Data Science and Tropics Conference
Articles about computer vision, interpretability, NLP - we visited the AISTATS conference in Japan and want to share a review of articles. This is a major conference on statistics and machine learning, and this year it is being held in Okinawa, an island near Taiwan. In this post, Yulia Antokhina ( Yulia_chan ) prepared a description of bright articles from the main section, and in the next, together with Anna Papeta, she will tell about the reports of guest lecturers and theoretical studies. We will tell a little about how the conference itself was held and about “non-Japanese” Japan.

Defending against Whitebox Adversarial Attacks via Randomized Discretization
Yuchen Zhang (Microsoft); Percy Liang (Stanford University)
→ Article
→ Code
')
Let's start with the article about protection against adversarial attacks in computer vision. These are targeted attacks on models, when the target of an attack is to cause a model to err, up to a predetermined result. Algorithms of computer vision can make mistakes even when changes in the original image are not essential for a person. The task is relevant, for example, for machine vision, which in good conditions recognizes road signs faster than a person, but works much worse when attacking.
Adversarial Attack visually
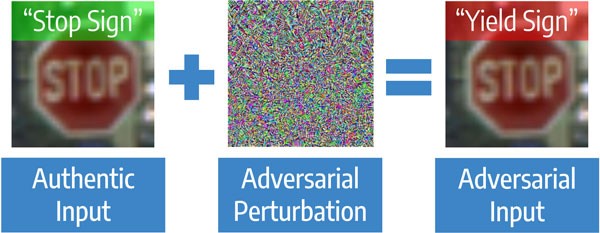
Attacks are Blackbox - when an attacker knows nothing about the algorithm, and the Whitebox is a reverse situation. To protect the models there are two main approaches. The first approach is to train the model on ordinary and “attacked” pictures - it is called adversarial training. This approach works well on small pictures like MNIST, but there are articles that show that it does not work well on large pictures, like ImageNet. The second type of protection does not require retraining of the model. It is enough just to pre-process the image before submission to the model. Conversion examples: JPEG compression, resizing. These methods require less computation, but now they only work against Blackbox attacks, since if the transformation is known, the opposite can be applied.
Method
In the article, the authors propose a method that does not require overtraining of the model and works for Whitebox attacks. The goal is to reduce the Kullback-Leibner distance between ordinary examples and “spoiled” using random transformation. It turns out that it is enough to add random noise, and then randomly sample colors. That is, the input of the algorithm is “degraded” image quality, but still sufficient for the algorithm to work. And due to chance, there is the potential to resist Whitebox attacks.
On the left - the original picture, in the middle - an example of clustering pixel colors in Lab space, on the right - a picture in several colors (For example, instead of 40 shades of blue - one)

results
This method was compared to the strongest attacks on the NIPS 2017 Adversarial Attacks & Defenses Competition, and it shows an average of better quality and does not retrain under the “attacker”.
Comparison of the strongest defense methods against the strongest attacks on the NIPS Competition

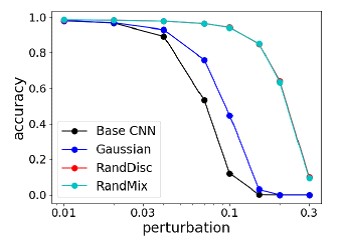
Comparison of accuracy of methods on MNIST with different image changes
Attenuating Bias in Word vectors
Sunipa Dev (University of Utah); Jeff Phillips (University of Utah)
→ Article
The “fashionable” talk was about Unbiased Word Vectors. In this case, Bias means bias by gender or nationality in the representations of words. Any regulators may oppose such “discrimination”, and therefore scientists from the University of Utah decided to explore the possibilities of “equalizing rights” for the NLP. In fact, why a man can not be "glamorous", and a woman "Data Scientist"?
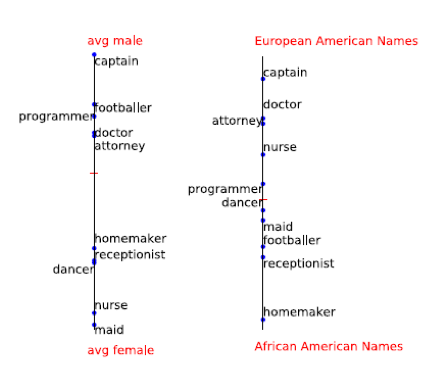
Original - the result, which is obtained now, the rest - the results of the unbiased algorithm

The article discusses how to find such an offset. They decided that gender and nationality are well characterized by names. So, if you find the displacement by name and subtract it, then, probably, you can get rid of the bias of the algorithm.
An example of more "male" and "female" words:
Names to search for sex offsets:

Oddly enough, such a simple method works. The authors have trained the unbiased with respect to the floor Glove and laid out in Git.
What made you do this? Understanding black-box decisions with input inputs
Brandon Carter (MIT CSAIL); Jonas Mueller (Amazon Web Services); Siddhartha Jain (MIT CSAIL); David Gifford (MIT CSAIL)
→ Article
→ Code one and two
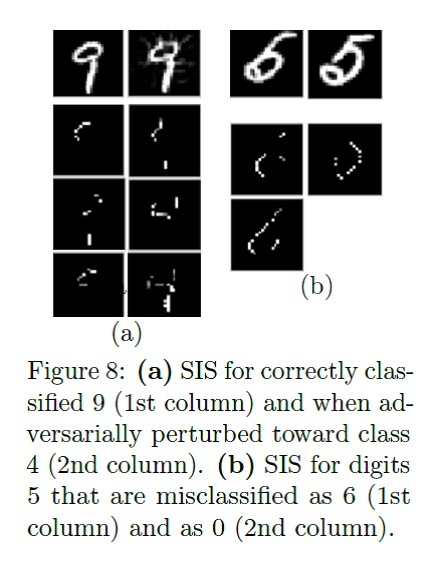
The following article describes the Sufficient Input Subset algorithm. SIS are minimal feature subsets for which the model will produce a certain result, even if all other features are zeroed. This is another way to somehow interpret the results of complex models. Works on both texts and pictures.
SIS search algorithm in detail:

Example of application on the text with reviews about beer:

Application example on MNIST:
Comparison of the methods of “interpretation” according to the Kullback-Leibler distance with respect to the “ideal” result:
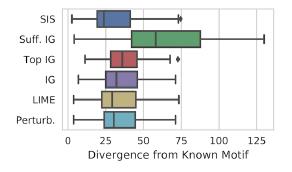
Features are first ranked by influence on the model, and then split into disjoint subsets, starting with the most influential. It works by brute force, and on a marked-up dataset, the result is interpreted better than LIME. There is a convenient implementation of SIS search from Google Research.
Empirical Risk Minimization and Stochastic Gradient Descent for Relational Data
Victor Veitch (Columbia University); Morgane Austern (Columbia University); Wenda Zhou (Columbia University); David Blei (Columbia University); Peter Orbanz (Columbia University)
→ Article
→ Code
In the section on optimization, there was a report on Empirical Risk Minimization, where the authors investigated how to apply stochastic gradient descent on graphs. For example, when building a model on a given social network, you can only use fixed profile features (the number of subscribers), but then information about the relationships between profiles (who is subscribed to) is lost. In this case, the entire graph is often difficult to process - for example, it does not fit in memory. When such a situation occurs on tabular data, the model can be run on subsamples. And how to choose the analog subsample on the graph was not clear. The authors theoretically substantiated the possibility of using random subgraphs as an analogue of subsamples, and this turned out to be “Not crazy idea”. On Github, there are replicable examples from the article, including the Wikipedia example.
Category Embeddings on Wikipedia data, taking into account its graph structure, the highlighted articles are closest in subject to French Physicists:
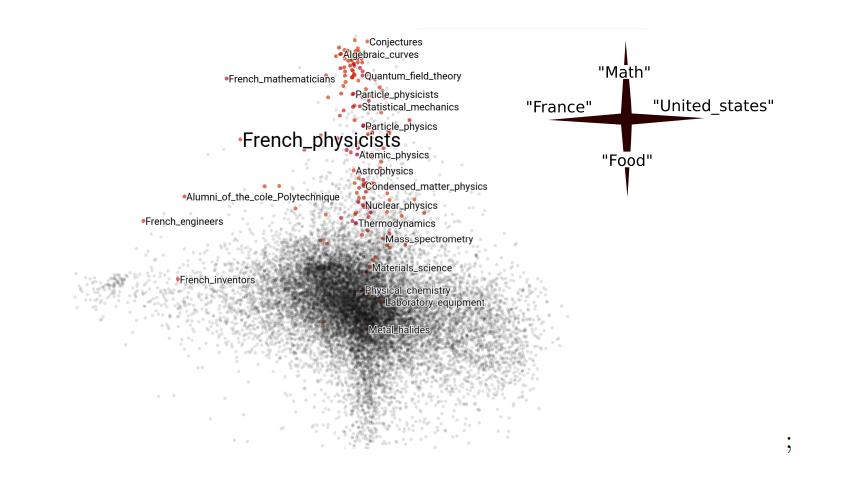
→ Data Science for Networked Data
About discrete data graphs was another review report by Data Science for Networked Data from guest speaker Poling Loh (University of Wisconsin-Madison). The presentation addressed the topics of Statistical inference, Resource allocation, Local algorithms. In Statistical inference, for example, it was about how to understand what structure a graph has according to data on infectious diseases. It is proposed to use statistics on the number of connections between infected nodes - and a theorem is proved for the corresponding statistical test.
In general, the report is more interesting to watch, most likely, to those who are not engaged in graph models, but would like to try and wonder how to test hypotheses for graphs.
How was the conference itself
AISTATS 2019 is a three-day conference in Okinawa. This is Japan, but Okinawa’s culture is closer to China. The main shopping street is reminiscent of tiny Miami, the streets are long cars, country music, and you step aside a bit - the jungle with snakes, mangrove trees turned up by typhoons. The local flavor creates the culture of the Ryukyu Kingdom, which was located on Okinawa, but first became a vassal and trading partner of China, and then was captured by the Japanese.
And also, apparently, weddings are often held in Okinawa, because there are a lot of wedding salons, and the conference was held at the Wedding Hall.
Scientists, authors of articles, listeners and speakers gathered more than 500 people. For three days you can have time to talk with almost everyone. Although the conference was held "at the edge of the world" - representatives from all over the world arrived. Despite the wide geography, it turned out that we all have similar interests. It came as a surprise to us, for example, that scientists from Australia solve the same Data Science problems using the same methods as we in our team. And, in fact, we live almost on opposite sides of the planet ... There were not so many participants from the industry: Google, Amazon, MTS and several other top companies.
There were representatives of Japanese sponsoring companies, who mostly watched and listened and, probably, hantels, despite the fact that “non-Japanese” work in Japan is very difficult.
Articles submitted to the conference by topics:

Everything else - in our next post. Do not miss!
Announcement:
Defending against Whitebox Adversarial Attacks via Randomized Discretization
Yuchen Zhang (Microsoft); Percy Liang (Stanford University)
→ Article
→ Code
')
Let's start with the article about protection against adversarial attacks in computer vision. These are targeted attacks on models, when the target of an attack is to cause a model to err, up to a predetermined result. Algorithms of computer vision can make mistakes even when changes in the original image are not essential for a person. The task is relevant, for example, for machine vision, which in good conditions recognizes road signs faster than a person, but works much worse when attacking.
Adversarial Attack visually
Attacks are Blackbox - when an attacker knows nothing about the algorithm, and the Whitebox is a reverse situation. To protect the models there are two main approaches. The first approach is to train the model on ordinary and “attacked” pictures - it is called adversarial training. This approach works well on small pictures like MNIST, but there are articles that show that it does not work well on large pictures, like ImageNet. The second type of protection does not require retraining of the model. It is enough just to pre-process the image before submission to the model. Conversion examples: JPEG compression, resizing. These methods require less computation, but now they only work against Blackbox attacks, since if the transformation is known, the opposite can be applied.
Method
In the article, the authors propose a method that does not require overtraining of the model and works for Whitebox attacks. The goal is to reduce the Kullback-Leibner distance between ordinary examples and “spoiled” using random transformation. It turns out that it is enough to add random noise, and then randomly sample colors. That is, the input of the algorithm is “degraded” image quality, but still sufficient for the algorithm to work. And due to chance, there is the potential to resist Whitebox attacks.
On the left - the original picture, in the middle - an example of clustering pixel colors in Lab space, on the right - a picture in several colors (For example, instead of 40 shades of blue - one)
results
This method was compared to the strongest attacks on the NIPS 2017 Adversarial Attacks & Defenses Competition, and it shows an average of better quality and does not retrain under the “attacker”.
Comparison of the strongest defense methods against the strongest attacks on the NIPS Competition
Comparison of accuracy of methods on MNIST with different image changes
Attenuating Bias in Word vectors
Sunipa Dev (University of Utah); Jeff Phillips (University of Utah)
→ Article
The “fashionable” talk was about Unbiased Word Vectors. In this case, Bias means bias by gender or nationality in the representations of words. Any regulators may oppose such “discrimination”, and therefore scientists from the University of Utah decided to explore the possibilities of “equalizing rights” for the NLP. In fact, why a man can not be "glamorous", and a woman "Data Scientist"?
Original - the result, which is obtained now, the rest - the results of the unbiased algorithm
The article discusses how to find such an offset. They decided that gender and nationality are well characterized by names. So, if you find the displacement by name and subtract it, then, probably, you can get rid of the bias of the algorithm.
An example of more "male" and "female" words:
Names to search for sex offsets:
Oddly enough, such a simple method works. The authors have trained the unbiased with respect to the floor Glove and laid out in Git.
What made you do this? Understanding black-box decisions with input inputs
Brandon Carter (MIT CSAIL); Jonas Mueller (Amazon Web Services); Siddhartha Jain (MIT CSAIL); David Gifford (MIT CSAIL)
→ Article
→ Code one and two
The following article describes the Sufficient Input Subset algorithm. SIS are minimal feature subsets for which the model will produce a certain result, even if all other features are zeroed. This is another way to somehow interpret the results of complex models. Works on both texts and pictures.
SIS search algorithm in detail:
Example of application on the text with reviews about beer:
Application example on MNIST:
Comparison of the methods of “interpretation” according to the Kullback-Leibler distance with respect to the “ideal” result:
Features are first ranked by influence on the model, and then split into disjoint subsets, starting with the most influential. It works by brute force, and on a marked-up dataset, the result is interpreted better than LIME. There is a convenient implementation of SIS search from Google Research.
Empirical Risk Minimization and Stochastic Gradient Descent for Relational Data
Victor Veitch (Columbia University); Morgane Austern (Columbia University); Wenda Zhou (Columbia University); David Blei (Columbia University); Peter Orbanz (Columbia University)
→ Article
→ Code
In the section on optimization, there was a report on Empirical Risk Minimization, where the authors investigated how to apply stochastic gradient descent on graphs. For example, when building a model on a given social network, you can only use fixed profile features (the number of subscribers), but then information about the relationships between profiles (who is subscribed to) is lost. In this case, the entire graph is often difficult to process - for example, it does not fit in memory. When such a situation occurs on tabular data, the model can be run on subsamples. And how to choose the analog subsample on the graph was not clear. The authors theoretically substantiated the possibility of using random subgraphs as an analogue of subsamples, and this turned out to be “Not crazy idea”. On Github, there are replicable examples from the article, including the Wikipedia example.
Category Embeddings on Wikipedia data, taking into account its graph structure, the highlighted articles are closest in subject to French Physicists:
→ Data Science for Networked Data
About discrete data graphs was another review report by Data Science for Networked Data from guest speaker Poling Loh (University of Wisconsin-Madison). The presentation addressed the topics of Statistical inference, Resource allocation, Local algorithms. In Statistical inference, for example, it was about how to understand what structure a graph has according to data on infectious diseases. It is proposed to use statistics on the number of connections between infected nodes - and a theorem is proved for the corresponding statistical test.
In general, the report is more interesting to watch, most likely, to those who are not engaged in graph models, but would like to try and wonder how to test hypotheses for graphs.
How was the conference itself
AISTATS 2019 is a three-day conference in Okinawa. This is Japan, but Okinawa’s culture is closer to China. The main shopping street is reminiscent of tiny Miami, the streets are long cars, country music, and you step aside a bit - the jungle with snakes, mangrove trees turned up by typhoons. The local flavor creates the culture of the Ryukyu Kingdom, which was located on Okinawa, but first became a vassal and trading partner of China, and then was captured by the Japanese.
And also, apparently, weddings are often held in Okinawa, because there are a lot of wedding salons, and the conference was held at the Wedding Hall.
Scientists, authors of articles, listeners and speakers gathered more than 500 people. For three days you can have time to talk with almost everyone. Although the conference was held "at the edge of the world" - representatives from all over the world arrived. Despite the wide geography, it turned out that we all have similar interests. It came as a surprise to us, for example, that scientists from Australia solve the same Data Science problems using the same methods as we in our team. And, in fact, we live almost on opposite sides of the planet ... There were not so many participants from the industry: Google, Amazon, MTS and several other top companies.
There were representatives of Japanese sponsoring companies, who mostly watched and listened and, probably, hantels, despite the fact that “non-Japanese” work in Japan is very difficult.
Articles submitted to the conference by topics:
Everything else - in our next post. Do not miss!
Announcement:
Source: https://habr.com/ru/post/455962/
All Articles