I offered him this one, and he assured me that it was suitable. So I gave this task to a good person “from the street” - Sharif Anvardinov (the NDA is signed to work with the data).
He told him about all his ideas, but most importantly - explained that the problem can be solved in any way. And it would be a good option to use those approaches that I absolutely do not understand: for example, to generate a text dump of data using LSTM. This looked encouraging thanks to the article The Unreasonable Effectiveness of Recurrent Neural Networks , which then caught my eye.
The first feature of the task is that you need to generate structured data, and not just text. It was not obvious whether the recurrent neural network could generate data with the desired structure. This can be solved in two ways. The first is to use separate models for the generation of the structure and for the “filler”: the neural network should only generate values. But this option was postponed until later, after which they never did. The second way is to simply generate a TSV dump as text. Practice has shown that in the text of the lines will not match the structure, but these lines can be thrown out when loading.
The second feature - the recurrent neural network generates a sequence of data, and the dependencies in the data can follow only in the order of this sequence. But in our data, perhaps, the order of the columns is reversed with respect to the dependencies between them. With this feature, we did not do anything.
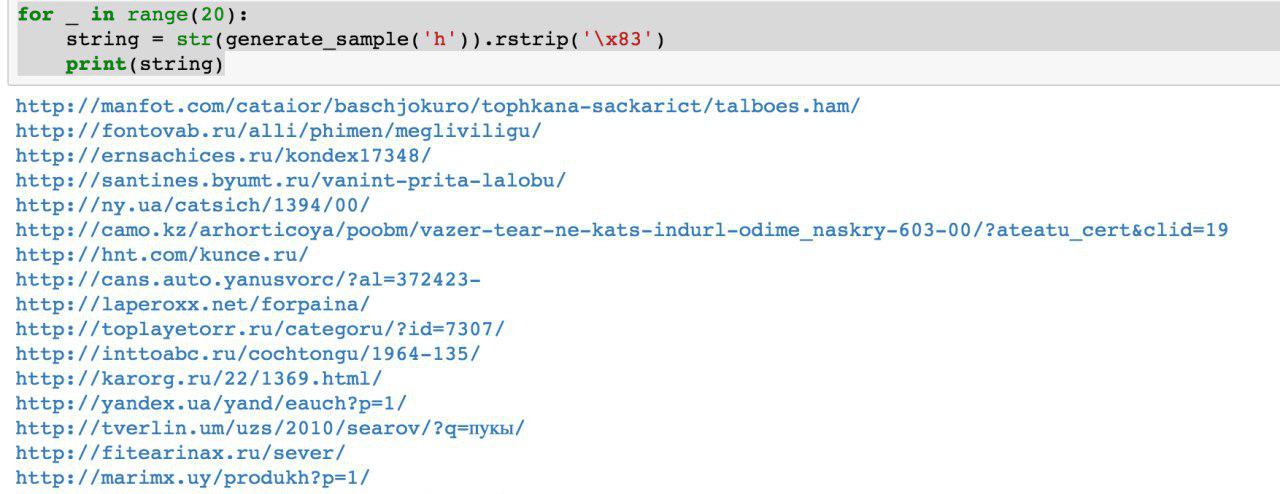
Closer to the summer, the first working Python script appeared that generated the data. At first glance, the quality of the data is decent:
The truth revealed difficulties:
Sharif tried to study the quality of the data by comparing statistics. For example, I calculated the frequency with which different characters are encountered in the source and in the generated data. The result was stunning - the most frequent symbols are Ð and Ñ.
Do not worry - he defended his diploma perfectly well, after which we safely forgot about this work.
Suppose that the statement of the problem has decreased to one point: you need to generate data for which the compression ratios will be exactly the same as for the original data, and the data should be decompressed with exactly the same speed. How to do it? You need to edit the bytes of the compressed data directly! Then the size of the compressed data will not change, but the data itself will change. Yes, and everything will work quickly. When this idea appeared, I immediately wanted to implement it, despite the fact that it solves some other task instead of the original one. It always happens.
How to edit a compressed file directly? Suppose we are only interested in LZ4. Compressed using LZ4 data consists of commands of two types:
Initial data:
Compressed data (conditionally):
In the compressed file, we leave match as it is, and in the literals we will change the values of bytes. As a result, after releasing, we get a file in which all repeating sequences of length not less than 4 are also repeated, and they are repeated at the same distances, but at the same time consist of another set of bytes (figuratively speaking, in the modified file not a single byte was taken ).
But how to change bytes? This is not obvious, because in addition to column types, the data also has its own internal, implicit structure that we would like to preserve. For example, text is often stored in UTF-8 encoding - and we want valid UTF-8 in the generated data too. I made a simple heuristic to satisfy several conditions:
The peculiarity of this approach is that the source data itself serves as a model for the data, which means that the model cannot be published. It allows you to generate the amount of data not more than the original. For comparison, in previous approaches it was possible to create a model and generate an unlimited amount of data on its basis.
Example for URL:
I was pleased with the result - it was interesting to watch the data. But still something was wrong. The structure of the URLs was preserved, but in some places it was too easy to guess yandex or avito. Made heuristics, which sometimes rearranges some bytes in places.
Worried and other considerations. For example, sensitive information can be represented in a column of the type FixedString in binary form and for some reason consist of ASCII control characters and punctuation, which I decided to keep. And I do not consider data types.
Another problem: if data of the “length, value” type is stored in one column (this is how String type columns are stored), then how to ensure that the length remains correct after the mutation? When I tried to fix it, the task immediately became uninteresting.
But the problem is not solved. We conducted several experiments, and it only got worse. It remains only to do nothing and read random pages on the Internet, because the mood is already spoiled. Fortunately, on one of these pages was an analysis of the algorithm for rendering the scene of the death of the main character in the game Wolfenstein 3D.

Beautiful animation - the screen is filled with blood. The article explains that this is actually a pseudo-random permutation. A random permutation is a randomly chosen one-to-one transformation of a set. That is, the display of the entire set, in which the results for different arguments are not repeated. In other words, it is a way to iterate over all the elements of a set in a random order. It is this process that is shown in the picture - we paint over each pixel, selected in random order from all, without repetitions. If we simply chose a random pixel at each step, it would take us a long time to fill in the last one.
The game uses a very simple algorithm for a pseudo-random permutation - LFSR (linear feedback shift register). Like pseudo-random number generators, random permutations, or rather their key parametrized families, can be cryptographically resistant — we just need this for data conversion. Although there may be unclear details. For example, cryptographically strong encryption of N bytes to N bytes with a pre-fixed key and initialization vector, it would seem, can be used as a pseudo-random permutation of a set of N-byte strings. Indeed, such a transformation is one-to-one and looks random. But if we use the same transformation for all our data, the result may be subject to analysis, because the same value is the initialization vector and the key is used several times. This is similar to the Electronic Codebook mode of block cipher operation.
What are some ways to get a pseudo-random permutation? You can take simple one-to-one transformations and assemble from them a fairly complex function that will look random. I will give as an example some of my favorite one-to-one transformations:
For example, from three multiplications and two xor-shift operations, the murmurhash finalizer is compiled . This operation is a pseudo-random permutation. But just in case, I note that hash functions, even N bits to N bits, are not required to be one-to-one.
Or another interesting example from elementary number theory from the site of Jeff Preshing.
How can pseudo-random permutations be used for our task? With their help, you can convert all numeric fields. Then it will be possible to preserve all the cardinality and mutual cardinality of all combinations of fields. That is, COUNT (DISTINCT) will return the same value as before the conversion, moreover with any GROUP BY.
It is worth noting that the preservation of all cardinality is a bit contrary to the formulation of the problem of anonymizing data. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , , .
, . , 10, . How to achieve this?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . And so on. .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c Hackers News , . Redis — . , .
. — , . , .
, F 4 , .
: , , — , , !
. , , , . :
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
. ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
, . :
, - , - . , . clickhouse-obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
, . , ? , , . , , . , (
, .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xz
clickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xz
ClickHouse. , ClickHouse .
We started conducting such tests in 2013, long before the product became available in the open source. Like now, then we were most interested in the speed of data service Yandex.Metrica. We have already stored data in ClickHouse since January 2009. Some of the data has been recorded in the database since 2012, and some has been converted from OLAPServer and Metrage , the data structures that Yandex.Metric has used before. Therefore, for tests, we took the first available subset of 1 billion pageview data. There were no queries in the Metric yet, and we came up with the queries that were most interesting to us (all sorts of filtering, aggregation and sorting).
')
ClickHouse has been tested against similar systems, such as Vertica and MonetDB. For the integrity of testing, it was conducted by an employee who had not previously been a ClickHouse developer, and special cases in the code were not optimized before receiving the results. Similarly, we obtained a data set for functional tests.
After ClickHouse came to open source in 2016, there are more questions for the tests.
Disadvantages of closed data tests
Performance tests:
- Not reproducible from the outside, because to run it requires a closed data that can not be published. For the same reason, some of the functional tests are not available to external users.
- Do not develop. There is a need to significantly expand their set, so that changes in the speed of operation of individual parts of the system can be insulated in an isolated manner.
- Do not run on the commit and for pull requests, external developers cannot check their code for performance regression.
You can solve these problems by discarding old tests and making new ones based on open data. Among the open data, you can take flight data to the United States , taxi trips to New York, or use ready-made benchmarks TPC-H, TPC-DS, Star Schema Benchmark . The inconvenience is that this data is far from Yandex.Metrica data, and I would like to keep the test queries.
It is important to use real data.
Testing the performance of the service is necessary only on real data from the production. Consider a few examples.
Example 1
Suppose you populate a database with uniformly distributed pseudo-random numbers. In this case, data compression will not work. But data compression is an important feature for analytical DBMSs. Choosing the right compression algorithm and the right way to integrate it into the system is a non-trivial task, in which there is no one correct solution, because data compression requires a compromise between the speed of compression and decompression and the potential degree of compression. Systems that cannot compress data are guaranteed to lose. But if uniformly distributed pseudo-random numbers are used for tests, this factor is not considered, and all other results will be distorted.
Conclusion: test data should have a realistic compression ratio.
I talked about optimizing data compression algorithms in ClickHouse in a previous post .
Example 2
Let us be interested in the speed of the SQL query:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10 This is a typical query for Yandex. Metrics. What is important for the speed of its work?
- How is GROUP BY .
- What data structure is used to calculate the uniq aggregate function.
- How many different RegionIDs are there and how many RAMs each state of the uniq function requires.
But it is also very important that the amount of data for different regions is unevenly distributed. (Probably, it is distributed according to a power law. I plotted the log-log scale, but I am not sure.) And if so, then it is important for us that the states of the uniq aggregate function with a small number of values use little memory. When there are a lot of aggregation keys, the count goes to units of bytes. How to get the generated data that has all these properties? Of course, it is better to use real data.
Many DBMSs implement the HyperLogLog data structure for an approximate calculation of COUNT (DISTINCT), but they all work relatively poorly because this data structure uses a fixed amount of memory. And in ClickHouse there is a function that uses a combination of three different data structures , depending on the size of the set.
Conclusion: test data should represent the properties of the distribution of values in the data - cardinality (the number of values in the columns) and mutual cardinality of several different columns.
Example 3
Okay, let us test the performance of non-analytical ClickHouse DBMS, but something simpler, for example, hash tables. For hash tables, the correct choice of hash function is very important. For std :: unordered_map, it is slightly less important because it is a hash table based on chains, and a prime number is used as the size of the array. In the implementation of the standard library in gcc and clang, the default hash function for numeric types is the trivial hash function. But std :: unordered_map is not the best choice when we want to get maximum speed. When using open-addressing hash tables, choosing the right hash function becomes a decisive factor, and we cannot use the trivial hash function.
It is easy to find the performance tests of hash tables on random data, without considering the hash functions used. It is also easy to find tests of hash functions with an emphasis on the speed of computation and some quality criteria, although apart from the data structures used. But the fact is that hash tables and HyperLogLog require different quality criteria for hash functions.
Read more about this in the report “How hash tables are organized in ClickHouse” . It is a bit outdated, as swiss tables are not considered in it.
Task
We want to obtain data for testing the performance of the structure is the same as Yandex.Metrica data, for which all properties important for benchmarks are saved, but so that no trace of real site visitors is left in these data. That is, the data must be anonymized, while maintaining:
- compression ratios
- cardinality (the number of different values),
- mutual cardinality of several different columns,
- properties of probability distributions that can be used to model data (for example, if we assume that regions are distributed according to a power law, then the exponent — the distribution parameter — artificial data should be about the same as this).
And what do you need for data to have a similar compression ratio? For example, if LZ4 is used, the substrings in the binary data should be repeated at approximately the same distances and the repetitions should be approximately the same length. For ZSTD, a byte entropy match is added.
The maximum task: to make a tool available to external people, with which everyone can anonymize their data set for publication. So that we can debug and test the performance on someone else's data similar to production data. And I would also like the generated data to be interesting to watch.
This is an informal formulation of the problem. However, no one was going to give a formal statement.
Attempts to solve
We should not exaggerate the importance of this task for us. In fact, it was never in the plans and no one was even going to do it. I just did not leave hopes that something would come up by itself, and suddenly I will have a good mood and a lot of things that can be put off until later.
Explicit Probabilistic Models
The first idea is to select for each column of the table a family of probability distributions that models it. Then, based on the statistics of the data, select the parameters (model fitting) and use the selected distribution to generate new data. You can use a pseudo-random number generator with a predefined seed to get a reproducible result.
For text fields you can use Markov chains - a clear model for which you can make an effective implementation.
True, some tricks will be required:
- We want to preserve the continuity of the time series - it means that for some data types, it is necessary to model not the value itself, but the difference between the neighboring ones.
- To simulate the conditional cardinality of the columns (for example, that one visitor ID usually has few IP addresses), you will also have to write dependencies between the columns explicitly (for example, to generate an IP address, the hash from the visitor ID is used as a seed, but some other pseudo-random data is added).
- It is not clear how to express the dependence that one visitor frequently visits URL addresses with matching domains approximately at the same time.
All this is presented in the form of a program in which all distributions and dependencies are hard coded — the so-called “C ++ script”. However, Markov models are still calculated from the sum of statistics, smoothing and desensitization using noise. I started writing this script, but for some reason after I wrote the model for ten columns explicitly, it suddenly became unbearably boring. And in the hits table in Yandex.Metrica back in 2012 there were more than 100 columns.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); }; This approach to the problem was a failure. If I approached her more diligently, surely the script would have been written.
Advantages:
- ideological simplicity.
Disadvantages:
- the complexity of the implementation,
- The implemented solution is only suitable for one kind of data.
And I would like a more general solution - so that it can be applied not only for Yandex.Metrica data, but also for obfuscation of any other data.
However, improvements are possible here. You can not manually select the models, but implement the catalog of models and choose the best among them (best fit + some kind of regularization). Or maybe you can use Markov models for all types of fields, and not just for text. The dependencies between the data can also be understood automatically. To do this, calculate the relative entropy (relative amount of information) between the columns, or, more simply, the relative cardinality (something like “how many are on average different values of A for a fixed value B”) for each pair of columns. This will allow you to understand, for example, that URLDomain depends entirely on the URL, and not vice versa.
But I also refused this idea, because there are too many options for what needs to be taken into account, and it will take a long time to write.
Neural networks
I have already told how important this task is for us. No one even thought about making any attempts to implement it. Fortunately, a colleague Ivan Puzyrevsky then worked as a teacher at the HSE and at the same time worked on the development of the YT core. He asked if I had any interesting tasks that could be offered to students as a diploma topic. I offered him this one, and he assured me that it was suitable. So I gave this task to a good person “from the street” - Sharif Anvardinov (the NDA is signed to work with the data).
He told him about all his ideas, but most importantly - explained that the problem can be solved in any way. And it would be a good option to use those approaches that I absolutely do not understand: for example, to generate a text dump of data using LSTM. This looked encouraging thanks to the article The Unreasonable Effectiveness of Recurrent Neural Networks , which then caught my eye.
The first feature of the task is that you need to generate structured data, and not just text. It was not obvious whether the recurrent neural network could generate data with the desired structure. This can be solved in two ways. The first is to use separate models for the generation of the structure and for the “filler”: the neural network should only generate values. But this option was postponed until later, after which they never did. The second way is to simply generate a TSV dump as text. Practice has shown that in the text of the lines will not match the structure, but these lines can be thrown out when loading.
The second feature - the recurrent neural network generates a sequence of data, and the dependencies in the data can follow only in the order of this sequence. But in our data, perhaps, the order of the columns is reversed with respect to the dependencies between them. With this feature, we did not do anything.
Closer to the summer, the first working Python script appeared that generated the data. At first glance, the quality of the data is decent:
The truth revealed difficulties:
- The size of the model is about a gigabyte. And we tried to create a model for data whose size was of the order of several gigabytes (for a start). The fact that the resulting model is so large causes concern: what if it will be possible to get real data from which it has been trained. Most likely no. But I don’t understand machine learning and neural networks. I didn’t read the Python code from this person, so how can I be sure? Then there were articles about how to compress neural networks without loss of quality, but this was left without implementation. On the one hand, this does not look like a problem - you can refuse to publish the model and publish only the generated data. On the other hand, in the case of retraining, the generated data may contain some part of the original data.
- On one machine with a CPU, the data generation rate is approximately 100 lines per second. We had a task - to generate at least a billion lines. The calculation showed that this could not be done before the diploma defense. And to use another iron is inexpedient, because I had a goal - to make the data generation tool available for wide use.
Sharif tried to study the quality of the data by comparing statistics. For example, I calculated the frequency with which different characters are encountered in the source and in the generated data. The result was stunning - the most frequent symbols are Ð and Ñ.
Do not worry - he defended his diploma perfectly well, after which we safely forgot about this work.
Compressed Data Mutation
Suppose that the statement of the problem has decreased to one point: you need to generate data for which the compression ratios will be exactly the same as for the original data, and the data should be decompressed with exactly the same speed. How to do it? You need to edit the bytes of the compressed data directly! Then the size of the compressed data will not change, but the data itself will change. Yes, and everything will work quickly. When this idea appeared, I immediately wanted to implement it, despite the fact that it solves some other task instead of the original one. It always happens.
How to edit a compressed file directly? Suppose we are only interested in LZ4. Compressed using LZ4 data consists of commands of two types:
- Literal (literals): copy the following N bytes as is.
- Match (match, minimum repetition length is 4): repeat N bytes that were in the file at a distance M.
Initial data:
Hello world Hello .Compressed data (conditionally):
literals 12 "Hello world " match 5 12 .In the compressed file, we leave match as it is, and in the literals we will change the values of bytes. As a result, after releasing, we get a file in which all repeating sequences of length not less than 4 are also repeated, and they are repeated at the same distances, but at the same time consist of another set of bytes (figuratively speaking, in the modified file not a single byte was taken ).
But how to change bytes? This is not obvious, because in addition to column types, the data also has its own internal, implicit structure that we would like to preserve. For example, text is often stored in UTF-8 encoding - and we want valid UTF-8 in the generated data too. I made a simple heuristic to satisfy several conditions:
- the null bytes and the ASCII control characters were kept as is,
- some punctuation preserved
- ASCII was translated to ASCII, and for the rest, the most significant bit was preserved (or you can explicitly write an if set for different UTF-8 lengths). Among one class of bytes, a new value is chosen uniformly at random;
- and also to keep
https://fragments and similar ones, otherwise everything looks too stupid.
The peculiarity of this approach is that the source data itself serves as a model for the data, which means that the model cannot be published. It allows you to generate the amount of data not more than the original. For comparison, in previous approaches it was possible to create a model and generate an unlimited amount of data on its basis.
Example for URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
I was pleased with the result - it was interesting to watch the data. But still something was wrong. The structure of the URLs was preserved, but in some places it was too easy to guess yandex or avito. Made heuristics, which sometimes rearranges some bytes in places.
Worried and other considerations. For example, sensitive information can be represented in a column of the type FixedString in binary form and for some reason consist of ASCII control characters and punctuation, which I decided to keep. And I do not consider data types.
Another problem: if data of the “length, value” type is stored in one column (this is how String type columns are stored), then how to ensure that the length remains correct after the mutation? When I tried to fix it, the task immediately became uninteresting.
Random permutations
But the problem is not solved. We conducted several experiments, and it only got worse. It remains only to do nothing and read random pages on the Internet, because the mood is already spoiled. Fortunately, on one of these pages was an analysis of the algorithm for rendering the scene of the death of the main character in the game Wolfenstein 3D.
Beautiful animation - the screen is filled with blood. The article explains that this is actually a pseudo-random permutation. A random permutation is a randomly chosen one-to-one transformation of a set. That is, the display of the entire set, in which the results for different arguments are not repeated. In other words, it is a way to iterate over all the elements of a set in a random order. It is this process that is shown in the picture - we paint over each pixel, selected in random order from all, without repetitions. If we simply chose a random pixel at each step, it would take us a long time to fill in the last one.
The game uses a very simple algorithm for a pseudo-random permutation - LFSR (linear feedback shift register). Like pseudo-random number generators, random permutations, or rather their key parametrized families, can be cryptographically resistant — we just need this for data conversion. Although there may be unclear details. For example, cryptographically strong encryption of N bytes to N bytes with a pre-fixed key and initialization vector, it would seem, can be used as a pseudo-random permutation of a set of N-byte strings. Indeed, such a transformation is one-to-one and looks random. But if we use the same transformation for all our data, the result may be subject to analysis, because the same value is the initialization vector and the key is used several times. This is similar to the Electronic Codebook mode of block cipher operation.
What are some ways to get a pseudo-random permutation? You can take simple one-to-one transformations and assemble from them a fairly complex function that will look random. I will give as an example some of my favorite one-to-one transformations:
- multiplication by an odd number (for example, a large prime number) in two's complement arithmetic,
- xor-shift:
x ^= x >> N, - CRC-N, where N is the number of bits of the argument.
For example, from three multiplications and two xor-shift operations, the murmurhash finalizer is compiled . This operation is a pseudo-random permutation. But just in case, I note that hash functions, even N bits to N bits, are not required to be one-to-one.
Or another interesting example from elementary number theory from the site of Jeff Preshing.
How can pseudo-random permutations be used for our task? With their help, you can convert all numeric fields. Then it will be possible to preserve all the cardinality and mutual cardinality of all combinations of fields. That is, COUNT (DISTINCT) will return the same value as before the conversion, moreover with any GROUP BY.
It is worth noting that the preservation of all cardinality is a bit contrary to the formulation of the problem of anonymizing data. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , , .
, . , 10, . How to achieve this?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . And so on. .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c Hackers News , . Redis — . , .
. — , . , .
- :
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - . xor :
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
, F 4 , .
: , , — , , !
. , , , . :
- , , Electronic Codebook mode of operation;
- ( ) , , .
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
P( | ) = 0.9
P( | ) = 0.05
P( | ) = 0.01
.... ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
— . — , . , , — .@Mail.Ru — — - . ) — AUTO.ria.ua
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
https://www.yandex.ru/images/cats/?id=xxxxxx . , URL, , . : http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . - , 8 .https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ..., . :
- | . - - — .: Lore - dfghf — . - ) 473682 - - ! » - — - ! » , - . c @Mail.Ru - - , 2010 | . - ! : 820 0000 ., - - - DoramaTv.ru - . - .. - . 2013 , -> 80 . - - (. , , - . 5, 69, W* - ., , World of Tanks - , . 2 @Mail.Ru - , .
Result
, - , - . , . clickhouse-obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
clickhouse-obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse-obfuscator --help
, . , ? , , . , , . , (
--help ) ., .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xz
clickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xz
ClickHouse. , ClickHouse .
Source: https://habr.com/ru/post/457354/
All Articles