"Bitriks24": "Quickly raised is not considered fallen"
To date, the Bitrix24 service does not have hundreds of gigabit traffic, there is not a huge fleet of servers (although there are, of course, many existing ones). But for many clients, it is the main tool for working in a company; this is a real business-critical application. Therefore, to fall - well, no way. But what if the fall did happen, but the service “rebelled” so quickly that no one noticed anything? And how is it possible to implement this failover without losing the quality of work and the number of clients? Alexander Demidov, director of cloud services at Bitrix24, spoke for our blog about how the backup system has evolved over the 7 years of its existence.

“In the form of SaaS, we launched Bitrix24 7 years ago. The main difficulty, probably, was as follows: before launching it as a SaaS in public, this product existed simply in the format of a boxed solution. Customers bought it from us, placed it on their servers, got a corporate portal - a common solution for employee communication, file storage, task management, CRM, that's all. And by 2012 we decided that we want to launch it as SaaS, administering it on our own, ensuring resiliency and reliability. We gained experience in the process, because until then we simply did not have it - we were only software producers, not service providers.
When launching the service, we understood that the most important thing is to ensure fault tolerance, reliability and constant availability of the service, because if you have a simple regular website, a store, for example, and it has fallen and you have an hour - only you yourself suffer, you lose orders , you lose clients, but for your client himself - for him it is not very critical. He was upset, of course, but he went and bought it on another site. And if this is an application that is tied to all the work within the company, communications, solutions, then the most important thing is to win the trust of users, that is, not to let them down and not to fall. Because all the work can get up if something inside does not work.
')
We collected the first prototype a year before the public launch, in 2011. They collected about a week, looked, twisted - he was even working. That is, it was possible to enter the form, enter the name of the portal there, a new portal was developed, a user base was established. We looked at it, evaluated the product in principle, turned it off, and worked on it a year later. Because we had a big task: we didn’t want to make two different code bases, we didn’t want to separately support the boxed product, separate cloud solutions, we wanted to do all this within the same code.

A typical web application at that time is one server on which some php code is spinning, the mysql database, files are being uploaded, documents, pictures are being put in the upload folder — well, it all works. Alas, it is impossible to start a critically stable web service. There, distributed cache is not supported, database replication is not supported.
We formulated the requirements: this is the ability to be located in different locations, to support replication, ideally to be located in different geographically distributed data centers. Separate the logic of the product and, in fact, data storage. Dynamically able to scale to the load, statics generally endure. For these reasons, in fact, the requirements for the product, which we have been refining over the course of a year, have been developed. During this time, in a platform that turned out to be the same - for boxed solutions, for our own service - we made support for those things that we needed. Mysql replication support at the level of the product itself: that is, the developer who writes the code - does not think about how his requests will be distributed, he uses our api, and we know how to properly distribute the write and read requests between the masters and the slaves.
We made product support for various cloud object storage: google storage, amazon s3, - plus, support for open stack swift. Therefore, it was convenient both for us as a service and for developers who work with a boxed solution: if they just use our api for work, they do not think about where the file will be saved, locally on the file system or go to the object file storage .
As a result, we immediately decided that we would be backed up at the level of the whole data center. In 2012, we launched all of Amazon AWS, because we already had experience with this platform — our own site was hosted there. We were attracted by the fact that in each region in Amazon there are several accessibility zones - in fact, (in their terminology) several data centers that are more or less independent of each other and allow us to be reserved at the level of the whole data center: if it suddenly crashes, the databases are replicated by the master-master, the web application servers are reserved, and the statics are moved to the s3 object storage. The load is balanced - at that time by the Amazon elb, but a little later we came to our own balancers, because we needed more complex logic.
All the basic things that we wanted to ensure - the fault tolerance of the servers themselves, web applications, databases - everything worked well. The simplest scenario: if any of the web applications fail, then everything is simple - they are turned off from balancing.

The balancer failed machines (then it was Amazon's elb) he ticked unhealthy himself, turned off the load distribution on them. Amazon autospeiling worked: when the load grew, new cars were added to the autospelling group, the load was distributed to the new cars - everything was fine. With our balancers, the logic is approximately the same: if something happens to the application server, we remove requests from it, throw out these machines, start new ones and continue to work. The scheme for all these years has changed a little, but it continues to work: it is simple, understandable, and there are no difficulties with this.
We work around the world, customer load peaks are completely different, and, in an amicable way, we should be able to carry out these or other service works with any components of our system at any time - invisible to customers. Therefore, we have the opportunity to turn off the database from work by redistributing the load on the second data center.
How does all this work? - We switch traffic to a working data center - if it is an accident at the data center, then completely, if it is our planned work with a single database, then we switch part of the traffic that serves these clients to the second data center, stops replication. If you need new machines for web applications, since the load on the second data center has increased, they automatically start. We finish the work, replication is restored, and we return the entire load back. If we need to mirror some work in the second DC, for example, install system updates or change settings in the second database, then, in general, we repeat the same thing, just the other way. And if this is an accident, then we do everything in a banal way: in the monitoring system we use the event-handlers mechanism. If we have several checks and the status goes to critical, then we run this handler, a handler that can execute this or that logic. We have written for each database which server is failover for it, and where it is necessary to switch traffic in case of its inaccessibility. We - so historically - use nagios or some of its forks in one form or another. In principle, there are similar mechanisms in almost any monitoring system, we are not using something more complicated, but maybe we will be sometime. Now monitoring is triggered on inaccessibility and has the ability to switch something.
We have many customers from the USA, many customers from Europe, many customers who are closer to the East — Japan, Singapore, and so on. Of course, a huge proportion of customers in Russia. That is, the work is not in the same region. Users want quick response, there are requirements for compliance with various local laws, and within each region we reserve for two data centers, plus there are some additional services that, again, are conveniently located within one region - for customers who are region work. REST handlers, authorization servers, they are less critical for the client as a whole, you can switch on them with a small acceptable delay, but you don’t want to reinvent the wheel, how to monitor them and what to do with them. Therefore, to the maximum, we are trying to use already existing solutions, and not to develop some kind of competence in additional products. And somewhere we tritely use switching at the dns level, and the liveliness of the service is determined by the same dns. Amazon has a Route 53 service, but it's not just dns, into which you can add entries, that's all - it is much more flexible and convenient. Through it, you can build geo-distributed services with geolocation, when you use it to determine where the client came from, and give him certain records — you can use it to build a failover architecture. The same health-checks are configured in Route 53 itself, you set the endpoint that is monitored, you set the metrics, you set the protocols by which to determine the service’s “liveliness” - tcp, http, https; you set the frequency of checks that determine whether the service is live or not. And in the dns you prescribe what will be primary, what will be secondary, where to switch, if the health-check inside route 53 works. All this can be done with some other tools, but it’s convenient to configure it once and then don’t think about how we make checks, how we go switching: everything works by itself.
The first "but" : how and what to reserve route 53 itself? You never know, suddenly something happens to him? We, fortunately, never attacked this rake, but again, I will have a story ahead of us why we thought that we should reserve it all the same. Here we lay our straw in advance. Several times a day we do a full unloading of all the zones that are established in route 53. The Amazon API allows you to safely submit them to JSON, and we have several backup servers raised, where we convert it, upload it in the form of configs, and, roughly speaking, have a backup configuration. In which case we can quickly deploy it manually, do not lose the data settings dns.
The second "but" : what is not reserved in this picture? Himself balancer! We have a very simple distribution of clients by region. We have domains bitrix24.ru, bitrix24.com, .de - now there are 13 different pieces that work in the most different zones. We have come to the following: each region has its own balancers. So it is more convenient to distribute by region, depending on what is where the peak load on the network. If this is a failure at the level of a single balancer, then it is simply decommissioned and removed from the dns. If there is any problem with the balance group, they are reserved at other sites, and switching between them is done using the same route53, because at the expense of a short ttl switching occurs a maximum of 2, 3, 5 minutes.
The third "but" : what else is not reserved? S3, right. When we placed files that we keep with users in s3, we sincerely believed that it was armor-piercing and we don’t need to reserve anything there. But the story shows what happens differently. In general, Amazon describes S3 as a fundamental service, because Amazon itself uses S3 to store images of machines, configs, AMI images, snapshots ... And if s3 falls, as it once happened during these 7 years, how much we exploit bitrix24 pulls a lot of everything - the inaccessibility of the start of virtual machines, the failure of api and so on.
And fall S3 can - it happened once. Therefore, we came to the following scheme: a few years ago, there were no serious object public repositories in Russia, and we considered the option of doing something of our own ... Fortunately, we did not start it, because we would have dug into that expertise, which we did not We possess, and for certain would nakosyachili. Now Mail.ru has s3-compatible storage, Yandex has it, a number of providers have it. We finally came to the idea that we want to have, firstly, a reservation, and secondly, the ability to work with local copies. For specifically the Russian region, we use the Mail.ru Hotbox service, which is api compatible with s3. We didn’t need any serious improvements in the code inside the application, and we did the following mechanism: there are triggers in s3 that trigger the creation / deletion of objects, Amazon has a service like Lambda - this is serverless code launch that will be executed when triggered or those triggers.
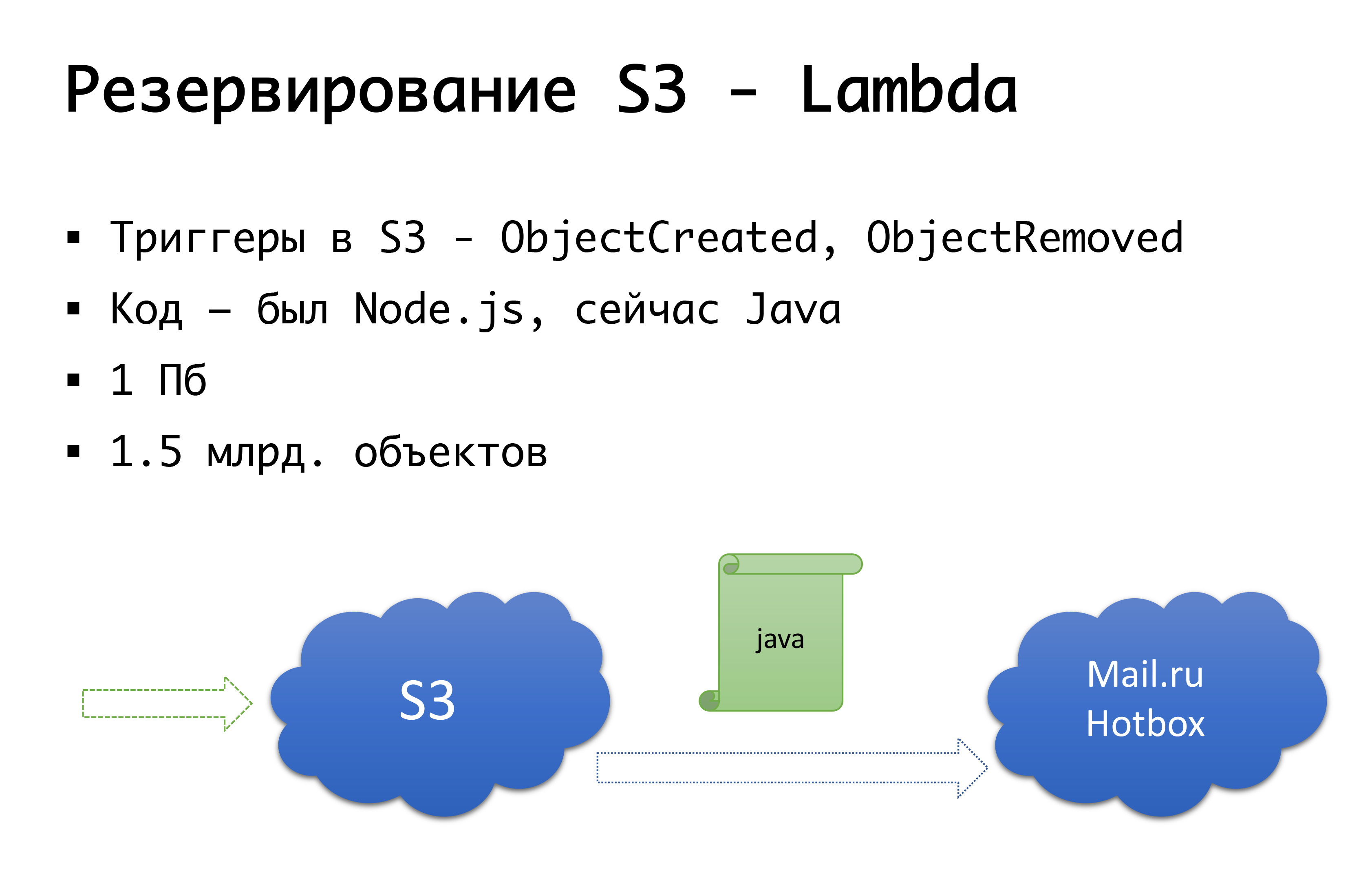
We made it very simple: if the trigger works for us, we execute the code that copies the object to the Mail.ru repository. In order to fully start working with local copies of data, we also need backward synchronization so that customers who are in the Russian segment can work with the storage that is closer to them. Mail is about to complete the triggers in its storage - it will be possible to perform reverse synchronization at the infrastructure level, while we are doing it at the level of our own code. If we see that the client has placed a file, then at our code level we put the event in a queue, process it, and do reverse replication. What it is bad for is: if we do some work with our objects outside our product, that is, by some external means, we will not take this into account. Therefore, we are waiting until the end, when there will be triggers at the storage level, so that no matter where we run the code, the object that came to us was copied in the other direction.
At the code level, we have both storages for each client: one is considered the main one, the other is backup. If everything is good, we work with the storage that is closer to us: that is, our customers who are at Amazon, they work with S3, and those who work in Russia, they work with Hotbox. If the checkbox is triggered, then we have to connect failover, and we switch clients to another storage. We can check this box independently by region and we can switch them back and forth. In practice, this has not yet been used, but this mechanism has been foreseen and we think that sometime this switch will be needed and useful to us. Once it happened.
This April is the anniversary of the start of Telegram locks in Russia. The most affected provider that came under this is Amazon. And, unfortunately, Russian companies that worked for the whole world suffered more.
If the company is global and Russia for it is a very small segment, 3-5% - well, one way or another, you can donate them.
If this is a purely Russian company - I am sure that it is necessary to locate locally - well, just by the users themselves will be convenient, comfortable, the risks will be less.
And if this is a company that operates globally, and it has approximately equal customers from Russia, and somewhere in the world? Segment connectivity is important, and they should work with each other anyway.
At the end of March 2018, Roskomnadzor sent a letter to the largest operators saying that they are planning to block several million ip Amazons in order to block ... the Zello messenger. Thanks to these same providers - they successfully leaked the letter to everyone, and there was an understanding that coherence with Amazon could fall apart. It was Friday, we ran in panic to colleagues from servers.ru, with the words: “Friends, we need several servers that will not stand in Russia, not in Amazon, but, for example, somewhere in Amsterdam,” in order to be able to at least in some way put there own vpn and proxy for some endpoints that we cannot influence in any way, for example, the endponts of the same s3 - you cannot try to raise a new service and get another ip, we you still need to get there. In a few days we set up these servers, raised them, and in general, by the time the locks began, we were ready. It is curious that the RKN, having looked at the hype and panic raised, said: “No, we will not block anything now.” (But this is exactly up to the moment when they began to block the telegrams.) By adjusting the bypass capabilities and realizing that the lock was not entered, we, however, did not begin to disassemble the whole thing. So, just in case.

And in 2019, we still live in blocking conditions. I watched last night: about a million ip continue to block. True, Amazon almost unlocked at full strength, reached a peak of 20 million addresses ... In general, the reality is that connectivity, good connectivity - it may not be. Suddenly. It may not be for technical reasons - fires, excavators, everything. Or, as we have seen, not quite technical. Therefore, someone large and large, with their own AS-kami, probably can steer it in other ways, - direct connect and other things already at the level of l2. But in a simple version, as we or even smaller, you can, just in case, have redundancy at the server level, raised somewhere else, configured in advance by vpn, proxy, with the ability to quickly switch to them the configuration in those segments that are critical for your connectivity . It came in handy to us more than once, when the blocking of Amazon began, we let through S3 traffic in the worst case, but gradually it all settled.
Now we don’t have a script in case of failure of the entire Amazon. We have a similar scenario for Russia. We were located in Russia with one provider, from whom we chose to have several sites. And a year ago we ran into a problem: even though these are two data centers, already at the level of the network configuration of the provider there may be problems that will affect both data centers anyway. And we can get unavailability at both sites. Of course, that's what happened. We eventually reviewed the architecture inside. It has not changed much, but for Russia we now have two sites, which are not from one provider, but from two different ones. If one of them fails, we can switch to another.
Hypothetically, for Amazon we are considering the possibility of reserving at the level of another provider; maybe Google, maybe someone else ... But so far we have seen in practice that if Amazon has accidents at the level of one availability-zone, accidents at the level of the whole region are quite rare. Therefore, we theoretically have an idea that we may make a reservation “Amazon is not Amazon”, but in practice there is no such thing yet.
Is automatics always needed? Here it is appropriate to recall the effect of Dunning-Kruger. On the axis "x" our knowledge and experience, which we are recruited, and on the axis "y" - confidence in our actions. At first we do not know anything and are not at all sure. Then we know a little and become mega-confident - this is the so-called “peak of stupidity”, well illustrated by the picture “dementia and courage.” Then we have already learned a little and are ready to go into battle. Then we step on some kind of mega-serious rake, we fall into the valley of despair, when we seem to know something, but in fact we don’t know much. Then, as we gain experience, we become more confident.
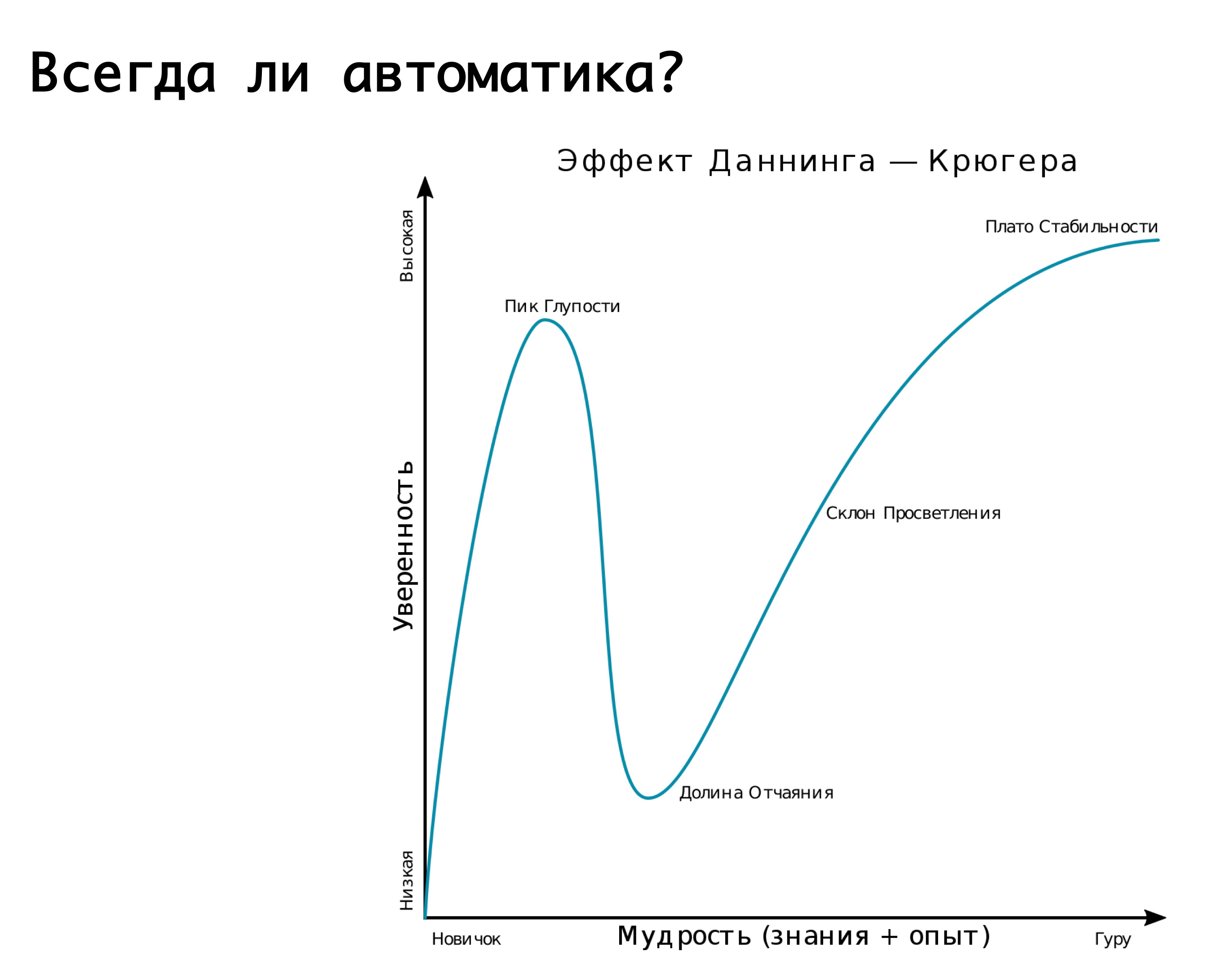
Our logic about various switchings automatically to certain accidents - it is very well described by this schedule. We started - we did not know how, almost all the work was done manually. Then we realized that it was possible to hang everything on automation and, like, sleep well. And suddenly we are stepping on a mega-rake: we have false positives triggered, and we switch traffic back and forth, when, in an amicable way, it was not worth it. Consequently, replication breaks down or something else - this is the very valley of despair. And then we come to the understanding that everything must be treated wisely. That is, it makes sense to rely on automation, providing for the possibility of false positives. But! if the consequences can be devastating, then it is better to give it at the mercy of the duty shift, on duty engineers, who will make sure that it is really an accident, and will perform the necessary actions manually ...
For 7 years we have gone the way from the fact that when something fell - there was panic-panic, to the understanding that there are no problems, there are only tasks, they are necessary - and you can - solve. When you build a service, look at it with a glance from above, assess all the risks that may occur. If you see them right away, then in advance, provide for redundancy and the possibility of building a fault-tolerant infrastructure, because any point that can fail and lead to the inoperability of the service - it will do it. And even if it seems to you that some elements of the infrastructure definitely will not fail - like the same s3, still keep in mind that they can. And at least in theory, have an idea of what you will do with them if something happens anyway. Have a risk management plan. When you think about doing everything automatically or manually, assess the risks: what will happen if the automation starts switching everything - will it not lead to an even worse picture compared to the accident? Maybe somewhere you need to use a reasonable compromise between the use of automation and the response of the engineer on duty, who will appreciate the real picture and understand whether something needs to be switched on the move or “yes, but not now”.
A reasonable compromise between perfectionism and real forces, time, money, which you can spend on the scheme that you will have in the end.
This text is an augmented and extended version of the report by Alexander Demidov at the Uptime day 4 conference.
“In the form of SaaS, we launched Bitrix24 7 years ago. The main difficulty, probably, was as follows: before launching it as a SaaS in public, this product existed simply in the format of a boxed solution. Customers bought it from us, placed it on their servers, got a corporate portal - a common solution for employee communication, file storage, task management, CRM, that's all. And by 2012 we decided that we want to launch it as SaaS, administering it on our own, ensuring resiliency and reliability. We gained experience in the process, because until then we simply did not have it - we were only software producers, not service providers.
When launching the service, we understood that the most important thing is to ensure fault tolerance, reliability and constant availability of the service, because if you have a simple regular website, a store, for example, and it has fallen and you have an hour - only you yourself suffer, you lose orders , you lose clients, but for your client himself - for him it is not very critical. He was upset, of course, but he went and bought it on another site. And if this is an application that is tied to all the work within the company, communications, solutions, then the most important thing is to win the trust of users, that is, not to let them down and not to fall. Because all the work can get up if something inside does not work.
')
Bitrix.24 as SaaS
We collected the first prototype a year before the public launch, in 2011. They collected about a week, looked, twisted - he was even working. That is, it was possible to enter the form, enter the name of the portal there, a new portal was developed, a user base was established. We looked at it, evaluated the product in principle, turned it off, and worked on it a year later. Because we had a big task: we didn’t want to make two different code bases, we didn’t want to separately support the boxed product, separate cloud solutions, we wanted to do all this within the same code.
A typical web application at that time is one server on which some php code is spinning, the mysql database, files are being uploaded, documents, pictures are being put in the upload folder — well, it all works. Alas, it is impossible to start a critically stable web service. There, distributed cache is not supported, database replication is not supported.
We formulated the requirements: this is the ability to be located in different locations, to support replication, ideally to be located in different geographically distributed data centers. Separate the logic of the product and, in fact, data storage. Dynamically able to scale to the load, statics generally endure. For these reasons, in fact, the requirements for the product, which we have been refining over the course of a year, have been developed. During this time, in a platform that turned out to be the same - for boxed solutions, for our own service - we made support for those things that we needed. Mysql replication support at the level of the product itself: that is, the developer who writes the code - does not think about how his requests will be distributed, he uses our api, and we know how to properly distribute the write and read requests between the masters and the slaves.
We made product support for various cloud object storage: google storage, amazon s3, - plus, support for open stack swift. Therefore, it was convenient both for us as a service and for developers who work with a boxed solution: if they just use our api for work, they do not think about where the file will be saved, locally on the file system or go to the object file storage .
As a result, we immediately decided that we would be backed up at the level of the whole data center. In 2012, we launched all of Amazon AWS, because we already had experience with this platform — our own site was hosted there. We were attracted by the fact that in each region in Amazon there are several accessibility zones - in fact, (in their terminology) several data centers that are more or less independent of each other and allow us to be reserved at the level of the whole data center: if it suddenly crashes, the databases are replicated by the master-master, the web application servers are reserved, and the statics are moved to the s3 object storage. The load is balanced - at that time by the Amazon elb, but a little later we came to our own balancers, because we needed more complex logic.
What they wanted was what they got ...
All the basic things that we wanted to ensure - the fault tolerance of the servers themselves, web applications, databases - everything worked well. The simplest scenario: if any of the web applications fail, then everything is simple - they are turned off from balancing.
The balancer failed machines (then it was Amazon's elb) he ticked unhealthy himself, turned off the load distribution on them. Amazon autospeiling worked: when the load grew, new cars were added to the autospelling group, the load was distributed to the new cars - everything was fine. With our balancers, the logic is approximately the same: if something happens to the application server, we remove requests from it, throw out these machines, start new ones and continue to work. The scheme for all these years has changed a little, but it continues to work: it is simple, understandable, and there are no difficulties with this.
We work around the world, customer load peaks are completely different, and, in an amicable way, we should be able to carry out these or other service works with any components of our system at any time - invisible to customers. Therefore, we have the opportunity to turn off the database from work by redistributing the load on the second data center.
How does all this work? - We switch traffic to a working data center - if it is an accident at the data center, then completely, if it is our planned work with a single database, then we switch part of the traffic that serves these clients to the second data center, stops replication. If you need new machines for web applications, since the load on the second data center has increased, they automatically start. We finish the work, replication is restored, and we return the entire load back. If we need to mirror some work in the second DC, for example, install system updates or change settings in the second database, then, in general, we repeat the same thing, just the other way. And if this is an accident, then we do everything in a banal way: in the monitoring system we use the event-handlers mechanism. If we have several checks and the status goes to critical, then we run this handler, a handler that can execute this or that logic. We have written for each database which server is failover for it, and where it is necessary to switch traffic in case of its inaccessibility. We - so historically - use nagios or some of its forks in one form or another. In principle, there are similar mechanisms in almost any monitoring system, we are not using something more complicated, but maybe we will be sometime. Now monitoring is triggered on inaccessibility and has the ability to switch something.
Have we all reserved?
We have many customers from the USA, many customers from Europe, many customers who are closer to the East — Japan, Singapore, and so on. Of course, a huge proportion of customers in Russia. That is, the work is not in the same region. Users want quick response, there are requirements for compliance with various local laws, and within each region we reserve for two data centers, plus there are some additional services that, again, are conveniently located within one region - for customers who are region work. REST handlers, authorization servers, they are less critical for the client as a whole, you can switch on them with a small acceptable delay, but you don’t want to reinvent the wheel, how to monitor them and what to do with them. Therefore, to the maximum, we are trying to use already existing solutions, and not to develop some kind of competence in additional products. And somewhere we tritely use switching at the dns level, and the liveliness of the service is determined by the same dns. Amazon has a Route 53 service, but it's not just dns, into which you can add entries, that's all - it is much more flexible and convenient. Through it, you can build geo-distributed services with geolocation, when you use it to determine where the client came from, and give him certain records — you can use it to build a failover architecture. The same health-checks are configured in Route 53 itself, you set the endpoint that is monitored, you set the metrics, you set the protocols by which to determine the service’s “liveliness” - tcp, http, https; you set the frequency of checks that determine whether the service is live or not. And in the dns you prescribe what will be primary, what will be secondary, where to switch, if the health-check inside route 53 works. All this can be done with some other tools, but it’s convenient to configure it once and then don’t think about how we make checks, how we go switching: everything works by itself.
The first "but" : how and what to reserve route 53 itself? You never know, suddenly something happens to him? We, fortunately, never attacked this rake, but again, I will have a story ahead of us why we thought that we should reserve it all the same. Here we lay our straw in advance. Several times a day we do a full unloading of all the zones that are established in route 53. The Amazon API allows you to safely submit them to JSON, and we have several backup servers raised, where we convert it, upload it in the form of configs, and, roughly speaking, have a backup configuration. In which case we can quickly deploy it manually, do not lose the data settings dns.
The second "but" : what is not reserved in this picture? Himself balancer! We have a very simple distribution of clients by region. We have domains bitrix24.ru, bitrix24.com, .de - now there are 13 different pieces that work in the most different zones. We have come to the following: each region has its own balancers. So it is more convenient to distribute by region, depending on what is where the peak load on the network. If this is a failure at the level of a single balancer, then it is simply decommissioned and removed from the dns. If there is any problem with the balance group, they are reserved at other sites, and switching between them is done using the same route53, because at the expense of a short ttl switching occurs a maximum of 2, 3, 5 minutes.
The third "but" : what else is not reserved? S3, right. When we placed files that we keep with users in s3, we sincerely believed that it was armor-piercing and we don’t need to reserve anything there. But the story shows what happens differently. In general, Amazon describes S3 as a fundamental service, because Amazon itself uses S3 to store images of machines, configs, AMI images, snapshots ... And if s3 falls, as it once happened during these 7 years, how much we exploit bitrix24 pulls a lot of everything - the inaccessibility of the start of virtual machines, the failure of api and so on.
And fall S3 can - it happened once. Therefore, we came to the following scheme: a few years ago, there were no serious object public repositories in Russia, and we considered the option of doing something of our own ... Fortunately, we did not start it, because we would have dug into that expertise, which we did not We possess, and for certain would nakosyachili. Now Mail.ru has s3-compatible storage, Yandex has it, a number of providers have it. We finally came to the idea that we want to have, firstly, a reservation, and secondly, the ability to work with local copies. For specifically the Russian region, we use the Mail.ru Hotbox service, which is api compatible with s3. We didn’t need any serious improvements in the code inside the application, and we did the following mechanism: there are triggers in s3 that trigger the creation / deletion of objects, Amazon has a service like Lambda - this is serverless code launch that will be executed when triggered or those triggers.
We made it very simple: if the trigger works for us, we execute the code that copies the object to the Mail.ru repository. In order to fully start working with local copies of data, we also need backward synchronization so that customers who are in the Russian segment can work with the storage that is closer to them. Mail is about to complete the triggers in its storage - it will be possible to perform reverse synchronization at the infrastructure level, while we are doing it at the level of our own code. If we see that the client has placed a file, then at our code level we put the event in a queue, process it, and do reverse replication. What it is bad for is: if we do some work with our objects outside our product, that is, by some external means, we will not take this into account. Therefore, we are waiting until the end, when there will be triggers at the storage level, so that no matter where we run the code, the object that came to us was copied in the other direction.
At the code level, we have both storages for each client: one is considered the main one, the other is backup. If everything is good, we work with the storage that is closer to us: that is, our customers who are at Amazon, they work with S3, and those who work in Russia, they work with Hotbox. If the checkbox is triggered, then we have to connect failover, and we switch clients to another storage. We can check this box independently by region and we can switch them back and forth. In practice, this has not yet been used, but this mechanism has been foreseen and we think that sometime this switch will be needed and useful to us. Once it happened.
Oh, and Amazon ran away from you ...
This April is the anniversary of the start of Telegram locks in Russia. The most affected provider that came under this is Amazon. And, unfortunately, Russian companies that worked for the whole world suffered more.
If the company is global and Russia for it is a very small segment, 3-5% - well, one way or another, you can donate them.
If this is a purely Russian company - I am sure that it is necessary to locate locally - well, just by the users themselves will be convenient, comfortable, the risks will be less.
And if this is a company that operates globally, and it has approximately equal customers from Russia, and somewhere in the world? Segment connectivity is important, and they should work with each other anyway.
At the end of March 2018, Roskomnadzor sent a letter to the largest operators saying that they are planning to block several million ip Amazons in order to block ... the Zello messenger. Thanks to these same providers - they successfully leaked the letter to everyone, and there was an understanding that coherence with Amazon could fall apart. It was Friday, we ran in panic to colleagues from servers.ru, with the words: “Friends, we need several servers that will not stand in Russia, not in Amazon, but, for example, somewhere in Amsterdam,” in order to be able to at least in some way put there own vpn and proxy for some endpoints that we cannot influence in any way, for example, the endponts of the same s3 - you cannot try to raise a new service and get another ip, we you still need to get there. In a few days we set up these servers, raised them, and in general, by the time the locks began, we were ready. It is curious that the RKN, having looked at the hype and panic raised, said: “No, we will not block anything now.” (But this is exactly up to the moment when they began to block the telegrams.) By adjusting the bypass capabilities and realizing that the lock was not entered, we, however, did not begin to disassemble the whole thing. So, just in case.
And in 2019, we still live in blocking conditions. I watched last night: about a million ip continue to block. True, Amazon almost unlocked at full strength, reached a peak of 20 million addresses ... In general, the reality is that connectivity, good connectivity - it may not be. Suddenly. It may not be for technical reasons - fires, excavators, everything. Or, as we have seen, not quite technical. Therefore, someone large and large, with their own AS-kami, probably can steer it in other ways, - direct connect and other things already at the level of l2. But in a simple version, as we or even smaller, you can, just in case, have redundancy at the server level, raised somewhere else, configured in advance by vpn, proxy, with the ability to quickly switch to them the configuration in those segments that are critical for your connectivity . It came in handy to us more than once, when the blocking of Amazon began, we let through S3 traffic in the worst case, but gradually it all settled.
And how to reserve ... a whole provider?
Now we don’t have a script in case of failure of the entire Amazon. We have a similar scenario for Russia. We were located in Russia with one provider, from whom we chose to have several sites. And a year ago we ran into a problem: even though these are two data centers, already at the level of the network configuration of the provider there may be problems that will affect both data centers anyway. And we can get unavailability at both sites. Of course, that's what happened. We eventually reviewed the architecture inside. It has not changed much, but for Russia we now have two sites, which are not from one provider, but from two different ones. If one of them fails, we can switch to another.
Hypothetically, for Amazon we are considering the possibility of reserving at the level of another provider; maybe Google, maybe someone else ... But so far we have seen in practice that if Amazon has accidents at the level of one availability-zone, accidents at the level of the whole region are quite rare. Therefore, we theoretically have an idea that we may make a reservation “Amazon is not Amazon”, but in practice there is no such thing yet.
A couple of words about automation
Is automatics always needed? Here it is appropriate to recall the effect of Dunning-Kruger. On the axis "x" our knowledge and experience, which we are recruited, and on the axis "y" - confidence in our actions. At first we do not know anything and are not at all sure. Then we know a little and become mega-confident - this is the so-called “peak of stupidity”, well illustrated by the picture “dementia and courage.” Then we have already learned a little and are ready to go into battle. Then we step on some kind of mega-serious rake, we fall into the valley of despair, when we seem to know something, but in fact we don’t know much. Then, as we gain experience, we become more confident.
Our logic about various switchings automatically to certain accidents - it is very well described by this schedule. We started - we did not know how, almost all the work was done manually. Then we realized that it was possible to hang everything on automation and, like, sleep well. And suddenly we are stepping on a mega-rake: we have false positives triggered, and we switch traffic back and forth, when, in an amicable way, it was not worth it. Consequently, replication breaks down or something else - this is the very valley of despair. And then we come to the understanding that everything must be treated wisely. That is, it makes sense to rely on automation, providing for the possibility of false positives. But! if the consequences can be devastating, then it is better to give it at the mercy of the duty shift, on duty engineers, who will make sure that it is really an accident, and will perform the necessary actions manually ...
Conclusion
For 7 years we have gone the way from the fact that when something fell - there was panic-panic, to the understanding that there are no problems, there are only tasks, they are necessary - and you can - solve. When you build a service, look at it with a glance from above, assess all the risks that may occur. If you see them right away, then in advance, provide for redundancy and the possibility of building a fault-tolerant infrastructure, because any point that can fail and lead to the inoperability of the service - it will do it. And even if it seems to you that some elements of the infrastructure definitely will not fail - like the same s3, still keep in mind that they can. And at least in theory, have an idea of what you will do with them if something happens anyway. Have a risk management plan. When you think about doing everything automatically or manually, assess the risks: what will happen if the automation starts switching everything - will it not lead to an even worse picture compared to the accident? Maybe somewhere you need to use a reasonable compromise between the use of automation and the response of the engineer on duty, who will appreciate the real picture and understand whether something needs to be switched on the move or “yes, but not now”.
A reasonable compromise between perfectionism and real forces, time, money, which you can spend on the scheme that you will have in the end.
This text is an augmented and extended version of the report by Alexander Demidov at the Uptime day 4 conference.
Source: https://habr.com/ru/post/455112/
All Articles