Sheep of Electric Sheep: Designing for Autonomous Operation
Who do you think will better configure PostgreSQL - DBA or ML algorithm? And if the second, then is it time for us to think about what to do when we are replaced by cars. Or it will not come to this, and the person must still make important decisions. Probably, the isolation level and transaction stability requirements should remain in the hands of the administrator. But the indexes will soon be possible to entrust the machine to determine independently.

Andy Pavlo on HighLoad ++ told about the future DBMS, which can be “touched” now. If you missed this speech or prefer to receive information in Russian - under the cut translation of the speech.
')
We will talk about the project of Carnegie Mellon University, dedicated to the creation of autonomous databases. The term "autonomous" means a system that can automatically deploy, configure, configure itself without any human intervention. It may take about ten years to develop something like this, but this is exactly what Andy and his students are doing. Of course, in order to create an autonomous DBMS, machine learning algorithms are necessary, however, in this article we will focus only on the engineering side of the topic. Consider how to design software to make it standalone.
About the speaker: Andy Pavlo is an associate professor at Carnegie Mellon University, under his leadership he creates “self-managed” PelotonDB DBMS , as well as ottertune , which helps to tune PostgreSQL and MySQL configs using machine learning. Andy and his team are now true leaders in self-managed databases.
The reason why we want to create an autonomous database management system is obvious. Data management by means of a DBMS is a very expensive and laborious process. The average DBA salary in the USA is about 89 thousand dollars a year. Translated into rubles, it is 5.9 million rubles a year. You’ll pay this really big amount to people just looking after your software. About 50% of the total cost of using the database is the payment of the work of such administrators and related personnel.
When it comes to really big projects, such as we discuss in HighLoad ++ and which use tens of thousands of databases, the complexity of their structure goes beyond human perception. All approach the solution to this problem superficially and try to achieve maximum performance by investing minimal effort in setting up the system.
The idea of autonomous DBMS is not new, their history dates back to the 1970s, when relational databases were first created. Then they were called self-adaptive databases (Self-Adaptive Databases), and with their help they tried to solve the classic problems of database design, over which people are still struggling. These are the choice of indices, the partitioning and construction of the database schema, as well as the placement of data. At that time, tools were developed that helped database administrators deploy databases. These tools, in fact, worked the same way as their modern counterparts work today.
Administrators track requests executed by the application. They then pass this stack of requests to the tuning algorithm, which builds an internal model of how the application should use the database.
If you create a tool that helps you automatically select indexes, then build charts from which you can see how often calls are made to each column. Then pass this information to the search algorithm, which will look at many different locations - try to determine which of the columns can be indexed in the database. The algorithm will use the internal value model to show that this particular will give better performance than other indices. Then the algorithm will give a suggestion, what changes in the indices need to be made. At this point, it's time to get involved with the person, consider the proposal and, not only decide whether it is right, but also choose the right time to implement it.

Database administrators should know how the application is used when there is a drop in user activity. For example, on Sunday at 3:00 am the lowest level of database queries, so you can reload indexes at this time.
As I said, all the design tools of the time worked the same way - this is a very old problem . The supervisor of my supervisor back in 1976 wrote an article about automatic index selection.
In the 1990s, people, in fact, worked on the same problem, only the name changed from adaptive to self-adjusting databases.
The algorithms have become a little better, the tools have become a little better, but at a high level, they also worked as before. The only company that was at the forefront of the self-tuning systems movement was Microsoft Research with their automatic administration project. They developed really great solutions, and in the late 90s, early 00s, they again presented a set of recommendations for configuring their database.
The key idea that Microsoft put forward was different from what it was in the past — instead of the customization tools supporting their own models, they actually simply reused the query optimizer cost model, which helps determine the benefits of one index against another. If you think about it, it makes sense. When you need to know whether a single index can really speed up queries, it doesn’t matter how big it is if the optimizer doesn’t select it. Therefore, the optimizer is used to find out if it will actually select something.

In 2007, Microsoft Research published an article outlining a retrospective of ten years of research. And it is well covered all the complex tasks that have arisen on each segment of the path.
Another task that was noticed in the era of self-tuning databases: how to make automatic tuning of regulators. The database controller is a configuration parameter that changes the behavior of the database system at run time. For example, the parameter that is present in almost every database is the size of the buffer. Or, for example, you can control parameters such as blocking policies, the frequency of cleaning the disk and the like. Due to the significant increase in the complexity of DBMS regulators in recent years, this topic has become relevant.
To show how bad things are, I’ll give an overview that my student did after examining many releases of PostgreSQL and MySQL.
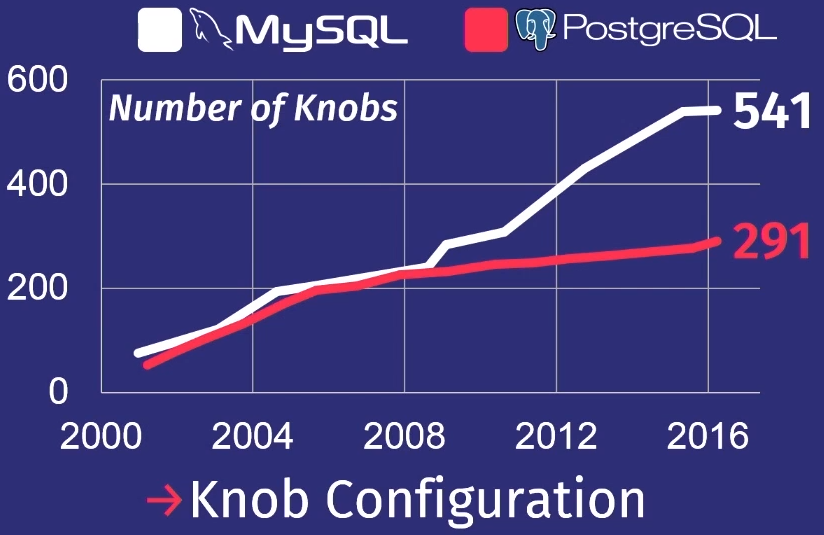
Of course, not all regulators actually control the task execution process. Some, for example, contain file paths or network addresses, so only a person can configure them. But a few dozen of them can actually affect performance. No man can hold that much in his head.
Then we find ourselves in the era of the 2010s, in which we are to this day. I call it the era of cloud databases. During this time, much work has been done to automate the deployment of a large number of databases in the cloud environment.
The main thing that bothers the major suppliers of cloud systems is how to place tenant or migrate from one to another. How to determine how much resources each tenant will need, and then try to distribute them among the cars so as to maximize productivity or meet the SLA at minimum cost.
Amazon, Microsoft and Google solve this problem, but mostly at the operational level. Only recently, cloud service providers began to think about the need to configure individual database systems. This work is not visible to ordinary users, but it determines the high level of the company.
Why today we can not have a truly autonomous system of self-government? There are three reasons for this.

First, all of these tools, except for the distribution of workload from cloud service providers, are only advisory in nature . That is, on the basis of the calculated option, the person must make a final, subjective decision as to whether such a proposal is correct. Moreover, it takes some time to monitor the operation of the system in order to decide whether the decision made remains true as the service develops. And then apply knowledge to your own internal decision making model in the future. You can do this for one DB, but not for tens of thousands.
The next problem is that any measures are only a reaction to something . In all the examples that we have reviewed, work goes with data on past workload. A problem arises, records about it are transmitted to the instrument, and he says: “Yes, I know how to solve this problem.” But the solution concerns only a problem that has already occurred. The tool does not predict future events and therefore does not offer preparatory actions. A person can do it, and does it manually, but tools cannot do this.
The final reason is that in none of the solutions is there a transfer of knowledge . Here is what I mean: for example, let's take a tool that worked in one application on the first database instance, if you put it in one more same application on another database instance, it could, based on the knowledge gained, work with the first database data to help set up a second database. In fact, all tools start from scratch, they need to re-get all the data about what is happening. The man works quite differently. If I know how to set up one application in a certain way, I can see the same patterns in another application and maybe set it up much faster. But none of these algorithms, none of these tools, still work in this way.
Why am I sure it is time for a change? The answer to this question is about the same as the question of why super data arrays or machine learning became popular. Equipment becomes better : production resources increase, storage capacity grows, hardware capacity increases, which speeds up calculations for learning machine learning models.
We have become available advanced software. Previously, you had to be an expert on MATLAB or low-level linear algebra to write some machine learning algorithms. Now we have Torch and Tenso Flow, which make ML available, and, of course, we have learned to better understand the data. People know exactly what data may be needed to make decisions in the future, so do not discard as much data as before.
The goal of our research is to close this circle in autonomous DBMS. We can, like the previous tools, propose solutions, but instead of relying on the person — whether the solution is right, when exactly you need to deploy it — the algorithm will do it automatically. And then with the help of feedback will learn and eventually get better.
I want to talk about the projects we are currently working at Carnegie Mellon University. In them we approach the problem in two different ways.
In the first — OtterTune — we look for ways to customize the database, treating them like black boxes. That is, ways to customize existing DBMSs , without controlling the internal part of the system, and observing only the response.
The Peloton project is about creating new databases from scratch , from scratch, given that the system should work autonomously. What adjustments and optimization algorithms need to be laid - which cannot be applied to existing systems.
Consider both projects in order.
The project for adjusting existing systems that we developed is called OtterTune.
Imagine that a database is configured as a service. The idea is that you load the time metrics for performing heavy DB operations that consume all the resources, and the recommended configuration of regulators comes in response, which, in our opinion, will increase performance. This can be delay time, bandwidth or any other characteristic that you specify - we will try to find the best option.

The main thing that is new in the OtterTune project is the ability to use data from previous sessions to customize and increase the efficiency of the next sessions. For example, we take the PostgreSQL configuration, in which there is an application that we have never seen before. But if it has certain characteristics or uses a database like the databases that we have already seen in our applications, then we already know how to configure it and this application is more efficient.
At a higher level, the algorithm works as follows.
Suppose there is a target database: PostgreSQL, MySQL, or VectorWise. You need to install a controller in the same domain that will perform two tasks.
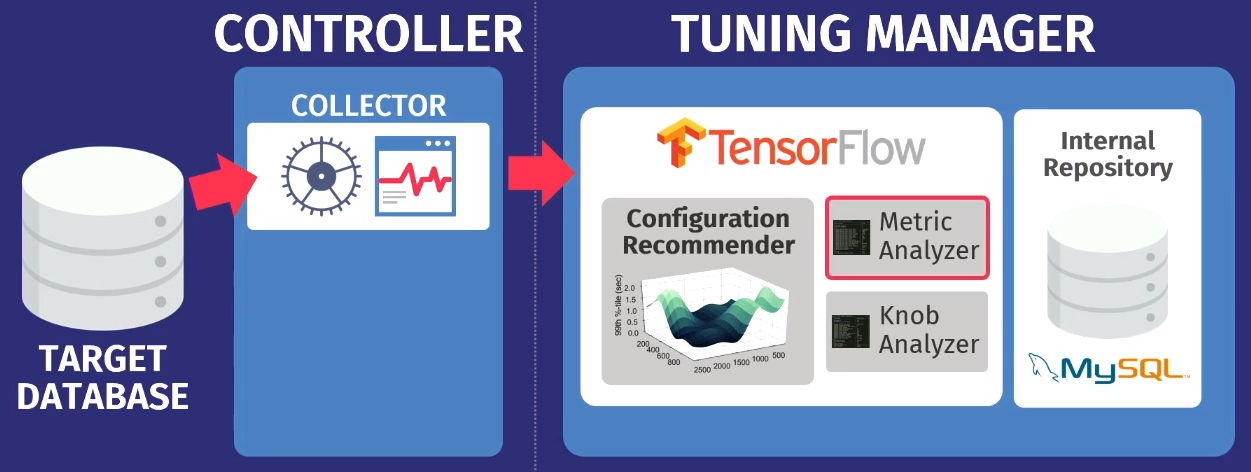
The first is performed by the so-called collector - a tool that collects data about the current configuration, i.e. metrics of query execution time from applications to the database. The data collected by the collector, loaded into the Tuning Manager - service settings. It does not matter if the database is running locally or in the cloud. After downloading, the data is saved in our own internal repository, which stores all test sessions we have ever made.
Before making recommendations, you need to perform two steps. First, you need to look at the runtime metrics and find out which of them are really important. In the example below, the metrics returned by MySQL but on the
For example, there are two metrics:
At the second stage we do the same, only with regards to the regulators. MySQL has 500 regulators , and, of course, not all of them are really significant, and different applications are important for different applications. It is necessary to carry out another statistical analysis to find out which regulators will really affect the objective function.
In our example, we found that the three regulators
There are other interesting points related to regulators. In the screenshot there is a controller named
After analysis, the data is transferred to our configuration algorithm using the Gaussian process model — a rather old method. You have probably heard about deep learning, we are doing something similar, but without deep networks. We use the GPflow - package for working with models of the Gaussian process, developed in Russia on the basis of TensorFlow. The algorithm issues a recommendation that should improve the objective function; This data is passed back to the installation agent running inside the controller. The agent applies the changes, performing a reset — unfortunately, it’s necessary to restart the database — and then the process repeats again. Some more metrics of execution time are collected, transferred to the algorithm, an analysis is made of the possibility of improving and increasing productivity, a recommendation is issued, and so on, again and again.
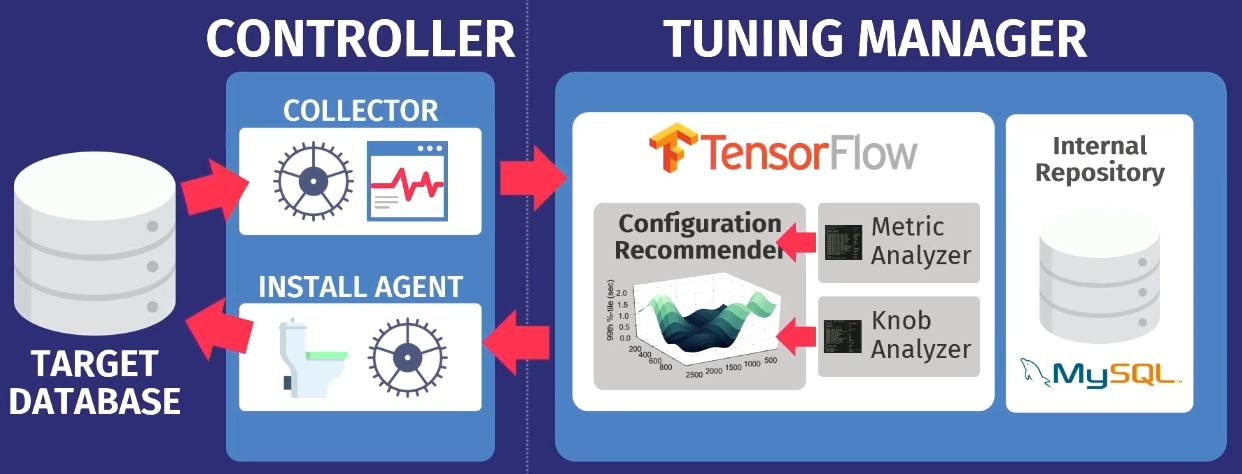
The key feature of OtterTune is that as input to the algorithms, only information about the execution time metrics is needed. We do not need to see your data and user requests. We just need to track read and write operations. This is a weighty argument - data belonging to you or your customers will not be disclosed to third parties. We do not need to see any requests, the algorithm works based only on the runtime metrics, because it gives recommendations for regulators, and not for physical design.
Let's take a look at the work of the OtterTune demo. On the project website, we will launch Postgres 9.6, and load the system with a TPC-C test. Let's start with the initial PostgreSQL configuration, which is deployed when installed on Ubuntu.

First, we will run the TPC-C test for five minutes, collect the required runtime metrics, load them into the OtterTune service, get recommendations, apply the changes, and then repeat the process. Let's come back to this later. The database system runs on one computer, the Tensor Flow service runs on another, and loads the data here.
After five minutes, refresh the page (the demonstration of this part of the results begins at this moment ). When we first started, in the default configuration for PostgreSQL, 623 transactions occurred per second. Then, after receiving the recommendation and applying the changes once, the number of transactions increased to 2300 per second . We have to admit that this demonstration has already been launched several times, so the system already has a set of previously collected data. That is why the solution is so fast. What would happen if the system did not have such previously collected data? This algorithm is a kind of step-by-step function, and gradually it would have reached that level.

After some time and five iterations, the best result was 2600. We went from 600 transactions per second, and were able to reach values of 2600. A small drop occurred due to the algorithm decided to try a different way of adjusting the regulators after reaching good results. The result was with a margin, so a large drop in performance did not happen. Having received a negative result, the algorithm reconfigured and began to look for other methods of regulation.
We conclude that we should not be afraid of launching a bad strategy into the work, because the algorithm will explore the solution space and try on different configurations to achieve the terms of the SLA agreement. Although you can always customize the service so that the algorithm chooses only enhancement solutions. And over time you will get all the best and best results.
Now back to the topic of our conversation. I will tell you about the results already available from an article published in Sigmod. We configured MySQL and PostgreSQL for TPC-C using OtterTune, in order to increase throughput.
Compare the configuration of these DBMS, deployed by default when first installed on Ubuntu. Next, let's run several open source configuration scripts that can be obtained from Percona and some other consulting firms working with PostgreSQL. These scripts use heuristic procedures, like the rule that for your hardware you must set a certain buffer size. We also have a configuration from Amazon RDS, which already has presets from Amazon for the equipment you work on. Then we compare this with the result of manual configuration of expensive DBA, but with the condition that they have 20 minutes and the ability to set any parameters. And the last step is to run OtterTune.
For MySQL, it is clear that the default configuration is far behind, the scripts work a little better, RDS is a little better. In this case, the best result was shown by the database administrator - the leading MySQL administrator from Facebook.
OtterTune lost to man . But the fact is that there is a certain regulator that disables the synchronization of magazine cleaning, and for Facebook it doesn’t matter. However, we denied access to this OtterTune regulator, because the algorithms do not know whether you agree to lose the last five milliseconds of data. In our opinion, this decision should be made by a person. Perhaps Facebook agrees with such losses, we do not know. If we set up this regulator in the same way, then we can compete with the person.
In the case of PostgreSQL, configuration scripts work well. RDS does a little worse. But, it is worth noting that OtterTune's performance has exceeded this person. The histogram shows the results obtained after the database was set up by the chief expert on PostgreSQL in the Wisconsin judicial system. In this example, OtterTune was able to find the optimal balance between the size of the log file and the size of the buffer pool, balancing the amount of memory used by these two components and ensuring the best performance.
The main conclusion is that OtterTune uses such algorithms and machine learning that we can achieve the same or better performance compared to very, very expensive DBA. And this concerns not only a single instance of the database, we can scale up to tens of thousands of copies, because it’s just software, just data.
The second project that I would like to talk about is called Peloton. This is a completely new data system that we are building from scratch at Carnegie Mellon. We call it a self-managed DBMS.
The idea is to find out which changes for the better can be made if you control the entire software stack. How to make the settings better than OtterTune can do, at the expense of knowing about each fragment of the system, about the entire program cycle.

How it will work: we have integrated the components of machine learning with reinforcement into the database system, and we can observe all aspects of its behavior during execution and then make recommendations. And we are not limited to recommendations for setting up regulators, as it happens in the OtterTune service, we would like to perform the entire standard set of actions that I mentioned earlier: the choice of indices, the choice of partitioning schemes, the vertical and horizontal scaling, etc.
The name of the Peloton system is likely to change. I do not know how in Russia, but here in the USA, the term “ peloton” means “fearless” and “finish”, and in French it means “platoon”. But in the US, there is the Peloton exercise bike company , which has a lot of money. Every time there is a mention of them, for example, opening a new store, or a new advertisement on TV, all my friends write to me: "Look, they stole your idea, stole your name." Advertising shows beautiful people who ride their exercise bikes, and we simply cannot compete with it. And recently, Uber announced a new resource planner called “ Peloton”, so we can no longer call our system that way. But we don’t have a new name yet, so in this story I’ll still use the current version of the name.
Consider how this system works at a high level. For example, take the target database, again, this is our software, this is what we work with. We are collecting the same workload history that I showed earlier. The difference is that we are going to generate prediction models that will allow us to predict what the workload cycles will be in the future, what the requirements of the workload will be in the future. That is why we call this system a self-managing DBMS.
An unmanned vehicle looks in front of itself and can see what is located in front of it on the road, can predict how to get to its destination. The autonomous database system works in the same way. You should be able to look to the future and conclude what the workload will look like in a week or an hour. Then we transfer this predicted data to the planning component — we call it the brain — working on Tensor Flow.
The process echoes the work of AlphaGo from London within the framework of the Google Deep Mind project, at the top level it all works according to a similar scenario: a Monte Carlo tree search is used, the search results are various actions that need to be performed to achieve the desired goal.
The work scheme is approximately determined by the following algorithm:

You should not constantly resort to the metaphor of an unmanned vehicle, but this is how they work. This is called the planning horizon.
Looking at the horizon on the road, we set an imaginary point to which we need to get, and then we begin to plan the sequence of actions to reach this point on the horizon: speed up, slow down, turn left, turn right, etc. Then we mentally discard all the actions except the first one that need to be performed, perform it, and then repeat the process again. UAVs chase such an algorithm 30 times a second. With regard to databases, this process proceeds a little slower, but the idea itself remains the same.
We decided to create our own database system from scratch, rather than build something on top of PostgreSQL or MySQL , because, frankly, they are too slow compared to what we would like to do. PostgreSQL is great, I love it and use it in my university courses, but it takes too much time to create indexes, because all the data comes from the disks.
In analogies with cars, an autonomous DBMS on PostgreSQL can be compared to an unmanned truck. The wagon will be able to recognize the dog in front of the road and drive around it, but not if it ran out onto the roadway right in front of the car. Then the collision is inevitable, because the wagon is not sufficiently maneuverable. We decided to create a system from scratch in order to be able to apply changes as quickly as possible and figure out what the correct configuration is.
Now we have solved the first problem and published an article about a combination of deep learning and classical linear regression for automatic selection and prediction of workloads.
But there is a bigger problem for which we do not have a good solution yet - action catalogs . The question is not how to choose actions, because the guys from Microsoft have already done it. The question is how to determine whether one action is better than another, in terms of what happens before and after deployment. How to reverse the action, if the index created by the command of a person is not optimal, how can you cancel this action and specify the reason for the cancellation. In addition, there are a number of other tasks in terms of the interaction of our own system with the outside world, for which we do not have a solution yet, but we are working on them.
By the way, I will tell an interesting story about a well-known database company. This company had an automatic index selection tool, and the tool had a problem. One customer constantly canceled all indices that the tool recommended and applied. This cancellation occurred so often that the tool hung. He did not know what the future strategy of behavior should be, because any solution offered to a person received a negative evaluation. When the developers turned to the client and asked: “Why do you cancel all recommendations and suggestions on indexes?”, The client answered that he simply did not like their names. People are stupid, but you have to deal with them. And for this problem, I still have no solution.
Considering two different approaches to creating autonomous database systems, now let's talk about how to design a DBMS so that it is autonomous.
Let us dwell on three topics:
Let's return to the key points once again: the database system should provide the correct information to the machine learning algorithms for later making the best decisions. The amount of useless data that we transmit must be reduced to increase the speed of receiving responses.
, , , .
, , , , .
, , , .
:
, . , 10 , , 10 . , .
- , . , , . , , , .
, , , . , . , , , — . , .
, , , . , .
, , . , : , , , , . - Oracle, , .

, , .
, , . , , , . - , , , . : PostgreSQL , .

, , , .
- , , , . , , . RocksDB, MyRocks MySQL.
RocksDB . , . , , , . RocksDB, .

, , , , . MyRocks . — :

, , open source. , .
, , . MySQL , . , . 5 , 10 , , . 5 , — .
, . — PostgreSQL .
— . , . , , , , .
. , — SLA. , .
, . , . , . , .

, - , . , , - , . , , , — , -, , .
, , , .
, . , , , , 5- . downtime, .
, , , , , . , , , , .
Oracle . 2017 Oracle , . , Oracle, , « , Oracle 20 ».

. , , , , , . CIDR , . , : «, , , . , , , Oracle ?» , — .
, , , Oracle. , .
, — , , , - .
— , . , , , 2000- . , Oracle , . , : , — - .
, . , , .
— . , . : JOIN. . . , . .
Oracle. Microsoft 2017 SQL Server, . IBM DB2 00- , «LEO» — . , 1970-, Ingres. , JOIN, , . .
, , . , , . , , .
, , — , , , . , , , . , , .., .
Andy Pavlo on HighLoad ++ told about the future DBMS, which can be “touched” now. If you missed this speech or prefer to receive information in Russian - under the cut translation of the speech.
')
We will talk about the project of Carnegie Mellon University, dedicated to the creation of autonomous databases. The term "autonomous" means a system that can automatically deploy, configure, configure itself without any human intervention. It may take about ten years to develop something like this, but this is exactly what Andy and his students are doing. Of course, in order to create an autonomous DBMS, machine learning algorithms are necessary, however, in this article we will focus only on the engineering side of the topic. Consider how to design software to make it standalone.
About the speaker: Andy Pavlo is an associate professor at Carnegie Mellon University, under his leadership he creates “self-managed” PelotonDB DBMS , as well as ottertune , which helps to tune PostgreSQL and MySQL configs using machine learning. Andy and his team are now true leaders in self-managed databases.
The reason why we want to create an autonomous database management system is obvious. Data management by means of a DBMS is a very expensive and laborious process. The average DBA salary in the USA is about 89 thousand dollars a year. Translated into rubles, it is 5.9 million rubles a year. You’ll pay this really big amount to people just looking after your software. About 50% of the total cost of using the database is the payment of the work of such administrators and related personnel.
When it comes to really big projects, such as we discuss in HighLoad ++ and which use tens of thousands of databases, the complexity of their structure goes beyond human perception. All approach the solution to this problem superficially and try to achieve maximum performance by investing minimal effort in setting up the system.
You can save a lot of money if you configure the database at the application and environment level to ensure maximum performance.
Self-adaptive databases, 1970–1990
The idea of autonomous DBMS is not new, their history dates back to the 1970s, when relational databases were first created. Then they were called self-adaptive databases (Self-Adaptive Databases), and with their help they tried to solve the classic problems of database design, over which people are still struggling. These are the choice of indices, the partitioning and construction of the database schema, as well as the placement of data. At that time, tools were developed that helped database administrators deploy databases. These tools, in fact, worked the same way as their modern counterparts work today.
Administrators track requests executed by the application. They then pass this stack of requests to the tuning algorithm, which builds an internal model of how the application should use the database.
If you create a tool that helps you automatically select indexes, then build charts from which you can see how often calls are made to each column. Then pass this information to the search algorithm, which will look at many different locations - try to determine which of the columns can be indexed in the database. The algorithm will use the internal value model to show that this particular will give better performance than other indices. Then the algorithm will give a suggestion, what changes in the indices need to be made. At this point, it's time to get involved with the person, consider the proposal and, not only decide whether it is right, but also choose the right time to implement it.
Database administrators should know how the application is used when there is a drop in user activity. For example, on Sunday at 3:00 am the lowest level of database queries, so you can reload indexes at this time.
As I said, all the design tools of the time worked the same way - this is a very old problem . The supervisor of my supervisor back in 1976 wrote an article about automatic index selection.
Self-tuning databases, 1990–2000
In the 1990s, people, in fact, worked on the same problem, only the name changed from adaptive to self-adjusting databases.
The algorithms have become a little better, the tools have become a little better, but at a high level, they also worked as before. The only company that was at the forefront of the self-tuning systems movement was Microsoft Research with their automatic administration project. They developed really great solutions, and in the late 90s, early 00s, they again presented a set of recommendations for configuring their database.
The key idea that Microsoft put forward was different from what it was in the past — instead of the customization tools supporting their own models, they actually simply reused the query optimizer cost model, which helps determine the benefits of one index against another. If you think about it, it makes sense. When you need to know whether a single index can really speed up queries, it doesn’t matter how big it is if the optimizer doesn’t select it. Therefore, the optimizer is used to find out if it will actually select something.
In 2007, Microsoft Research published an article outlining a retrospective of ten years of research. And it is well covered all the complex tasks that have arisen on each segment of the path.
Another task that was noticed in the era of self-tuning databases: how to make automatic tuning of regulators. The database controller is a configuration parameter that changes the behavior of the database system at run time. For example, the parameter that is present in almost every database is the size of the buffer. Or, for example, you can control parameters such as blocking policies, the frequency of cleaning the disk and the like. Due to the significant increase in the complexity of DBMS regulators in recent years, this topic has become relevant.
To show how bad things are, I’ll give an overview that my student did after examining many releases of PostgreSQL and MySQL.
Over the past 15 years, the number of regulators in PostgreSQL has increased 5 times, and in MySQL - 7 times.
Of course, not all regulators actually control the task execution process. Some, for example, contain file paths or network addresses, so only a person can configure them. But a few dozen of them can actually affect performance. No man can hold that much in his head.
Cloud Databases, 2010–…
Then we find ourselves in the era of the 2010s, in which we are to this day. I call it the era of cloud databases. During this time, much work has been done to automate the deployment of a large number of databases in the cloud environment.
The main thing that bothers the major suppliers of cloud systems is how to place tenant or migrate from one to another. How to determine how much resources each tenant will need, and then try to distribute them among the cars so as to maximize productivity or meet the SLA at minimum cost.
Amazon, Microsoft and Google solve this problem, but mostly at the operational level. Only recently, cloud service providers began to think about the need to configure individual database systems. This work is not visible to ordinary users, but it determines the high level of the company.
Summing up the 40-year database research with autonomous and non-autonomous systems, it can be concluded that this work is still not enough.
Why today we can not have a truly autonomous system of self-government? There are three reasons for this.
First, all of these tools, except for the distribution of workload from cloud service providers, are only advisory in nature . That is, on the basis of the calculated option, the person must make a final, subjective decision as to whether such a proposal is correct. Moreover, it takes some time to monitor the operation of the system in order to decide whether the decision made remains true as the service develops. And then apply knowledge to your own internal decision making model in the future. You can do this for one DB, but not for tens of thousands.
The next problem is that any measures are only a reaction to something . In all the examples that we have reviewed, work goes with data on past workload. A problem arises, records about it are transmitted to the instrument, and he says: “Yes, I know how to solve this problem.” But the solution concerns only a problem that has already occurred. The tool does not predict future events and therefore does not offer preparatory actions. A person can do it, and does it manually, but tools cannot do this.
The final reason is that in none of the solutions is there a transfer of knowledge . Here is what I mean: for example, let's take a tool that worked in one application on the first database instance, if you put it in one more same application on another database instance, it could, based on the knowledge gained, work with the first database data to help set up a second database. In fact, all tools start from scratch, they need to re-get all the data about what is happening. The man works quite differently. If I know how to set up one application in a certain way, I can see the same patterns in another application and maybe set it up much faster. But none of these algorithms, none of these tools, still work in this way.
Why am I sure it is time for a change? The answer to this question is about the same as the question of why super data arrays or machine learning became popular. Equipment becomes better : production resources increase, storage capacity grows, hardware capacity increases, which speeds up calculations for learning machine learning models.
We have become available advanced software. Previously, you had to be an expert on MATLAB or low-level linear algebra to write some machine learning algorithms. Now we have Torch and Tenso Flow, which make ML available, and, of course, we have learned to better understand the data. People know exactly what data may be needed to make decisions in the future, so do not discard as much data as before.
The goal of our research is to close this circle in autonomous DBMS. We can, like the previous tools, propose solutions, but instead of relying on the person — whether the solution is right, when exactly you need to deploy it — the algorithm will do it automatically. And then with the help of feedback will learn and eventually get better.
I want to talk about the projects we are currently working at Carnegie Mellon University. In them we approach the problem in two different ways.
In the first — OtterTune — we look for ways to customize the database, treating them like black boxes. That is, ways to customize existing DBMSs , without controlling the internal part of the system, and observing only the response.
The Peloton project is about creating new databases from scratch , from scratch, given that the system should work autonomously. What adjustments and optimization algorithms need to be laid - which cannot be applied to existing systems.
Consider both projects in order.
Ottertune
The project for adjusting existing systems that we developed is called OtterTune.
Imagine that a database is configured as a service. The idea is that you load the time metrics for performing heavy DB operations that consume all the resources, and the recommended configuration of regulators comes in response, which, in our opinion, will increase performance. This can be delay time, bandwidth or any other characteristic that you specify - we will try to find the best option.
The main thing that is new in the OtterTune project is the ability to use data from previous sessions to customize and increase the efficiency of the next sessions. For example, we take the PostgreSQL configuration, in which there is an application that we have never seen before. But if it has certain characteristics or uses a database like the databases that we have already seen in our applications, then we already know how to configure it and this application is more efficient.
At a higher level, the algorithm works as follows.
Suppose there is a target database: PostgreSQL, MySQL, or VectorWise. You need to install a controller in the same domain that will perform two tasks.
The first is performed by the so-called collector - a tool that collects data about the current configuration, i.e. metrics of query execution time from applications to the database. The data collected by the collector, loaded into the Tuning Manager - service settings. It does not matter if the database is running locally or in the cloud. After downloading, the data is saved in our own internal repository, which stores all test sessions we have ever made.
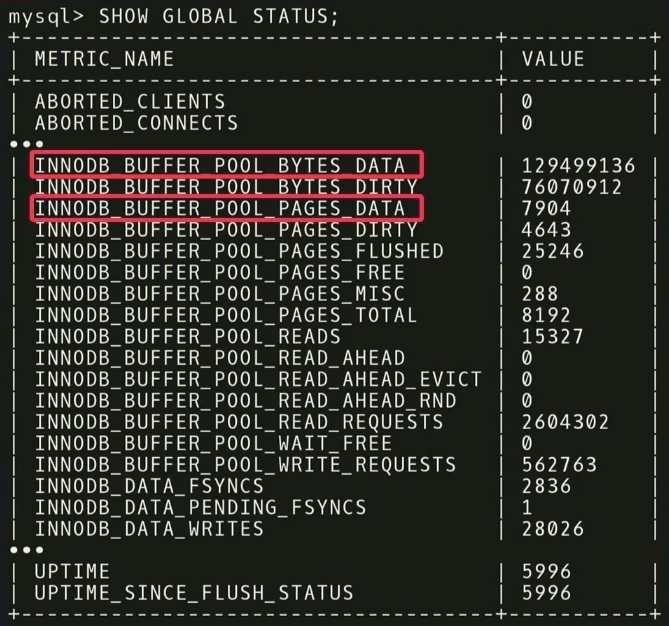
Before making recommendations, you need to perform two steps. First, you need to look at the runtime metrics and find out which of them are really important. In the example below, the metrics returned by MySQL but on the
SHOW_GLOBAL_STATUS on InnoDB. Not all of them are useful for our analysis. It is known that in machine learning a large amount of data is not always good. Because then it takes even more data to separate the wheat from the chaff. As in this case, it is important to get rid of entities that do not really matter .For example, there are two metrics:
INNODB_BUFFER_POOL_BYTES_DATA and INNODB_BUFFER_POOL_PAGES_DATA . In fact, this is the same metric, but in different units. You can perform a statistical analysis, see that the metrics are strongly correlated, and conclude that using both for analysis is redundant. If one of them is discarded, the dimension of the learning task is reduced and the time to receive a response is reduced.At the second stage we do the same, only with regards to the regulators. MySQL has 500 regulators , and, of course, not all of them are really significant, and different applications are important for different applications. It is necessary to carry out another statistical analysis to find out which regulators will really affect the objective function.
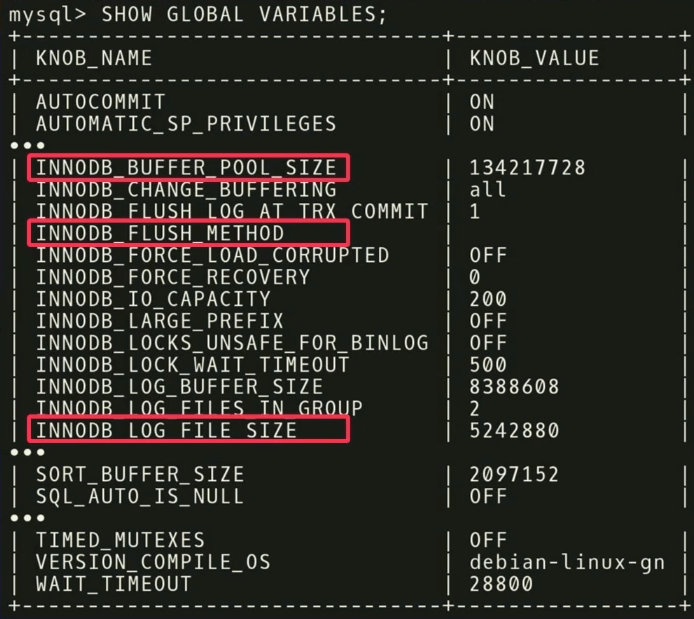
In our example, we found that the three regulators
INNODB_BUFFER_POOL_SIZE , FLUSH_METHOD and LOG_FILE_SIZE have the greatest impact on performance. At their expense, the latency for transactional workload is reduced.There are other interesting points related to regulators. In the screenshot there is a controller named
TIMED_MUTEXES . If you refer to the MySQL working documentation, section 45.7 will indicate that this regulator is outdated. But the machine learning algorithm cannot read the documentation , so it does not know about it. He knows that there is a regulator that can be turned on or off, and it will take a long time to realize that this does not affect anything. But you can make calculations in advance and find out that the regulator is not doing anything, and not wasting time setting it up.After analysis, the data is transferred to our configuration algorithm using the Gaussian process model — a rather old method. You have probably heard about deep learning, we are doing something similar, but without deep networks. We use the GPflow - package for working with models of the Gaussian process, developed in Russia on the basis of TensorFlow. The algorithm issues a recommendation that should improve the objective function; This data is passed back to the installation agent running inside the controller. The agent applies the changes, performing a reset — unfortunately, it’s necessary to restart the database — and then the process repeats again. Some more metrics of execution time are collected, transferred to the algorithm, an analysis is made of the possibility of improving and increasing productivity, a recommendation is issued, and so on, again and again.
The key feature of OtterTune is that as input to the algorithms, only information about the execution time metrics is needed. We do not need to see your data and user requests. We just need to track read and write operations. This is a weighty argument - data belonging to you or your customers will not be disclosed to third parties. We do not need to see any requests, the algorithm works based only on the runtime metrics, because it gives recommendations for regulators, and not for physical design.
Let's take a look at the work of the OtterTune demo. On the project website, we will launch Postgres 9.6, and load the system with a TPC-C test. Let's start with the initial PostgreSQL configuration, which is deployed when installed on Ubuntu.
First, we will run the TPC-C test for five minutes, collect the required runtime metrics, load them into the OtterTune service, get recommendations, apply the changes, and then repeat the process. Let's come back to this later. The database system runs on one computer, the Tensor Flow service runs on another, and loads the data here.
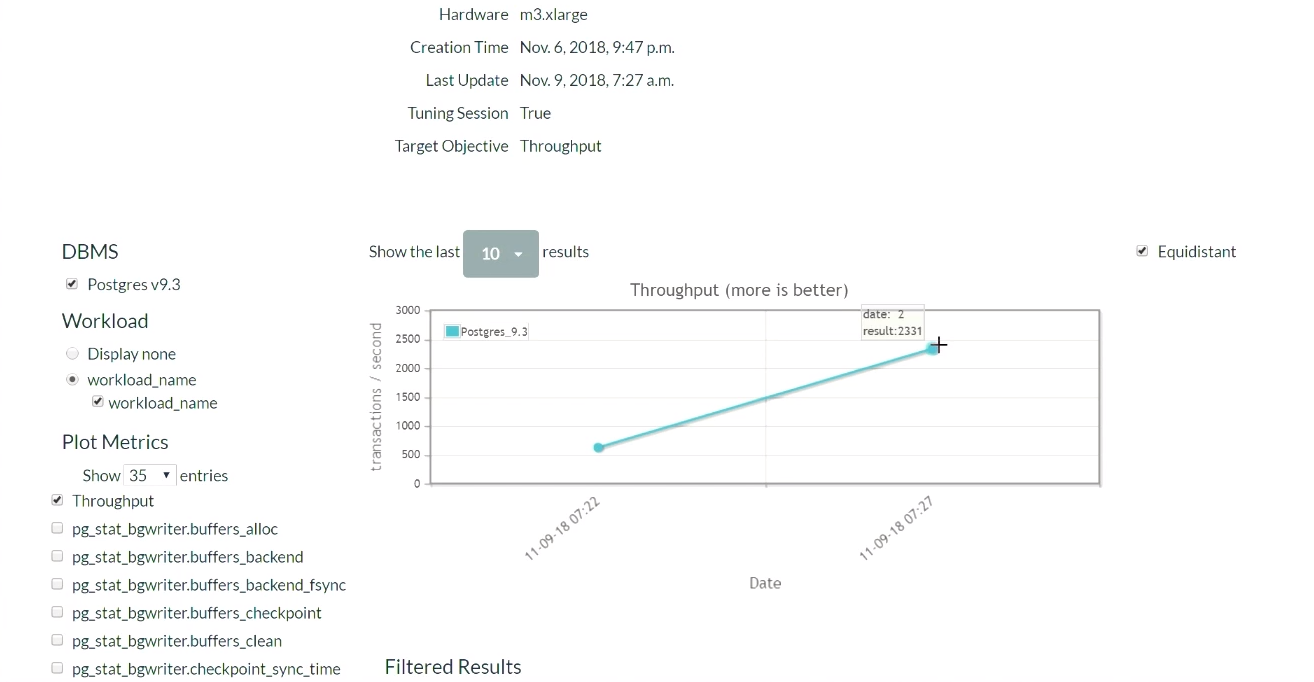
After five minutes, refresh the page (the demonstration of this part of the results begins at this moment ). When we first started, in the default configuration for PostgreSQL, 623 transactions occurred per second. Then, after receiving the recommendation and applying the changes once, the number of transactions increased to 2300 per second . We have to admit that this demonstration has already been launched several times, so the system already has a set of previously collected data. That is why the solution is so fast. What would happen if the system did not have such previously collected data? This algorithm is a kind of step-by-step function, and gradually it would have reached that level.
After some time and five iterations, the best result was 2600. We went from 600 transactions per second, and were able to reach values of 2600. A small drop occurred due to the algorithm decided to try a different way of adjusting the regulators after reaching good results. The result was with a margin, so a large drop in performance did not happen. Having received a negative result, the algorithm reconfigured and began to look for other methods of regulation.
We conclude that we should not be afraid of launching a bad strategy into the work, because the algorithm will explore the solution space and try on different configurations to achieve the terms of the SLA agreement. Although you can always customize the service so that the algorithm chooses only enhancement solutions. And over time you will get all the best and best results.
Now back to the topic of our conversation. I will tell you about the results already available from an article published in Sigmod. We configured MySQL and PostgreSQL for TPC-C using OtterTune, in order to increase throughput.
Compare the configuration of these DBMS, deployed by default when first installed on Ubuntu. Next, let's run several open source configuration scripts that can be obtained from Percona and some other consulting firms working with PostgreSQL. These scripts use heuristic procedures, like the rule that for your hardware you must set a certain buffer size. We also have a configuration from Amazon RDS, which already has presets from Amazon for the equipment you work on. Then we compare this with the result of manual configuration of expensive DBA, but with the condition that they have 20 minutes and the ability to set any parameters. And the last step is to run OtterTune.
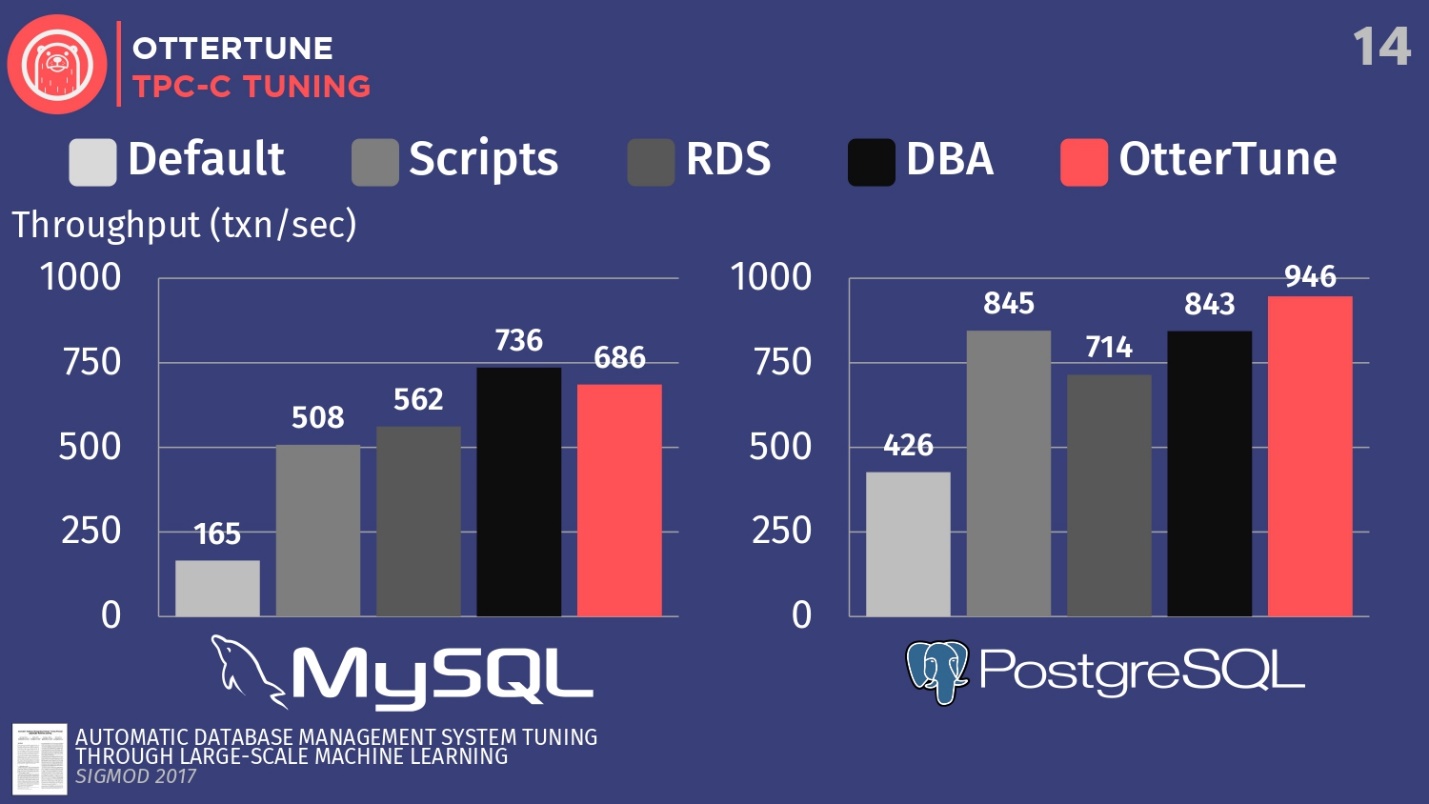
For MySQL, it is clear that the default configuration is far behind, the scripts work a little better, RDS is a little better. In this case, the best result was shown by the database administrator - the leading MySQL administrator from Facebook.
OtterTune lost to man . But the fact is that there is a certain regulator that disables the synchronization of magazine cleaning, and for Facebook it doesn’t matter. However, we denied access to this OtterTune regulator, because the algorithms do not know whether you agree to lose the last five milliseconds of data. In our opinion, this decision should be made by a person. Perhaps Facebook agrees with such losses, we do not know. If we set up this regulator in the same way, then we can compete with the person.
This example shows how we try to be conservative in that the final decision should be made by a person. Because there are certain aspects of databases, about which the ML algorithm does not guess.
In the case of PostgreSQL, configuration scripts work well. RDS does a little worse. But, it is worth noting that OtterTune's performance has exceeded this person. The histogram shows the results obtained after the database was set up by the chief expert on PostgreSQL in the Wisconsin judicial system. In this example, OtterTune was able to find the optimal balance between the size of the log file and the size of the buffer pool, balancing the amount of memory used by these two components and ensuring the best performance.
The main conclusion is that OtterTune uses such algorithms and machine learning that we can achieve the same or better performance compared to very, very expensive DBA. And this concerns not only a single instance of the database, we can scale up to tens of thousands of copies, because it’s just software, just data.
Peloton
The second project that I would like to talk about is called Peloton. This is a completely new data system that we are building from scratch at Carnegie Mellon. We call it a self-managed DBMS.
The idea is to find out which changes for the better can be made if you control the entire software stack. How to make the settings better than OtterTune can do, at the expense of knowing about each fragment of the system, about the entire program cycle.
How it will work: we have integrated the components of machine learning with reinforcement into the database system, and we can observe all aspects of its behavior during execution and then make recommendations. And we are not limited to recommendations for setting up regulators, as it happens in the OtterTune service, we would like to perform the entire standard set of actions that I mentioned earlier: the choice of indices, the choice of partitioning schemes, the vertical and horizontal scaling, etc.
The name of the Peloton system is likely to change. I do not know how in Russia, but here in the USA, the term “ peloton” means “fearless” and “finish”, and in French it means “platoon”. But in the US, there is the Peloton exercise bike company , which has a lot of money. Every time there is a mention of them, for example, opening a new store, or a new advertisement on TV, all my friends write to me: "Look, they stole your idea, stole your name." Advertising shows beautiful people who ride their exercise bikes, and we simply cannot compete with it. And recently, Uber announced a new resource planner called “ Peloton”, so we can no longer call our system that way. But we don’t have a new name yet, so in this story I’ll still use the current version of the name.
Consider how this system works at a high level. For example, take the target database, again, this is our software, this is what we work with. We are collecting the same workload history that I showed earlier. The difference is that we are going to generate prediction models that will allow us to predict what the workload cycles will be in the future, what the requirements of the workload will be in the future. That is why we call this system a self-managing DBMS.
The basic idea of the work of a self-managed DBMS is similar to the idea of a car with automatic control.
An unmanned vehicle looks in front of itself and can see what is located in front of it on the road, can predict how to get to its destination. The autonomous database system works in the same way. You should be able to look to the future and conclude what the workload will look like in a week or an hour. Then we transfer this predicted data to the planning component — we call it the brain — working on Tensor Flow.
The process echoes the work of AlphaGo from London within the framework of the Google Deep Mind project, at the top level it all works according to a similar scenario: a Monte Carlo tree search is used, the search results are various actions that need to be performed to achieve the desired goal.
The work scheme is approximately determined by the following algorithm:
- The source data is a set of required actions, for example, deleting an index, adding an index, vertical and horizontal scaling, and the like.
- A sequence of actions is generated, which ultimately leads to the maximum of the objective function.
- All criteria except the first one are discarded and changes are applied.
- The system looks at the resulting effect, then the process repeats over and over.
You should not constantly resort to the metaphor of an unmanned vehicle, but this is how they work. This is called the planning horizon.
Looking at the horizon on the road, we set an imaginary point to which we need to get, and then we begin to plan the sequence of actions to reach this point on the horizon: speed up, slow down, turn left, turn right, etc. Then we mentally discard all the actions except the first one that need to be performed, perform it, and then repeat the process again. UAVs chase such an algorithm 30 times a second. With regard to databases, this process proceeds a little slower, but the idea itself remains the same.
We decided to create our own database system from scratch, rather than build something on top of PostgreSQL or MySQL , because, frankly, they are too slow compared to what we would like to do. PostgreSQL is great, I love it and use it in my university courses, but it takes too much time to create indexes, because all the data comes from the disks.
In analogies with cars, an autonomous DBMS on PostgreSQL can be compared to an unmanned truck. The wagon will be able to recognize the dog in front of the road and drive around it, but not if it ran out onto the roadway right in front of the car. Then the collision is inevitable, because the wagon is not sufficiently maneuverable. We decided to create a system from scratch in order to be able to apply changes as quickly as possible and figure out what the correct configuration is.
Now we have solved the first problem and published an article about a combination of deep learning and classical linear regression for automatic selection and prediction of workloads.
But there is a bigger problem for which we do not have a good solution yet - action catalogs . The question is not how to choose actions, because the guys from Microsoft have already done it. The question is how to determine whether one action is better than another, in terms of what happens before and after deployment. How to reverse the action, if the index created by the command of a person is not optimal, how can you cancel this action and specify the reason for the cancellation. In addition, there are a number of other tasks in terms of the interaction of our own system with the outside world, for which we do not have a solution yet, but we are working on them.
By the way, I will tell an interesting story about a well-known database company. This company had an automatic index selection tool, and the tool had a problem. One customer constantly canceled all indices that the tool recommended and applied. This cancellation occurred so often that the tool hung. He did not know what the future strategy of behavior should be, because any solution offered to a person received a negative evaluation. When the developers turned to the client and asked: “Why do you cancel all recommendations and suggestions on indexes?”, The client answered that he simply did not like their names. People are stupid, but you have to deal with them. And for this problem, I still have no solution.
Designing an autonomous DBMS
Considering two different approaches to creating autonomous database systems, now let's talk about how to design a DBMS so that it is autonomous.
Let us dwell on three topics:
- how to set up regulators,
- how to collect internal metrics
- how to design action.
Let's return to the key points once again: the database system should provide the correct information to the machine learning algorithms for later making the best decisions. The amount of useless data that we transmit must be reduced to increase the speed of receiving responses.
, , , .
PG_SETTINGS , ., , , .. , .
, , , , .
, , , .
:
- . , , .
- . , , -1 0, .
- , . , . 64- , 0 2 64 . , .
, . , 10 , , 10 . , .
- , . , , . , , , .
, , , . , . , , , — . , .
, , , . , .
, , . , : , , , , . - Oracle, , .
, , .
, , . , , , . - , , , . : PostgreSQL , .
, , , .
- , , , . , , . RocksDB, MyRocks MySQL.
RocksDB . , . , , , . RocksDB, .
, , , , . MyRocks . — :
ROCKSDB_BITES_READ, ROCKSDB_BITES_WRITTEN . , , . , . , ., , , .
, , open source. , .
, , . MySQL , . , . 5 , 10 , , . 5 , — .
, . — PostgreSQL .
— . , . , , , , .
. , — SLA. , .
, . , . , . , .
, - , . , , - , . , , , — , -, , .
, , , .
, . , , , , 5- . downtime, .
, , , , , . , , , , .
Oracle autonomous database
Oracle . 2017 Oracle , . , Oracle, , « , Oracle 20 ».
. , , , , , . CIDR , . , : «, , , . , , , Oracle ?» , — .
, , , Oracle. , .
, — , , , - .
— , . , , , 2000- . , Oracle , . , : , — - .
, . , , .
— . , . : JOIN. . . , . .
Oracle. Microsoft 2017 SQL Server, . IBM DB2 00- , «LEO» — . , 1970-, Ingres. , JOIN, , . .
, , .
, , . , , . , , .
, , — , , , . , , , . , , .., .
HighLoad++ , HighLoad++ Siberia . , 39 , , highload- - .
HighLoad++ , . , UseData Conf — 16 , . , .
Source: https://habr.com/ru/post/456580/
All Articles