Datatable Python Package Overview
"Five exabytes of information created by mankind since the birth of civilization until 2003, but the same amount is now being created every two days." Eric Schmidt

Datatable is a Python library for efficient multi-threaded data processing. Datatable supports datasets that do not fit in memory.
If you are writing to R, then you are probably already using the
')
The
What is the use of all this for those who are engaged in data analysis in Python? The thing is that there is a

Modern machine learning systems need to process monstrous amounts of data and generate many signs. This is necessary to build as accurate models as possible. The
This toolkit is very similar to pandas , but it is more focused on providing high speed data processing and support for large data sets. The developers of the
On MacOS,
On Linux, installation is performed from binary distributions:
Currently,
Details on installing
The code that will be used in this material can be found in this GitHub repository or here at mybinder.org.
The data set that we are going to experiment with here is taken from Kaggle ( Lending Club Loan Data Dataset ). This set consists of complete data on all loans issued in 2007-2015, including the current status of the loan (Current, Late, Fully Paid, etc.) and the latest information about the payment. The file consists of 2.26 million lines and 145 columns. The size of this data set is ideal for demonstrating the capabilities of the
Let's load the data into the
The above function
In addition, the
Now let's see how long it takes
You can see that
An existing
Let's try to convert an existing
It seems that reading a file into a
Consider the basic properties of the
Here, the

The first 10 lines of the Frame object from datatable
Header colors indicate data type. Lines are marked with red, integers are green, and floating point numbers are blue.
Calculating summary statistics in
Calculate the average value of the columns using
As you can see, in
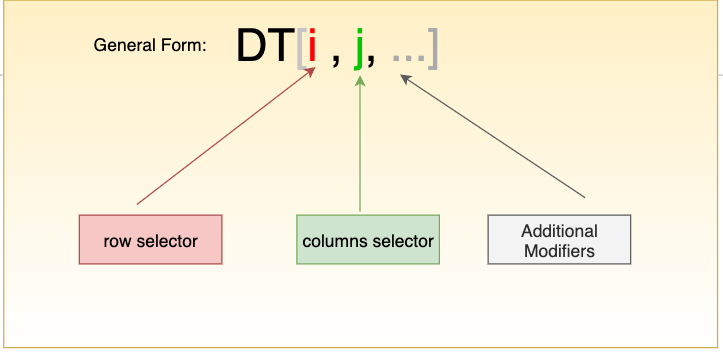
Work with data in datatable using square brackets
In mathematics, when working with matrices, constructions of the form
The following code selects all rows from the

Select all rows in a funded_amnt column
Here is how to select the first 5 rows and 3 columns:

Select the first 5 rows and 3 columns
Sort the data set by the selected column:
Note the significant difference in time required to sort
Here's how to remove a column named
Datatable, like
Here you can see the use of the
The filtering syntax is similar to the grouping syntax. Filter those
The contents of the
You can read about other
The
Dear readers! Do you plan to use


Datatable is a Python library for efficient multi-threaded data processing. Datatable supports datasets that do not fit in memory.
If you are writing to R, then you are probably already using the
data.table package. Data.table is an extension of the R-package data.frame . In addition, those who use R for fast aggregation of large data sets (this is, in particular, about 100 GB of data in RAM) cannot do without this package.')
The
data.table package for R is very flexible and productive. It is easy and convenient to use it, programs in which it is used are written fairly quickly. This package is widely known in the circles of R-programmers. It is loaded more than 400 thousand times a month, it is used in almost 650 CRAN and Bioconductor-packages ( source ).What is the use of all this for those who are engaged in data analysis in Python? The thing is that there is a
datatable Python package, which is an analogue of data.table from the world R. The datatable package datatable clearly focused on processing large data sets. It is distinguished by high performance - both when working with data that fits completely in RAM, and when working with data that is larger than the amount of available RAM. It supports multithreaded data processing. In general, the datatable package may well be called the younger brother of data.table .Datatable
Modern machine learning systems need to process monstrous amounts of data and generate many signs. This is necessary to build as accurate models as possible. The
datatable Python module was created to solve this problem. This is a set of tools for performing operations with large (up to 100 GB) volumes of data on a single computer at the highest possible speed. datatable is sponsored by H2O.ai , and the first user of the package is Driverless.ai .This toolkit is very similar to pandas , but it is more focused on providing high speed data processing and support for large data sets. The developers of the
datatable package also strive to make it convenient for users to work with it. It is, in particular, a powerful API and well-thought-out error messages. In this article we will talk about how to use datatable , and how it looks in comparison with pandas when processing large data sets.Installation
On MacOS,
datatable can be easily installed using pip : pip install datatable On Linux, installation is performed from binary distributions:
# Python 3.5 pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp35-cp35m-linux_x86_64.whl # Python 3.6 pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp36-cp36m-linux_x86_64.whl Currently,
datatable does not work under Windows, but now work is being done in this direction, so Windows support is only a matter of time.Details on installing
datatable can be found here .The code that will be used in this material can be found in this GitHub repository or here at mybinder.org.
Reading data
The data set that we are going to experiment with here is taken from Kaggle ( Lending Club Loan Data Dataset ). This set consists of complete data on all loans issued in 2007-2015, including the current status of the loan (Current, Late, Fully Paid, etc.) and the latest information about the payment. The file consists of 2.26 million lines and 145 columns. The size of this data set is ideal for demonstrating the capabilities of the
datatable library. # import numpy as np import pandas as pd import datatable as dt Let's load the data into the
Frame object. The basic unit of analysis in datatable is Frame . This is the same as a DataFrame from a pandas or SQL table. Namely, we are talking about data organized in the form of a two-dimensional array in which rows and columns can be distinguished.▍Datload using datatable
%%time datatable_df = dt.fread("data.csv") ____________________________________________________________________ CPU times: user 30 s, sys: 3.39 s, total: 33.4 s Wall time: 23.6 s The above function
fread() is a powerful and very fast mechanism. It can automatically detect and process parameters for the vast majority of text files, load data from .ZIP archives and from Excel files, retrieve data from URLs and do much more.In addition, the
datatable parser has the following features:- It can automatically detect delimiters, headers, column types, character escaping rules, and so on.
- He can read data from various sources. Among them - the file system, URL, command shell, raw text, archives.
- It can perform multi-threaded data reading for maximum performance.
- It displays a progress indicator when reading large files.
- It can read files that are compliant and not compliant with RFC4180 .
▍ Downloading data using pandas
Now let's see how long it takes
pandas to read the same file. %%time pandas_df= pd.read_csv("data.csv") ___________________________________________________________ CPU times: user 47.5 s, sys: 12.1 s, total: 59.6 s Wall time: 1min 4s You can see that
datatable clearly faster than pandas when reading large data sets. Pandas in our experiment takes more than a minute, and the time required for datatable is measured in seconds.Frame Object Conversion
An existing
Frame object of the datatable package can be converted to a DataFrame numpy or pandas object. This is done like this: numpy_df = datatable_df.to_numpy() pandas_df = datatable_df.to_pandas() Let's try to convert an existing
Frame datatable object to a DataFrame pandas object and see how long it will take. %%time datatable_pandas = datatable_df.to_pandas() ___________________________________________________________________ CPU times: user 17.1 s, sys: 4 s, total: 21.1 s Wall time: 21.4 s It seems that reading a file into a
Frame datatable object and then converting this object into a DataFrame pandas object takes less time than loading data into a DataFrame using pandas . Therefore, it is possible, if you plan to process large amounts of data using pandas , it will be better to load them with datatable tools, and then convert them into a DataFrame . type(datatable_pandas) ___________________________________________________________________ pandas.core.frame.DataFrame Main properties of the Frame object
Consider the basic properties of the
Frame object from datatable . They are very similar to similar properties of the DataFrame object from pandas : print(datatable_df.shape) # ( , ) print(datatable_df.names[:5]) # 5 print(datatable_df.stypes[:5]) # 5 ______________________________________________________________ (2260668, 145) ('id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv') (stype.bool8, stype.bool8, stype.int32, stype.int32, stype.float64) Here, the
head() method is also available, which n first n lines: datatable_df.head(10) The first 10 lines of the Frame object from datatable
Header colors indicate data type. Lines are marked with red, integers are green, and floating point numbers are blue.
Summary Statistics
Calculating summary statistics in
pandas is an operation that requires a lot of memory. In the case of datatable this is not the case. Here are the commands you can use to calculate various indicators in datatable : datatable_df.sum() datatable_df.nunique() datatable_df.sd() datatable_df.max() datatable_df.mode() datatable_df.min() datatable_df.nmodal() datatable_df.mean() Calculate the average value of the columns using
datatable and pandas and analyze the time required to perform this operation.▍ Finding average using datatable
%%time datatable_df.mean() _______________________________________________________________ CPU times: user 5.11 s, sys: 51.8 ms, total: 5.16 s Wall time: 1.43 s ▍ Finding average using pandas
pandas_df.mean() __________________________________________________________________ Throws memory error. As you can see, in
pandas we could not get a result - a memory error was issued.Data manipulation
Frame and DataFrame are data structures representing tables. In datatable , square brackets are used to perform data manipulations. This is reminiscent of how they work with ordinary matrices, but here you can use additional features when using square brackets.Work with data in datatable using square brackets
In mathematics, when working with matrices, constructions of the form
DT[i, j] also used. Similar structures can be found in C, C ++ and R, in pandas and numpy packages, as well as in many other technologies. Consider performing common data manipulations in datatable .▍ Forming row or column samples
The following code selects all rows from the
funded_amnt column: datatable_df[:,'funded_amnt'] Select all rows in a funded_amnt column
Here is how to select the first 5 rows and 3 columns:
datatable_df[:5,:3] Select the first 5 rows and 3 columns
▍Sort data using datatable
Sort the data set by the selected column:
%%time datatable_df.sort('funded_amnt_inv') _________________________________________________________________ CPU times: user 534 ms, sys: 67.9 ms, total: 602 ms Wall time: 179 ms ▍Sorting data using pandas
%%time pandas_df.sort_values(by = 'funded_amnt_inv') ___________________________________________________________________ CPU times: user 8.76 s, sys: 2.87 s, total: 11.6 s Wall time: 12.4 s Note the significant difference in time required to sort
datatable and pandas .▍Removing rows and columns
Here's how to remove a column named
member_id : del datatable_df[:, 'member_id'] Grouping
Datatable, like
pandas , supports the ability to group data. Let's look at how to get the average for the funded_amound column, the data in which are grouped by the grade column.▍Grouping data using datatable
%%time for i in range(100): datatable_df[:, dt.sum(dt.f.funded_amnt), dt.by(dt.f.grade)] ____________________________________________________________________ CPU times: user 6.41 s, sys: 1.34 s, total: 7.76 s Wall time: 2.42 s Here you can see the use of the
.f construct. This is the so-called frame proxy, a simple mechanism that allows you to refer to the Frame object with which some actions are currently being performed. In our case, dt.f is the same as datatable_df .▍Grouping data using pandas
%%time for i in range(100): pandas_df.groupby("grade")["funded_amnt"].sum() ____________________________________________________________________ CPU times: user 12.9 s, sys: 859 ms, total: 13.7 s Wall time: 13.9 s String filtering
The filtering syntax is similar to the grouping syntax. Filter those
loan_amnt lines for which the value of loan_amnt greater than funded_amnt . datatable_df[dt.f.loan_amnt>dt.f.funded_amnt,"loan_amnt"] Saving a Frame Object
The contents of the
Frame object can be written to a CSV file, which allows you to use data in the future. This is done like this: datatable_df.to_csv('output.csv') You can read about other
datatable methods for working with data here .Results
The
datatable Python module is definitely faster than most pandas . It is also a real find for those who need to process very large data sets. So far, the only minus datatable in comparison with pandas is the amount of functionality. However, active work is underway on datatable , so it is quite possible that in the future datatable will surpass pandas in all directions.Dear readers! Do you plan to use
datatable package in your projects?Source: https://habr.com/ru/post/455507/
All Articles