How to set up a web analytics infrastructure for $ 100 per month
Sooner or later, almost any company faces the challenge of developing web analytics. This does not mean that you only need to put the Google Analytics code on the site - you need to find the benefit in the data obtained. In this post I will tell you how to do this as efficiently as possible, spending a little (by the standards of specialized services) money.

My name is Andrey Kolesnichenko, I am the head of the web analytics department at the fintech company ID Finance. In the company, we constantly monitor many indicators; first of all, conversions at different steps are important for us. At the beginning, all reporting was by Google Analytics only. In order to calculate the conversion, we have segmented users and found the share of each segment.
Then we went to the reports in Google Docs. We wrote about it earlier on Habré .
Now we are at the next stage - all reports are based on raw data.
For any analyst, it is they who are important: working with aggregated Google Analytics reports, it is not possible to deeply understand the user's behavior, which greatly affects the quality of analytics.
To obtain such data, you can pay Google Analytics Premium, which costs several million rubles a year. In this case, we get the raw data in BigQuery. There are also various services that duplicate Google Analytics data and store it in BigQuery. But you can do it yourself and less costly way. Let's start.
')
You already have a website and a customized Google Analytics. Now we need to make small changes to start collecting raw data. The basic idea is to send the Google Client ID and then upload the data in these sections.
First, we need to create three new custom dimension in the Google Analytics interface.
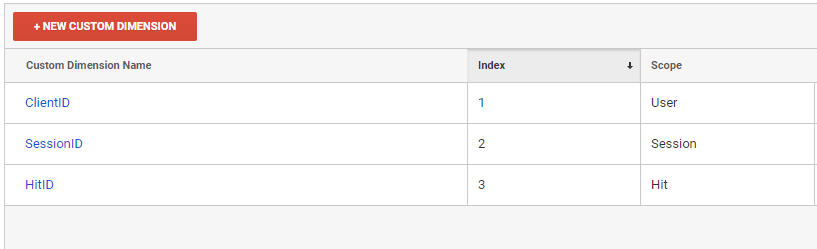
It is in the context of these custom dimensions that we will download reports from Google Analytics.
Then we have to add these variables to all hits sent to Google Analytics.
When sending each hit, dimension2 and dimension3 must be regenerated. Dimension3 is a hit identifier, so it must be unique. If you are using GTM, then the principle of adding a custom dimension is the same.
Our ClientID is configured at the User level, so using it we can uniquely identify a person. SessionID is configured at the Session level, according to which we will be able to determine the user's session. You may notice that we send different SessionIDs each time, but Google will only have one last value. This value will determine the session.
After setting up the front-end, we need to set up the unloading of raw data.
The data flow looks like this:
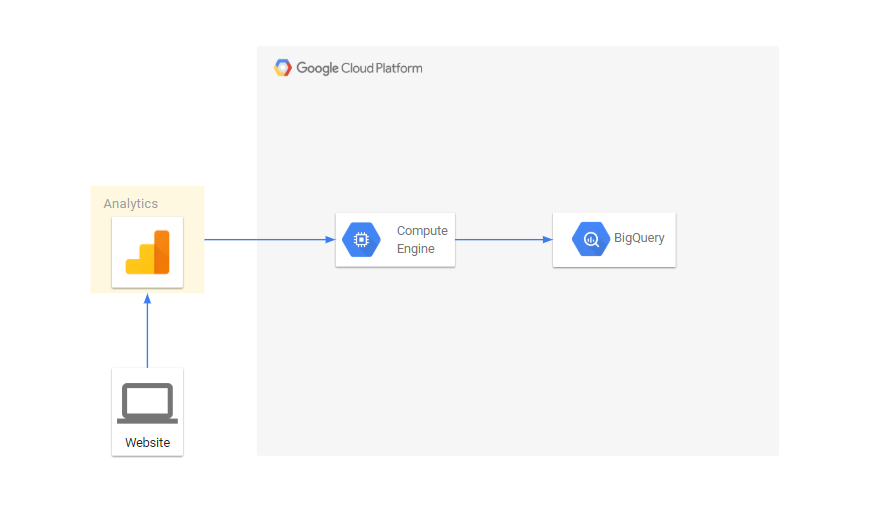
Google Analytics has an API that allows you to download reports. We will download reports in the context of our parameters. All scripts are written in python, tell you about the main things:
The script downloads API data and writes to the file for the date date. View_id - view number in google analytics:
In order to get all the hits, download the data in the section dimension2, dimension3:
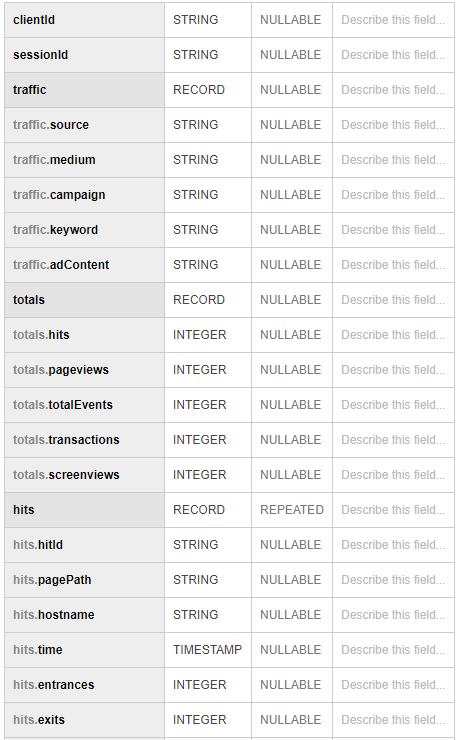
At the end, we merge all the data between each other by a sql query. It turns out something similar to:
We set up raw data collection in BigQuery, we just need to prepare reports for our conversions. They are made by simple sql queries. For reporting, we use Tableau and Google Data Studio.
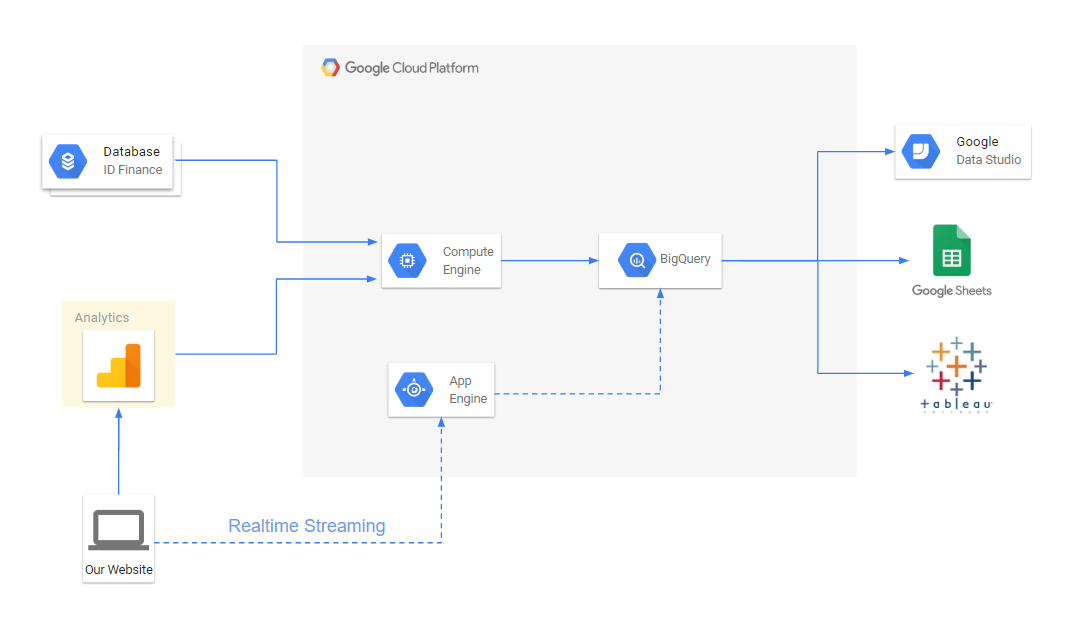
In addition, we have the opportunity to enrich data from google analytics with data from an internal database containing information about applications, issuances, delinquencies, payments, etc.
In addition, Google Cloud allows you to simply set up realtime data streaming, if necessary.
The full flow chart for analytical reporting now looks like this:
As a result, we managed:
My name is Andrey Kolesnichenko, I am the head of the web analytics department at the fintech company ID Finance. In the company, we constantly monitor many indicators; first of all, conversions at different steps are important for us. At the beginning, all reporting was by Google Analytics only. In order to calculate the conversion, we have segmented users and found the share of each segment.
Then we went to the reports in Google Docs. We wrote about it earlier on Habré .
Now we are at the next stage - all reports are based on raw data.
For any analyst, it is they who are important: working with aggregated Google Analytics reports, it is not possible to deeply understand the user's behavior, which greatly affects the quality of analytics.
To obtain such data, you can pay Google Analytics Premium, which costs several million rubles a year. In this case, we get the raw data in BigQuery. There are also various services that duplicate Google Analytics data and store it in BigQuery. But you can do it yourself and less costly way. Let's start.
')
Prepare Front-End
You already have a website and a customized Google Analytics. Now we need to make small changes to start collecting raw data. The basic idea is to send the Google Client ID and then upload the data in these sections.
First, we need to create three new custom dimension in the Google Analytics interface.
It is in the context of these custom dimensions that we will download reports from Google Analytics.
- ClientID - user ID
- SessionID - session identifier
- HitID - hit identifier
Then we have to add these variables to all hits sent to Google Analytics.
ga(function (tracker) { var clientId = tracker.get('clientId'); var timestamp = new Date().getTime(); ga('set', 'dimension1', clientId); ga('set', 'dimension2', clientId + '_' + timestamp); ga('set', 'dimension3', clientId + '_' + timestamp); }); When sending each hit, dimension2 and dimension3 must be regenerated. Dimension3 is a hit identifier, so it must be unique. If you are using GTM, then the principle of adding a custom dimension is the same.
Our ClientID is configured at the User level, so using it we can uniquely identify a person. SessionID is configured at the Session level, according to which we will be able to determine the user's session. You may notice that we send different SessionIDs each time, but Google will only have one last value. This value will determine the session.
Infrastructure
After setting up the front-end, we need to set up the unloading of raw data.
- We will upload data to Google BigQuery. To do this, we will need to create a project in the Google Cloud Platform . Even if you are not going to use BigQuery, you still need to create a project to download data by API. Those who will use the services of Google Cloud, waiting for a nice bonus of $ 300 when binding a card. For analytics needs a small project will last for at least six months free use.
- On the console.cloud.google.com/iam-admin/serviceaccounts page, you need to create a service key with which we will use the Google Analytics API and Google BigQuery.
- Then you need to give this email access to reading Google Analytics.
- Go to console.cloud.google.com/apis/library/analytics.googleapis.com and enable the Google Analytics API
- Since we will download the data every day, we need a server to perform our tasks. For this we will use the Google Compute Engine
The data flow looks like this:
Data export via Google Analytics API
Google Analytics has an API that allows you to download reports. We will download reports in the context of our parameters. All scripts are written in python, tell you about the main things:
Export data from Google Analytics to file
from apiclient.discovery import build import os import unicodecsv as csv from googleapiclient.errors import HttpError import time SCOPES = ['https://www.googleapis.com/auth/analytics.readonly'] KEY_FILE_LOCATION = 'my_key_file.p12' SERVICE_ACCOUNT_EMAIL = 'service_account_email@my-google-cloud-project.iam.gserviceaccount.com' class ApiGA(): def __init__(self, scopes=SCOPES, key_file_location=KEY_FILE_LOCATION, service_account_email=SERVICE_ACCOUNT_EMAIL, version='v4'): credentials = ServiceAccountCredentials.from_p12_keyfile( service_account_email, key_file_location, scopes=scopes) self.handler = build('analytics', version, credentials=credentials) def downloadReport(self, view_id, dim_list, metrics_list, date, page, end_date=None, filters=None): if not end_date: end_date = date body = { 'reportRequests': [ { 'viewId': view_id, 'dateRanges': [{'startDate': date, 'endDate': end_date}], 'dimensions': dim_list, 'metrics': metrics_list, 'includeEmptyRows': True, 'pageSize': 10000, 'samplingLevel': 'LARGE' }]} if page: body['reportRequests'][0]['pageToken'] = page if filters: body['reportRequests'][0]['filtersExpression'] = filters while True: try: return self.handler.reports().batchGet(body=body).execute() except HttpError: time.sleep(0.5) def getData(self, view_id, dimensions, metrics, date, filename='raw_data.csv', end_date=None, write_mode='wb', filters=None): dim_list = map(lambda x: {'name': 'ga:'+x}, dimensions) metrics_list = map(lambda x: {'expression': 'ga:'+x}, metrics) file_data = open(filename, write_mode) writer = csv.writer(file_data) page = None while True: response = self.downloadReport(view_id, dim_list, metrics_list, date, page, end_date=end_date, filters=filters) report = response['reports'][0] rows = report.get('data', {}).get('rows', []) for row in rows: dimensions = row['dimensions'] metrics = row['metrics'][0]['values'] writer.writerow(dimensions+metrics) if 'nextPageToken' in report: page = report['nextPageToken'] else: break file_data.close() The script downloads API data and writes to the file for the date date. View_id - view number in google analytics:
filename = 'raw_data.csv' date = '2019-01-01' view_id = '123123123' ga = ApiGA() dims = ['dimension1', 'dimension2', 'source', 'medium', 'campaign', 'keyword', 'adContent', 'userType'] metrics = ['hits', 'pageviews', 'totalEvents', 'transactions', 'screenviews'] ga.getData(view_id, dims, metrics, date, filename) Then we load the data into BigQuery
from google.cloud import bigquery client = bigquery.Client() schema = [ bigquery.SchemaField('clientId', 'STRING'), bigquery.SchemaField('sessionId', 'STRING'), bigquery.SchemaField('source', 'STRING'), bigquery.SchemaField('medium', 'STRING'), bigquery.SchemaField('campaign', 'STRING'), bigquery.SchemaField('keyword', 'STRING'), bigquery.SchemaField('adContent', 'STRING'), bigquery.SchemaField('userType', 'STRING'), bigquery.SchemaField('hits', 'INTEGER'), bigquery.SchemaField('pageviews', 'INTEGER'), bigquery.SchemaField('totalEvents', 'INTEGER'), bigquery.SchemaField('transactions', 'INTEGER'), bigquery.SchemaField('screenviews', 'INTEGER') ] table_id = 'raw.sessions' table = bigquery.Table(table_id, schema=schema) table = client.create_table(table) dataset_ref = client.dataset(dataset_id) table_ref = dataset_ref.table(table_id) job_config = bigquery.LoadJobConfig() job_config.source_format = bigquery.SourceFormat.CSV job_config.skip_leading_rows = 0 job_config.autodetect = True with open(filename, "rb") as source_file: job = client.load_table_from_file(source_file, table_ref, job_config=job_config) job.result() In order to get all the hits, download the data in the section dimension2, dimension3:
dims = ['dimension2', 'dimension13', 'pagePath', 'hostname', 'dateHourMinute'] metrics = ['hits', 'entrances', 'exits'] …. dims = ['dimension3', 'eventCategory', 'eventAction', 'eventLabel'] metrics = ['eventValue'] …. At the end, we merge all the data between each other by a sql query. It turns out something similar to:
Using
We set up raw data collection in BigQuery, we just need to prepare reports for our conversions. They are made by simple sql queries. For reporting, we use Tableau and Google Data Studio.
In addition, we have the opportunity to enrich data from google analytics with data from an internal database containing information about applications, issuances, delinquencies, payments, etc.
In addition, Google Cloud allows you to simply set up realtime data streaming, if necessary.
The full flow chart for analytical reporting now looks like this:
As a result, we managed:
- Make reporting more flexible and convenient
- Reduce time to resolve conversion issues
- Build a multi-channel attribution for marketing. This allows us to distribute the value of the application not only for the latest source, but also for all other sources that led the user to the site.
- Combine user data in one place
Source: https://habr.com/ru/post/457052/
All Articles