Hardware acceleration of deep neural networks: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP and other letters

On May 14, when Trump prepared to unleash all the dogs at Huawei, I peacefully sat in Shenzhen at the Huawei STW 2019 - a large conference for 1000 participants - which included reports by Philip Wong , vice president of TSMC research on the prospects for non-von Neumann computing architectures, and Heng Liao, Huawei Fellow, Chief Scientist Huawei 2012 Lab, on the development of a new architecture of tensor processors and neuroprocessors. TSMC, if you know, makes neural accelerators for Apple and Huawei using 7 nm technology (which few people own ), and Huawei is ready to compete with Google and NVIDIA for neuroprocessors.
Google in China is banned, I did not bother to put a VPN on a tablet, so I
')
Last year alone, more than $ 3 billion was invested in the topic. Google has long declared neural networks to be a strategic area, actively building their hardware and software support. NVIDIA, feeling that the throne was staggering, invests fantastic efforts in libraries of accelerating neural networks and new hardware. Intel in 2016 spent 0.8 billion on the purchase of two companies engaged in hardware acceleration of neural networks. And this is despite the fact that the main purchases have not yet begun, and the number of players has exceeded fifty and is growing rapidly.

TPU, VPU, IPU, DPU, NPU, RPU, NNP - what does all this mean and who will win? Let's try to figure it out. Who cares - Wellcome under the cat!
Disclaimer: The author had to completely rewrite the video processing algorithms for effective implementation on ASIC, and clients did prototyping on FPGA, so there is an idea of the depth of the difference of architectures. However, the author has not worked directly with iron lately. But I anticipate that I will have to delve into it.
Background problems
The number of required calculations is growing rapidly, people would gladly take more layers, more options for architecture, more actively play with hyper parameters, but ... run into performance. At the same time, for example, with the growth of the performance of good old processors - big problems. All good things come to an end: Moore's law, as you know, dries up and the growth rate of processor performance drops:

Calculations of the real performance of SPECint integer operations compared to VAX11-780 , hereafter often the logarithmic scale
If from the mid-80s to the mid-2000s — in the blessed years of the heyday of computers — growth was at an average speed of 52% per year, in recent years it has decreased to 3% per year. And this is a problem (the translation of the recent article by the patriarch of the theme of John Hennessy about the problems and prospects of modern architectures was on Habré ).
There are many reasons, for example, the frequency of processors has ceased to grow:
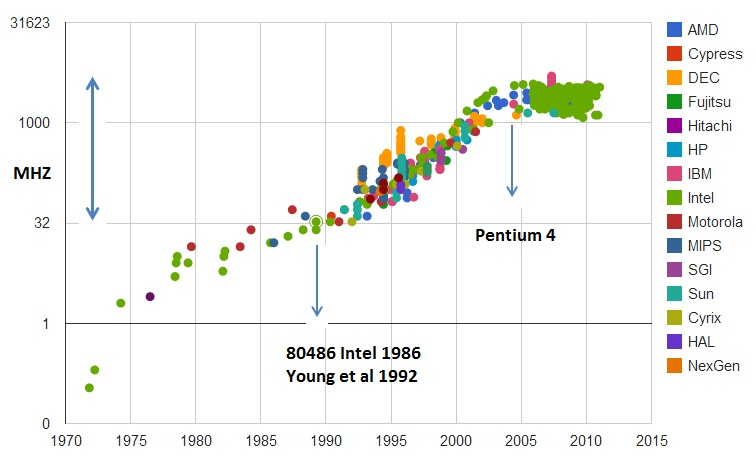
It became more difficult to reduce the size of transistors. The last attack that drastically reduces performance (including the performance of already released CPUs) is (drum roll) ... that's right, security. Meltdown , Specter and other vulnerabilities cause enormous damage to the growth rate of the computational power of the CPU ( an example of disabling hyperthreading (!)). The topic has become popular, and new vulnerabilities of this kind are found almost monthly . And this is a nightmare, because it hurts the performance.
At the same time, the development of many algorithms is firmly tied to the growth of processor power that has become habitual. For example, many researchers today do not worry about the speed of algorithms - something will be invented. And it would be okay when training - the networks become large and “heavy” to use. This is especially clearly seen in the video, for which most approaches, in principle, are not applicable at high speed. And they make sense often only in real time. This is also a problem.
Similarly, new compression standards are being developed, which imply an increase in decoder power. And if the power of the processors will not grow? The older generation remembers how in the 2000s there were problems to play high-resolution video in the fresh then H.264 on older computers. Yes, the quality was better with a smaller size, but on fast scenes the picture hung up or the sound was torn. I have to communicate with the developers of the new VVC / H.266 (release is planned for the next year). They do not envy.
So, what is the coming age preparing for us in the light of a decrease in the growth rate of processor performance in the application to neural networks?
CPU
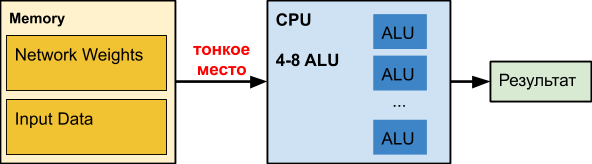
Regular CPU is a great number crusher that has been refined over the decades. Alas, for other tasks.
When we work with neural networks, especially deep ones, our network can take hundreds of megabytes. For example, the memory requirements for object detection networks are:
| model | input size | param memory | feature memory |
| rfcn-res50-pascal | 600 x 850 | 122 MB | 1 GB |
| rfcn-res101-pascal | 600 x 850 | 194 MB | 2 GB |
| ssd-pascal-vggvd-300 | 300 x 300 | 100 MB | 116 MB |
| ssd-pascal-vggvd-512 | 512 x 512 | 104 MB | 337 MB |
| ssd-pascal-mobilenet-ft | 300 x 300 | 22 MB | 37 MB |
| faster-rcnn-vggvd-pascal | 600 x 850 | 523 MB | 600 MB |
In our experience, deep neural network coefficients for processing semi - transparent boundaries can take 150–200 MB. Colleagues in the neural network for determining age and sex size coefficients of the order of 50 MB. And when optimizing for the low-precision mobile version, it is about 25 MB (float32⇒float16).
In this case, the delay schedule for accessing the memory, depending on the size of the data, is distributed approximately as follows (horizontal scale is logarithmic):
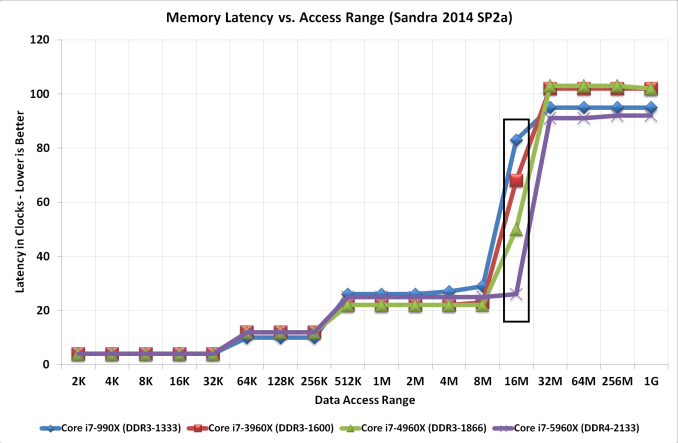
Those. with an increase in data volume of more than 16 MB, the delay increases 50 or more times, which is fatal to performance. In fact, most of the CPU time when working with deep neural networks is
For adherents of neural networks on the CPU
Even Intel OpenVINO, according to our internal tests, loses the implementation of the framework on matrix multiplication + NNPACK on many network architectures (especially on simple architectures where bandwidth is important for realtime processing of data in single-threaded mode). This scenario is relevant for various classifiers of objects in the image (where the neural network needs to be run a large number of times - 50–100 by the number of objects in the image) and the overhead of starting OpenVINO becomes unreasonably large.
Pros:
- “Everyone has it”, and usually idle, i.e. Relatively low input cost of calculations and implementation.
- There are some non-CV networks that fit the CPU well, colleagues call, for example, Wide & Deep and GNMT.
Minus:
- CPU is inefficient when working with deep neural networks (when the number of layers of the network and the size of the input data are large), everything works painfully slowly.
GPU

The topic is well known, so we will quickly denote the main thing. In the case of neural networks, the GPU has a significant performance advantage on massively parallel tasks:
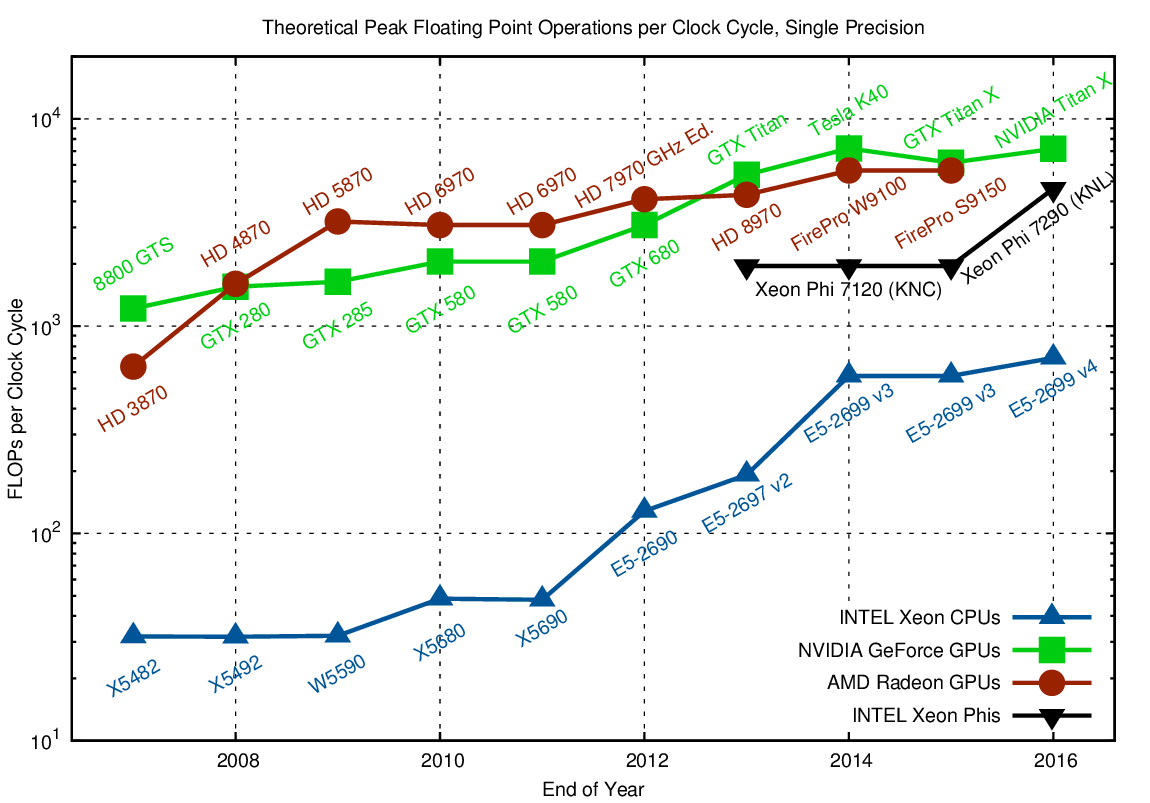
Notice how the 72-core Xeon Phi 7290 is annealed, while the “blue” is also the server-side Xeon, i.e. Intel does not give up so easily, as will be lower. But more importantly, the memory of video cards was originally designed for about 5 times higher performance. In neural networks, data calculations are extremely simple. Several elementary actions, and we need new data. As a result, the speed of access to data is critical for the efficient operation of a neural network. The high-speed on-board memory of the GPU and a more flexible cache management system than on the CPU solve this problem:
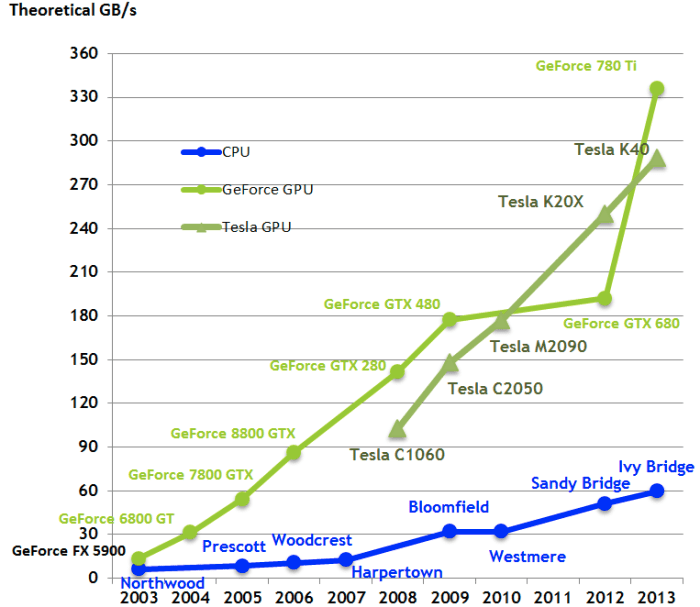
For several years, Tim Detmers has supported an interesting review entitled “Which GPU (s) for Deep Learning: “ What kind of GPU is better for deep learning ... ”). It is clear that Tesla and Titans rule for learning, although the difference in architectures can cause interesting bursts, for example, in the case of recurrent neural networks (and the leader in general TPU, we note for the future):
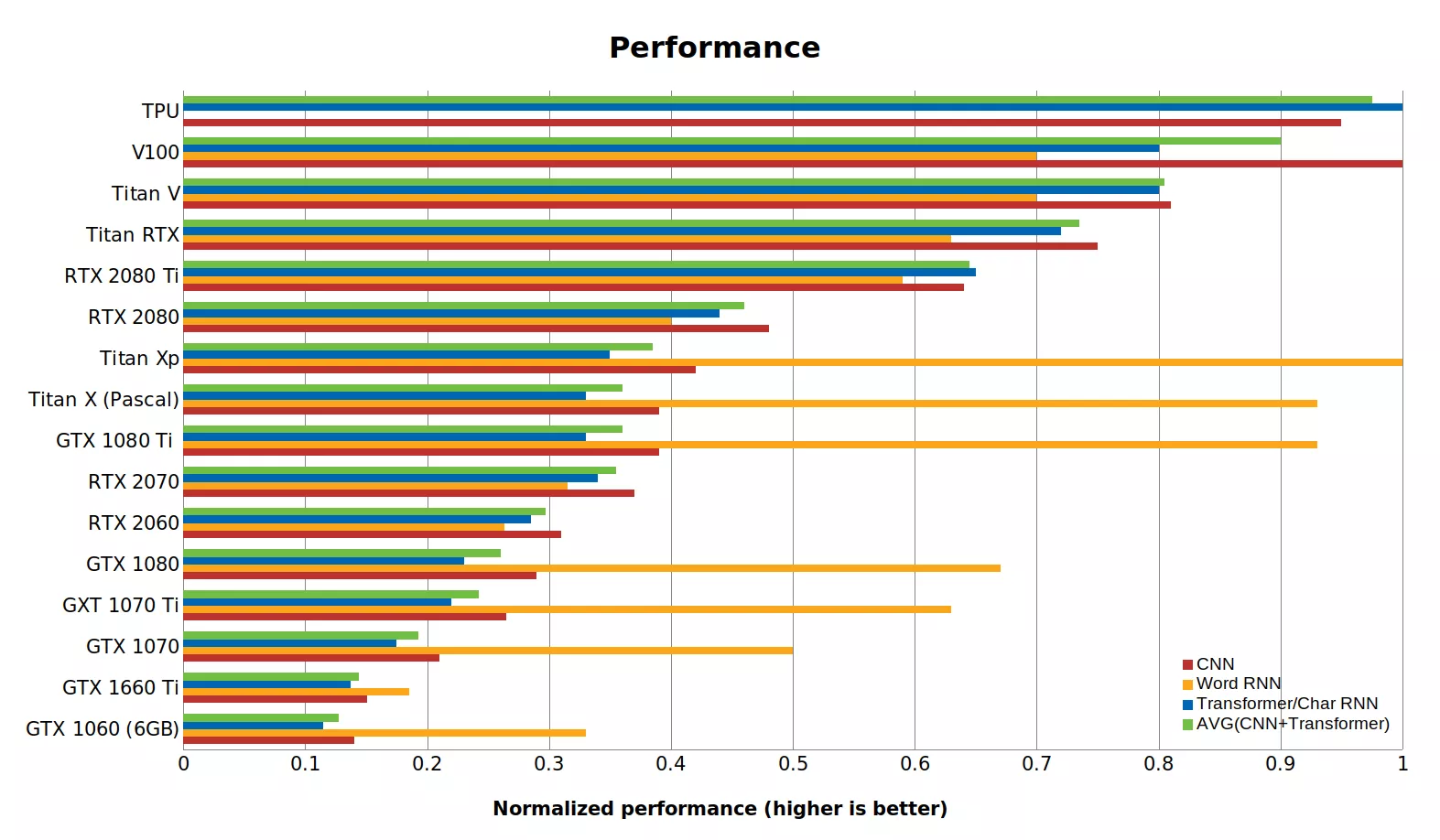
However, there is a very useful performance chart for a dollar, where RTX is on a horse (most likely due to their Tensor cores ), if you have enough memory, of course:
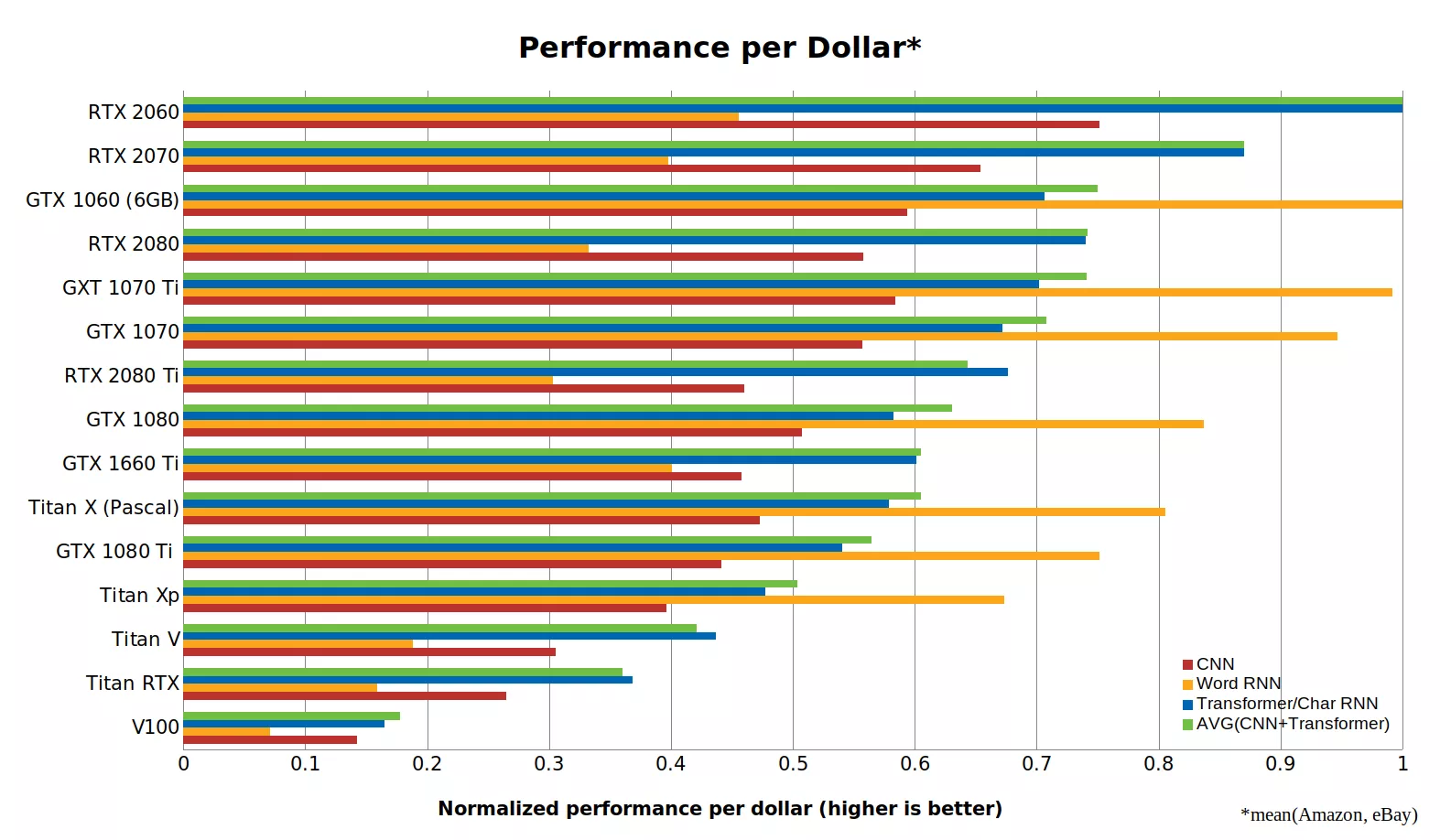
Of course, the cost of computing is important. The second place of the first rating and the last of the second - Tesla V100 is sold for 700 thousand rubles, like 10 "ordinary" computers (+ an expensive Infiniband switch, if you want to train on several nodes). True V100 and works for ten. People are willing to overpay for a noticeable acceleration of learning.
Total, summarized!
Pros:
- The cardinal - 10–100 times faster work compared to the CPU.
- Extremely effective for learning (and somewhat less effective for use).
Minus:
- The cost of top-end video cards (with enough memory to train large networks) exceeds the cost of the rest of the computer ...
Fpga

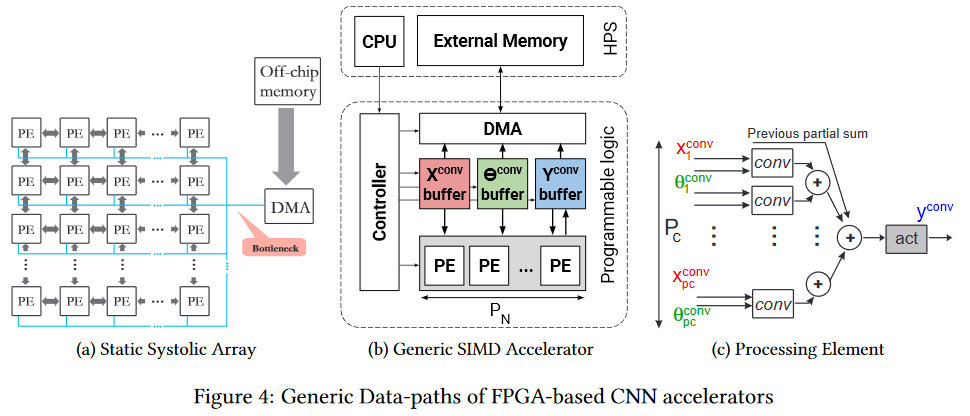
FPGA is more interesting. This is a network of several millions of programmable blocks that we can also programmatically interconnect. The network and the blocks look something like this (the thin place is Bottleneck, pay attention, again before the chip's memory, but everything is easier, which will be discussed below):
Naturally, it makes sense to use FPGA already at the stage of applying a neural network (in most cases there is not enough memory for training). Moreover, the topic of implementation on the FPGA is now beginning to actively develop. For example, here is the fpgaConvNet framework , which helps to dramatically speed up the use of CNN on FPGAs and at the same time reduce power consumption.
The key advantage of the FPGA is that we can store the network directly in cells, i.e. a thin place in the form of overloaded 25 times per second (for video) in the same direction hundreds of megabytes of the same data magically disappears. This allows for a lower clock frequency and no caches, instead of a decrease in performance, to obtain a noticeable increase. Yes, and dramatically reduce
Intel was actively involved in the process, releasing the OpenVINO Toolkit in open source last year, which includes the Deep Learning Deployment Toolkit (part of OpenCV ). And the performance on FPGA on different grids looks quite interesting, and the advantage of the FPGA over the GPU (albeit the integrated GPU from Intel) is very significant:

What particularly warms the soul of the author - FPS are compared, i.e. frames per second is the most practical metric for video. Given that Intel bought Altera , the second-largest player on the FPGA market in 2015, the graph provides good food for thought.
And, obviously, the entrance barrier to such architectures is higher, so some time must pass in order for convenient tools to appear that effectively take into account fundamentally different FPGA architecture. But you should not underestimate the potential of technology. It pains a lot of thin places she embroider.
Finally, we emphasize that programming an FPGA is a separate art. As such, the program is not executed there, and all calculations are done in terms of data flows, flow delays (which affects performance) and used gates (which are always lacking). Therefore, to start programming effectively, you need to thoroughly change your own firmware (in the neural network that is between the ears). With good efficiency, it does not work for everyone. However, new frameworks will soon hide from the researchers an external difference.
Pros:
- Potentially, faster network performance.
- The power consumption is noticeably lower compared to the CPU and GPU (this is especially important for mobile solutions).
Minuses:
- Mostly help with the acceleration of performance, to train on them, unlike the GPU, is noticeably less convenient.
- More complex programming compared to previous versions.
- Noticeably less specialists.
ASIC

Next comes ASIC - short for Application-Specific Integrated Circuit, i.e. integrated circuit under our task. For example, implementing the neural network put into iron. However, most compute nodes can work in parallel. In fact, only data dependencies and uneven computations at different levels of the network can prevent us from constantly using all the ALUs running.
Perhaps the greatest advertisement of ASIC among the general public in recent years has been mining cryptocurrency mining. At the very beginning, the mining on the CPU was quite profitable, later I had to buy GPUs, then FPGAs, and then specialized ASICs, since the people (read the market) were ripe for orders in which their production became profitable.
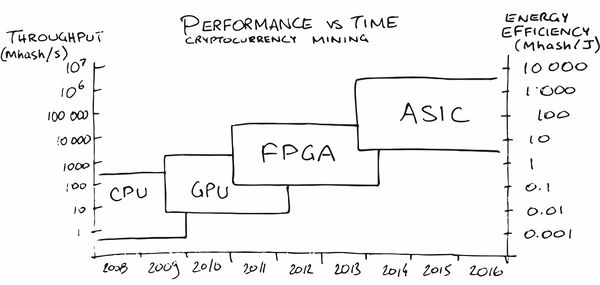
In our area, too, services have appeared (naturally!) That help us to put a neural network on iron with the necessary characteristics for power consumption, FPS and price. Magically, agree!
BUT! We lose network customizability. And, of course, people think about it too. For example, here’s an article with the saying title “ Can a reconfigurable architecture beat ASIC as a CNN accelerator? ” (“Can a configurable architecture beat ASIC like a CNN accelerator?”). There is enough work on this topic, because the question is not idle. The main disadvantage of ASIC is that after we have driven the network into iron, it becomes difficult for us to change it. They are most beneficial for cases where an already well-established network is needed by millions of chips with low power consumption and high performance. And this situation is gradually emerging in the market of auto pilots, for example. Or in surveillance cameras. Or in the cameras of robot vacuum cleaners. Or in the chambers of the home refrigerator. Or in the camera coffee makers.

It is important that in mass production the chip is cheap, works fast and consumes a minimum of energy.
Pros:
- The lowest cost of the chip compared with all previous decisions.
- The lowest power consumption per unit of operation.
- Quite a high speed of work (including, if desired, a record).
Minuses:
- The possibilities of updating the network and logic are very limited.
- The highest development cost compared to all previous solutions.
- Using ASIC is cost effective mainly for large runs.
TPU
Recall that when working with networks there are two tasks - training (training) and execution (inference). If FPGA / ASIC are primarily aimed at speeding up execution (including some kind of fixed network), then TPU (Tensor Processing Unit or tensor processors) is either a hardware learning acceleration or relatively universal acceleration of an arbitrary network. The name is beautiful, you see, although in fact, rank 2 c tensors with Mixed Multiply Unit (MXU) connected to high-speed memory (High-Bandwidth Memory - HBM) are used. Below is the TPU Google 2nd and 3rd version architecture diagram:
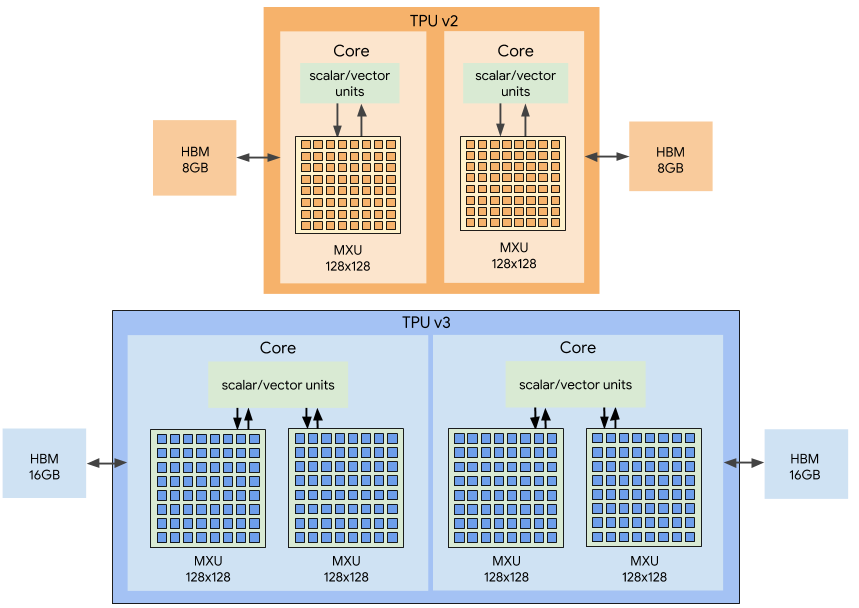
TPU Google
In general, TPU made the advertisement for Google, revealing the internal development in 2017:
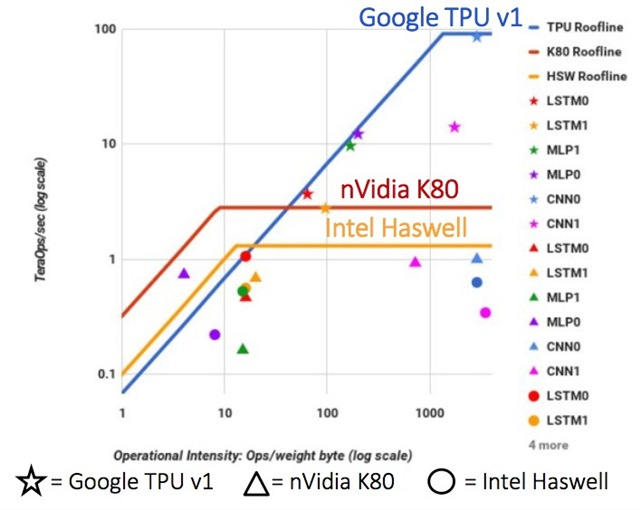
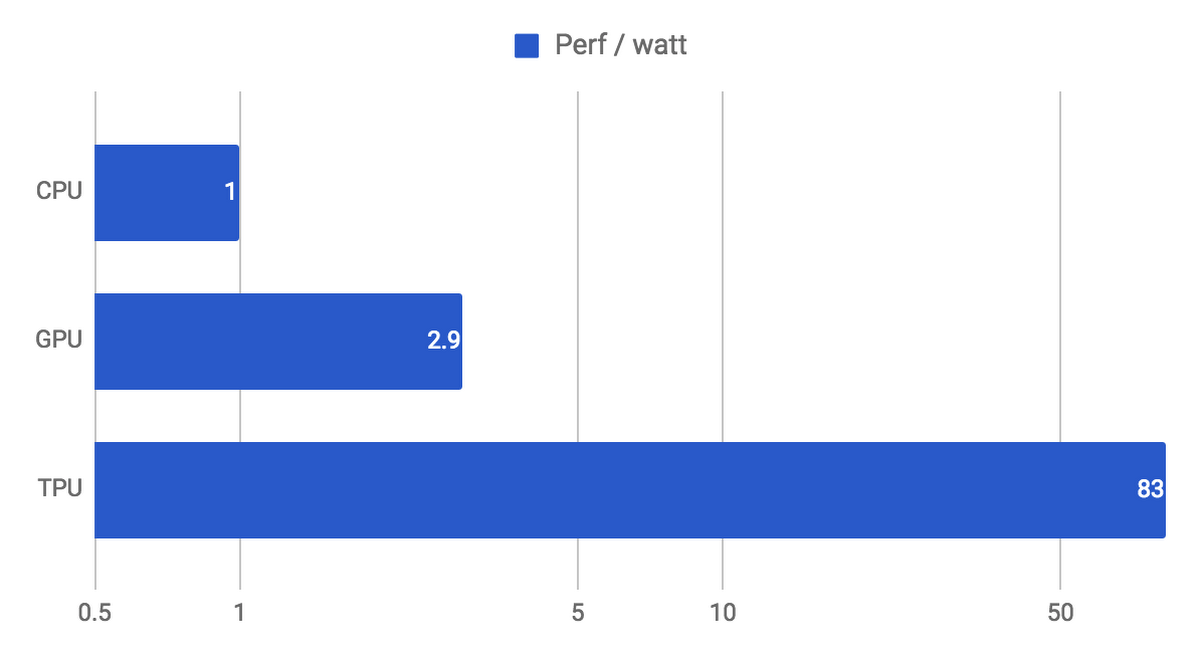
They began preliminary work on specialized processors for neural networks with their words back in 2006, in 2013 they created a project with good funding, and in 2015 they started working with the first chips that greatly helped neural networks for the Google Translate cloud service and not only. And this was, we emphasize, the acceleration of network performance . An important advantage for data centers is two orders of magnitude higher TPU energy efficiency compared to CPU (graph for TPU v1):
Also, as a rule, compared to a GPU, performance of the network performance is 10–30 times better:
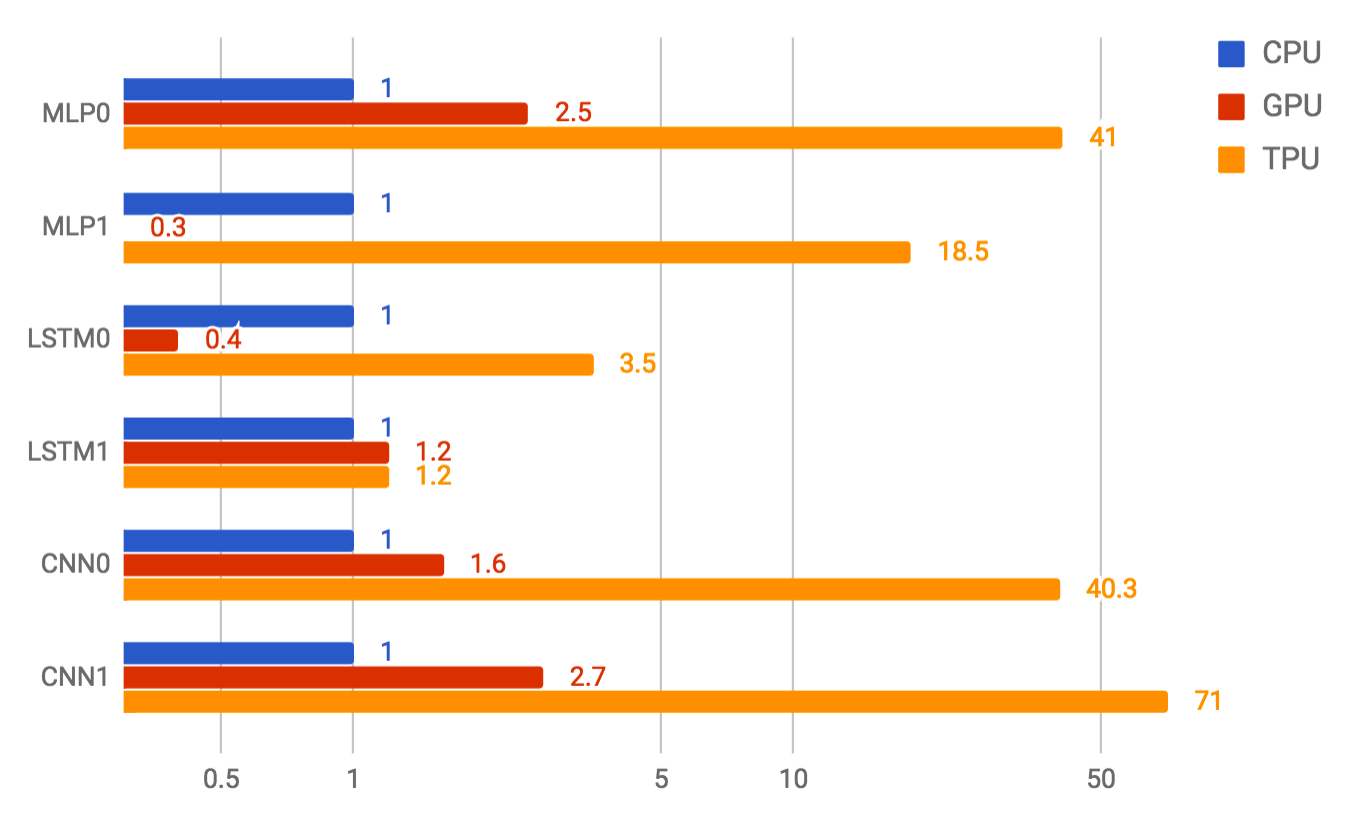
The difference is even 10 times significant. It is clear that the difference with the GPU in 20-30 times determines the development of this direction.
And, fortunately, Google is not alone.
TPU Huawei
Now, the long-suffering Huawei also began the development of TPU several years ago under the name Huawei Ascend, and in two versions at once - for data centers (like Google) and for mobile devices (which Google also began to do recently). If you believe the materials of Huawei, then they overtook fresh Google TPU v3 by FP16 by 2.5 times and NVIDIA V100 by 2 times:

As usual, a good question: how this chip will behave on real tasks. For on the graph, as you can see, peak performance. In addition, Google TPU v3 is good in many respects because it can work effectively in clusters of 1024 processors each. Huawei also announced server clusters for the Ascend 910, but no details. In general, Huawei engineers have shown themselves to be extremely literate over the past 10 years, and there is every chance that a 2.8 times greater peak performance compared to Google TPU v3, coupled with the latest 7 nm process technology, will be used in the case.
Memory and data bus are critical for performance, and you can see from the slide that considerable attention is paid to these components (including the speed of communication with the memory noticeably faster than that of the GPU):
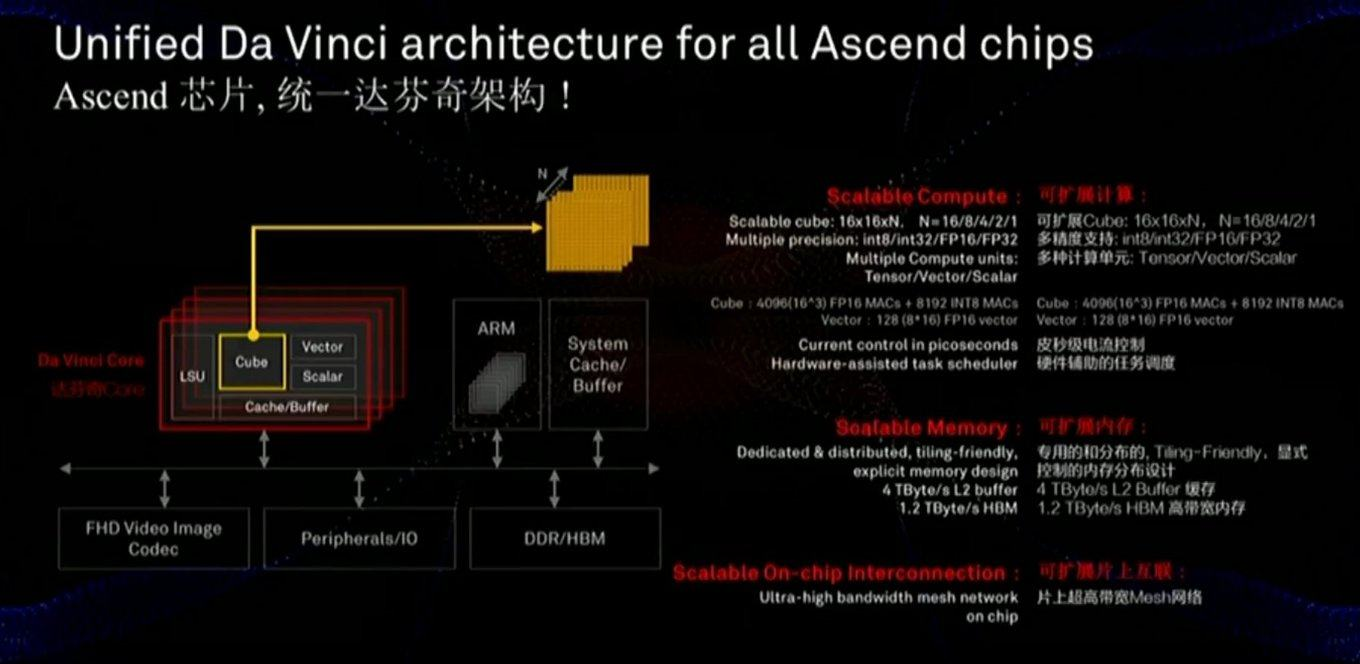
Also in the chip there is a slightly different approach - not two-dimensional MXU 128x128 are scaled, but calculations in a three-dimensional cube of a smaller size 16x16xN, where N = {16,8,4,2,1}. Therefore, the key question is how well this will fall on the actual acceleration of specific networks (for example, calculations in a cube are convenient for images). Also, a closer look at the slide shows that, unlike Google, the chip immediately starts working with compressed FullHD video. For the author, this sounds very encouraging!
As mentioned above, processors for mobile devices are developed in the same line, for which energy efficiency is critical, and on which the network will be mainly executed (that is, separately - processors for cloud learning and separately - for execution):

And according to this parameter, everything looks pretty good compared to NVIDIA at least (note that they didn’t compare Google with Google’s, however, TPU doesn’t give Google hands on a cloud). And their mobile chips will compete with processors from Apple, Google and other companies, but it’s still too early to sum up.
It is clearly seen that the new Nano, Tiny and Lite chips should be even better. It becomes clear
Analog Deep Networks
As you know, technology often develops in a spiral, when, at a new stage, old and forgotten approaches become relevant.
Something similar may well happen with neural networks. You may have heard that once the multiplication and addition operations were performed with electron tubes and transistors (for example, color space conversion — a typical matrix multiplication — was in every color television until the mid-90s)? There was a good question: if our neural network is relatively resistant to inaccurate calculations inside, what if we translate these calculations into an analog form? We immediately get a noticeable acceleration of calculations and a potentially dramatic reduction in energy consumption for performing a single operation:
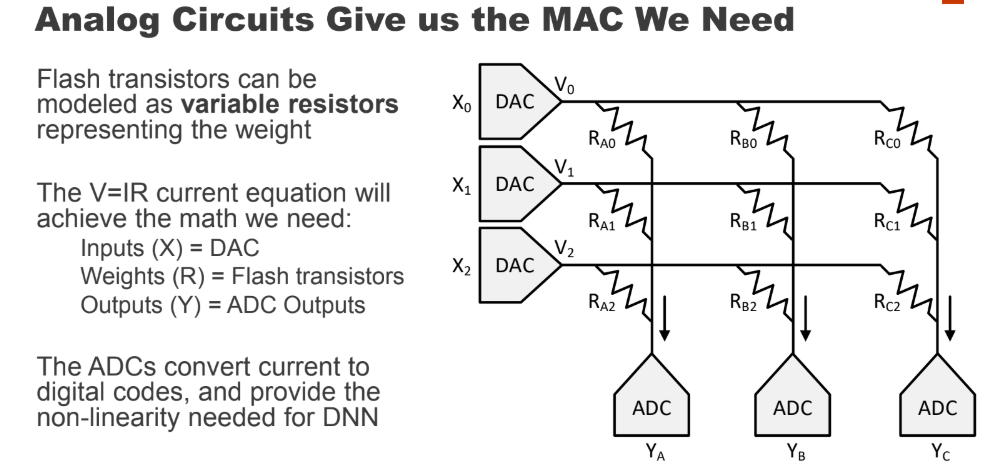
With this approach, DNN (Deep Neural Network) is calculated quickly and energy efficiently. But there is a problem - it is DAC / ADC (DAC / ADC) - converters from digital to analog and vice versa, which reduce both energy efficiency and process accuracy.
However, back in 2017, IBM Research offered analog CMOS for RPU ( Resistive Processing Units ), which allow storing the processed data also in analog form and significantly increase the overall efficiency of the approach:
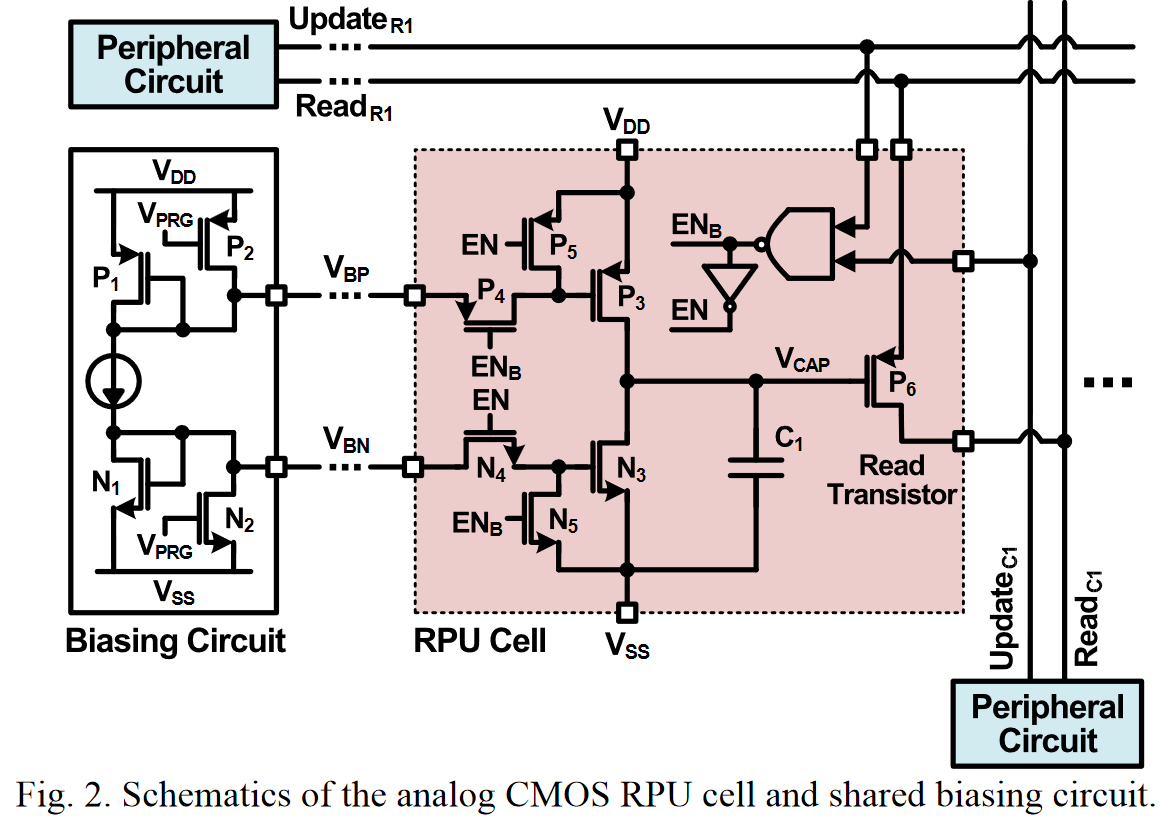
Also, in addition to analog memory, a reduction in the accuracy of a neural network can be of great help - this is the key to miniaturizing RPUs, which means increasing the number of computational cells on a chip. And here IBM is also among the leaders, and in particular, recently this year they quite successfully hardened the network to 2-bit accuracy and are going to bring the accuracy to one-bit (and two-bit during training), which will potentially allow 100 times (!) Increase in performance compared to modern GPUs:
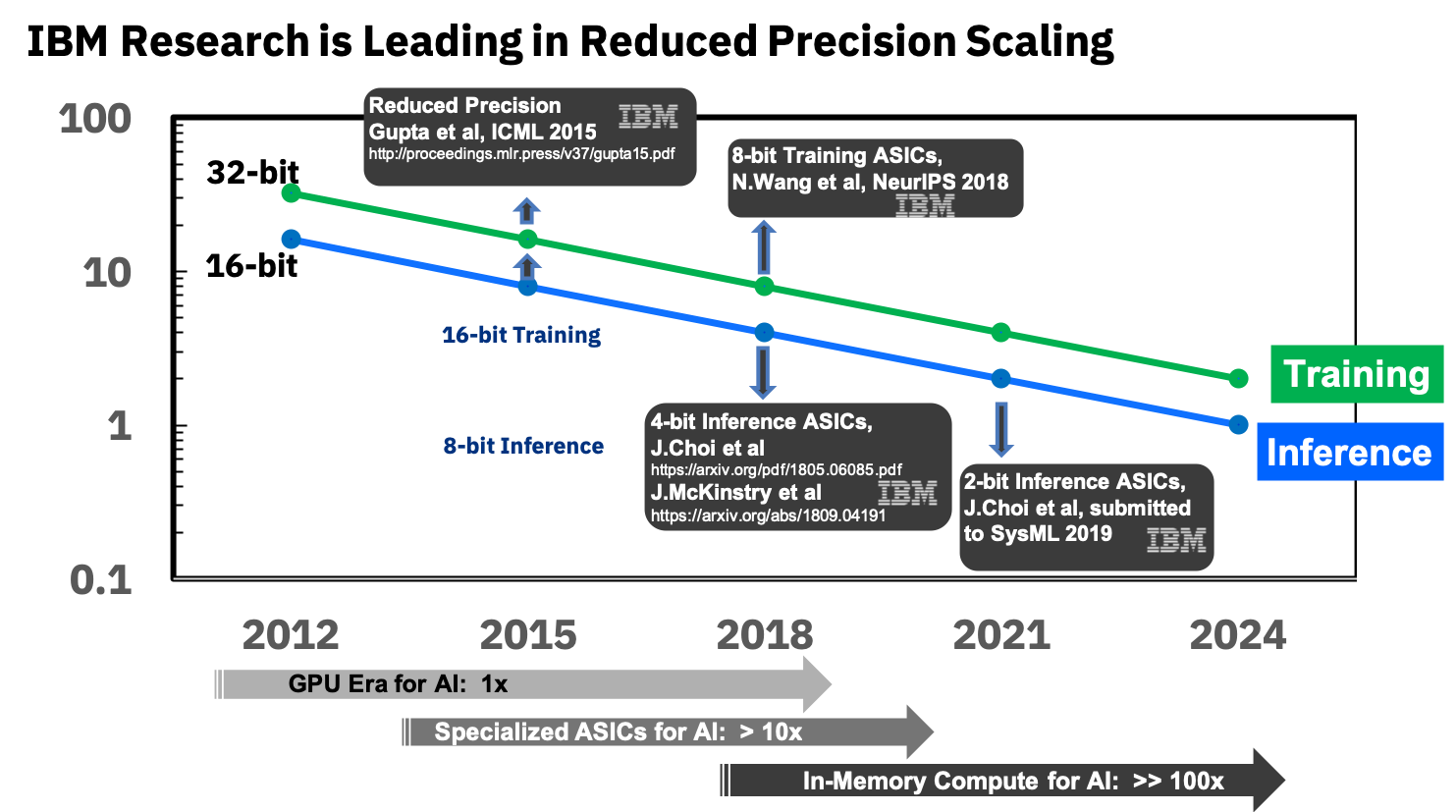
It’s still too early to talk about analog neurochips, because so far all of this is being tested at the level of early prototypes:

However, potentially the direction of analog computing looks extremely interesting.
The only thing that confuses is that this is IBM, which has already filed dozens of patents on the topic .According to the experience, due to the peculiarities of the corporate culture, they are relatively weakly cooperating with other companies and, owning some kind of technology, are more likely to slow down its development in others than to effectively share. For example, IBM at the time refused to license arithmetic compression for JPEG to the ISO committee, while in the draft standard there was an option with arithmetic compression. As a result, JPEG went into life with compression according to Huffman and pressed 10–15% worse than it could. The same situation was with video compression standards. And the industry massively switched to arithmetic compression in codecs only when 5 IBM patents expired 12 years later ... Let's hope that IBM will be more inclined to cooperate this time, and, accordingly, we wish maximum success in the field to everyone who is not associated with IBM, the benefit of such people and companies a lot .
If it works, it will be a revolution in the use of neural networks and a revolution in many areas of computer science.
Different other letters
In general, the topic of accelerating neural networks has become fashionable; all large companies and dozens of start-ups are engaged in it, and at least 5 of them attracted more than $ 100 million in investment by the beginning of 2018. In total, in 2017, startups associated with the development of chips were invested 1.5 billion dollars. Given that investors did not notice chip makers for a good 15 years (for there was nothing to catch there against the background of giants). In general - now there is a real chance for a small iron revolution. Moreover, it is extremely difficult to predict which architecture will win, the need for a revolution has matured, and the possibilities for increasing productivity are great. The classic revolutionary situation has matured: Moore is no longer able, but Dean is not yet ready.
Well, since the most important market law is different, many new letters have appeared, for example:
- Neural Processing Unit ( NPU ) - Neuroprocessor, sometimes beautifully - neuromorphic chip - in general, the common name for the neural network accelerator, which is called Samsung , Huawei chips and the list goes on ...

, , , Apple Huawei, TSMC. , , 2-8 :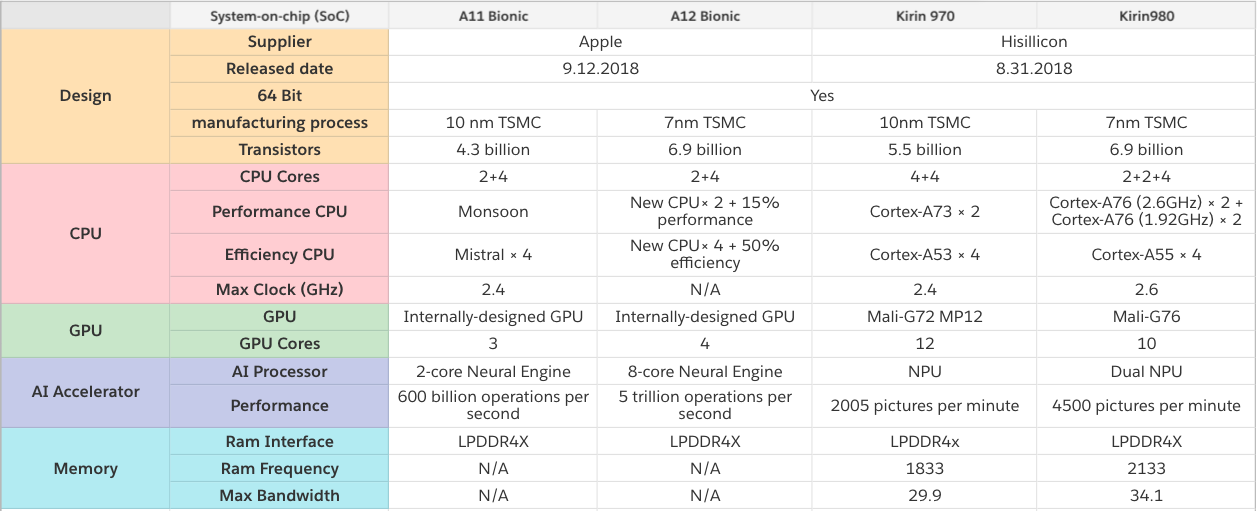
- Neural Network Processor (NNP) — .
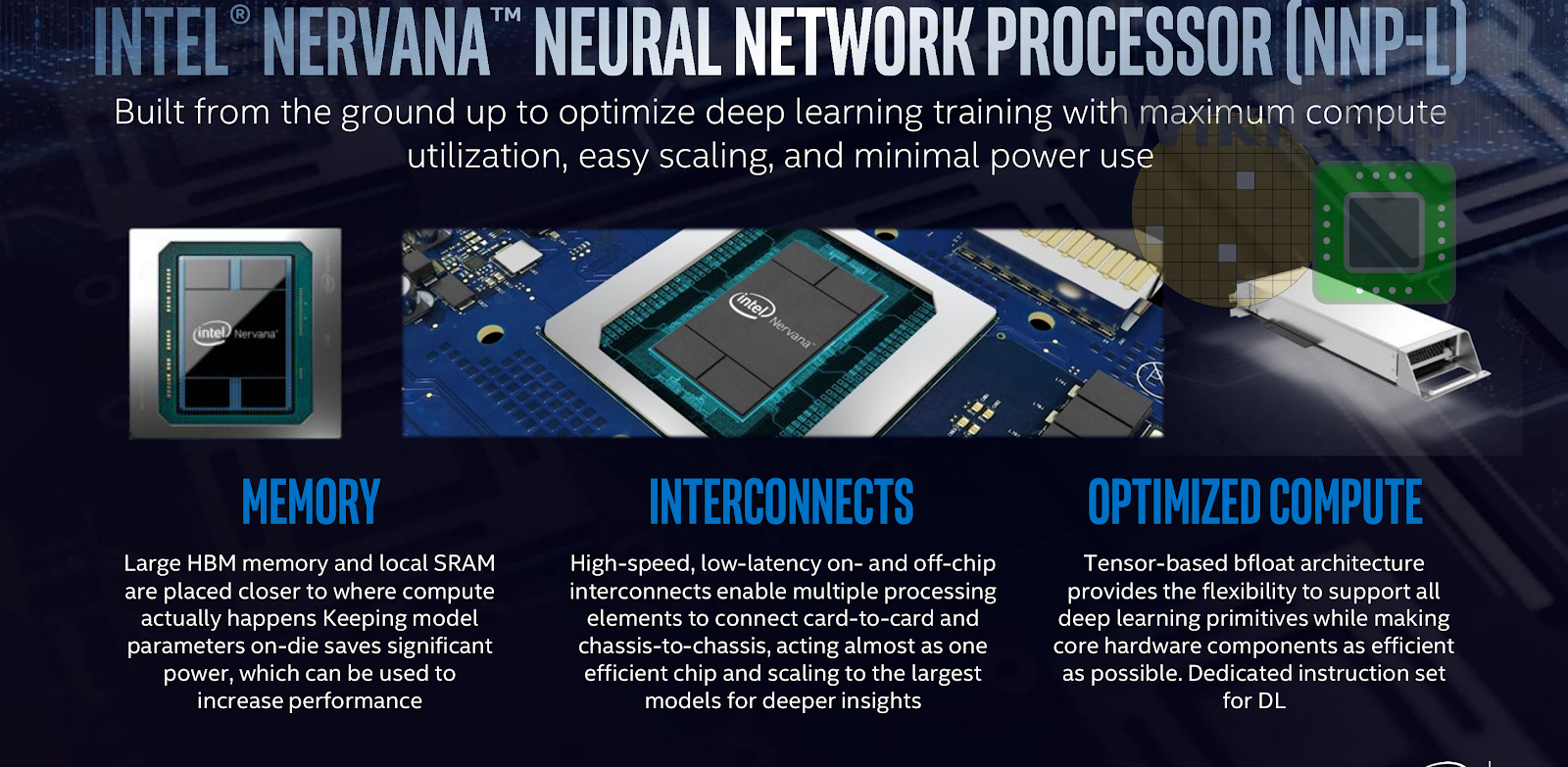
, , Intel ( Nervana Systems , Intel 2016 $400+ ). , , NNP . - Intelligence Processing Unit (IPU) — — , Graphcore (, $310 ).

, , RNN 180–240 , NVIDIA P100. - Dataflow Processing Unit (DPU) — — WAVE Computing , $203 . , Graphcore:
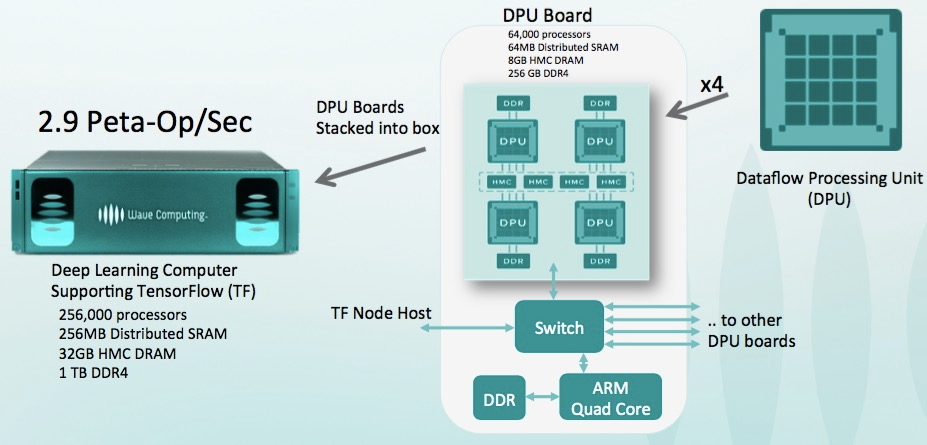
100 , 25+ , GPU ( , 1000 ). … - Vision Processing Unit ( VPU ) — :
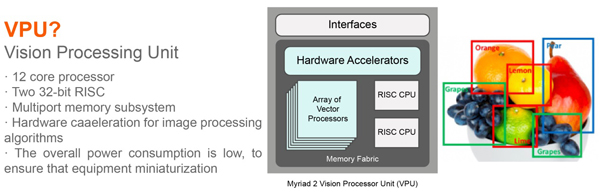
, , Myriad X VPU Movidius ( Intel 2016). - IBM (, , RPU ) — Mythic — Analog DNN , . , :

And it lists only the largest areas, in the development of which hundreds of millions have been invested (when developing iron, this is important).
In general, as we see, all the flowers are flourishing. Gradually, companies will digest billions of dollars in investment (usually it takes 1.5–3 years to produce chips), the dust will settle, the leader will become clear, the winners will write history as usual, and the name of the technology most successful on the market will become generally accepted. This has already happened more than once (“IBM PC”, “Smartphone”, “Xerox”, etc.).
A couple of words about the correct comparison
As noted above, it is not easy to compare the performance of neural networks correctly. Exactly why Google publishes a graph on which the TPU v1 makes the NVIDIA V100. NVIDIA, seeing such a disgrace, publishes a chart where Google TPU v1 loses V100. (Duc!) Google publishes the following graph, where V100 loses Google TPU v2 & v3 with a bang. And finally, Huawei is a graph where everyone loses Huawei Ascend, but V100 is better than TPU v3. Circus, in short. What is characteristic - there is a truth in every chart!
The root causes of the situation are clear:
- You can measure the speed of learning or the speed of execution (whichever is more convenient).
- You can measure different neural networks, since the speed of implementation / training of different neural networks on specific architectures may differ significantly due to the network architecture and the amount of data required.
- And you can measure the peak performance of the accelerator (perhaps the most abstract value of all of the above).
As an attempt to establish order in this zoo, the MLPerf test appeared , for which version 0.5 is now available, i.e. It is in the process of developing a comparison methodology, which is planned to be completed in the third quarter of this year before the first release :

Since there is one of the main contributors of TensorFlow in the authors, there is every chance of finding out what the fastest way to train and possibly use (for the mobile version of TF will probably also be included in this test over time).
Recently, the international organization IEEE , which publishes the third part of the world technical literature on electronics, computers and electrical engineering, is not childishly banned by Huawei , soon, however, having canceled a ban. In the current MLPerf rating, Huawei is not yet available, while Huawei TPU is a serious competitor to Google TPU and NVIDIA cards (that is, besides political ones, there are also economic reasons to ignore Huawei, let's face it). With undisguised interest we will follow the development of events!
All in the sky! Closer to the clouds!
And, since we are talking about training, it is worth saying a few words about its specificity:
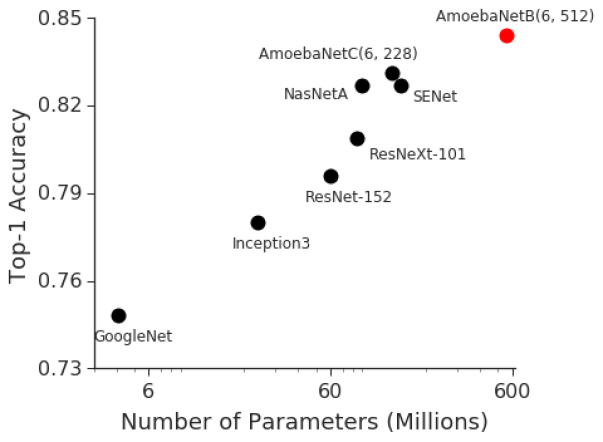
- With the rampage of research into deep neural networks (with dozens and hundreds of layers that really break everyone), it was necessary to grind hundreds of megabytes of coefficients, which immediately made all the processors caches of previous generations ineffective. At the same time, a classic ImageNet is reasoned about a strict correlation between the size of the network and its accuracy (the higher, the better, the more to the right, the larger the network, the horizontal axis is logarithmic):
- The course of computations inside the neural network goes in a fixed pattern, i.e. where all “branching” and “transitions” (in terms of the last century) will occur in the overwhelming majority of cases, it is precisely known in advance, which leaves without work the speculative execution of instructions that previously markedly increases productivity:
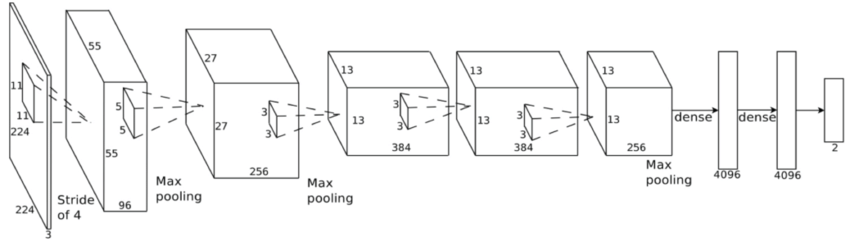
This makes inefficient the sophisticated superscalar mechanisms of predicting branching and predictions of previous decades of improving processors (this part of the chip also, unfortunately, on DNN rather contributes to global warming, as does the cache). - At the same time, neural network training is relatively weakly scaled horizontally . Those. we can not take 1000 powerful computers and get the acceleration of learning 1000 times. And even in 100 we cannot (at least the theoretical problem of deterioration in the quality of education on a large amount of batch is not solved yet). It’s generally quite difficult for us to distribute something across several computers, because as soon as the access speed to a single memory in which the network is located decreases, the speed of its learning drops dramatically. Therefore, if the researcher has access to 1000 powerful computers
for free, he will certainly take them all soon, but most likely (if there is no infiniband + RDMA) there will be many neural networks with different hyperparameters there. Those. the total training time will be only several times less than with 1 computer. There is possible a game with the size of a batch, and additional training, and other new modern technologies, but the main conclusion is yes, with an increase in the number of computers, the work efficiency and the probability of achieving results will increase, but not linearly. And today the time of the Data Science researcher is expensive and often if you can spend a lot of cars (albeit unwisely), but to get acceleration is done (see the example with 1, 2 and 4 expensive V100 in the clouds just below).
Exactly these moments explain why so many people rushed towards the development of specialized iron for deep neural networks. And why they got their billions. The light at the end of the tunnel is really visible there and not only at Graphcore (which, we recall, RNN training was accelerated 240 times).
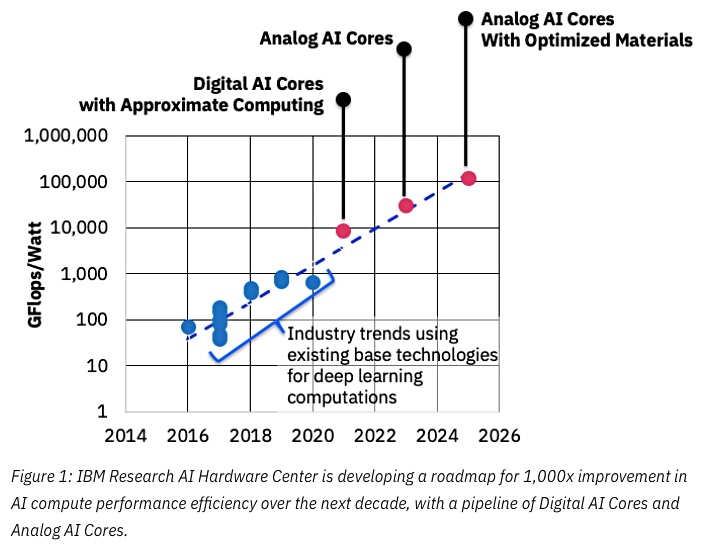
For example, gentlemen from IBM Research are optimistic , to develop special chips that will increase the efficiency of computing by an order of magnitude already after 5 years (and 10 years later by 2 orders of magnitude, having reached an increase of 1000 times compared to the level of 2016, on this graph, though , in efficiency per watt, but the power of the cores will also increase):
All this means the emergence of glands, the training on which will be relatively fast, but which will cost much, which naturally leads to the idea of sharing the time of using this expensive piece of iron between researchers. And this idea today no less naturally leads us to cloud computing. And the transition of learning to the clouds has long been active.
Note that already now the training of the same models may differ in time by an order of magnitude with different cloud services. Below is the lead Amazon, and in the last place free Colab from Google. Notice how the result changes from the number of V100 among the leaders - an increase in the number of cards by 4 times (!) Increases productivity by less than a third (!!!) from blue to purple, and by Google even less:
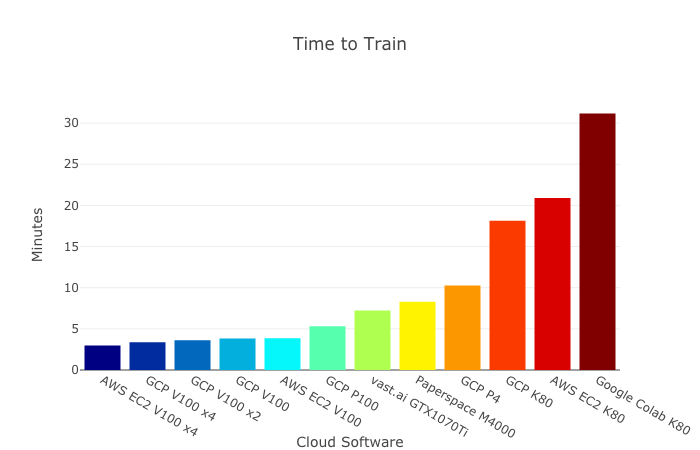
It seems that in the coming years the difference will grow to two orders of magnitude. Lord Cooking money! Together we will return multi-billion investments to the most successful investors ...
In short
Let's try to summarize the key points in the table:
| Type of | What speeds up | Comment |
| CPU | Mostly performance | Usually the worst in speed and energy efficiency, but quite suitable for small neural networks |
| GPU | Execution + training | The most universal solution, but rather expensive, both in terms of computation cost and energy efficiency. |
| Fpga | Performance | Relatively versatile solution for network performance, in some cases allows to drastically speed up the execution |
| ASIC | Performance | The cheapest, fastest, and most energy efficient network implementation option, but large runs are needed. |
| TPU | Execution + training | The first versions were used to speed up execution, now they are used to speed up execution and training very effectively. |
| IPU, DPU ... NNP | Mostly training | Many marketing letters that will be safely forgotten in the coming years. The main advantage of this zoo is checking the different directions of DNN acceleration. |
| Analog DNN / RPU | Execution + training | Potentially analogue accelerators can revolutionize the speed and energy efficiency of performing and training neural networks. |
A few words about software acceleration
In fairness, we mention that today a big topic is the software acceleration of the implementation and training of deep neural networks. Implementation can be significantly accelerated primarily due to the so-called quantization of the network. Perhaps this is, first, because the range of weights used is not so large and it is often possible to roughen weights from a 4-byte floating-point value to 1 byte integer (and, recalling IBM's successes, even stronger). Secondly, the trained network as a whole is quite resistant to noise in the calculations and the accuracy of work during the transition to int8 drops slightly. At the same time, despite the fact that the number of operations may even increase (due to scaling when counting), the fact that the network decreases in size by 4 times and can be considered as fast vector operations significantly increases the overall execution speed. This is especially important for mobile applications, but it also works in the clouds (an example of speeding up execution in Amazon clouds):
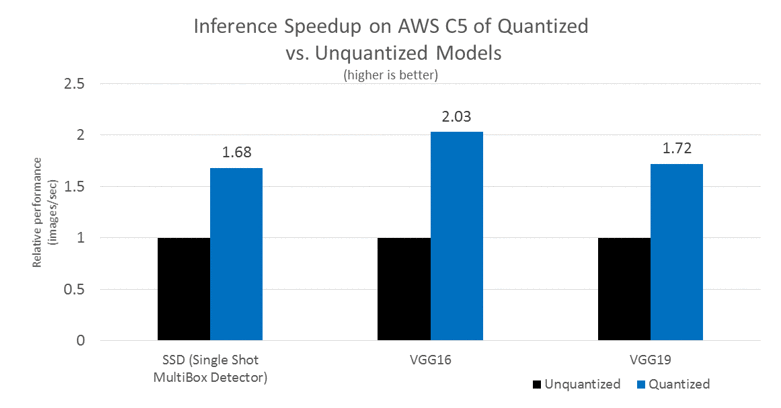
There are other ways to accelerate network execution and even more ways to accelerate learning . However, these are separate big topics about which not this time.
Instead of conclusion
In his lectures, the investor and author Tony Seb gives a great example: in 2000, the supercomputer №1 with a capacity of 1 teraflops occupied 150 square meters, cost $ 46 million and consumed 850 kW:

15 years later, NVIDIA GPU with a capacity of 2.3 teraflops (2 times more) was placed in the hand, cost $ 59 (improvement about a million times) and consumed 15 W (improvement 56 thousand times):

In March of this year, Google introduced TPU Pods - in fact, liquid-cooled supercomputers based on TPU v3, a key feature of which is that they can work together on 1024 TPU systems. They look pretty impressive:

Exact data is not given, but it is said that the system is comparable with the Top-5 supercomputers in the world. TPU Pod allows you to dramatically increase the speed of learning neural networks. To increase the speed of interaction, TPUs are connected by high-speed highways to a toroidal structure:

It seems that in 15 years this neuroprocessor twice as big in performance can also fit in your hand, like the Skynet processor (agree with something similar):

Given the current rate of improvement of hardware accelerators of deep neural networks and the example above, this is completely realistic. There is every chance in a few years to take in hand a chip with a performance like today's TPU Pod.
By the way, it's funny that in the film the chip makers (apparently, imagining where the network can lead to self-study) by default turned off the additional training. It is characteristic that the T-800 itself could not turn on the training mode and worked in the inference mode (see the longer directorial version ). Moreover, his neural-net processor was advanced and, with the inclusion of pre-training, could use previously accumulated data to update the model. Not bad for 1991.
This text was started in the hot 13-million Shenzhen. I was sitting in one of the 27,000 electric vehicles in the city, and with great interest I looked at the 4 LCD screens of the car. One small one is among the devices in front of the driver, two are centrally located in the dashboard and the last one is translucent in the rearview mirror combined with a DVR, interior surveillance camera and android on board (judging by the top line with the charge level and connection to the network). There the driver's data was displayed (to whom to complain, if that), a fresh weather forecast and, it seems, there was a connection with the taxis. The driver did not know English, and asked him about the impressions of the electric machine did not work. Therefore, he idly pressed the pedal, slightly pushing the car in traffic. And I watched with interest the futuristic view of the window - the Chinese in jackets were driving from work on electric scooters and monowheels ... and wondered how it would look like in 15 years ...
Actually, already today the rear-view mirror, using the data of the DVR camera and hardware acceleration of neural networks , is quite able to control the car in a traffic jam and create a route. Happy at least). After 15 years, the system will obviously not only be able to drive a car, but will also gladly provide me with the characteristics of fresh Chinese electric cars. In Russian, of course (as an option: English, Chinese ... Albanian, finally). The driver is superfluous, poorly trained, link.
Lord Waiting for us EXTREMELY INTERESTING 15 years!
Stay tuned!
I'll be back! )))

Acknowledgments
I would like to sincerely thank:
- Laboratory of Computer Graphics VMK MSU. MV Lomonosov for his contribution to the development of computer graphics in Russia and not only,
- our colleagues, Mikhail Erofeev and Nikita Bagrov, whose examples are used above,
- personally Konstantin Kozhemyakov, who did a lot to make this article better and clearer,
- and, finally, many thanks to Alexander Bokov, Mikhail Erofeev, Vitaly Lyudvichenko, Roman Kazantsev, Nikita Bagrov, Ivan valiant, Egor Sklyarov, Alexei Solovyov, Eugene Lyapustin, Sergei Lavrushkina and Nicholas Oplachko for a large number of fittings of comments and edits to make this text a lot it is better!
Source: https://habr.com/ru/post/455353/
All Articles