Double-page list rotation. Swift Edition
It's no secret that one of the favorite fun for a software developer is interviewing employers. We all do this from time to time and for completely different reasons. And the most obvious of them - the search for work - I think, not the most common. Attending an interview is a good way to keep yourself in shape, repeat forgotten basics and learn something new. And if successful, also increase self-reliance. We get bored, we expose ourselves to the status of "open to suggestions" in some "business" social network like "LinkedIn" - and the army of human resources managers are already attacking our inboxes.

In the process, while all this bedlam is created, we are faced with a lot of questions that, as they say on the other side of the implicitly-collapsed curtain, “ring a bell”, and their details disappeared behind the fog of war . They are often remembered only in the tests for algorithms and data structures (I personally did not have such) and the interviews themselves.
One of the most common questions at the interview for the post of programmer of any specialization is the lists. For example, single-linked lists. And the associated basic algorithms. For example, turn. And usually it happens something like this: “Well, how would you expand a simply linked list?” The main thing is to catch the applicant by surprise.
')
Actually, all this led me to write this short review for constant reminder and edification. So, joking aside, behold!
A linked list is one of the basic data structures . Each element (or node) of it consists of, in fact, stored data and references to neighboring elements. A singly linked list stores only the link to the next element in the structure, and a doubly linked list to the next and previous one. Such an organization of data allows them to be located in any area of memory (unlike, for example, an array , all the elements of which should be located in memory one after the other).
You can say a lot more about lists, of course: they can be circular (that is, the last element stores a link to the first one) or not (that is, there is no link to the last element). Lists can be typed, i.e. contain data of one type or not. And so on and so forth.
Better try to write some code. For example, somehow you can imagine a list node:
“Generic” is a type that is capable of storing any type of
The list itself is exhaustively identified only by the first node:
The first node is declared optional, because the list may well be empty.
The idea is, of course, that in the class it is necessary to implement all the necessary methods - insertion, deletion, access to nodes, etc., but we will deal with this some other time. At the same time, we will check whether the use of a
It's time to do business for which we are here today! And the most effective they can do in two ways. The first is a simple loop, from the first to the last node.
The cycle works with three variables, which before the beginning is assigned the value of the previous, current and next node. (At this point, the value of the previous node is, of course, empty.) The cycle begins by checking that the next node is not empty, and, if so, the body of the loop is executed. There is no magic in the loop: the current node referring to the next element is assigned a reference to the previous one (on the first iteration, the reference value is reset to zero, which corresponds to the state of affairs in the last node). Well, then the variables corresponding to the previous, current and next node are assigned new values. After exiting the loop, the current (ie, generally the last iterated) node is assigned a new value of the reference to the next node, since the exit from the cycle occurs just at the moment when the last node in the list becomes current.
In words, of course, it all sounds strange and incomprehensible, so it's better to see the code:
For verification, we will use the list of nodes whose payloads are simple integer identifiers. Create a list of ten items:
Everything seems to be fine, but you and I are people, not computers, and it would be good for us to get a visual proof of the correctness of the list created and the algorithm described above. Perhaps simple printing will be enough. To make the output readable, add the implementation of the
... And the corresponding list to display all nodes in order:
The string representation of our types will contain an address in memory and an integer identifier. With the help of such assistance, we organize the printing of the generated list of ten nodes:
Expand this list and print it again:
In the output you can see that the addresses in the memory of the list and the nodes have not changed, and the nodes of the list are printed in the reverse order. References to the next element of the node now point to the previous one (i.e., for example, the next element of the node “5” is no longer “6”, but “4”). And that means we did it!
The second known way to do this is based on recursion . To implement it, we will declare a function that accepts the first node of the list, and returns the “new” first node (which was the last before).
The parameter and the return value are optional, because inside this function it is called again and again on each subsequent node until it is empty (that is, until the end of the list is reached). Accordingly, it is necessary to check in the function body whether the node on which the function is called and whether the node has the following is empty. If not, the function returns the same that was passed to the argument.
Actually, I honestly tried to describe the full algorithm in words, but in the end I erased almost everything I wrote, because the result would be impossible to understand. To draw flowcharts and formally describe the steps of the algorithm - also in this case, I think, it does not make sense, because it will be more convenient for us to just read and interpret the code in “Swift” :
The algorithm itself is "wrapped" by the type of the list itself, for convenience of the call.
It looks shorter, but, in my opinion, more difficult to understand.
Let's call this method on the result of the previous reversal and print the new result:
From the output, it is clear that all the addresses in memory have not changed again, and the nodes now follow the original order (that is, they “unfolded” one more time). And that means we did it again!
If you look at the reversal methods carefully (or conduct an experiment with counting calls), you will notice that the cycle in the first case and the internal (recursive) method call in the second case occur one time less than the number of nodes in the list (in our case, nine time). You can also pay attention to what is happening around the loop in the first case - the same chain of assignments - and on the first, non-recursive, method call in the second case. It turns out that in both cases the “circle” is repeated exactly ten times for a list of ten nodes. Thus, we have linear complexity for both algorithms - O (n).
Generally speaking, the two described algorithms are considered the most effective for solving this problem. With regard to computational complexity, the ability to come up with an algorithm with a lower value is not possible: one way or another, it is necessary to “visit” each node to assign a new value for the link stored inside.
Another characteristic worth mentioning is “memory complexity”. Both proposed algorithms create a fixed number of new variables (three in the first case and one in the second). This means that the amount of allocated memory does not depend on the quantitative characteristics of the input data and is described by the constant function - O (1).
But, in fact, in the second case it is not. The danger of recursion is that additional memory is allocated for each recursive call on the stack . In our case, the recursion depth corresponds to the amount of input data.
And finally, I decided to experiment a little more: in a simple and primitive way, I measured the absolute execution time of the two methods for different amounts of input data. Like this:
And that's what I got (this is the "raw" data from the "Playground" ):
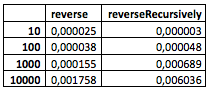
(Unfortunately, my computer has not mastered the larger values.)
What can be seen from the table? So far, nothing special. Although it is already noticeable that the recursive method behaves slightly worse with a relatively small number of nodes, but somewhere between 100 and 1000 starts to show itself better.
I also tried the same simple test inside a full-fledged “Xcode” project. The results were as follows:

Firstly, it is worth mentioning that the results were obtained after the activation of the “aggressive” optimization mode aimed at execution speed (
I tried to highlight a rather classical topic from the point of view of my currently favorite programming language and, I hope, you were curious to follow the progress as well as myself. And I am very glad if you managed to learn something new - then I definitely did not waste time on this article (instead of sitting and watching TV shows).
If someone has a desire to track my social activity, here is a link to my Twitter , where links to my new posts appear first and a little more.
In the process, while all this bedlam is created, we are faced with a lot of questions that, as they say on the other side of the implicitly-collapsed curtain, “ring a bell”, and their details disappeared behind the fog of war . They are often remembered only in the tests for algorithms and data structures (I personally did not have such) and the interviews themselves.
One of the most common questions at the interview for the post of programmer of any specialization is the lists. For example, single-linked lists. And the associated basic algorithms. For example, turn. And usually it happens something like this: “Well, how would you expand a simply linked list?” The main thing is to catch the applicant by surprise.
')
Actually, all this led me to write this short review for constant reminder and edification. So, joking aside, behold!
Singly linked list
A linked list is one of the basic data structures . Each element (or node) of it consists of, in fact, stored data and references to neighboring elements. A singly linked list stores only the link to the next element in the structure, and a doubly linked list to the next and previous one. Such an organization of data allows them to be located in any area of memory (unlike, for example, an array , all the elements of which should be located in memory one after the other).
You can say a lot more about lists, of course: they can be circular (that is, the last element stores a link to the first one) or not (that is, there is no link to the last element). Lists can be typed, i.e. contain data of one type or not. And so on and so forth.
Better try to write some code. For example, somehow you can imagine a list node:
final class Node<T> { let payload: T var nextNode: Node? init(payload: T, nextNode: Node? = nil) { self.payload = payload self.nextNode = nextNode } } “Generic” is a type that is capable of storing any type of
payload in the payload field.The list itself is exhaustively identified only by the first node:
final class SinglyLinkedList<T> { var firstNode: Node<T>? init(firstNode: Node<T>? = nil) { self.firstNode = firstNode } } The first node is declared optional, because the list may well be empty.
The idea is, of course, that in the class it is necessary to implement all the necessary methods - insertion, deletion, access to nodes, etc., but we will deal with this some other time. At the same time, we will check whether the use of a
struct (to which Apple is actively encouraged by our example) is a more advantageous choice, and recall the “Copy-on-write” approach.Spreading a single linked list
The first way. Cycle
It's time to do business for which we are here today! And the most effective they can do in two ways. The first is a simple loop, from the first to the last node.
The cycle works with three variables, which before the beginning is assigned the value of the previous, current and next node. (At this point, the value of the previous node is, of course, empty.) The cycle begins by checking that the next node is not empty, and, if so, the body of the loop is executed. There is no magic in the loop: the current node referring to the next element is assigned a reference to the previous one (on the first iteration, the reference value is reset to zero, which corresponds to the state of affairs in the last node). Well, then the variables corresponding to the previous, current and next node are assigned new values. After exiting the loop, the current (ie, generally the last iterated) node is assigned a new value of the reference to the next node, since the exit from the cycle occurs just at the moment when the last node in the list becomes current.
In words, of course, it all sounds strange and incomprehensible, so it's better to see the code:
extension SinglyLinkedList { func reverse() { var previousNode: Node<T>? = nil var currentNode = firstNode var nextNode = firstNode?.nextNode while nextNode != nil { currentNode?.nextNode = previousNode previousNode = currentNode currentNode = nextNode nextNode = currentNode?.nextNode } currentNode?.nextNode = previousNode firstNode = currentNode } } For verification, we will use the list of nodes whose payloads are simple integer identifiers. Create a list of ten items:
let node = Node(payload: 0) // T == Int let list = SinglyLinkedList(firstNode: node) var currentNode = node var nextNode: Node<Int> for id in 1..<10 { nextNode = Node(payload: id) currentNode.nextNode = nextNode currentNode = nextNode } Everything seems to be fine, but you and I are people, not computers, and it would be good for us to get a visual proof of the correctness of the list created and the algorithm described above. Perhaps simple printing will be enough. To make the output readable, add the implementation of the
CustomStringConvertible protocol CustomStringConvertible node with a numeric identifier: extension Node: CustomStringConvertible where T == Int { var description: String { let firstPart = """ Node \(Unmanaged.passUnretained(self).toOpaque()) has id \(payload) and """ if let nextNode = nextNode { return firstPart + " next node \(nextNode.payload)." } else { return firstPart + " no next node." } } } ... And the corresponding list to display all nodes in order:
extension SinglyLinkedList: CustomStringConvertible where T == Int { var description: String { var description = """ List \(Unmanaged.passUnretained(self).toOpaque()) """ if firstNode != nil { description += " has nodes:\n" var node = firstNode while node != nil { description += (node!.description + "\n") node = node!.nextNode } return description } else { return description + " has no nodes." } } } The string representation of our types will contain an address in memory and an integer identifier. With the help of such assistance, we organize the printing of the generated list of ten nodes:
print(String(describing: list)) /* List 0x00006000012e1a60 has nodes: Node 0x00006000012e2380 has id 0 and next node 1. Node 0x00006000012e8d40 has id 1 and next node 2. Node 0x00006000012e8d20 has id 2 and next node 3. Node 0x00006000012e8ce0 has id 3 and next node 4. Node 0x00006000012e8ae0 has id 4 and next node 5. Node 0x00006000012e89a0 has id 5 and next node 6. Node 0x00006000012e8900 has id 6 and next node 7. Node 0x00006000012e8a40 has id 7 and next node 8. Node 0x00006000012e8a60 has id 8 and next node 9. Node 0x00006000012e8820 has id 9 and no next node. */ Expand this list and print it again:
list.reverse() print(String(describing: list)) /* List 0x00006000012e1a60 has nodes: Node 0x00006000012e8820 has id 9 and next node 8. Node 0x00006000012e8a60 has id 8 and next node 7. Node 0x00006000012e8a40 has id 7 and next node 6. Node 0x00006000012e8900 has id 6 and next node 5. Node 0x00006000012e89a0 has id 5 and next node 4. Node 0x00006000012e8ae0 has id 4 and next node 3. Node 0x00006000012e8ce0 has id 3 and next node 2. Node 0x00006000012e8d20 has id 2 and next node 1. Node 0x00006000012e8d40 has id 1 and next node 0. Node 0x00006000012e2380 has id 0 and no next node. */ In the output you can see that the addresses in the memory of the list and the nodes have not changed, and the nodes of the list are printed in the reverse order. References to the next element of the node now point to the previous one (i.e., for example, the next element of the node “5” is no longer “6”, but “4”). And that means we did it!
The second way. Recursion
The second known way to do this is based on recursion . To implement it, we will declare a function that accepts the first node of the list, and returns the “new” first node (which was the last before).
The parameter and the return value are optional, because inside this function it is called again and again on each subsequent node until it is empty (that is, until the end of the list is reached). Accordingly, it is necessary to check in the function body whether the node on which the function is called and whether the node has the following is empty. If not, the function returns the same that was passed to the argument.
Actually, I honestly tried to describe the full algorithm in words, but in the end I erased almost everything I wrote, because the result would be impossible to understand. To draw flowcharts and formally describe the steps of the algorithm - also in this case, I think, it does not make sense, because it will be more convenient for us to just read and interpret the code in “Swift” :
extension SinglyLinkedList { func reverseRecursively() { func reverse(_ node: Node<T>?) -> Node<T>? { guard let head = node else { return node } if head.nextNode == nil { return head } let reversedHead = reverse(head.nextNode) head.nextNode?.nextNode = head head.nextNode = nil return reversedHead } firstNode = reverse(firstNode) } } The algorithm itself is "wrapped" by the type of the list itself, for convenience of the call.
It looks shorter, but, in my opinion, more difficult to understand.
Let's call this method on the result of the previous reversal and print the new result:
list.reverseRecursively() print(String(describing: list)) /* List 0x00006000012e1a60 has nodes: Node 0x00006000012e2380 has id 0 and next node 1. Node 0x00006000012e8d40 has id 1 and next node 2. Node 0x00006000012e8d20 has id 2 and next node 3. Node 0x00006000012e8ce0 has id 3 and next node 4. Node 0x00006000012e8ae0 has id 4 and next node 5. Node 0x00006000012e89a0 has id 5 and next node 6. Node 0x00006000012e8900 has id 6 and next node 7. Node 0x00006000012e8a40 has id 7 and next node 8. Node 0x00006000012e8a60 has id 8 and next node 9. Node 0x00006000012e8820 has id 9 and no next node. */ From the output, it is clear that all the addresses in memory have not changed again, and the nodes now follow the original order (that is, they “unfolded” one more time). And that means we did it again!
findings
If you look at the reversal methods carefully (or conduct an experiment with counting calls), you will notice that the cycle in the first case and the internal (recursive) method call in the second case occur one time less than the number of nodes in the list (in our case, nine time). You can also pay attention to what is happening around the loop in the first case - the same chain of assignments - and on the first, non-recursive, method call in the second case. It turns out that in both cases the “circle” is repeated exactly ten times for a list of ten nodes. Thus, we have linear complexity for both algorithms - O (n).
Generally speaking, the two described algorithms are considered the most effective for solving this problem. With regard to computational complexity, the ability to come up with an algorithm with a lower value is not possible: one way or another, it is necessary to “visit” each node to assign a new value for the link stored inside.
Another characteristic worth mentioning is “memory complexity”. Both proposed algorithms create a fixed number of new variables (three in the first case and one in the second). This means that the amount of allocated memory does not depend on the quantitative characteristics of the input data and is described by the constant function - O (1).
But, in fact, in the second case it is not. The danger of recursion is that additional memory is allocated for each recursive call on the stack . In our case, the recursion depth corresponds to the amount of input data.
And finally, I decided to experiment a little more: in a simple and primitive way, I measured the absolute execution time of the two methods for different amounts of input data. Like this:
let startDate = Date().timeIntervalSince1970 // list.reverse() / list.reverseRecursively() let finishDate = Date().timeIntervalSince1970 let runningTime = finishDate – startDate // Seconds And that's what I got (this is the "raw" data from the "Playground" ):
(Unfortunately, my computer has not mastered the larger values.)
What can be seen from the table? So far, nothing special. Although it is already noticeable that the recursive method behaves slightly worse with a relatively small number of nodes, but somewhere between 100 and 1000 starts to show itself better.
I also tried the same simple test inside a full-fledged “Xcode” project. The results were as follows:
Firstly, it is worth mentioning that the results were obtained after the activation of the “aggressive” optimization mode aimed at execution speed (
-Ofast ), which is partly why the numbers are so small. It is also interesting that in this case the recursive method showed itself a little better, on the contrary, only on very small sizes of input data, and already on the list of 100 nodes, the method loses. Out of 100,000, he made the program crash at all.Conclusion
I tried to highlight a rather classical topic from the point of view of my currently favorite programming language and, I hope, you were curious to follow the progress as well as myself. And I am very glad if you managed to learn something new - then I definitely did not waste time on this article (instead of sitting and watching TV shows).
If someone has a desire to track my social activity, here is a link to my Twitter , where links to my new posts appear first and a little more.
Source: https://habr.com/ru/post/455842/
All Articles