The neural network learned how to draw complex scenes by textual description.
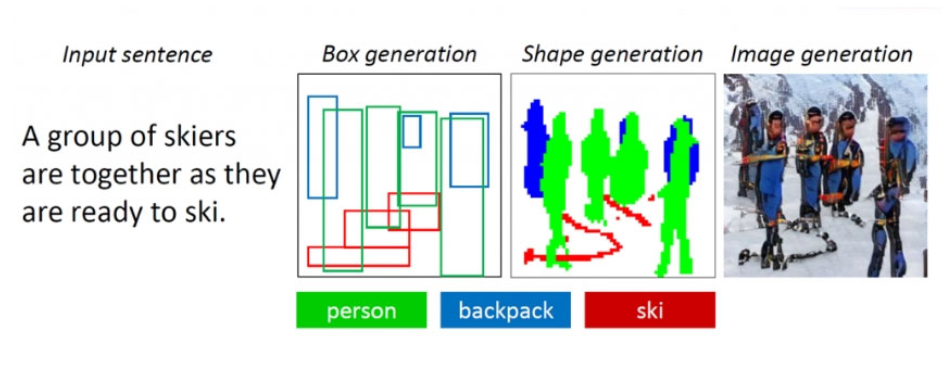
The research group Microsoft Research presented a generative-adversary neural network that is able to generate images with several objects based on a textual description. Unlike earlier similar text-to-image algorithms, capable of reproducing images of only basic objects, this neural network can cope with complex descriptions more qualitatively.
The difficulty of creating such an algorithm was that, first, the bot was previously unable to recreate all the basic objects in good quality from their descriptions, and, second, could not analyze how several objects can relate to each other in within the same composition. For example, to create an image according to the description “A woman in a helmet is sitting on a horse,” the neural network had to semantically “understand” how each of the objects relates to each other. These problems were solved by training the neural network based on the open COCO data set containing markup and segmentation data for more than 1.5 million objects.

The algorithm is based on the object-oriented generative-adversary neural network ObjGAN (Object-driven Attentive Generative Adversarial Newtorks). It analyzes the text, extracting from it words-objects that need to be placed on the image. Unlike a regular generative-adversarial network consisting of one generator, which creates images, and one discriminator, which assesses the quality of the generated images, ObjGAN contains two different discriminators. One analyzes how realistic each of the reproduced objects is and how it corresponds to the existing description. The second determines how realistic the entire composition is and is related to the text.
The predecessor of the ObjGAN algorithm was AttnGAN, also developed by Microsoft researchers. He is able to generate images of objects for more simple text descriptions. The text-to-image technology can be used to help designers and artists create sketches.
The ObjGAN algorithm is publicly available on GitHub.
More technical details.
')
Source: https://habr.com/ru/post/457198/
All Articles