Android Application Architecture Guide
Hi, Habr! I present to your attention the free translation of the “Guide to app architecture” from JetPack . All comments on the translation please leave in the comments, and they will be corrected. Also for all comments from those who used the presented architecture with recommendations for its use will be useful.
This guide covers best practices and recommended architecture for building robust applications. This page assumes a basic familiarity with the Android Framework. If you are new to developing applications for Android, check out our developer guides to get started and learn more about the concepts mentioned in this guide. If you are interested in application architecture and would like to get acquainted with the materials of this manual from the point of view of programming in Kotlin, familiarize yourself with the Udacity course “Developing Android Applications with Kotlin” .
In most cases, desktop applications have a single entry point from the desktop or startup programs, and then run as a single monolithic process. Android applications have a much more complex structure. A typical Android application contains several application components , including Activities , Fragments , Services , ContentProviders, and BroadcastReceivers .
')
You declare all or some of these application components in the application manifest . The Android OS then uses this file to decide how to integrate your application into the device’s common user interface. Given that a well-written Android application contains several components, and users often interact with several applications in a short period of time, applications must adapt to different types of workflows and tasks that users manage.
For example, consider what happens when you share a photo in your favorite social networking app:
At any time during the process, the user may be interrupted by a phone call or notification. After the action associated with this interruption, the user expects to be able to return and resume this photo-sharing process. This behavior of switching applications is common on mobile devices, so your application must correctly handle these moments (tasks).
Remember that mobile devices are also limited in resources, so at any time the operating system can destroy some application processes in order to make room for new ones.
Given the conditions of this environment, the components of your application can be launched separately and not in order, and the operating system or the user can destroy them at any time. Since these events are not under your control, you should not store any data or states in your application components, and your application components should not depend on each other.
If you do not need to use application components to store data and application status, how should you develop your application?
The most important principle to follow is the division of responsibility . A common mistake is when you write all your code in an Activity or Fragment . These are user interface classes that must contain only logic, the processing interaction of the user interface and the operating system. By sharing as much of the responsibility as possible in these classes (SRP) , you can avoid many of the problems associated with the application life cycle.
Another important principle is that you must manage your user interface from a model , preferably from a permanent model. Models are the components that are responsible for processing data for an application. They are independent of View objects and application components, so they are not affected by the application life cycle and its associated problems.
The permanent model is ideal for the following reasons:
By organizing the foundation of your application on model classes with a clearly defined responsibility for data management, your application becomes more testable and supported.
This section demonstrates how to structure an application using architecture components , working in end- to- end usage scenarios .
Note. It is impossible to have one way of writing applications that is best suited for each scenario. However, the recommended architecture is a good starting point for most situations and workflows. If you already have a good way of writing applications for Android, corresponding to the general architectural principles, you should not change it.
Imagine that we are creating a user interface that displays a user profile. We use a private API and REST API to retrieve profile data.
To begin, consider the interaction of the modules of the architecture of the finished application
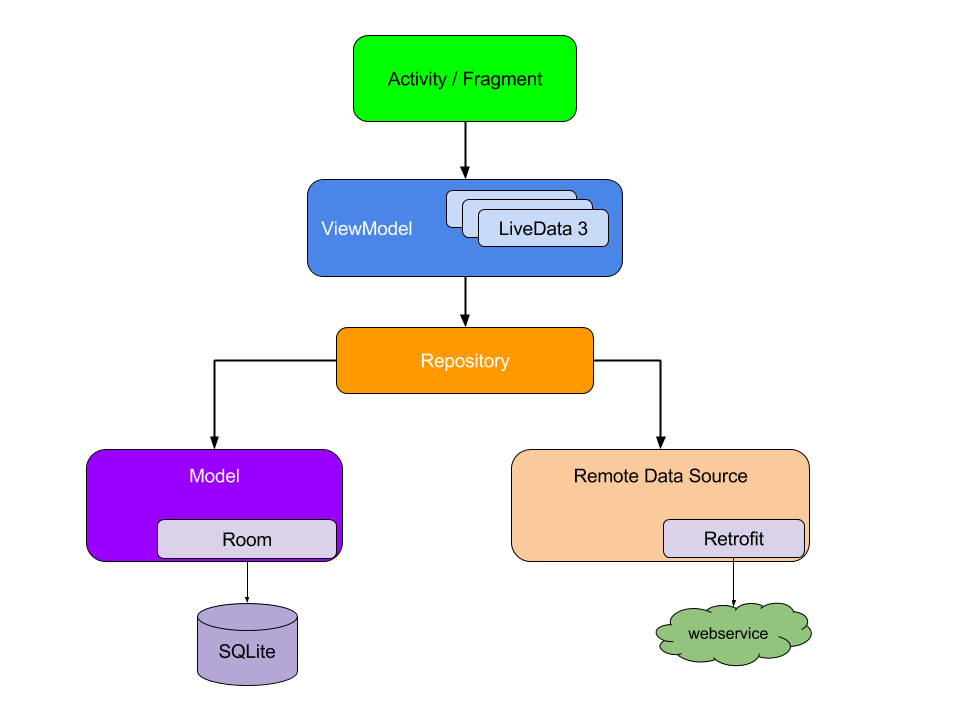
Please note that each component depends only on the component one level below it. For example, Activity and Fragments depend only on the view model. Repository is the only class that depends on many other classes; in this example, the storage depends on the constant data model and the remote internal data source.
This design pattern creates a consistent and enjoyable user experience. Regardless of whether the user returns to the application a few minutes after it is closed or a few days later, he will instantly see the user's information that the application is stored locally. If this data is outdated, the application storage module starts updating data in the background.
The user interface consists of the
To manage the user interface, our data model must contain the following data elements:
We use
The ViewModel object provides data for a specific component of the user interface, such as a fragment or an Activity, and contains business processing logic to interact with the model. For example, the ViewModel can call other components to load data and can forward user requests for data changes. The ViewModel is not aware of the components of the user interface, so it is not affected by configuration changes, such as recreating the Activity when the device is rotated.
Now we have defined the following files:
The following code snippets show the initial contents of these files. (Layout file omitted for simplicity.)
Now that we have these code modules, how do we connect them? After the user field is set in the UserProfileViewModel class, we need a way to inform the user interface.
Note. SavedStateHandle allows the ViewModel to access the saved state and the arguments of the associated fragment or action.
Now we need to inform our Fragment when a user object is received. This is where the LiveData architecture component appears.
LiveData is the observed data holder. Other components in your application can track object changes using this holder, without creating explicit and hard dependencies between them. The LiveData component also takes into account the state of the life cycle of components of your application, such as Activities, Fragments and Services, and includes cleaning logic to prevent objects from leaking and excessive memory consumption.
Note. If you already use libraries such as RxJava or Agera, you can continue to use them instead of LiveData. However, when using libraries and similar approaches, make sure that you handle the life cycle of your application correctly. In particular, make sure that you pause your data flows when the associated LifecycleOwner is stopped, and destroy those flows when the associated LifecycleOwner has been destroyed. You can also add the android.arch.lifecycle artifact: reactive streams to use LiveData with another library of reactive streams, such as RxJava2.
To include the LiveData component in our application, we change the field type in the
Now we modify the
Each time the user profile data is updated, the onChanged () callback is called, and the user interface is updated.
If you are familiar with other libraries that use observable callbacks, you may have realized that we did not redefine the onStop () fragment method to stop monitoring data. This step is not required for LiveData, because it supports the life cycle, it means that it will not call the
We have not added any logic to handle configuration changes, such as rotating a device’s screen by the user.
Now that we used LiveData to connect a
In this example, we assume that our backend provides a REST API. We use the Retrofit library to access our backend, although you can use another library that serves the same purpose.
Here is our definition of
The first idea for implementing a
Instead, our
Repository modules handle data operations. They provide a clean API, so the rest of the application can easily retrieve this data. They know where to get the data and what API calls to do when updating data. You can view repositories as intermediaries between different data sources, such as persistent models, web services, and caches.
Our
Although the storage module seems unnecessary, it serves an important purpose: it abstracts data sources from the rest of the application. Now our
Note. We missed the case of network errors for simplicity. For an alternative implementation that exposes errors and download status, see Appendix: Network Status Disclosure.
Manage dependencies between components
The
To solve this problem, you can use the following design patterns:
Implementing the service registry is easier than using DI, so if you are not familiar with DI, use the service location instead.
These templates allow you to scale your code because they provide clear templates for managing dependencies without duplicating or complicating the code. In addition, these templates allow you to quickly switch between test and production data sampling implementations.
In our sample application, Dagger 2 is used to manage the dependencies of the
Now we modify our
The
The main problem with the implementation of the
This design is suboptimal for the following reasons:
To eliminate these shortcomings, we add a new data source to our
Using our current implementation, if the user rotates the device or leaves and immediately returns to the application, the existing user interface becomes visible instantly because the storage retrieves data from our cache in memory.
However, what happens if the user leaves the app and returns a few hours after the Android OS finishes the process? Relying on our current implementation in this situation, we need to retrieve data from the network again. This update process is not just a bad user experience; it is also wasteful because it consumes valuable mobile data.
You can solve this problem by caching web requests, but this creates a key new problem: what happens if the same user data is displayed in a different type of request, for example, when you receive a list of friends? The application will display conflicting data, which at best is confusing. For example, our application can display two different versions of the data of the same user if the user sent a friend list request and a single user request at different times. Our application would have to figure out how to combine these conflicting data.
The right way to handle this situation is to use a permanent model. We come to the aid of the library of saving permanent data (DB) Room .
Room is an object-mapping library (object-mapping) that provides local data storage with minimal standard code. At compile time, it checks every request for conformance to your data schema, so non-working SQL queries result in compile-time errors and not runtime failures. Room abstracts from some basic details of the implementation of working with raw SQL tables and queries. It also allows you to monitor changes in database data, including collections and connection requests, exposing such changes using LiveData objects. It even explicitly defines execution constraints that solve common threading problems, such as access to the repository in the main thread.
Note. If your application already uses another solution, such as an SQLite object-relational mapping (ORM), you do not need to replace the existing solution with Room. However, if you are writing a new application or reorganizing an existing application, we recommend using Room to save your application data. Thus, you can take advantage of the abstraction of the library and the verification of queries.
To use Room, we need to define our local layout. First we add the
Then we create a database class, implementing
Note that
Now we need a way to insert user data into the database. For this task, we create a data access object (DAO) .
Notice that the
Note: Room checks invalidation based on table modifications, which means that it can send false positive notifications.
Having defined our
Now we can change our
Note that even if we changed the data source in the
If users return in a few days, the application using this architecture is likely to show outdated information until the repository receives updated information. Depending on your use case, you may not display outdated information. Instead, you can display placeholder data that shows dummy values and indicates that your application is currently loading and loading up-to-date information.
The only source of truth
Typically, different REST API endpoints return the same data. For example, if our backend has another endpoint that returns a list of friends, the same user object can come from two different API endpoints, perhaps even using different levels of detail. If it
For this reason, our implementation
In some use cases, such as pull-to-refresh, it is important that the user interface shows the user that a network operation is currently being performed. It is recommended to separate the user interface action from the actual data, since the data can be updated for various reasons. For example, if we received a list of friends, the same user can be selected again programmatically, which will lead to updating LiveData. From the point of view of the user interface, the fact of having a request in flight is just another data point, similar to any other part of the data in the object itself
We can use one of the following strategies to display the consistent update status of the data in the user interface, regardless of where the update request came from:
In the section on division of interests, we mentioned that testability is one of the key benefits of following this principle.
The following list shows how to test each module code from our advanced example:
Programming is a creative field, and the creation of Android applications is no exception. There are many ways to solve a problem, be it transferring data between multiple actions or fragments, retrieving remote data and storing it offline when offline, or any number of other common scenarios that non-trivial applications encounter.
Although the following recommendations are optional, our experience shows that implementing them makes your codebase more reliable, tested and supported in the long term:
Avoid designating entry points for your application — such as actions, services, and broadcast receivers — as data sources.
Instead, they should coordinate only with other components in order to obtain a subset of the data related to this entry point. Each component of the application is rather short-lived, depending on the interaction of the user with his device and the overall current state of the system.
Create clear boundaries of responsibility between the various modules of your application.
For example, do not distribute code that downloads data from the network, across several classes or packages in your codebase. Similarly, do not define multiple unrelated responsibilities — such as data caching and data binding — in the same class.
Expose as little as possible from each module.
Do not be tempted to create a “just one” label that reveals the details of the internal implementation of a single module. You may gain a little time in the short term, but then you will incur technical debt many times as your code base develops.
Think about how to make each module testable in isolation.
For example, having a well-defined API for retrieving data from the network makes it easier to test a module that stores this data in a local database. If instead you mix the logic of these two modules in one place or distribute your network code across the entire code base, testing becomes much more difficult - in some cases not even impossible.
Focus on the unique core of your application so that it stands out among other applications.
Do not reinvent the wheel by writing the same template over and over again. Instead, focus your time and energy on what makes your application unique, and allow the components of the Android architecture and other recommended libraries to cope with a repetitive pattern.
Save as much up-to-date and up-to-date data as possible.
Thus, users can enjoy the functionality of your application, even if their device is offline. Remember that not all your users enjoy a permanent high-speed connection.
Assign one data source to a single source that is true.
Whenever your application needs access to this piece of data, it should always come from this one source of truth.
In the above recommended application architecture section, we missed network errors and boot states to simplify code snippets.
This section shows how to display network status using the Resource class, which encapsulates both data and its status.
The following code fragment provides an example implementation.
Since downloading data from the network when displaying a copy of this data is common practice, it is useful to create an auxiliary class that can be reused in several places. For this example, we create a class named
The following diagram shows the decision tree for

It begins by observing the database for the resource. When a record is loaded from the database for the first time, it
If the network call succeeds, it stores the response in the database and reinitializes the stream. In the event of a failure, the network request
Keep in mind that relying on a database to submit changes involves using the associated side effects, which is not very good, because the unspecified behavior of these side effects can occur if the database does not send the changes, because the data has not changed.
In addition, do not send the results obtained from the network, as this will violate the principle of a single source of truth. In the end, perhaps the database contains triggers that change data values during a save operation. Similarly, do not send `SUCCESS` without new data, because then the client will receive the wrong version of the data.
The following code snippet shows the public API provided by the class
Note the following important details of class definition:
The full implementation of the class
Once created,
This guide covers best practices and recommended architecture for building robust applications. This page assumes a basic familiarity with the Android Framework. If you are new to developing applications for Android, check out our developer guides to get started and learn more about the concepts mentioned in this guide. If you are interested in application architecture and would like to get acquainted with the materials of this manual from the point of view of programming in Kotlin, familiarize yourself with the Udacity course “Developing Android Applications with Kotlin” .
Mobile app user experience
In most cases, desktop applications have a single entry point from the desktop or startup programs, and then run as a single monolithic process. Android applications have a much more complex structure. A typical Android application contains several application components , including Activities , Fragments , Services , ContentProviders, and BroadcastReceivers .
')
You declare all or some of these application components in the application manifest . The Android OS then uses this file to decide how to integrate your application into the device’s common user interface. Given that a well-written Android application contains several components, and users often interact with several applications in a short period of time, applications must adapt to different types of workflows and tasks that users manage.
For example, consider what happens when you share a photo in your favorite social networking app:
- The application invokes the intent of the camera. Android launches a camera application to process the request. At the moment, the user has left the application for social networks, and his experience as a user is impeccable.
- A camera application may trigger other intentions, such as launching a file picker that another application can launch.
- In the end, the user returns to the social networking app and shares the photo.
At any time during the process, the user may be interrupted by a phone call or notification. After the action associated with this interruption, the user expects to be able to return and resume this photo-sharing process. This behavior of switching applications is common on mobile devices, so your application must correctly handle these moments (tasks).
Remember that mobile devices are also limited in resources, so at any time the operating system can destroy some application processes in order to make room for new ones.
Given the conditions of this environment, the components of your application can be launched separately and not in order, and the operating system or the user can destroy them at any time. Since these events are not under your control, you should not store any data or states in your application components, and your application components should not depend on each other.
General architectural principles
If you do not need to use application components to store data and application status, how should you develop your application?
Division of responsibility
The most important principle to follow is the division of responsibility . A common mistake is when you write all your code in an Activity or Fragment . These are user interface classes that must contain only logic, the processing interaction of the user interface and the operating system. By sharing as much of the responsibility as possible in these classes (SRP) , you can avoid many of the problems associated with the application life cycle.
User interface control from model
Another important principle is that you must manage your user interface from a model , preferably from a permanent model. Models are the components that are responsible for processing data for an application. They are independent of View objects and application components, so they are not affected by the application life cycle and its associated problems.
The permanent model is ideal for the following reasons:
- Your users will not lose data if Android OS destroys your application to free up resources.
- Your application continues to work in cases where the network connection is unstable or unavailable.
By organizing the foundation of your application on model classes with a clearly defined responsibility for data management, your application becomes more testable and supported.
Recommended Application Architecture
This section demonstrates how to structure an application using architecture components , working in end- to- end usage scenarios .
Note. It is impossible to have one way of writing applications that is best suited for each scenario. However, the recommended architecture is a good starting point for most situations and workflows. If you already have a good way of writing applications for Android, corresponding to the general architectural principles, you should not change it.
Imagine that we are creating a user interface that displays a user profile. We use a private API and REST API to retrieve profile data.
Overview
To begin, consider the interaction of the modules of the architecture of the finished application
Please note that each component depends only on the component one level below it. For example, Activity and Fragments depend only on the view model. Repository is the only class that depends on many other classes; in this example, the storage depends on the constant data model and the remote internal data source.
This design pattern creates a consistent and enjoyable user experience. Regardless of whether the user returns to the application a few minutes after it is closed or a few days later, he will instantly see the user's information that the application is stored locally. If this data is outdated, the application storage module starts updating data in the background.
Create user interface
The user interface consists of the
UserProfileFragment fragment and the corresponding user_profile_layout.xml layout user_profile_layout.xml .To manage the user interface, our data model must contain the following data elements:
- User ID: user ID. The best solution is to pass this information to the fragment using the fragment arguments. If the Android OS disrupts our process, this information is saved, so the ID will be available the next time we launch our application.
- User object: a data class that contains user information.
We use
UserProfileViewModel , based on the ViewModel component of the architecture, to store this information.The ViewModel object provides data for a specific component of the user interface, such as a fragment or an Activity, and contains business processing logic to interact with the model. For example, the ViewModel can call other components to load data and can forward user requests for data changes. The ViewModel is not aware of the components of the user interface, so it is not affected by configuration changes, such as recreating the Activity when the device is rotated.
Now we have defined the following files:
user_profile.xml: defined the layout of the user interface.UserProfileFragment: described the user interface controller, which is responsible for displaying information to the user.UserProfileViewModel: the class responsible for preparing the data for display in theUserProfileFragmentand responding to user interaction.
The following code snippets show the initial contents of these files. (Layout file omitted for simplicity.)
class UserProfileViewModel : ViewModel() { val userId : String = TODO() val user : User = TODO() } class UserProfileFragment : Fragment() { private val viewModel: UserProfileViewModel by viewModels() override fun onCreateView( inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle? ): View { return inflater.inflate(R.layout.main_fragment, container, false) } } Now that we have these code modules, how do we connect them? After the user field is set in the UserProfileViewModel class, we need a way to inform the user interface.
Note. SavedStateHandle allows the ViewModel to access the saved state and the arguments of the associated fragment or action.
// UserProfileViewModel class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : User = TODO() } // UserProfileFragment private val viewModel: UserProfileViewModel by viewModels( factoryProducer = { SavedStateVMFactory(this) } ... ) Now we need to inform our Fragment when a user object is received. This is where the LiveData architecture component appears.
LiveData is the observed data holder. Other components in your application can track object changes using this holder, without creating explicit and hard dependencies between them. The LiveData component also takes into account the state of the life cycle of components of your application, such as Activities, Fragments and Services, and includes cleaning logic to prevent objects from leaking and excessive memory consumption.
Note. If you already use libraries such as RxJava or Agera, you can continue to use them instead of LiveData. However, when using libraries and similar approaches, make sure that you handle the life cycle of your application correctly. In particular, make sure that you pause your data flows when the associated LifecycleOwner is stopped, and destroy those flows when the associated LifecycleOwner has been destroyed. You can also add the android.arch.lifecycle artifact: reactive streams to use LiveData with another library of reactive streams, such as RxJava2.
To include the LiveData component in our application, we change the field type in the
UserProfileViewModel to LiveData. Now UserProfileFragment informed about the updated data. In addition, since this LiveData field supports the life cycle, it automatically clears links when they are no longer needed. class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = TODO() } Now we modify the
UserProfileFragment to observe the data in the ViewModel and to update the user interface according to the changes: override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) viewModel.user.observe(viewLifecycleOwner) { // UI } } Each time the user profile data is updated, the onChanged () callback is called, and the user interface is updated.
If you are familiar with other libraries that use observable callbacks, you may have realized that we did not redefine the onStop () fragment method to stop monitoring data. This step is not required for LiveData, because it supports the life cycle, it means that it will not call the
onChanged() callback if the fragment is in an inactive state; that is, he received the onStart () call, but has not yet received onStop() ). LiveData also automatically removes the observer when calling the fragment onDestroy () method.We have not added any logic to handle configuration changes, such as rotating a device’s screen by the user.
UserProfileViewModel automatically restored when the configuration changes, so as soon as a new fragment is created, it receives the same ViewModel instance and the callback is called immediately using current data. Given that ViewModel objects are designed to relive the corresponding View objects that they update, you should not include direct references to View objects in your ViewModel implementation. For more information on the lifetime of a ViewModel corresponds to the life cycle of user interface components, see ViewModel Life Cycle.Data retrieval
Now that we used LiveData to connect a
UserProfileViewModel to a UserProfileFragment , how can we get user profile data?In this example, we assume that our backend provides a REST API. We use the Retrofit library to access our backend, although you can use another library that serves the same purpose.
Here is our definition of
Webservice , which is associated with our backend: interface Webservice { /** * @GET declares an HTTP GET request * @Path("user") annotation on the userId parameter marks it as a * replacement for the {user} placeholder in the @GET path */ @GET("/users/{user}") fun getUser(@Path("user") userId: String): Call<User> } The first idea for implementing a
ViewModel may include a direct call to the Webservice to retrieve data and assign this data to our LiveData object. This design works, but with its use, our application becomes increasingly difficult to maintain as it grows. This gives too much responsibility to the UserProfileViewModel class, which violates the principle of separation of interests . In addition, the ViewModel scope is associated with an Activity or Fragment life cycle, which means that the data from the Webservice lost when the life cycle of the associated user interface object ends. This behavior creates an undesirable user experience.Instead, our
ViewModel delegates the process of extracting data to a new module, the repository.Repository modules handle data operations. They provide a clean API, so the rest of the application can easily retrieve this data. They know where to get the data and what API calls to do when updating data. You can view repositories as intermediaries between different data sources, such as persistent models, web services, and caches.
Our
UserRepository class, shown in the following code snippet, uses an instance of the WebService to retrieve user data: class UserRepository { private val webservice: Webservice = TODO() // ... fun getUser(userId: String): LiveData<User> { // . . val data = MutableLiveData<User>() webservice.getUser(userId).enqueue(object : Callback<User> { override fun onResponse(call: Call<User>, response: Response<User>) { data.value = response.body() } // . override fun onFailure(call: Call<User>, t: Throwable) { TODO() } }) return data } } Although the storage module seems unnecessary, it serves an important purpose: it abstracts data sources from the rest of the application. Now our
UserProfileViewModel does not know how to retrieve data, so we can provide the view model with data obtained from several different implementations of data retrieval.Note. We missed the case of network errors for simplicity. For an alternative implementation that exposes errors and download status, see Appendix: Network Status Disclosure.
Manage dependencies between components
The
UserRepository class above requires an instance of Webservice to retrieve user data. He could just create an instance, but for that he also needs to know the dependencies of the Webservice class. In addition, UserRepository is probably not the only class that needs a web service. This situation requires us to duplicate the code, because every class that needs a link to the Webservice needs to know how to create it and its dependencies. If each class creates a new WebService , our application can become very resource-intensive.To solve this problem, you can use the following design patterns:
- Dependency Injection (DI) . Dependency injection allows classes to define their dependencies without creating them. At run time, another class is responsible for providing these dependencies. We recommend the Dagger 2 library for implementing dependency injection in Android applications. Dagger 2 automatically creates objects, bypassing the dependency tree, and provides guarantees of compile time for dependencies.
- (Service location) Service Locator: A service locator template provides a registry in which classes can get their dependencies instead of building them.
Implementing the service registry is easier than using DI, so if you are not familiar with DI, use the service location instead.
These templates allow you to scale your code because they provide clear templates for managing dependencies without duplicating or complicating the code. In addition, these templates allow you to quickly switch between test and production data sampling implementations.
In our sample application, Dagger 2 is used to manage the dependencies of the
Webservice object.Connect the ViewModel and Vault
Now we modify our
UserProfileViewModel to use the UserRepository object: class UserProfileViewModel @Inject constructor( savedStateHandle: SavedStateHandle, userRepository: UserRepository ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = userRepository.getUser(userId) } Caching
The
UserRepository implementation abstracts the call to the Webservice object, but since it relies on only one data source, it is not very flexible.The main problem with the implementation of the
UserRepository is that after receiving data from our backend, this data is not stored anywhere. Therefore, if the user leaves the UserProfileFragment and then returns to it, our application must re-retrieve the data, even if it has not changed.This design is suboptimal for the following reasons:
- It spends valuable traffic resources.
- This forces the user to wait for the completion of a new request.
To eliminate these shortcomings, we add a new data source to our
UserRepository , which caches User objects in memory: // Dagger, . @Singleton class UserRepository @Inject constructor( private val webservice: Webservice, // . . private val userCache: UserCache ) { fun getUser(userId: String): LiveData<User> { val cached = userCache.get(userId) if (cached != null) { return cached } val data = MutableLiveData<User>() userCache.put(userId, data) // , , . // . webservice.getUser(userId).enqueue(object : Callback<User> { override fun onResponse(call: Call<User>, response: Response<User>) { data.value = response.body() } // . override fun onFailure(call: Call<User>, t: Throwable) { TODO() } }) return data } } Permanent data
Using our current implementation, if the user rotates the device or leaves and immediately returns to the application, the existing user interface becomes visible instantly because the storage retrieves data from our cache in memory.
However, what happens if the user leaves the app and returns a few hours after the Android OS finishes the process? Relying on our current implementation in this situation, we need to retrieve data from the network again. This update process is not just a bad user experience; it is also wasteful because it consumes valuable mobile data.
You can solve this problem by caching web requests, but this creates a key new problem: what happens if the same user data is displayed in a different type of request, for example, when you receive a list of friends? The application will display conflicting data, which at best is confusing. For example, our application can display two different versions of the data of the same user if the user sent a friend list request and a single user request at different times. Our application would have to figure out how to combine these conflicting data.
The right way to handle this situation is to use a permanent model. We come to the aid of the library of saving permanent data (DB) Room .
Room is an object-mapping library (object-mapping) that provides local data storage with minimal standard code. At compile time, it checks every request for conformance to your data schema, so non-working SQL queries result in compile-time errors and not runtime failures. Room abstracts from some basic details of the implementation of working with raw SQL tables and queries. It also allows you to monitor changes in database data, including collections and connection requests, exposing such changes using LiveData objects. It even explicitly defines execution constraints that solve common threading problems, such as access to the repository in the main thread.
Note. If your application already uses another solution, such as an SQLite object-relational mapping (ORM), you do not need to replace the existing solution with Room. However, if you are writing a new application or reorganizing an existing application, we recommend using Room to save your application data. Thus, you can take advantage of the abstraction of the library and the verification of queries.
To use Room, we need to define our local layout. First we add the
@Entity annotation to our User data model class and the @PrimaryKey annotation in the class id field. These annotations mark User as a table in our database, and id as the primary key of the table: @Entity data class User( @PrimaryKey private val id: String, private val name: String, private val lastName: String ) Then we create a database class, implementing
RoomDatabase for our application: @Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() Note that
UserDatabase is abstract. The Room library automatically provides an implementation of this. See the Room documentation for details.Now we need a way to insert user data into the database. For this task, we create a data access object (DAO) .
@Dao interface UserDao { @Insert(onConflict = REPLACE) fun save(user: User) @Query("SELECT * FROM user WHERE id = :userId") fun load(userId: String): LiveData<User> } Notice that the
load method returns an object of type LiveData. Room knows when the database is changed, and automatically notifies all active observers of data changes. Because Room uses LiveData , this operation is effective; it updates data only if there is at least one active observer.Note: Room checks invalidation based on table modifications, which means that it can send false positive notifications.
Having defined our
UserDao class, we then refer to the DAO from our database class: @Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() { abstract fun userDao(): UserDao } Now we can change our
UserRepository to enable the Room data source: // Dagger, . @Singleton class UserRepository @Inject constructor( private val webservice: Webservice, // . . private val executor: Executor, private val userDao: UserDao ) { fun getUser(userId: String): LiveData<User> { refreshUser(userId) // LiveData . return userDao.load(userId) } private fun refreshUser(userId: String) { // . executor.execute { // , . val userExists = userDao.hasUser(FRESH_TIMEOUT) if (!userExists) { // . val response = webservice.getUser(userId).execute() // . // . LiveData , // . userDao.save(response.body()!!) } } } companion object { val FRESH_TIMEOUT = TimeUnit.DAYS.toMillis(1) } } Note that even if we changed the data source in the
UserRepository , we did not need to change our UserProfileViewModel or UserProfileFragment . This minor update demonstrates the flexibility that our application architecture provides. It is also great for testing, because we can provide a fake UserRepository and at the same time test our production UserProfileViewModel .If users return in a few days, the application using this architecture is likely to show outdated information until the repository receives updated information. Depending on your use case, you may not display outdated information. Instead, you can display placeholder data that shows dummy values and indicates that your application is currently loading and loading up-to-date information.
The only source of truth
Typically, different REST API endpoints return the same data. For example, if our backend has another endpoint that returns a list of friends, the same user object can come from two different API endpoints, perhaps even using different levels of detail. If it
UserRepositoryreturned the response from the query Webserviceas is, without consistency checking, our user interfaces might show confusing information, because the version and format of the data from the repository would depend on the last called endpoint.For this reason, our implementation
UserRepositorystores web service responses in a database. The database changes then callbacks for the active LiveData objects . Using this model,The database serves as the only source of truth , and other parts of the application access it through ours UserRepository. Regardless of whether you use disk cache, we recommend that your repository identify the data source as the only source of truth for the rest of your application.Show the progress of the operation
In some use cases, such as pull-to-refresh, it is important that the user interface shows the user that a network operation is currently being performed. It is recommended to separate the user interface action from the actual data, since the data can be updated for various reasons. For example, if we received a list of friends, the same user can be selected again programmatically, which will lead to updating LiveData. From the point of view of the user interface, the fact of having a request in flight is just another data point, similar to any other part of the data in the object itself
User.We can use one of the following strategies to display the consistent update status of the data in the user interface, regardless of where the update request came from:
getUser (),LiveData. . , NetworkBoundResource GitHub android-Architecture-components .UserRepository, . , , , pull-to-refresh.
In the section on division of interests, we mentioned that testability is one of the key benefits of following this principle.
The following list shows how to test each module code from our advanced example:
- User interface and interaction : use the Android UI test toolkit . The best way to create this test is to use the Espresso library . You can create a snippet and provide it with a layout
UserProfileViewModel. Since the fragment is associated only withUserProfileViewModel, mocking (imitation) of only this class is sufficient to fully test the user interface of your application. - ViewModel:
UserProfileViewModelJUnit . ,UserRepository. - UserRepository:
UserRepositoryJUnit.WebserviceUserDao. :- -.
- .
- , .
Webservice,UserDao, .- UserDao: DAO . - , . , , , …
: Room , DAO, JSQL SupportSQLiteOpenHelper . , SQLite SQLite . - -: . , -, . , MockWebServer , .
- : maven .
androidx.arch.core: JUnit:
Programming is a creative field, and the creation of Android applications is no exception. There are many ways to solve a problem, be it transferring data between multiple actions or fragments, retrieving remote data and storing it offline when offline, or any number of other common scenarios that non-trivial applications encounter.
Although the following recommendations are optional, our experience shows that implementing them makes your codebase more reliable, tested and supported in the long term:
Avoid designating entry points for your application — such as actions, services, and broadcast receivers — as data sources.
Instead, they should coordinate only with other components in order to obtain a subset of the data related to this entry point. Each component of the application is rather short-lived, depending on the interaction of the user with his device and the overall current state of the system.
Create clear boundaries of responsibility between the various modules of your application.
For example, do not distribute code that downloads data from the network, across several classes or packages in your codebase. Similarly, do not define multiple unrelated responsibilities — such as data caching and data binding — in the same class.
Expose as little as possible from each module.
Do not be tempted to create a “just one” label that reveals the details of the internal implementation of a single module. You may gain a little time in the short term, but then you will incur technical debt many times as your code base develops.
Think about how to make each module testable in isolation.
For example, having a well-defined API for retrieving data from the network makes it easier to test a module that stores this data in a local database. If instead you mix the logic of these two modules in one place or distribute your network code across the entire code base, testing becomes much more difficult - in some cases not even impossible.
Focus on the unique core of your application so that it stands out among other applications.
Do not reinvent the wheel by writing the same template over and over again. Instead, focus your time and energy on what makes your application unique, and allow the components of the Android architecture and other recommended libraries to cope with a repetitive pattern.
Save as much up-to-date and up-to-date data as possible.
Thus, users can enjoy the functionality of your application, even if their device is offline. Remember that not all your users enjoy a permanent high-speed connection.
Assign one data source to a single source that is true.
Whenever your application needs access to this piece of data, it should always come from this one source of truth.
Addition: network status disclosure
In the above recommended application architecture section, we missed network errors and boot states to simplify code snippets.
This section shows how to display network status using the Resource class, which encapsulates both data and its status.
The following code fragment provides an example implementation.
Resource: // , . sealed class Resource<T>( val data: T? = null, val message: String? = null ) { class Success<T>(data: T) : Resource<T>(data) class Loading<T>(data: T? = null) : Resource<T>(data) class Error<T>(message: String, data: T? = null) : Resource<T>(data, message) } Since downloading data from the network when displaying a copy of this data is common practice, it is useful to create an auxiliary class that can be reused in several places. For this example, we create a class named
NetworkBoundResource.The following diagram shows the decision tree for
NetworkBoundResource:It begins by observing the database for the resource. When a record is loaded from the database for the first time, it
NetworkBoundResourcechecks whether the result is good enough to be sent, or whether it needs to be retrieved from the network again. Please note that both of these situations can occur at the same time, given that you probably want to show cached data when you update it from the network.If the network call succeeds, it stores the response in the database and reinitializes the stream. In the event of a failure, the network request
NetworkBoundResourcesends the failure directly.. . , .Keep in mind that relying on a database to submit changes involves using the associated side effects, which is not very good, because the unspecified behavior of these side effects can occur if the database does not send the changes, because the data has not changed.
In addition, do not send the results obtained from the network, as this will violate the principle of a single source of truth. In the end, perhaps the database contains triggers that change data values during a save operation. Similarly, do not send `SUCCESS` without new data, because then the client will receive the wrong version of the data.
The following code snippet shows the public API provided by the class
NetworkBoundResourcefor its subclasses: // ResultType: . // RequestType: API. abstract class NetworkBoundResource<ResultType, RequestType> { // API . @WorkerThread protected abstract fun saveCallResult(item: RequestType) // , , // . @MainThread protected abstract fun shouldFetch(data: ResultType?): Boolean // . @MainThread protected abstract fun loadFromDb(): LiveData<ResultType> // API. @MainThread protected abstract fun createCall(): LiveData<ApiResponse<RequestType>> // , . // , . protected open fun onFetchFailed() {} // LiveData, , // . fun asLiveData(): LiveData<ResultType> = TODO() } Note the following important details of class definition:
- It defines two type parameters,
ResultTypeandRequestTypesince the data type returned from the API may not match the data type used locally. - It uses the class
ApiResponsefor network requests.ApiResponseIs a simple wrapper for a classRetrofit2.Callthat converts the answers into instancesLiveData.
The full implementation of the class
NetworkBoundResourceappears as part of the GitHub android-Architecture-components project .Once created,
NetworkBoundResourcewe can use it to write our disk-attached and network implementations Userin the class UserRepository: // Dagger2, . @Singleton class UserRepository @Inject constructor( private val webservice: Webservice, private val userDao: UserDao ) { fun getUser(userId: String): LiveData<User> { return object : NetworkBoundResource<User, User>() { override fun saveCallResult(item: User) { userDao.save(item) } override fun shouldFetch(data: User?): Boolean { return rateLimiter.canFetch(userId) && (data == null || !isFresh(data)) } override fun loadFromDb(): LiveData<User> { return userDao.load(userId) } override fun createCall(): LiveData<ApiResponse<User>> { return webservice.getUser(userId) } }.asLiveData() } } Source: https://habr.com/ru/post/456256/
All Articles