Haxe 4: What's new?
I bring to your attention the translation of the report by Alexander Kuzmenko (since April of this year, he officially works as the developer of the Haxe compiler) about the changes in the language of Haxe since the release of Haxe 3.4.

More than two and a half years have passed since the release of Haxe 3.4. During this time, 7 patch releases have been released, 5 preview releases of Haxe 4 and 2 release candidates Haxe 4. It was a long way to the new version and it is almost ready (it remains to solve about 20 problems ).

Alexander thanked the Haxe community for reports on bugs, for the desire to participate in the development of the language. Thanks to the haxe-evolution project in Haxe 4 there will appear such things as:
- inline markup
- inlining functions at call location
- arrow functions

Also within the framework of this project, there are discussions of such possible innovations as: Promises , polymorphic this and default type parameters.
Then Alexander spoke about the changes in the syntax of the language .

The first is a new syntax for describing function types (function type syntax). The old syntax was a bit strange.
Haxe is a multi-paradigm programming language, it has always had support for functions of the first class, but the syntax for describing the types of functions was inherited from the functional language (and differs from that adopted in other paradigms). And programmers familiar with functional programming expect functions with this syntax to support automatic currying. But in Haxe it is not.
The main disadvantage of the old syntax, according to Alexander, is the inability to determine the names of the arguments, which is why one has to write long annotations with the description of the arguments.
But now we have a new syntax for describing the types of functions (which, by the way, was added to the language as part of the haxe-evolution initiative), where there is such an opportunity (although it is not necessary to do it, but recommended). The new syntax is easier to read and can even be considered part of the code documentation.
Another drawback of the old syntax for describing function types was its some illogicality - the need to specify the type of function arguments even when the function takes no arguments: Void->Void (this function takes no arguments and returns nothing).
In the new syntax, this is implemented more elegantly: ()->Void

The second is arrow functions or lambda expressions — a brief form of describing anonymous functions. The community has been asking to add them to the language for a long time, and finally it happened!
In such functions, instead of the return keyword, the sequence of characters -> used -> (hence the syntax name "arrow function").
In the new syntax, it remains possible to specify the types of arguments (since the type auto-derivation system cannot always do it the way the programmer wishes, for example, the compiler may decide to use Float instead of Int ).
The only limitation of the new syntax is the inability to explicitly specify the return type. If necessary, you have the choice to either use the old syntax or use the check-type syntax in the function body, which tells the compiler the return type.

The switch functions do not have a special representation in the syntactic tree; they are processed just like ordinary anonymous functions. The sequence -> is replaced by the keyword return .

The third change - final now become a keyword (in Haxe 3 final was one of the meta tags embedded in the compiler).
If you apply it to a class, it will prevent inheritance from it, the same applies to interfaces. And applying the final qualifier to a class method will forbid its redefinition in child classes.
However, in Haxe there was a way to get around the restrictions imposed by the final keyword - for this you can use the meta tag @:hack (but still it should be done only when absolutely necessary).
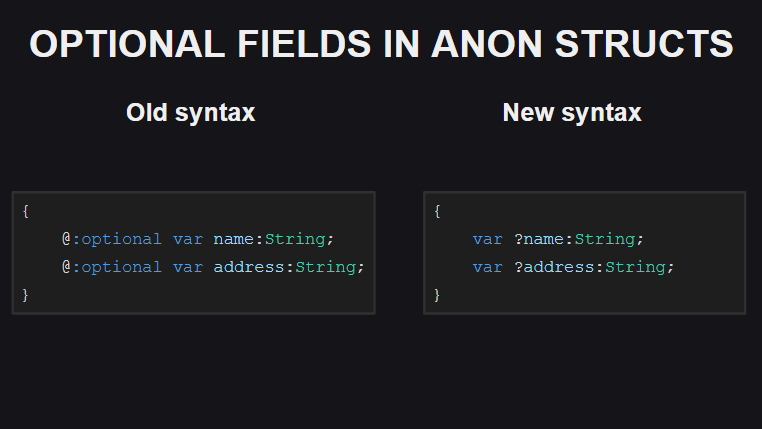
The fourth change is the way of declaring optional fields in anonymous structures. Previously, for this, a meta tag @:optional ; now it is enough to add a question mark in front of the field name.

Fifth, abstract enumerations have become a full-fledged member of the type family in Haxe, and instead of the meta tag @:enum , the keyword @:enum now used to declare them.
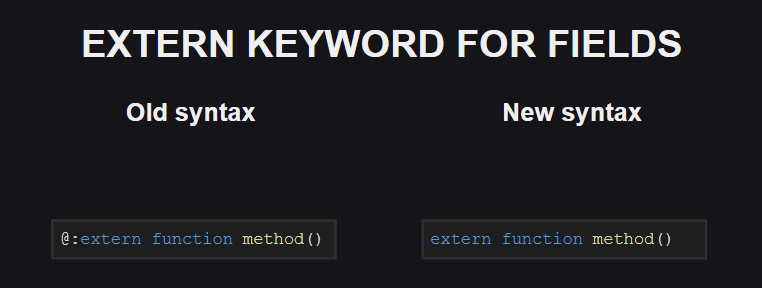
A similar change was made to the meta tag @:extern .

The seventh is a new syntax for type union (type intersection), which better reflects the essence of the expansion of structures.
The same syntax is used to restrict the types of parameters (type parameters constraints), it more accurately conveys the constraints imposed on the type. For a person unfamiliar with Haxe, the old syntax MyClass<T:(Type1, Type2)> could be perceived as a requirement for the type of the parameter T be either Type1 or Type2 . The new syntax clearly tells us that T must be both Type1 and Type2 .
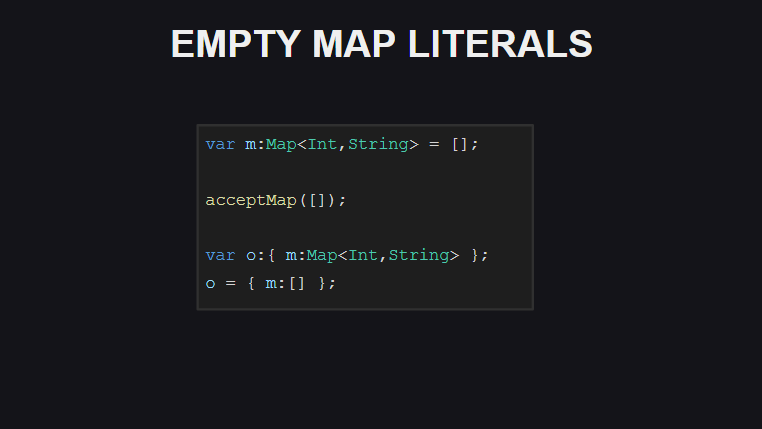
The eighth is the ability to use [] to declare an empty Map container (however, if you do not explicitly specify the variable type, the compiler will print the type as an array for this case).
Having talked about the changes in syntax, we proceed to the description of new functions in the language .
Let's start with the new key-value iterators
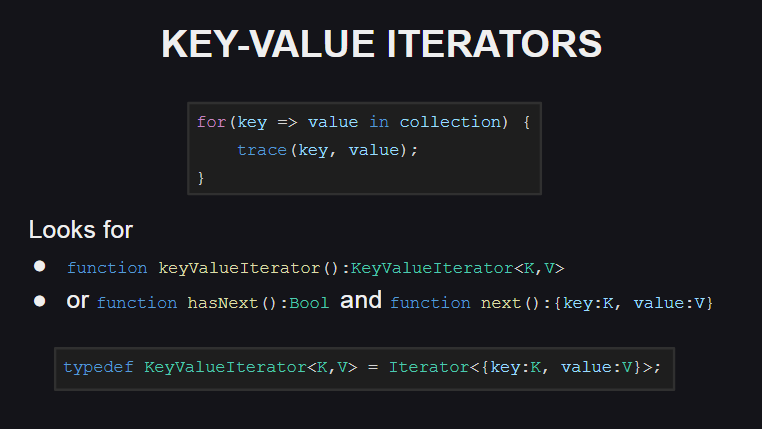
A new syntax has been added for their use.
To support such iterators, either the keyValueIterator():KeyValueIterator<K, V> method or the hasNext():Bool and next():{key:K, value:V} methods must be implemented in the type. In this case, the type KeyValueIterator<K, V> is a synonym for a regular iterator with an anonymous Iterator<{key:K, value:V}> structure Iterator<{key:K, value:V}> .
Key-value iterators are implemented for some types from the Haxe standard library ( String , Map , DynamicAccess ), and work is underway to implement them for arrays.
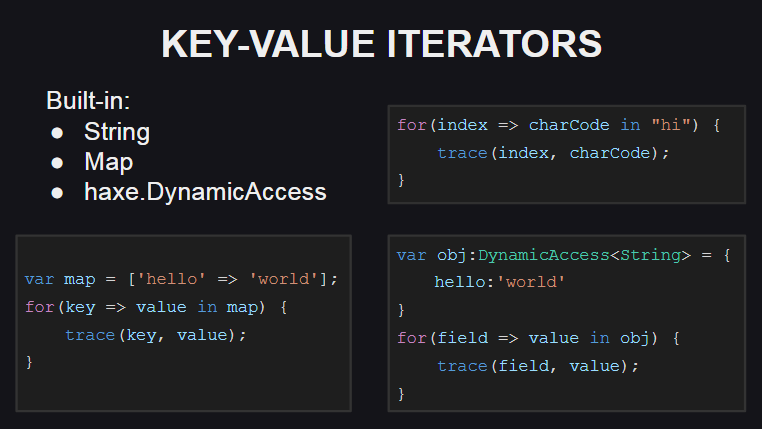
For strings, the index of the character in the string is used as the key, and the value is the character code at the given index (if you need the character itself, you can use the String.fromCharCode() method).
For the Map container, the new iterator works just like the old iteration method, that is, it receives an array of keys in the container and passes through it, asking for values for each of the keys.
For DynamicAccess (wrapper for anonymous objects), the iterator works using reflection (to get a list of object fields using the Reflect.fields() method and to get field values by their names using the Reflect.field() method).

Haxe 4 uses a completely new macro interpreter "eval". Simon Krazewski, the author of the interpreter, described it in some detail in the official Haxe blog , as well as in his last year’s progress report .
The main changes in the interpreter:
- it is several times faster than the old macro interpreter (4 times on average)
- supports interactive debugging (previously, only output to the console could be used for macros)
- it is used for the compiler to work in interpreter mode (neko was previously used for this. By the way, eval also surpasses neko in speed).

Unicode support for all platforms (with the exception of neko) is one of the biggest changes in Haxe 4. Simon talked about this in detail last year . But here is a brief overview of the current state of Unicode support in Haxe:
- for Lua, PHP, Python and eval (macro interpreter) full Unicode support is implemented (UTF8 encoding)
- for other platforms (JavaScript, C #, Java, Flash, HashLink and C ++), the encoding is UTF16.
Thus, the lines in Haxe work in the same way for characters in the main multilingual plane , but for characters outside this plane (for example, for emoji), the code for working with strings can produce different results depending on the platform (but it is still better than the situation we have in Haxe 3, when each platform had its own behavior).

For Unicode-encoded strings (both in UTF8 and UTF16), special iterators are added to the Haxe standard library that work equally on ALL platforms for all characters (both within and outside the main multilingual plane):
haxe.iterators.StringIteratorUnicode haxe.iterators.StringKeyValueIteratorUnicode 
Due to the fact that the implementation of strings varies from platform to platform, it is necessary to keep in mind some of the nuances of their work. In UTF16, each character occupies 2 bytes, thanks to which access to a character in a string by index works quickly, but only within the main multilingual plane. On the other hand, all characters are supported in UTF8, but this is achieved at the cost of a slow search for a character in a string (since characters can occupy a different number of bytes in memory, accessing a character by index requires each time to pass through the string from its very beginning). Therefore, if you work with large strings in Lua and PHP, you need to keep in mind that access to an arbitrary character works rather slowly (also on these platforms, the length of the string is calculated again every time).
However, although full Unicode support is declared for Python, this restriction does not apply to it due to the fact that the strings in it are implemented somewhat differently: for characters within the main multilingual plane, it uses UTF16 encoding, and for “wider” characters (3 and more bytes) Python uses UTF32.
Additional optimizations are implemented for the eval macro interpreter: the string “knows” whether there are any Unicode characters in it. If there are no such characters in it, the string is interpreted as consisting of ASCII characters (where each character occupies 1 byte). Sequential index access in eval is also optimized: the position of the last character accessed is cached in the string. So, if you first refer to the 10th character in the string, then when you next access the 20th character, eval will search for it not from the very beginning of the line, but from the 10th. In addition, the length of the string in eval is cached, that is, it is calculated only on the first request.
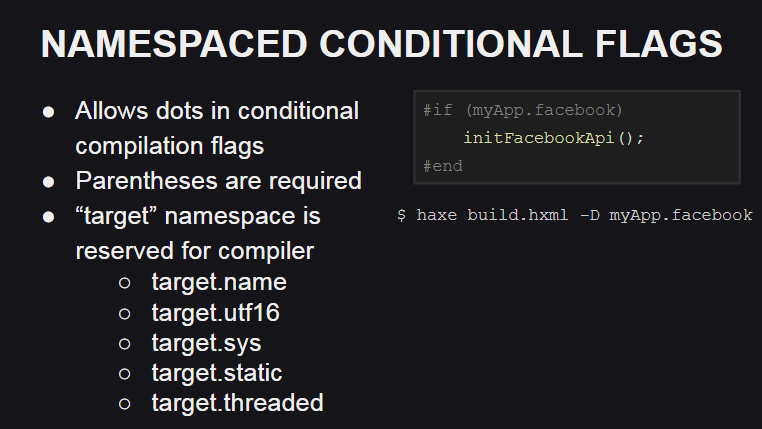
Haxe 4 introduced support for namespaces for compilation flags, which can be useful, for example, for organizing code when writing custom libraries.
A reserved namespace for the compilation flags, target , also appeared, which is used by the compiler to describe the target platform and its behavior:
target.name- platform name (js, cpp, php, etc.)target.utf16- says that unicode support is implemented using UTF16target.sys- indicates whether classes from the sys package are available (for example, for working with the file system)target.static- indicates whether the platform is static (on static platforms, the basic typesInt,FloatandBoolcannot havenullvalues)target.threaded- indicates whether the platform supports multithreading
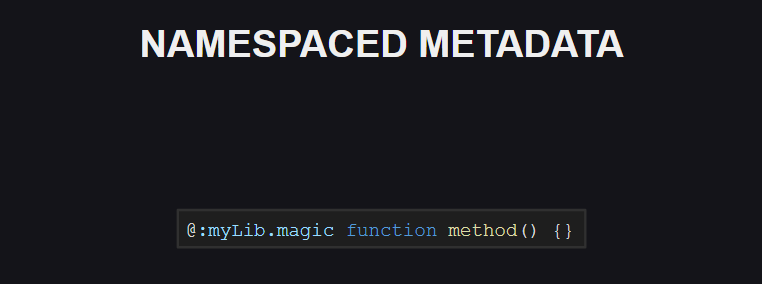
Similarly, namespace support has appeared for meta tags. So far, there are no reserved namespaces for meta tags in the language, but this may change in the future.

The ReadOnlyArray type ReadOnlyArray added to the Haxe standard library - an abstract above a regular array, in which only methods are available for reading data from an array.

Another innovation in the language is the final fields and local variables.
If the declaration of a class field or a local variable instead of the var keyword to use final , this will mean that the field or variable cannot be reassigned (if you try to do this, the compiler will generate an error). But at the same time, its state can be changed, so the final field or variable is not a constant.
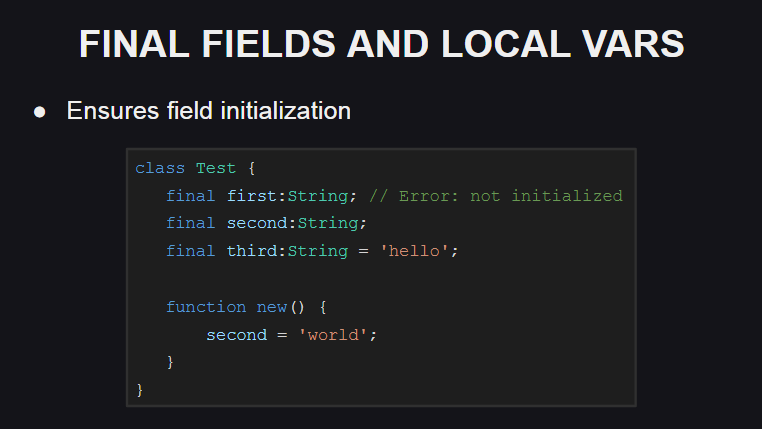
The values of the final fields must be initialized either when they are declared or in the constructor, otherwise the compiler will generate an error.

HashLink - a new platform with its own virtual machine, created specifically for Haxe. HashLink supports the so-called "Dual compilation" (Dual compilation) - the code can be compiled either into bytecode (which is very fast, speeds up the process of debugging developed applications), or in C-code (which is characterized by increased performance). Nicholas HashLink dedicated several posts to the Haxe blog , and also spoke about him at last year ’s Seattle conference . HashLink technology is used in such popular games like Dead Cells and Northgard.

Another new interesting feature of Haxe 4 is Null safety (Null safety), which is still in the experimental stage (due to false positives and insufficient checks for code safety).
What is null security? If your function does not explicitly declare that it can accept null as parameter values, then when you try to pass null into it, the compiler will generate an appropriate error. In addition, for parameters of functions that can take null as a value, the compiler will require you to write additional code to check and handle such cases.
This functionality is turned off by default, but it does not affect the speed of code execution (if it is still enabled), since the described checks are performed only at the compilation stage. It can be turned on for the entire code, or it can be gradually turned on for individual fields, classes and packages (thus ensuring a gradual transition to more secure code). To do this, you can use special meta tags and macros.
Modes in which Null-security can work: Strict (most strict), Loose (default mode) and Off (used to disable checks for individual packages and types).

For the function on the slide, the check for Null-security is enabled. We see that this function has an optional parameter s , that is, we can pass null to it as a parameter value. When trying to compile code with this function, the compiler will generate a number of errors:
- when trying to access any field of the object
s(since it can benull) - when trying to assign a variable to str, which, as we can see, should not be
null(otherwise we had to declare it not as aString, but as aNull<String>) - when trying to return an object
sfrom a function (since the function should not returnnull)
How to fix these errors?
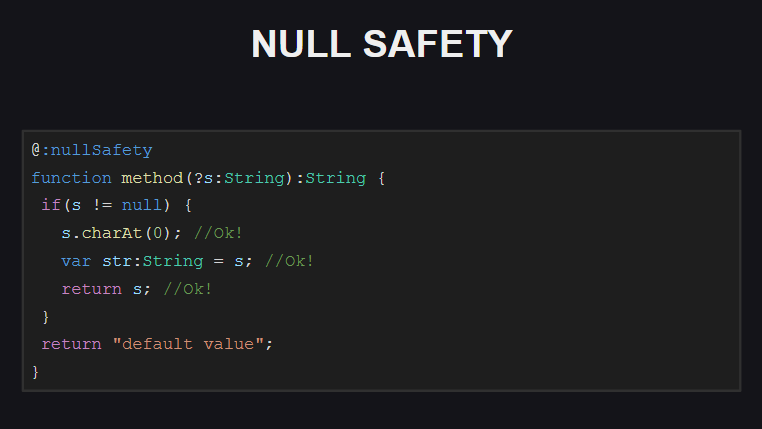
We just have to add a check for null to the code (inside the block with a check for null compiler "knows" that s cannot be null and can be safely worked with), and also make sure that the function does not return null !

In addition, when performing checks on Null-security, the compiler takes into account the order of program execution. For example, if after checking the value of the s parameter for null to terminate the execution of the function (or throw an exception), the compiler will "know" that after such a test the s parameter can no longer be null and that it can be safely operated.

If you enable Strict-mode checks for Null-security for the compiler, it will require additional checks for null in those cases when between the initial check of the value for null and the attempt to access the field of the object, some code could be set that could set it to null .
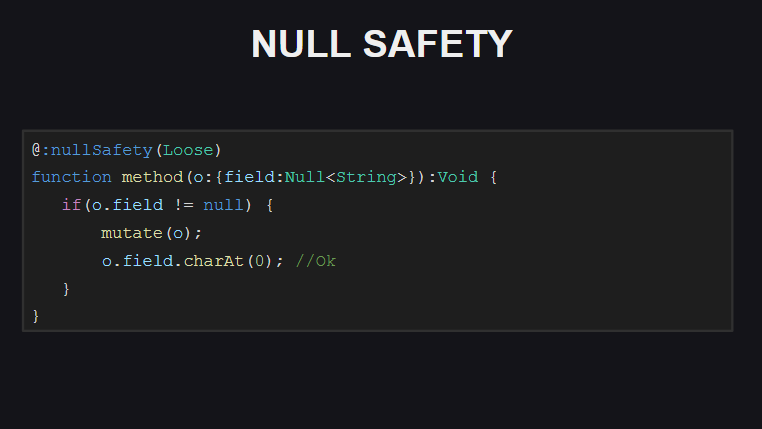
In Loose mode (used by default), the compiler does not require such checks (by the way, this behavior is also used by default in TypeScript).

Also, with the included checks for null-security, the compiler checks whether the fields in the classes are initialized (either immediately upon their declaration or in the constructor). Otherwise, the compiler will generate errors when trying to pass an object of this class, as well as when trying to call methods on such objects, until all the fields of the object are initialized. Such checks can be disabled for individual fields of the class by marking them with a meta tag @:nullSafety(Off)
Alexander spoke more about Null-security in Haxe last October .

Haxe 4 now has the ability to generate ES6 classes for JavaScript, it is enabled using the js-es=6 compilation flag.
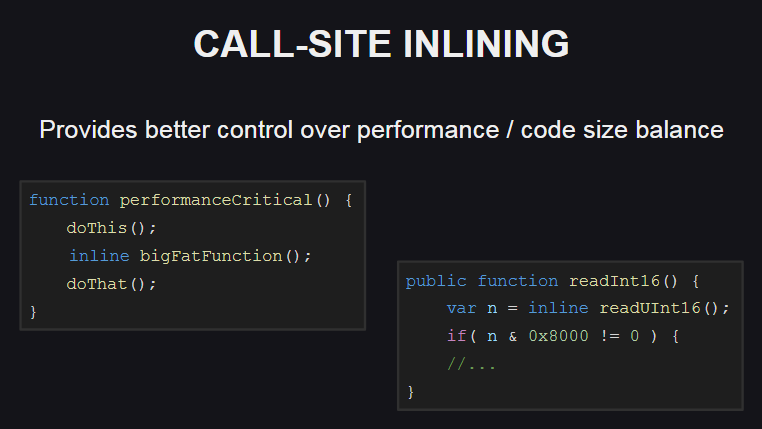
Call-site inlining provides more options for controlling the balance between code performance and its size. This functionality is also used in the standard Haxe library.
What is she like? It allows you to embed the function body (using the inline ) only in those places where it is required to ensure high performance (for example, if you need to call a sufficiently volumetric method in a loop), while the function body is not embedded in other places. As a result, the size of the generated code will be slightly increased.
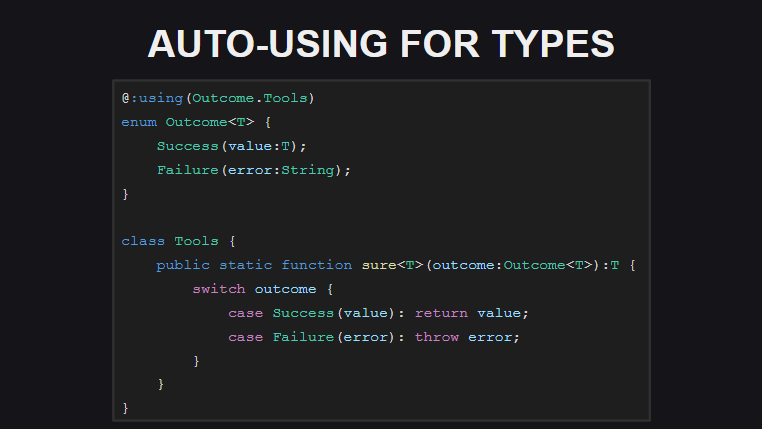
Auto-using (automatic extensions for types) means that now for types you can declare static extensions at the place of type declaration. In this case, there is no need to use the using type; every time using type; in each module where the type and extension methods are used. At the moment, this type of extensions is implemented only for transfers, but in the final release (and in nightly builds) it can be used not only for transfers.

In Haxe 4, it will be possible to override for the abstract types the operator of access to the fields of the object (only for fields that do not exist in the type). For this purpose, methods marked with the meta tag @:op(ab) .

Embedded markup is another experimental feature in Hax. The code of the built-in markup is not processed by the compiler as an xml document - the compiler sees it as a string wrapped in a meta tag @:markup . .
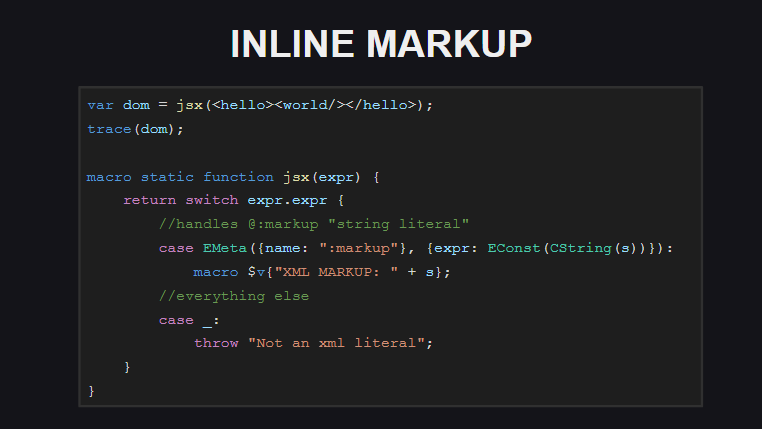
-, - @:markup , .

( untyped ). . , , Js.build() - @:markup , <js> , js-.

Haxe 4 - - , — .

. , . , Int , , C.
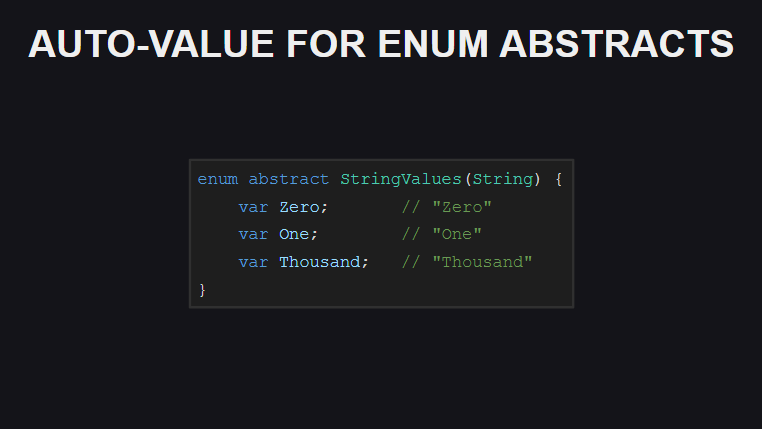
— .
:

JVM- JDK, Java-. . .

, async / await yield . ( C#, ). Haxe github.

Haxe , . ( ) . , .

API . , , API .
Haxe 4 !
')
Source: https://habr.com/ru/post/455389/
All Articles