Neural Matching: how to adapt content for Google

The search engines are not very logic, it is a fact. But they are trying. And SEO-specialists are trying to answer - trying to achieve the utmost relevance of the pages, based on the guesses and experiments.
Recently, Google has pleased the new ranking factor - Neural Matching. We read that experts are writing about it, and collected some techniques that will help write more relevant texts for requests.
And by the way, NM is not LSI for you, everything is a bit more complicated.
In September 2018, Danny Sullivan tweeted that in the past few months, Google has been using the AI-method of neural matching (Neural Matching) to better link words with concepts. This algorithm influenced the results of issuing 30% of requests worldwide.

We were in no hurry to write about the new algorithm, waited for an explanation from Google and research in this area. But things are still there - mostly commentators show the same screenshots and tell about the transition from search by words to search by intent. And also refer to the Deep Relevance Matching Model (DRMM) .
Let's try to figure out what kind of animal this Neural Matching is and how to adapt the content on the site for it.
Neural Matching Work Examples
Danny Sullivan outlined what Neural Matching is. He gave an example of the issue for the query “why does my TV look strange”. The user enters such a request when he does not yet know what a soap opera effect is. But Google, thanks to a new algorithm, knows exactly what is needed:

')
In Russian, a similar story:

Another example. You met in the apartment "beautiful" insect and have no idea what his name is:

We go to Google, enter a set of signs and in the first position we get the relevant answer:

The introduction of Neural Matching is due to the fact that users do not always know what they are looking for and do not always correctly formulate requests. Danny Sullivan showed several such "wrong" requests:

The goal of Neural Matching is to determine the true search content (intent) and produce the correct results.

To determine the intent, not separate words are used, but entities and connections between them. See how it works - using the example of “getting drunk what to do” and “getting drunk at night” requests.
Each request contains the same entity - “got drunk”. But combining it with an entity “for the night” signals the search engine that the user means overeating. And the intoxication is most likely connected with the essence of “what to do”.

How does Google define intent - are semantics similar? The search engine compares how often the entities combined in the request are found side by side on the pages. In addition, statistics on requests are taken into account (users, when entering a request to get drunk at night, more often click on articles about overeating).
Another example. The user enters the phrase "put the window." This is just the “wrong” request that Danny Sullivan is talking about. Google understands that a man by “put” implies something different than a simple installation of windows, and displays in the TOP the correct results from his point of view:
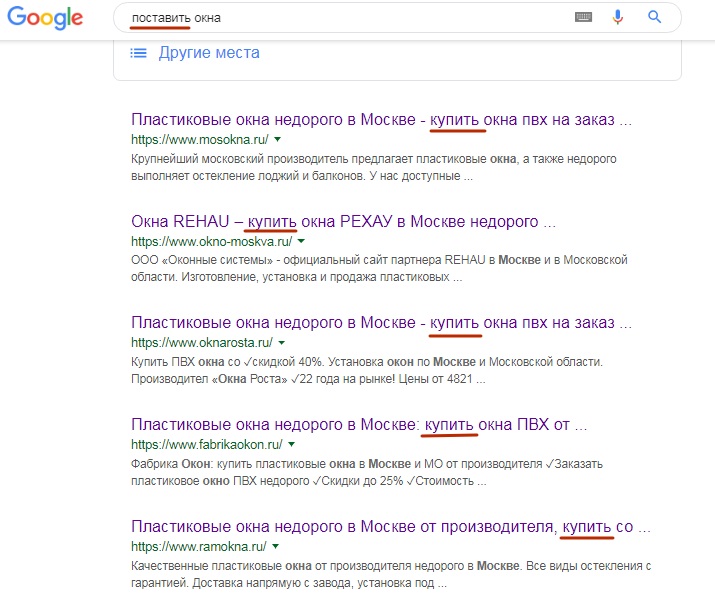
At the same time, only one page from TOP-6 contains the word “deliver” (meaning “supplier of windows”, and not “install windows by myself”). On the remaining pages of the TOP-6, there is not a single word “to deliver,” or even single-root words. Although below are mixed up the results like "How to put the windows yourself", etc.
This leads to a paradoxical at first glance conclusion: in order to occupy high positions in many words, it is not necessary to saturate texts with semantics similar to a search query. Content relevance is assessed by a set of entities (marker phrases) that are likely to satisfy the search content.
This changes the approach to writing SEO texts: before, the key point was the keys, now the needs of the audience.
Document Relevance Ranking and Neural Matching - how will this affect SEO?
Roger Montti in the article for the Search Engine Journal suggested that the Neural Matching algorithm could work based on the Document Relevance Ranking (DRR) method. The method is described in the article “ Deep Relevance Ranking using Enhanced Document-Query Interactions, ” published on the Google AI website.
The essence of the DRR method is that when determining the relevance of a document, its text is used exclusively. Other factors — links, anchors, mentions, on-page SEO — don't matter.
Are these links no longer needed at all? Not certainly in that way. Ranking by the described DRR method is part of the overall ranking algorithm. At the first stage, the issue is formed taking into account all the ranking factors (links, keys, “mobility”, geolocation, etc.). So the search engine eliminates low-grade content and identifies reputable sites. At the second stage, DRR enters the work - among the best results, it selects the most relevant (but takes into account only the text).
In practice, it may look like this. There are two sites: very reputable and young. The young site contains super-content, which has no analogues in the niche, saturated with details and specifics. But since the authoritative site leads more links, its page takes the first position, and the page of the young site - the tenth. And here comes the DRR - the search engine scans the texts and understands that the content of the young site is more meaningful than that of the authoritative. The consequence is the relocation of a young site to a higher position.
How to make content under Neural Matching
Whether Neural Matching works on the basis of DRR or not is not so important. It is important that the search intent here "steers". Not long "footcloths", not keyword density, not synonymizing.

Before you create content, decide:
- for whom he is (it is best to conduct research, create portraits of users and write for them);
- why is it needed (which task closes);
- what is in it what competitors do not have (what value it contributes).
To increase the relevance of texts, in addition to basic queries, use closely related entities. If the text is written by an expert, then such entities will most certainly be in the text. Another thing is when a copywriter’s TK is put in - in this case it is necessary to define entities and indicate them in the task.
Consider ways to collect entities on the example of the category of the online store "Gasoline Generators".
1. Search for questions / answers
To identify user needs, you can use forums, comments on articles in blogs, discussions in social networks. It all works. But it's easier to go to the Answers@Mail.ru (or Western analogue - Quora ), enter a query in the search, go through the questions and highlight the entities associated with the main keys.
On request, "petrol generators" mail.ru issues 1624 questions. Go through the list and select the entities that characterize the needs of the target audience.


After the selection of entities, we think which content is suitable for them. For example, gasoline consumption for 1 hour and how to use the generator (for welding, for the boiler, for lighting, etc.) should be indicated in the description of specific products. In the description of the “Gasoline Generators” heading you can briefly describe how gasoline differ from gas, inverter, etc. And problems with the work of generators are described in the article for the blog.
Handling questions in QA services is painstaking, but it allows you to highlight the real needs of the audience, which you could not guess.
You can try to simplify the work using the Answer The Public service . He collects questions, comparisons and various formulations that are found on the network with the entry of a given phrase.

The only drawback is the English language service. Translation of the search phrase partially solves the problem. But in the commercial segment it is worth remembering about the peculiarities of the markets (what Russians care about may be useless to Russians).
2. Parsing association phrases
Under the search results, the block “Together with ... often looking for” is displayed - here are collected the phrases that the search engine himself associates with the original phrase (“gasoline generators”).

The analysis of phrases-associations allows to identify related entities: 5 kW, 3 kW, 10 kW, inverter, 1 kW.
It remains to consider how to include them in the content. For example, in the description of the “gasoline generators” heading, it is worth mentioning for what purposes generators of different power (1, 3, 5, 10 kW) and type (inverter, conventional, etc.) are suitable.
If you have a lot of initial requests, manually build associations for a long time - use a parser .
3. Parsing search hints
Hints are another source for matching related entities.

We fill up the list of entities collected from associations: auto-start, diesel, 380 volts, silent. These are words that characterize user problems well.
There is also a parser for collecting hints.
In principle, the considered methods are enough to get an idea of the needs of the audience. But if you want to work out the semantics even more deeply, here are two optional ways.
4. Selection of quasi-synonyms
Quasi-synonyms (semantic associates) call words that are similar in meaning but not interchangeable in different contexts. For example, the words “generator” and “autogenerator” are synonymous in the text on automotive parts, but in the text on types of generators, they will not be.
Quasi-synonyms are determined on the basis of the frequency of their occurrence in the texts. To solve this problem there is a service RusVectōrēs (section "Related words"). Enter the word of interest, select all available models and parts of speech and start the search.

As a result, you will receive 10 of the most significant associates for each search model. It is not necessary to blindly use them when forming TK - there will be a lot of “garbage” (parsing associations based on search engine data is still preferable). Nevertheless, you can reveal interesting words. For example, we see that the words "gas generator", "inverter", "gas generator", "contactor", etc. are associated with the word "generator".
5. Parsing the texts of competitors
To identify the needs of the audience, this method is not the best. Firstly, it is not known when the content was created on competitors' sites (during this time, search preferences could shift). Secondly, there is no guarantee that competitors thoroughly analyzed the problems of the audience and created texts based on them.
On the other hand, if you use this method as an auxiliary method, then there is a chance to identify entities that you might have missed.
So, we enter in the search for the main query “gasoline generators”, copy the relevant texts from the sites in the TOP-10 and select the semantics with the help of Advego :

We supplement the list of relevant entities: 4-stroke, emergency, autonomous, uninterrupted, for summer cottage, for nature, etc.
Putting it all together and get the TZ, optimized for Neural Matching.
Terms of Reference: make Neural Matching, not LSI
After the relevant entities are collected, you must write the text. But it is not enough just to indicate the keys and the list of synonyms and related words in the TOR, as is usually done when ordering LSI texts .

Example TOR for LSI-text
On the basis of such TK - just with a list of words - sometimes we get quite strange texts.
A common practice for copywriters is to write a text, and only then enter the given words in it. This is easier, because you do not need to be interrupted to select and insert words in the process of composing a text. But such inserts in hindsight can break - and often break - the logic and style of the text.
The text under Neural Matching is about users and their needs, not about keys and plus-words. Therefore, purely marketing pieces appear in TK: consumer descriptions and their motives. Keys and plus-words fade into the background - they are used as markers, and not as obligatory elements. Their place is occupied by the information needs of the audience.

Example TK under Neural Matching
Such TK allows the author to clearly understand for whom the text, why and under what circumstances it will be read. Such TK not only throws out the words to be used, but gives directions on what to write in order to use these words.
Neural Matching, when optimizing pages for search, shifts the focus from purely pure mechanics to marketing. In fact, this trend is not observed the first year. Just Neural Matching is another step towards search engine optimization with a human face.
Optimizing content for Neural Matching takes time and head work. It is much easier to throw keys from SJ into TZ, compare the plus-words and tell the copywriter: “Write for people”. But in the conditions of the development of AI-search, this approach will be less and less effective.
Source: https://habr.com/ru/post/455575/
All Articles